



 文章探讨了YOLO和FasterR-CNN在目标检测领域的应用。YOLO以其快速性适用于实时任务,但精度略逊;而FasterR-CNN虽然速度较慢,但效果较好。MaskR-CNN在实例分割上有优势。mAP是评估检测精度的关键指标。YOLOv2和YOLOv3通过改进网络结构和先验框策略提高了性能。
文章探讨了YOLO和FasterR-CNN在目标检测领域的应用。YOLO以其快速性适用于实时任务,但精度略逊;而FasterR-CNN虽然速度较慢,但效果较好。MaskR-CNN在实例分割上有优势。mAP是评估检测精度的关键指标。YOLOv2和YOLOv3通过改进网络结构和先验框策略提高了性能。
2015年faster-rcnn 经典之作
mask-rcnn 5fps不能做实时的任务
深度学习经典检测方式:有两种两阶段
需要先预选
单阶段-YOLO系列
one-stage:最核心的优势就是速度非常快,适合做实时检测任务
缺点就是通常情况下效果不太好。YOLO效果没有mask-rcnn
YOLO可以自己控制网络的深度,效果越好,速度越慢,效果越好,速度就会越差
map值检测任务中的指标,综合的指标。
fps速度值代表网络的速度。
对于two-stage的网络
速度通常较慢5fps,但是效果通常还是不错
非常实用的通用框架maskrcnn,可以熟悉一下
指标分析:map指标综合测量检测的结果
精度:识别出来的锚框和实际的框是否吻合
召回:有多少的框没有识别出来,原始标注的数据中所有的对象是否都识别到了。
单独看精度和recall,其中一个指标变高,另一个就会变低,所以并不能用两个值作为衡量网络好坏的指标
交并比iou
iou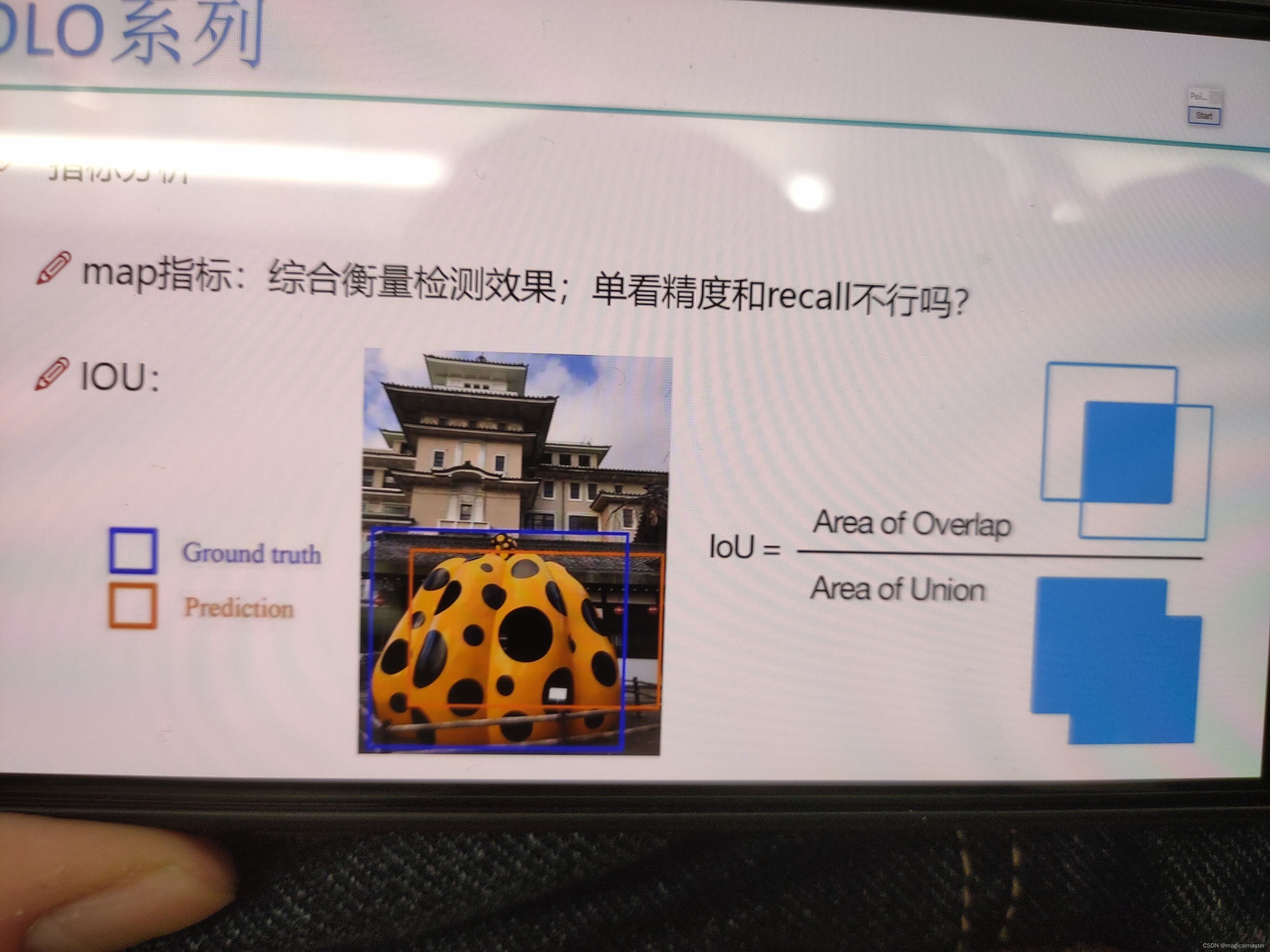
ios越高代表越重合,网络效果越好,越低效果越差。
mAP由精度和召回率计算得到

tp选对的情况下的数目
fp做错的情况下判断为正例数目
fn错误的判断成负例,把女生当做男的拿出来了
tn本身是负例,判断为负例
召回率也叫做查全率。精度指的是我预测出来的框和真实出来的框越接近越好。如果iou的值比较小,都可以认为没有检测到目标。知信度表示当前检测的框是个物体。或者是一个人脸的可能性是多大的
在检测的过程中设定一个阈值,用来筛选出置信度较高的框,作为最终展示出来的框,以避免出现太多的框。小于阈值的框都会被过滤掉
mPA值是由pr图片得出的,取阶段最大值,并计算由最大值所围成的面积 算出来的结果就是一个map值的结果
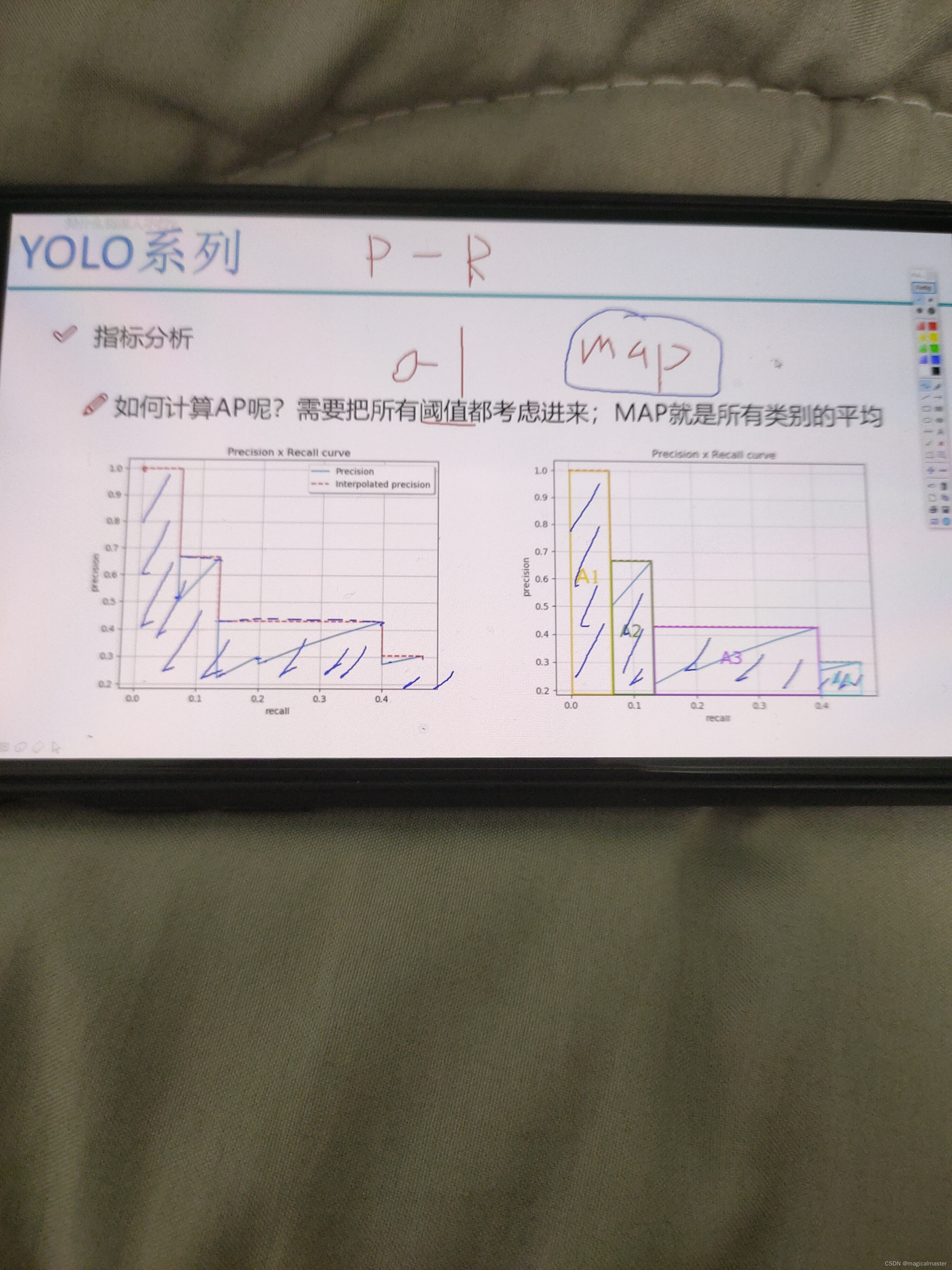
MPA值越接近1效果越好
YOLOv1 2016
经典的one—stage方法
you only look once
将所有的检测问题都转换成回归问题,一个cnn就可以搞定
对视频进行实时检测,应用领域很广

2016年的时候同时出了两款网络,一款是fast rcnn一款是yolo可以看到,虽然rcnn的m'ap值很高,但是实时性太差不可能用于视频流中,yolo在速度上的性能很好
yolov1核心思想
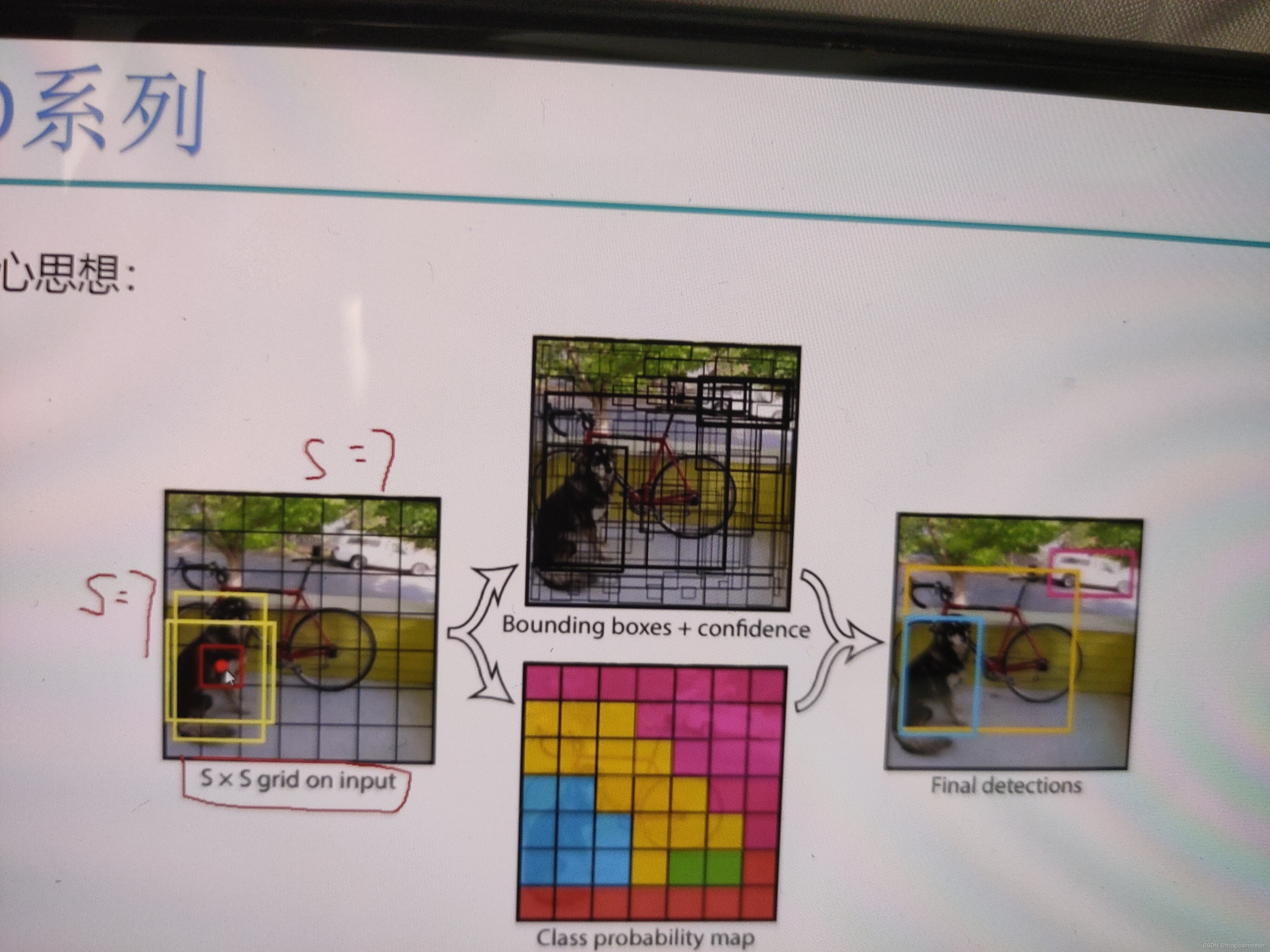
每个方格都要负责表示所代表的物体是什么
中心点附近假设预测出来了两个锚框,h和w各有两个,那么到底是哪个h和w这就是一个回归任务。
总结,yolov1将输入图像划分成若干小方格,产生出两种候选框,实际中两种后选框不够用,检测候选框和实际真实的物体匹配的如何,那么到底用哪个框就要和真实值做对比了,也即IOU值谁的大就微调谁,在预测每一个小框的时候都会得到一个confidence置信度,预测不仅仅要预测出来xyhw回归,也需要预测confidence表示当前点对应的候选框是物体的可能性,所以对每一个小方格计算四个偏移量(x,y,w,h)值和一个置信度的值,最终做过滤,ims对重合框做处理。
细节
输入图形是448*448大小的图像,输入大小不能改变,主要是和fc层相关,全连接层做了强制限定,拉长操作2048的特征,有一个权重参数矩阵和一个偏置参数矩阵不能改变,所以全连接层必须固定前面特征图的大小,由于yolov1,2版本有全连接层所以输入数据是固定的不能改变 特征提取使用Googlenet网络结构,得到一个7*7*1024的特征图,全连接层得到一个4096个特征最终得到7*7*30的特征图,也意味着7*7的格子,每个格子都有30个值,每一个小格子都要产生两种框,B1(x1.y1.w1.h1.C1)其中xy是归一化的结果,值分布在0-1之间,wh经过对数的变化也是经过归一化处理的,在每个格子预测两个框B2(X2.Y2.w2.h2.C2)还有20个数字是20个分类,因为当前的图表中一共有20个类别,预测该点属于每一个类别的概率值是多少,5+5+20为30这就是30的意义,所以需要得到一个7*7*30的特征图。
通过指定损失函数,告诉计算机会逐渐猜到我们的需求,神经网络给它合适的损失值就可以达到想要的结果。
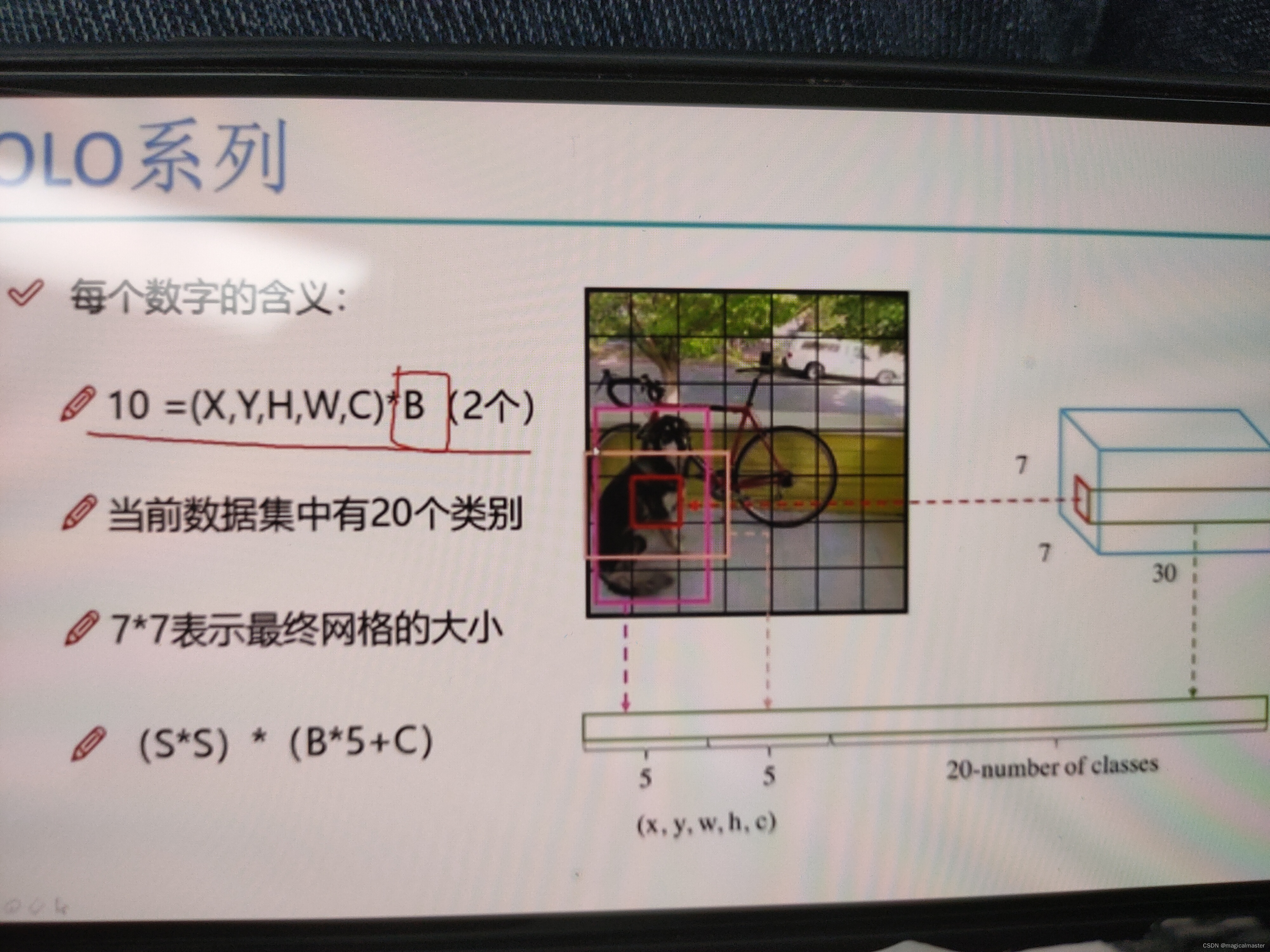
最后的预测值得到(s*s)的大小的小格子数目,每个格子另外赋有置信度个数*5个值+检测的类别如此设计最终的特征图。
损失函数
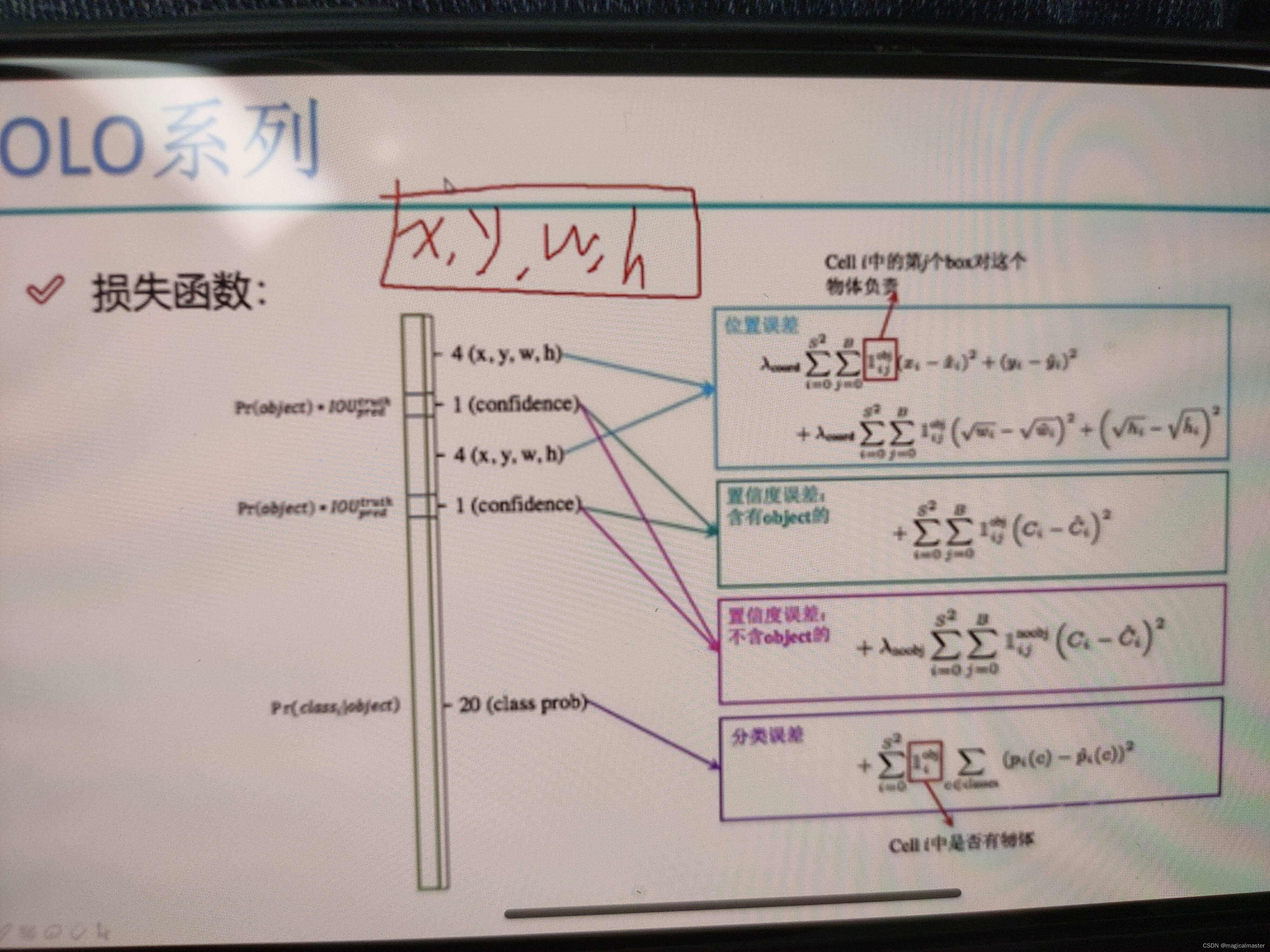
最后的结果会计算x,y,w,h希望x,y,w,h和真实值的差距越小越好,最小化他们和真实值之间的误差,这就是第一个损失函数(位置误差)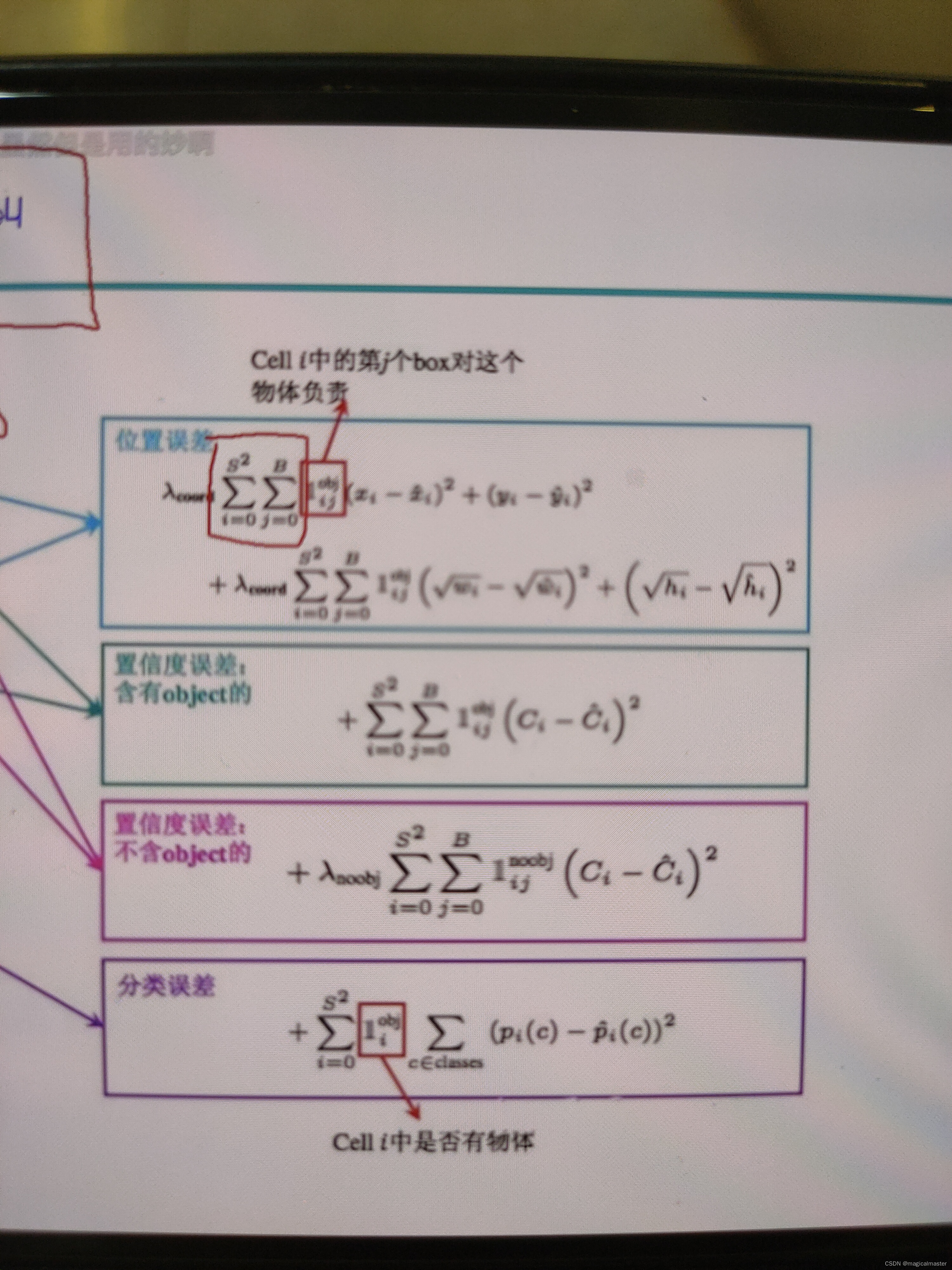
位置误差第一项代表S*S个小方格都会预测一遍,下一项从0-B(b代表设定每个方格要有两个框的选项,这个是yolov1设定的),下一项用于计算两个框与真实框的iou最大的那一个框然后再计算预测值和真实值之间的差异。对h进行根号做差平方处理,这是由于在目标检测的时候较大和较小,目标物的大小没法控制,但是我们可以在做预测的时候去有意的去设置一些侧重点,这个地方的处理就是为了从数学的角度来讲,计算一个y等于根号x的方程,时候对应点的斜率,发现x越小对应的斜率越大,即更敏感,x越大,斜率越小,越迟缓这样就做到了这样就做法到了侧重,加根号解决了一点但并没有全部解决,xy和wh前面都有一个权重项可以自己加权重项。
除了位置还需要置信度
在做置信度的时候需要区分前景和背景的区别,含有物体的计算一个置信度,不含物体的也计算一个置信度对于不带目标物的损失函数前多了一个权重λ,带目标物的置信度误差没有权重参数。
对比一张图像中的前景和背景,背景会比较多,导致样本不均衡,若不加权重项,影响因素可能会被背景影响。
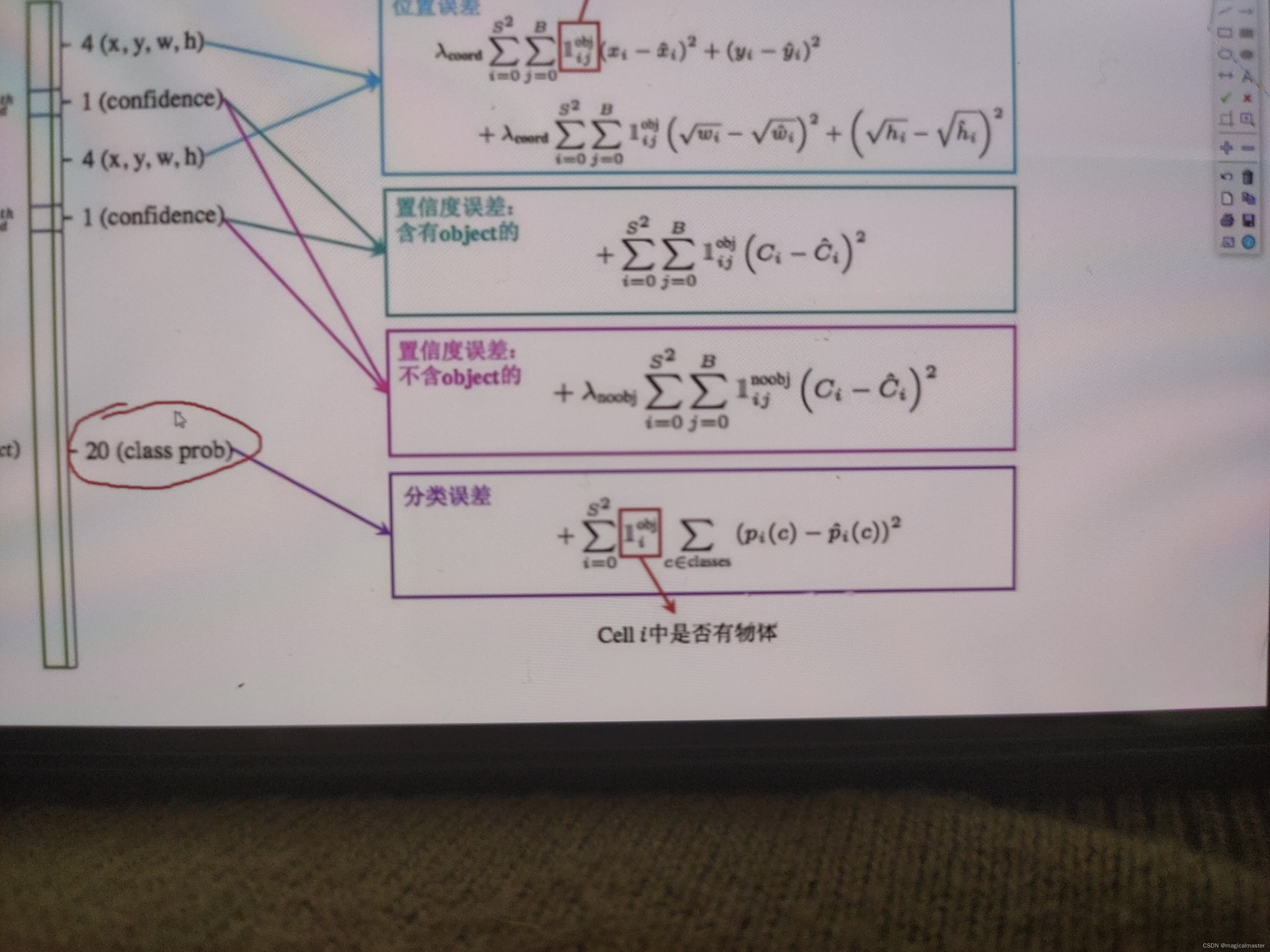
对于20分类任务的损失函数,预测概率和真实概率计算交叉熵即可。
第一个损失函数是位置上的偏差,第二个是置信度(置信度就是判断前景和背景是不是一个物体的误差)第三个就是判断这个物体是哪个类别的损失函数。v1后面loss也会沿用。
NMS非极大值抑制
有很多框重叠,按置信度进行排序,选择极大值即可,筛选出一个框即可。
问题:
1.当前的点只会预测一个物体,重合在一起,很难区分出来。
2.小物体检测不到,两种框一般都是大型的物体,多标签softmax无法解决,长宽比可选但是单一。b1&b2
优点:快速简单。
YOLOv2版本改进

v2相比于v1变动并不大,相比之下是细节的调整,整体的思想变动不大。
图标中的每一项增加都会增加yolo的mAP的性能指标。
YOLOv2 batch normalization 16-17年
v2版本放弃了全连接操作(dropout)取而代之是卷积层之间进行batch normalization,网络的每一层的输入都做了归一化,收敛相对更容易
经过batch normalization处理后的网络会提高2%的mAP性能,从现代的角度看,batch normalization已经成为网络必备的处理。
yolov2使用更大的分辨率
v1训练的时候使用224*224,测试使用448*448,可能导致模型水土不服,在v2版本中进行了10次448*448的微调,使用高分辨率分辨器使得mAP的性能提高4%

YOLOv2提出了一个新的网络结构Darknet
darknet借鉴了vgg和resnet的思想合并
主要提取网络取消了全连接层,所有的网络全都是卷积操作,好处是全连接层容易过拟合,全连接层训练慢,(参数比较多)。
没有全连接层,使用五次降采样(max pooling)经过max pooling,结果都会变成之前的1/2,5次降采样意味着缩小2∧5=32,代表着h和w都除以32,YOLOv2的实际输入是416*416,(为什么不是448*448,这是因为这里的数字一定要被32所整除,便于计算,最终只有一个中心点,如果是偶数会得到4个中心点不便于计算选取)最终得到一个13*13的特征图。
采用的卷积是1*1和3*3,这样会节省很多参数,感受野比较大,借鉴了vgg的思想。
常用的是DarkNet19,19意味着有19个卷积层,对于1*1的卷积核只改变了特征图的个数,只是为了特征的传递代价较少。
YOLOv1的先验框是可以设定的B=2。
对于coco数据集,将100w的锚框聚类成5类,这5类都会有一个中心点wh对应的值,相比于机械的1/2 2/1较为机械,使用kmeans的做法会更合理。
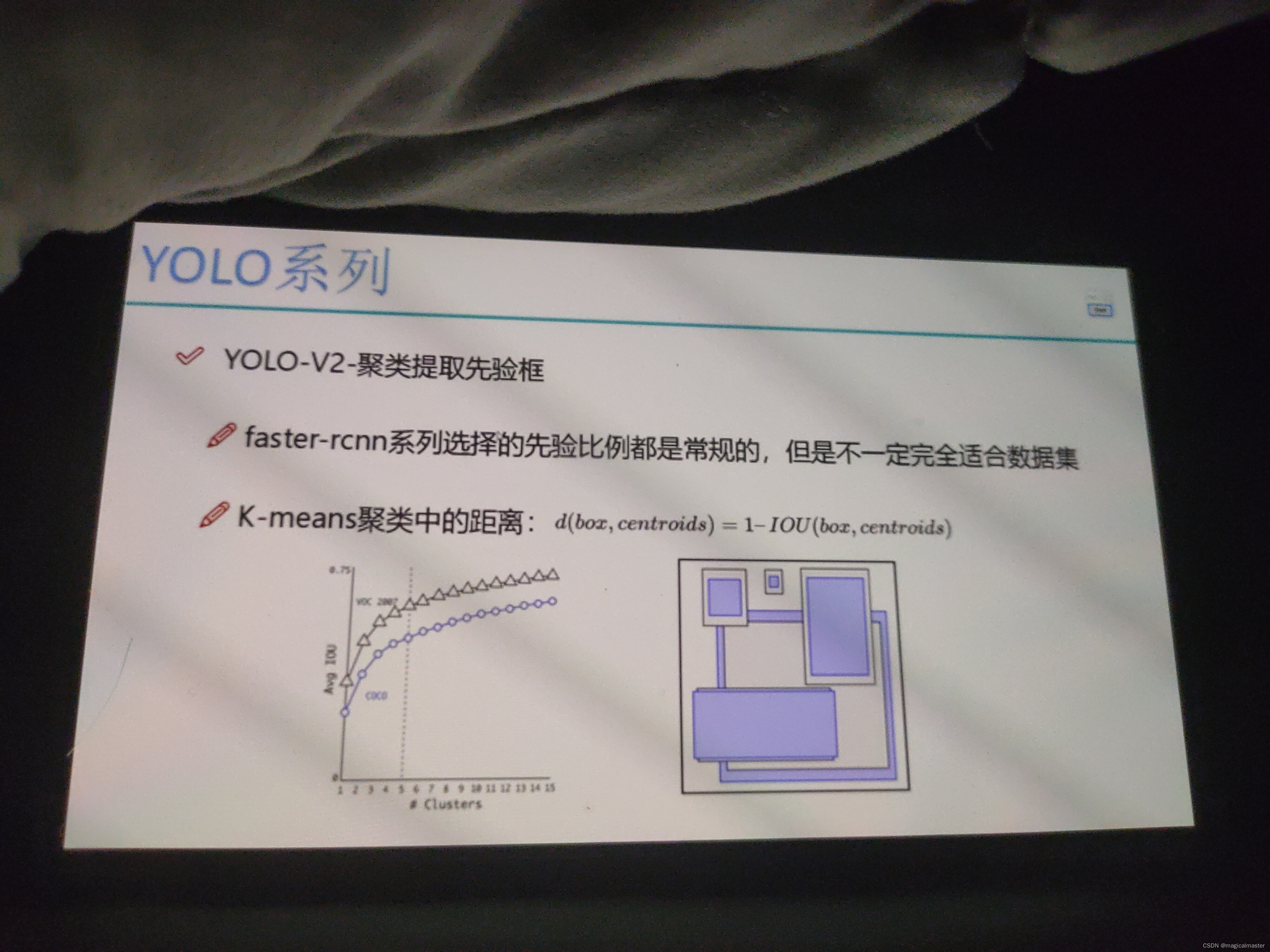
YOLOv2聚类提取先验框
faster-rcnn系列选择的先验比例都比较常规,但是不一定适应所有的数据集。
kmeans计算机距离不考虑欧式距离,真实情况中有特别大的锚框和特别小的锚框,对于特别大的误差也比较大,对于较小的物体产生的误差比较小,误差和锚框的大小相关。
这里提出了一种距离的定义方式:,d(box,centrouds)=1-IOU(box,centrouds)
整体的思想是,中心点和目标点锚框的交并比计算,如果交并比<1代表有∩,d=1代表离得远,d靠近0代表离得近。可以限制距离的取值范围,没有大小物体的限制了。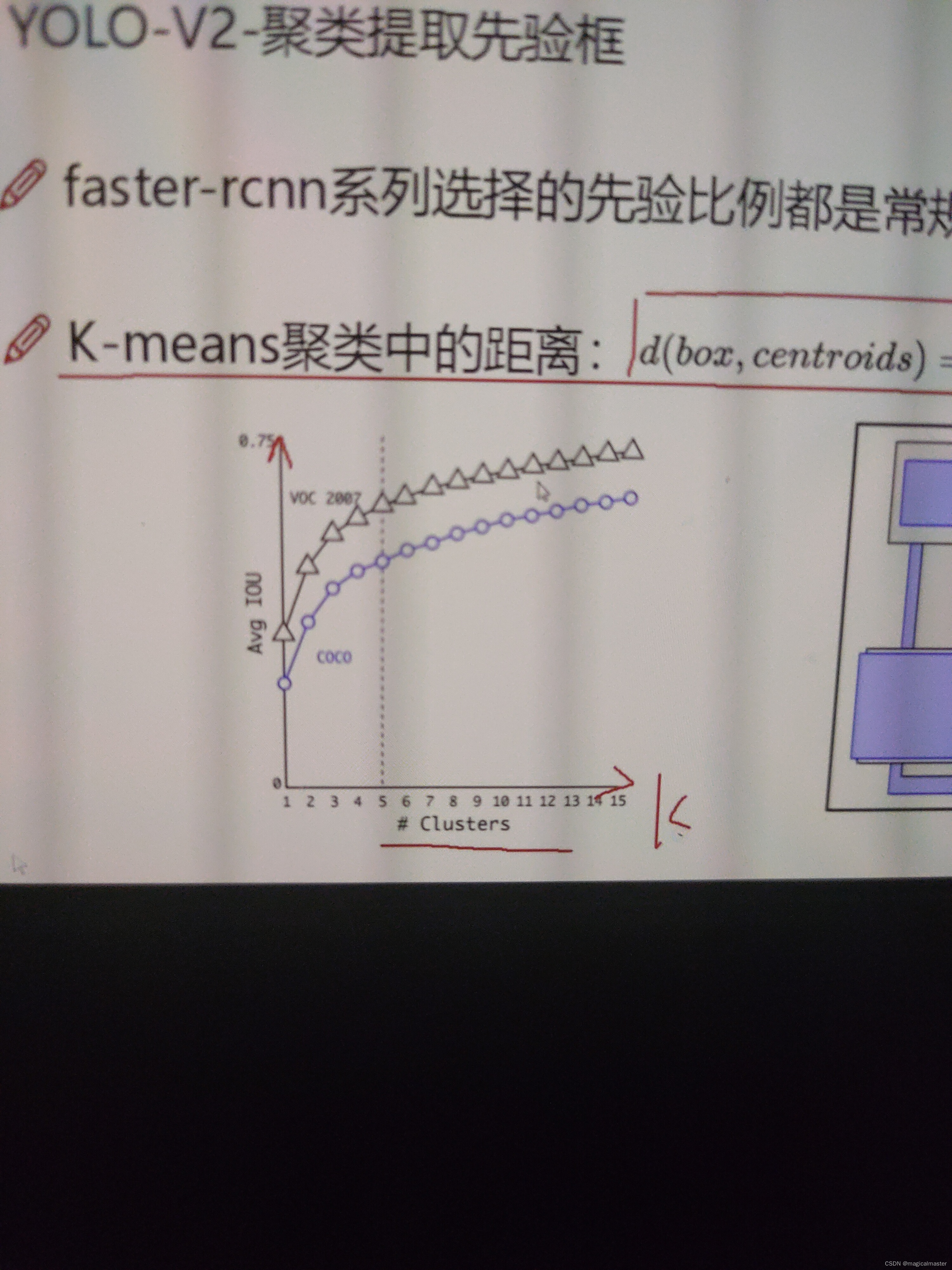
如图所示,横轴为k的取值,纵轴是avg平均iou的取值,对于k越大iou越精确,k等于5avgiou可以,再向上提升并不明显了,每个点产生5个候选框。
YOLOv2 anchor-box
通过引用anchor-boxes,使得预测的boxes更多(13*13*n),和faster-rcnn系列不同的是先验框并不是直接按照长宽比例计算的,对比增加了锚框mAP从69.5下降到69.2下降了0.3个点,但是recall从81%-88%提升了7个点意味着有更多的目标被识别出来了 。

之前的办法对候选框中的值进行预测x,y,w,h。先验框(打标)的有xywh,而对于预测的tx,ty,tw,th。预测的其实是偏移量,网络参数就是随机初始化,不适合网络学习和收敛,所以直接预测的是相对的位置,因为向左向右移动会使得预测的锚框漂移出先验框。V2并没有直接使用偏移量,而是相对于基本网格的偏移量
上图中pw,ph,px,py是先验信息,tx,ty,tw,th为预测值,偏移值传输到sigmoid函数中,取值始终保持在0-1之间,限制输入值范围,cx,cy相对于左上角(0.0)网格的位置值,anchor框是先验框,需要映射会原始图片的长和宽,通过预测值和先验框计算在特征图中的xywh,再扩大对应的倍数就得到图片中的x,y,w,h实际的中心的坐标点。
YOLOv2感受野

概述就是特征图上的点能看到原始图像的多大区域。和卷积核大小一致。
YOLOv2对于特征图进行了拆分和组合。
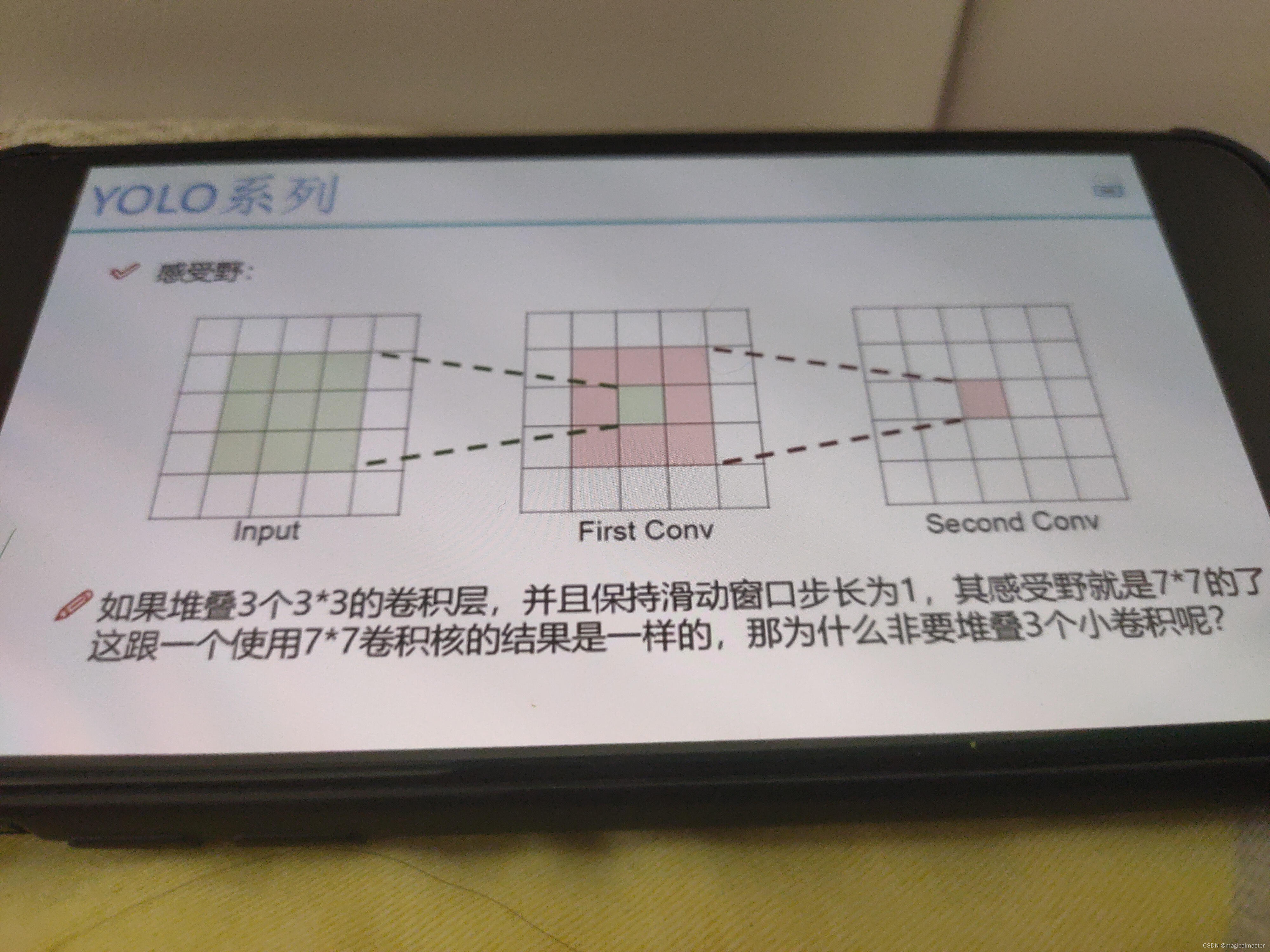

为什么说使用较小的卷积核,因为通过计算堆叠的卷积核所需的参数更小,卷积的过程越多,特征提取更细致。
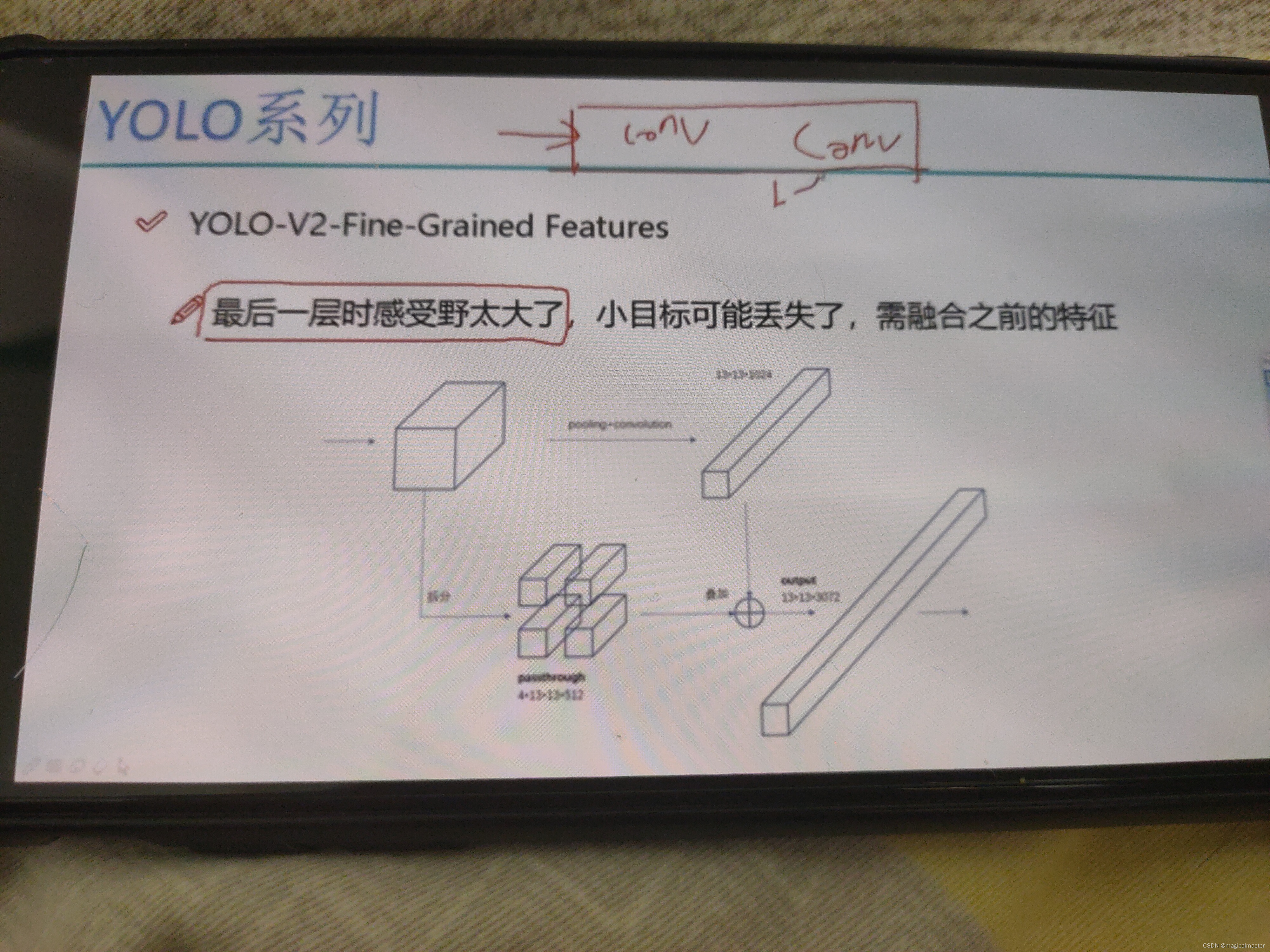
一个原始图像经过不断的卷积得到的最后的特征图的感受野会比较大,适合捕捉大的物体,小物体不受关注,倒数第二或三可能会关注,不仅使用最后的特征图,可以加将之前的特征图融合在一起,拆分成四个。
具体过程是将一个26*26*512大小的特征图拆分成四个4*13*13*512的特征图,由于第一步得到1024个特征图,4*512+1024
YOLOv2多尺度的检测

多尺度检测,正常情况下训练过程中,数据多大就固定死不变了,如果都resize成固定的大小,网络中都是卷积,输入的大小不受限制。只有全连接层输入大小才是固定的,之所以是320*320是因为要求可以被32所整除,最大是608*608每经过几次迭代有适应能力,能力会更全面。
经过v2各种各样的改变map值提高了。
YOLOv3
希望把特征提取的更好,YOLOv3darknet网络的升级
yolo的源码可以直接拿来套用,YOLOv3最大的改进就是网络结构,使其更适合小目标检测
特征做的更细致,融入更多持续特征图信息来预测不同规格物体。
先验框更丰富,3种scal,每种3个规格,一共有9种
softmax改进,预测多标签任务(狗,哈士奇,母狗,哺乳动物)把多分类划分成多个二分类。

多scale,物体有大小之分,目标有大中小三种不同的物体,预测大的就单独预测大的物体,预测中的就专门预测中的专门预测中等大小物体。特定大小的锚框专门检测特点大小的物体。13 23 53三种规格,每种都要有候选框,一共有9种候选框。
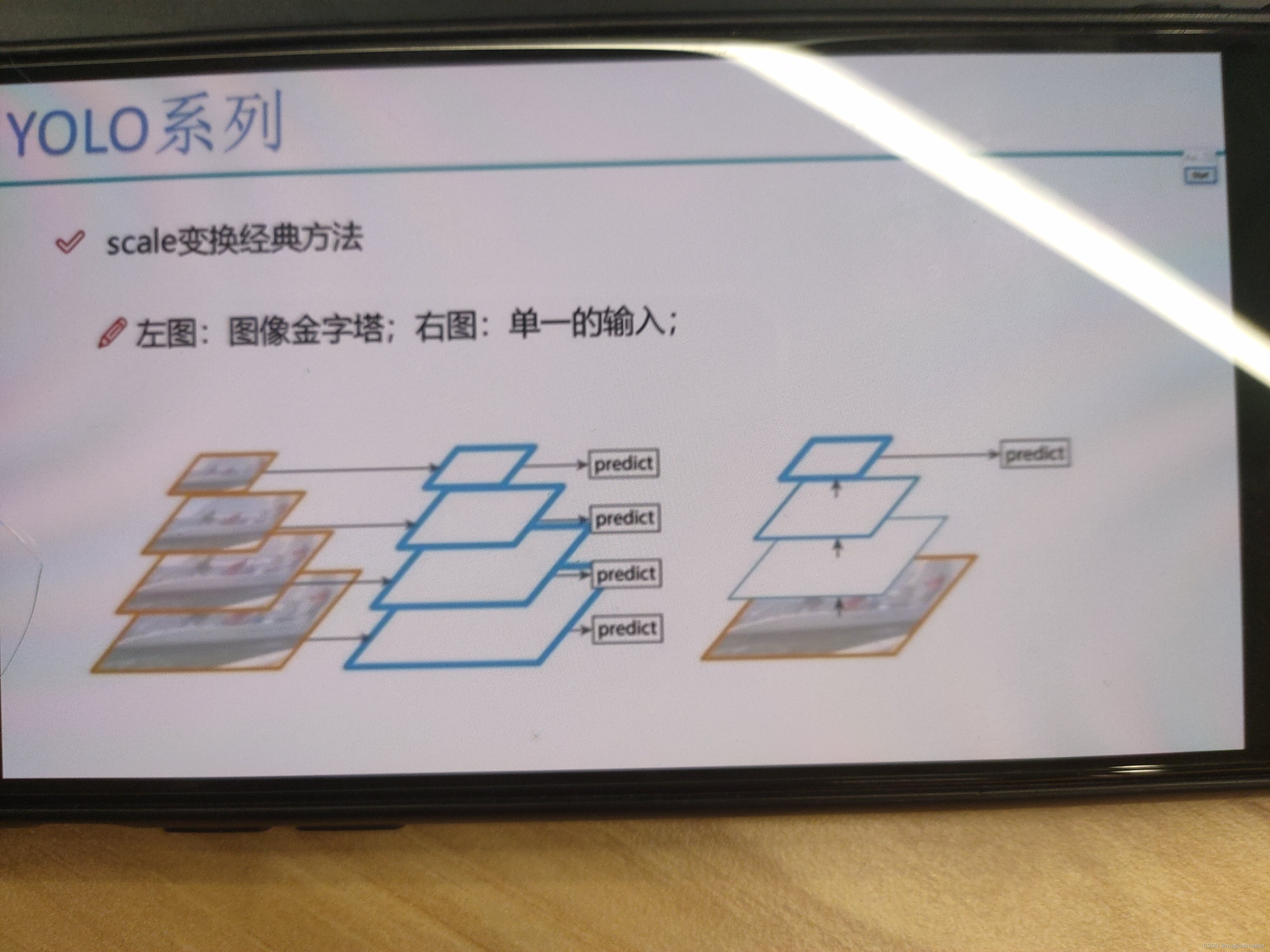
在scale的变化的过程中,左图将图像数据做成金字塔resize,输入网络中得到的特征图就是固定的,但是YOLO追求速度第一map第二,速度太慢了 右侧cnn单一预测
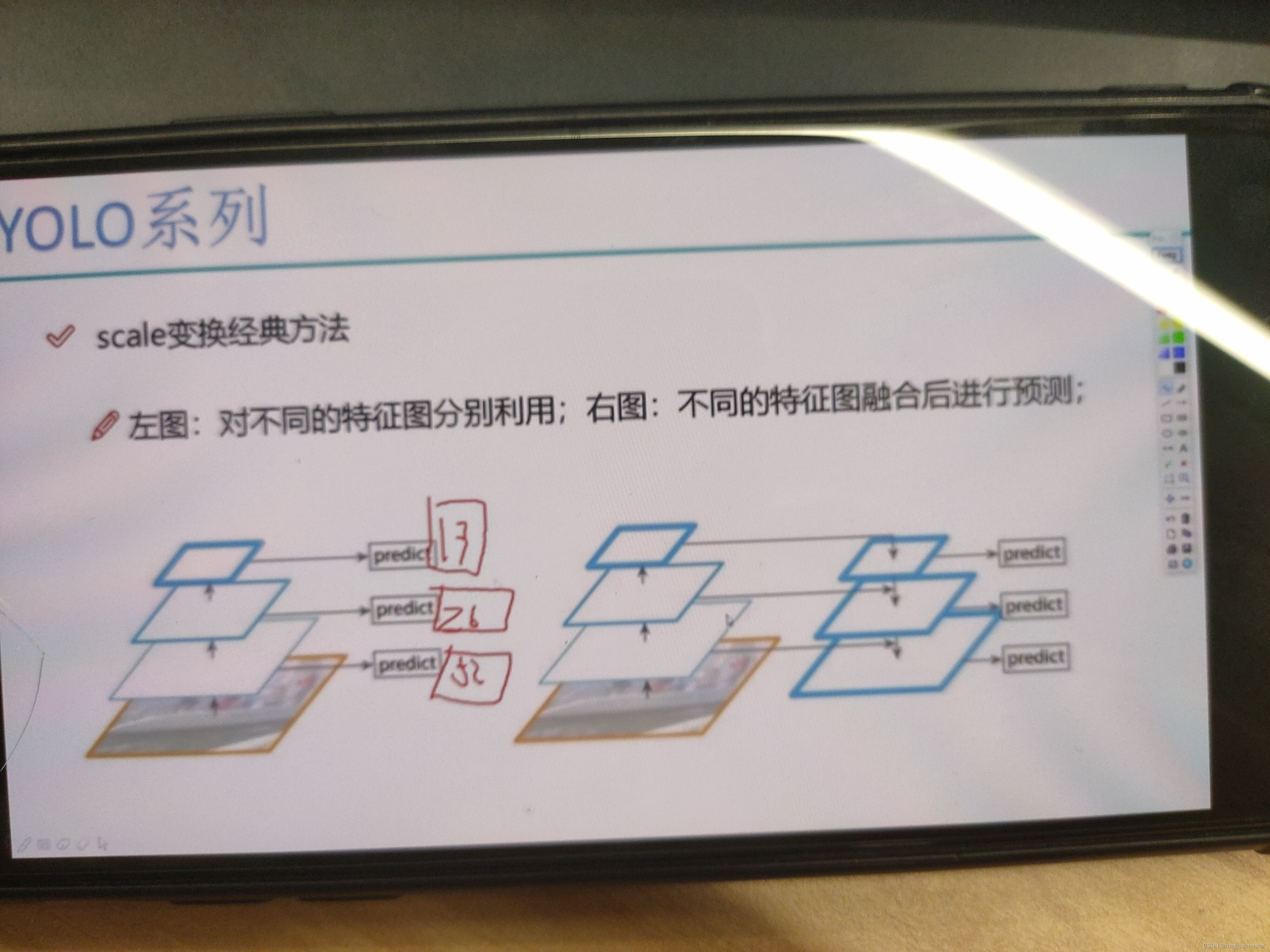
13眼界广 26中年人 52年轻人
互相融合,尺度不匹配,如此可以进行上采样,差值将13*13上采样到26*26 预测中目标的时候是26*26和13*13(做完上采样之后)累加起来特征就融合了,同样的道理52*52预测小目标的会将13*13和26*26都做一个上采样再进行融合。
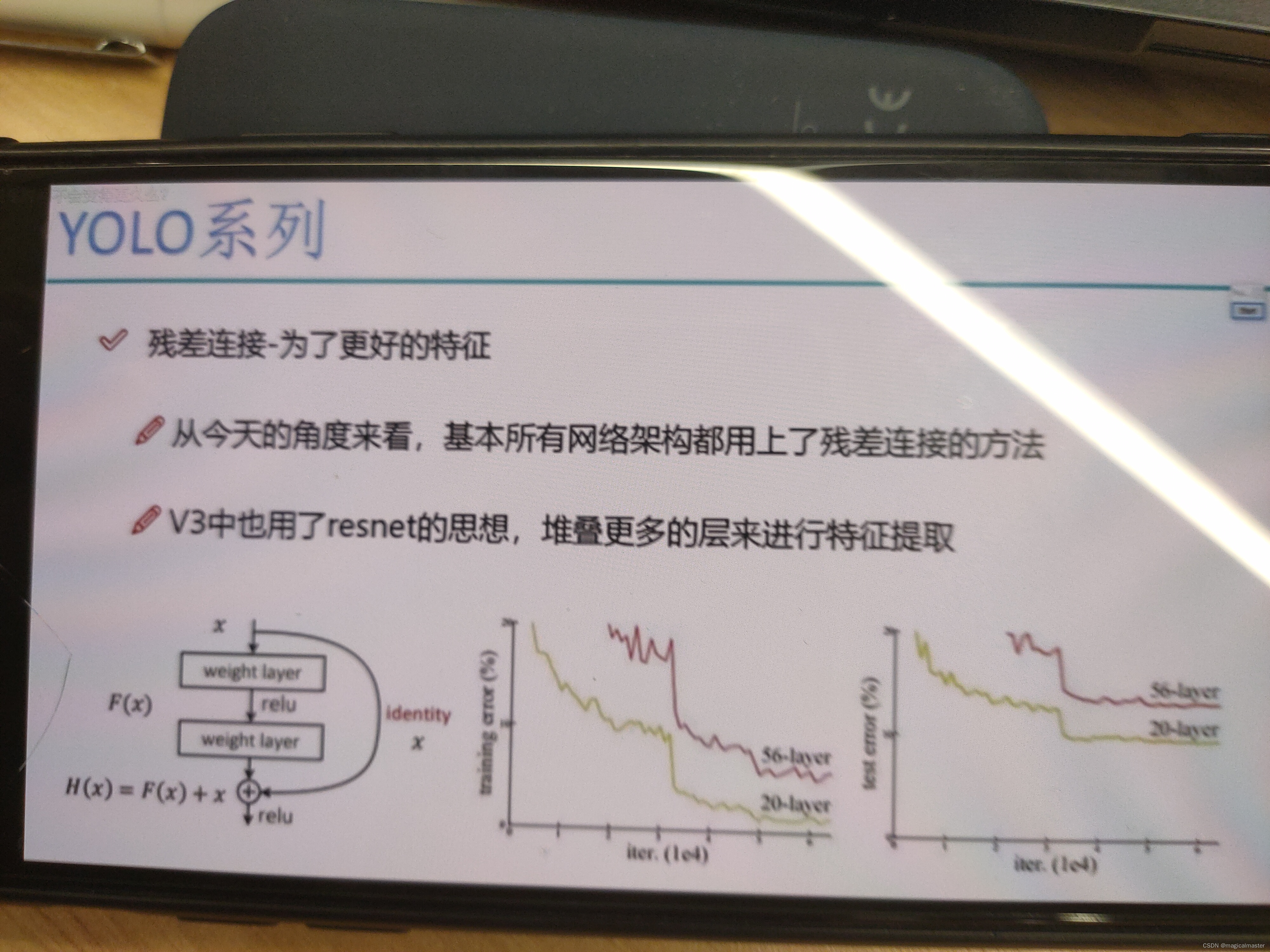
YOLO中的所有的网络都是应用到了resnet 网络进行融合。
残差链接,实现了网络深度和网络性能的呈现正比。
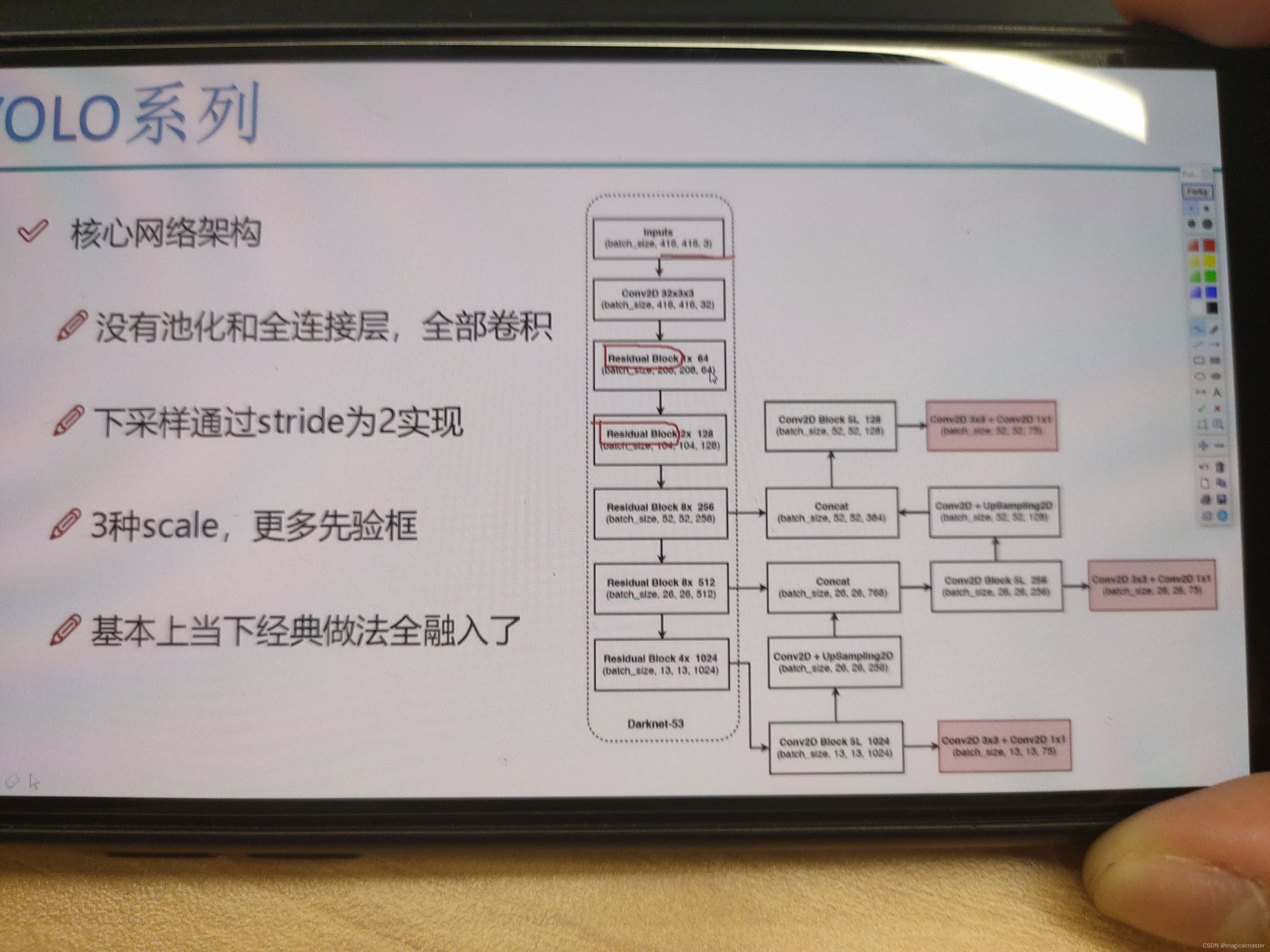
网络没有全连接层和池化,池化做了压缩,可能对特征做了损失,全部做卷积通过设定strid为2将416*416*32的特征图大小变成原来的1/2,需要下采样的地方strid为2.不需要的地方strid 为1,卷积省事,最终得到13*13相当于要预测大目标
YOLOv3的网络结构
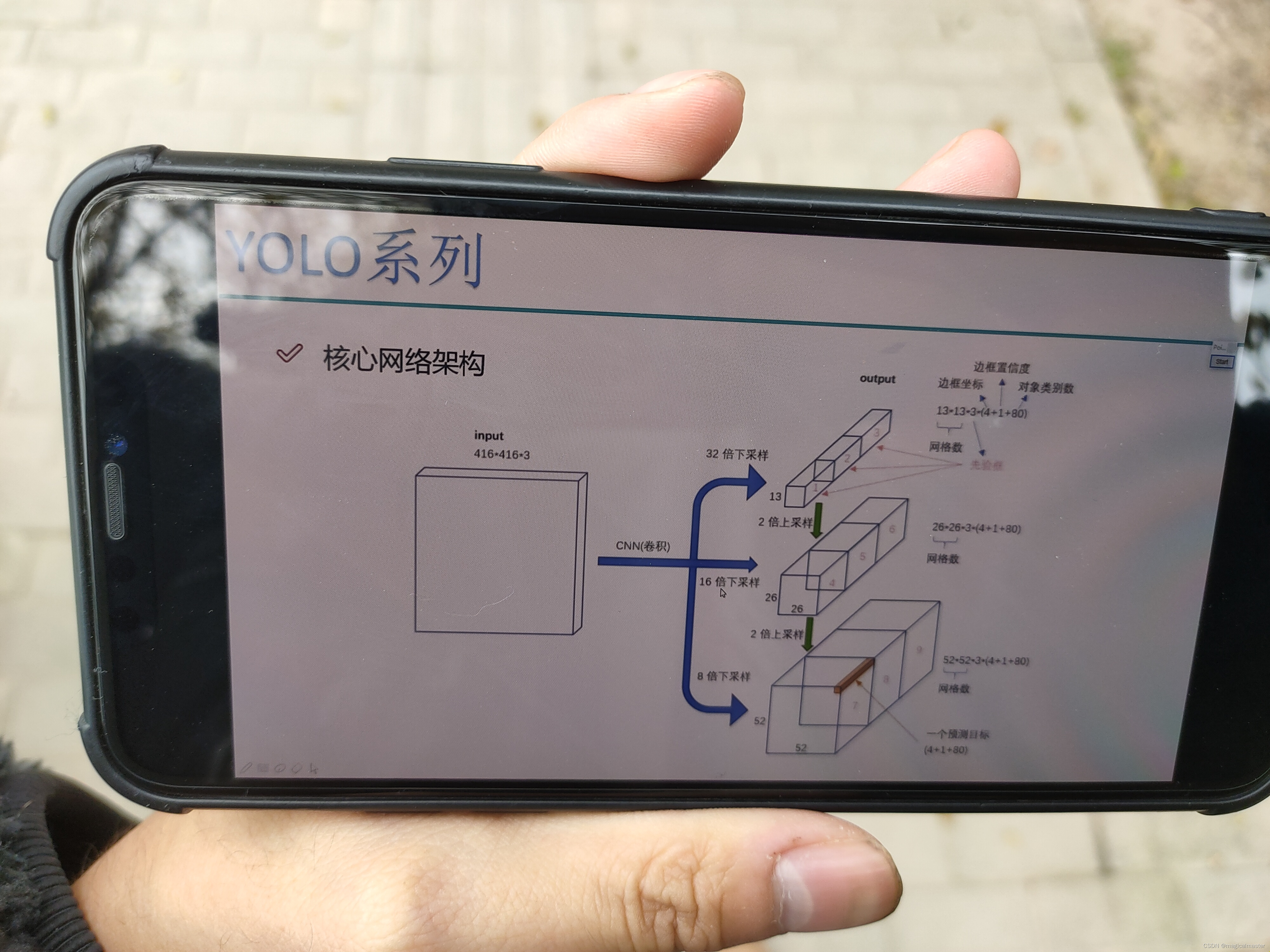
在卷积之中有不同的采样倍数。 V1的网络数量是7×7。V2中的网络数量是13×13。V3之中的网络数量是13乘13和26×26 52×52。共计有三种。最终会得到一个13×13×3×85的特征。其中三的含义是在网格之中的每一个点都会产生三个不同的检验框。也就是先验框个数。其中85的含义是80+4+1 四代表的是bounding box预测出来的xyhw。最后的那个一是confidence 它是属于背景还是属于前景,它是一个物体的概率值。80代表的是这个数据集中,一共有80个类别,不同的任务啊可能80这个数字有所不同,但其他的数字都是一致的。
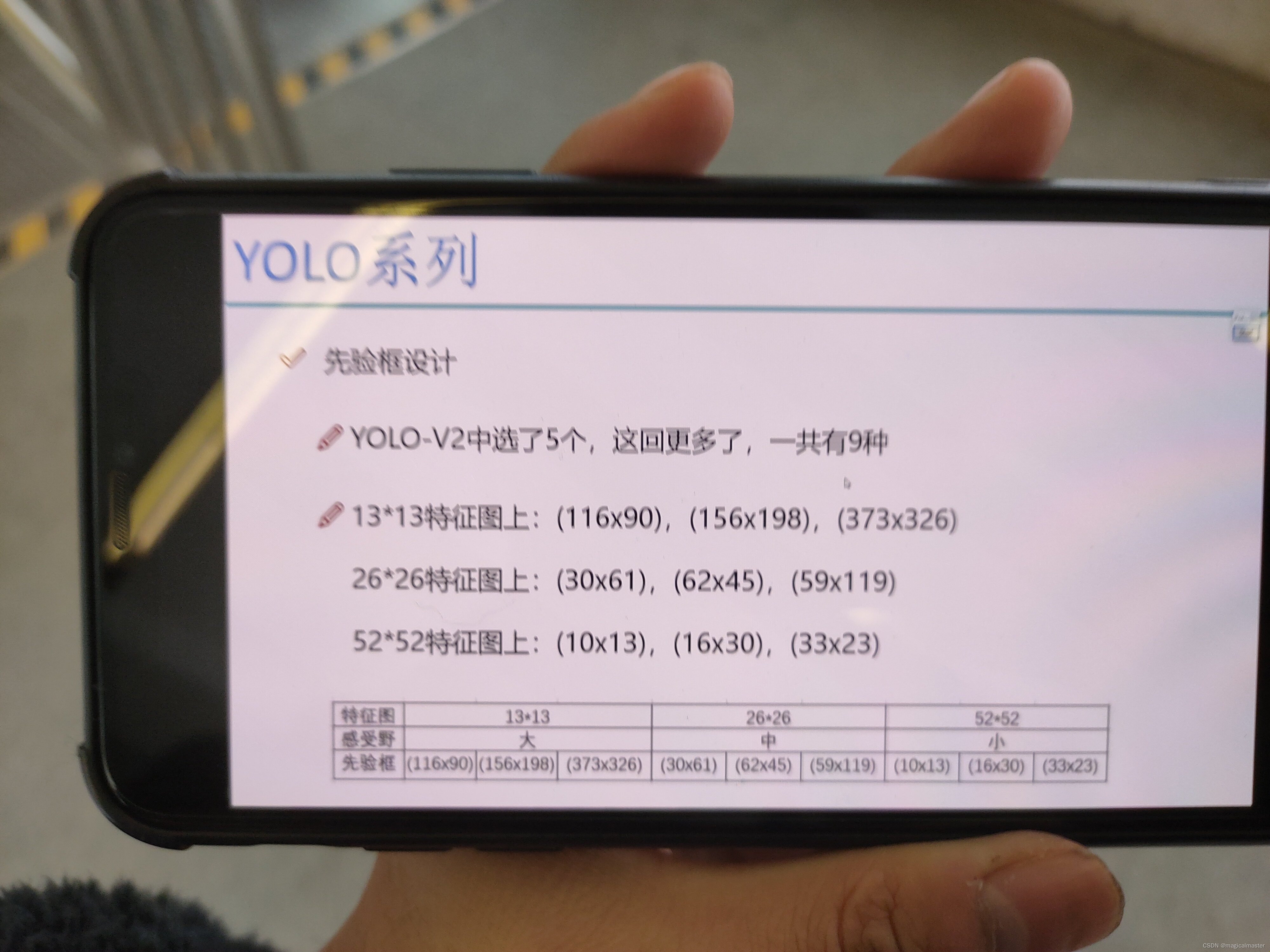
V2通过聚类将不同的物体归纳成为五种大致的对于V3来说,把这个数字提升到了9对于每一个格子,每一个点都要预测九种。在经过聚类之后得到九种不同的规格。属于大的类别可以给13*13,因为感触也大,适合做大物体的识别,对于中等大小的物体,交于26×26。小的物体交于52×52的特征图。
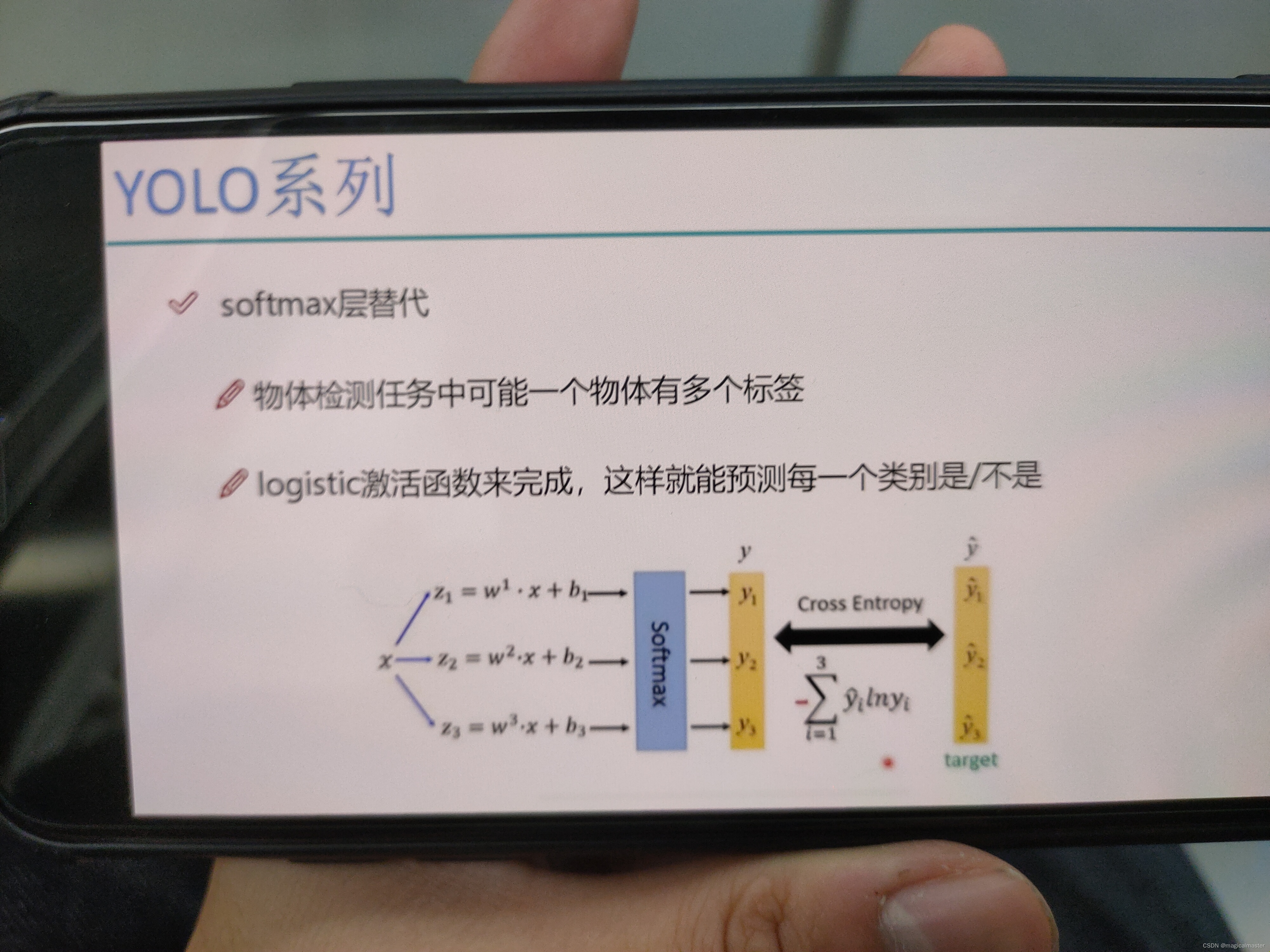
softmax之间做分类,对数函数如果属于物体概率接近于1反之接近0,不适合做多标签任务。对于不同的标签,都做预测概率,设定阈值,大于0.7都可以判定为属于这个类别。



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









