



书接上文 零基础网络爬虫技术(三)
接下来进行几个实战看看学习成果,采用三步走的策略
观察网页,构造resp,解析resp
目录
一、爬取新浪股票
观察网页
https://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml
好了,什么都没有,撤退
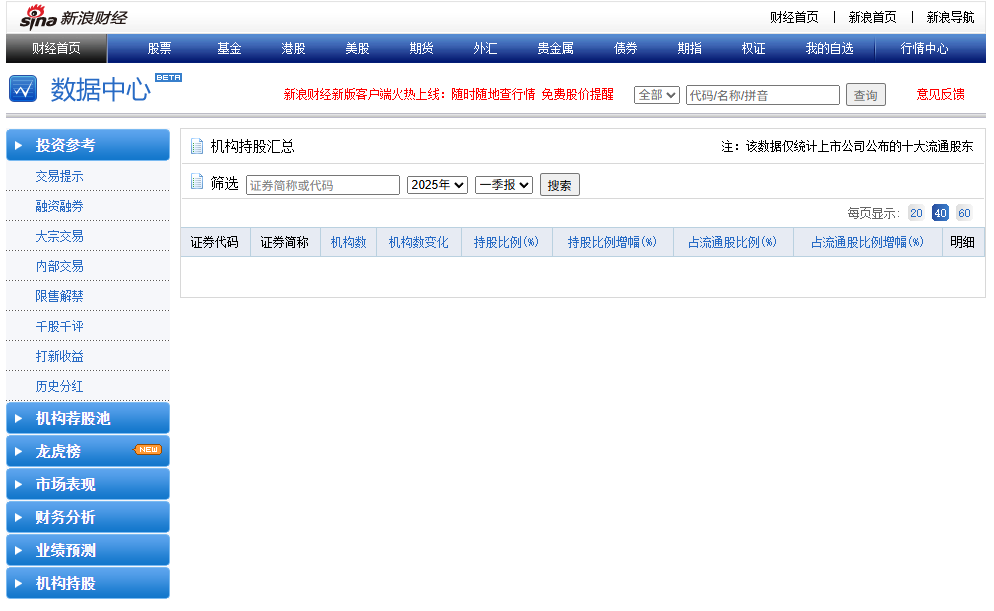
尝试点击搜索,获取我们需要的信息请求URL,请求方法,Referer,User-Agent
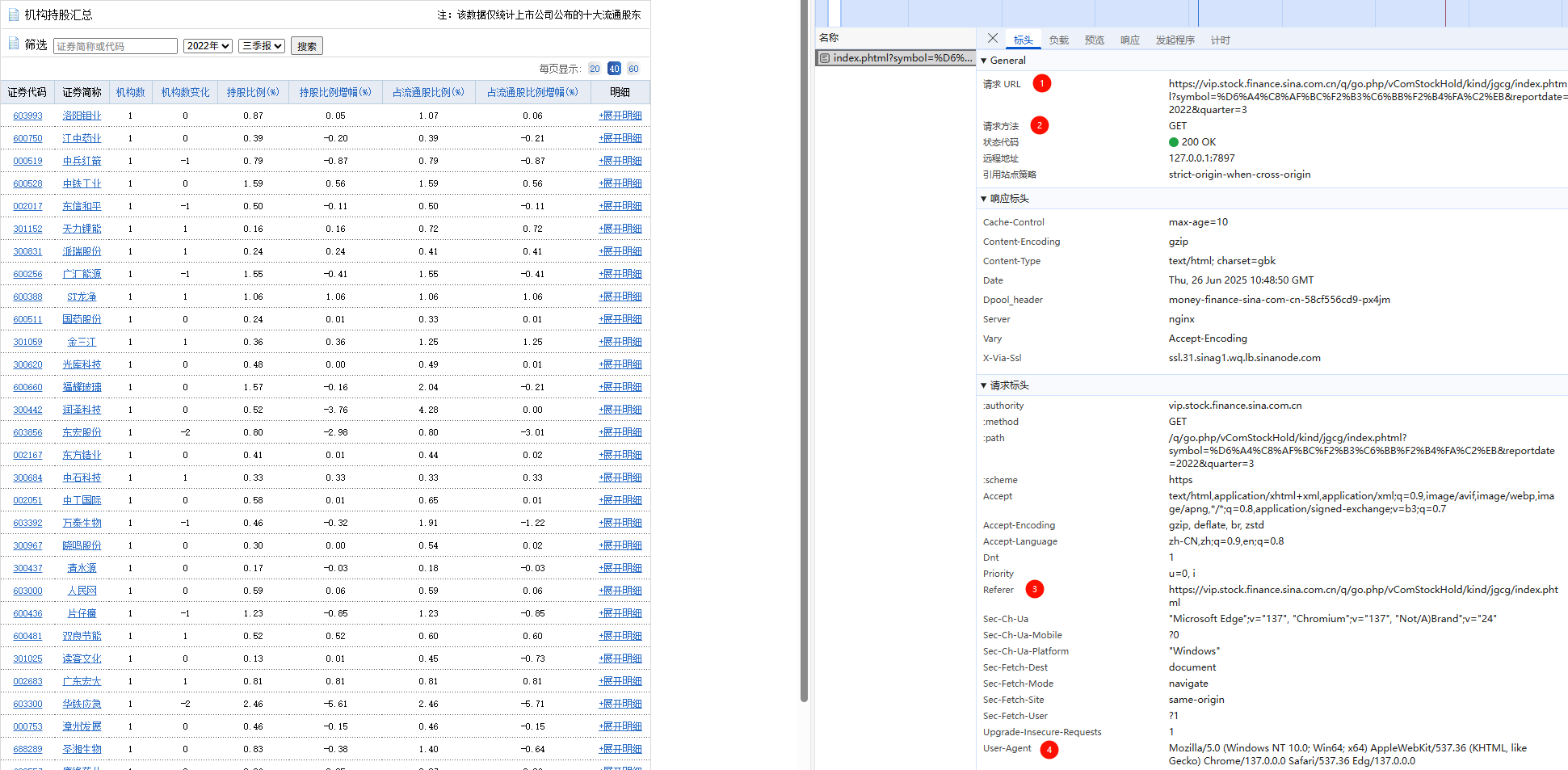
构造代码
import requests
url = r"https://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml?symbol=%D6%A4%C8%AF%BC%F2%B3%C6%BB%F2%B4%FA%C2%EB&reportdate=2022&quarter=3"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml?symbol=%D6%A4%C8%AF%BC%F2%B3%C6%BB%F2%B4%FA%C2%EB&reportdate=2022&quarter=3",
}
session = requests.Session()
resp = session.get(url=url, headers=headers)
resp结果如下,完成任务
解析代码
获取表头
from bs4 import BeautifulSoup
soup = BeautifulSoup(resp.text, "html.parser")
stock_table = soup.find_all(class_='list_table')[0]
stock_list = stock_table.find_all('tr')
stock_header = stock_list[0].find_all('td')
stock_header_list = []
for i in stock_header:
# print(i.text)
stock_header_list.append(i.text)
print(stock_header_list)
"""
['证券代码', '证券简称', '机构数', '机构数变化', '持股比例(%)', '持股比例增幅(%)', '占流通股比例(%)', '占流通股比例增幅(%)', '明细']
"""
获取表内容
body_list = []
for i in stock_list[1:]:
temp_body = i.find_all("td")
temp_list = []
for j in temp_body:
# print(j.text)
if "\n" not in j.text:
temp_list.append(j.text)
if len(temp_list) > 0:
body_list.append(temp_list)
print(body_list)
"""
[['603993', '洛阳钼业', '1', '0', '0.87', '0.05', '1.07', '0.06', '+展开明细'], ['600750', '江中药业', '1', '0', '0.39', '-0.20', '0.39', '-0.21', '+展开明细']...
"""
写入文件,明细那一列没什么用给他扔了
import pandas as pd
df = pd.DataFrame(body_list, columns=stock_header_list)
df = df.drop(['明细'], axis=1)
df.to_csv(
"stock.csv",
index=False,
header=True,
)
最终结果如下

二、爬取北京空气质量指数
https://www.air-level.com/
以北京为例,其他城市只需要换一下url就好
观察网页
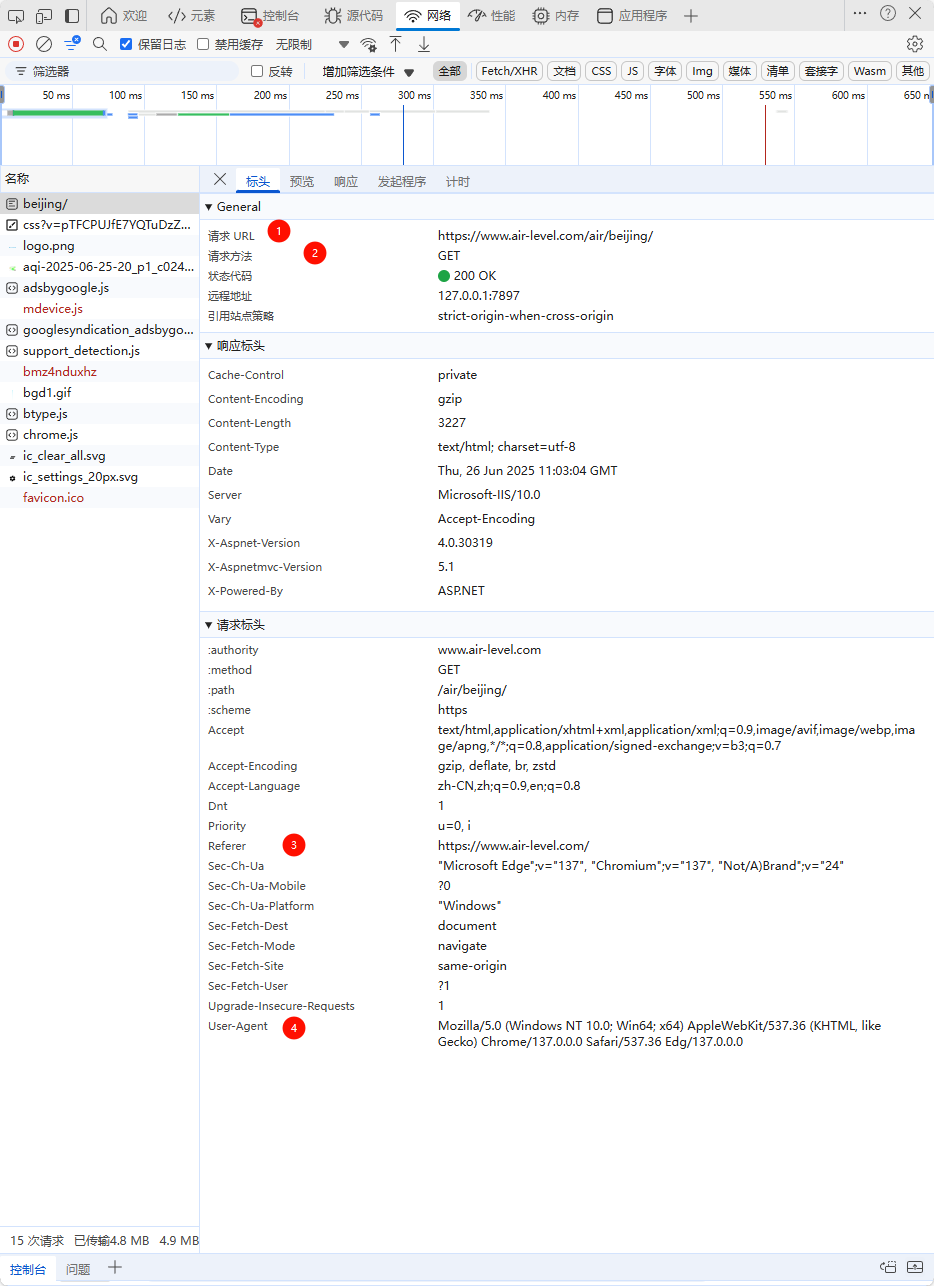
构造代码
import requests
url = r"https://www.air-level.com/air/beijing/"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://www.air-level.com/air/beijing/",
}
session = requests.Session()
resp = session.get(url=url, headers=headers)
print(resp.text)
结果如下
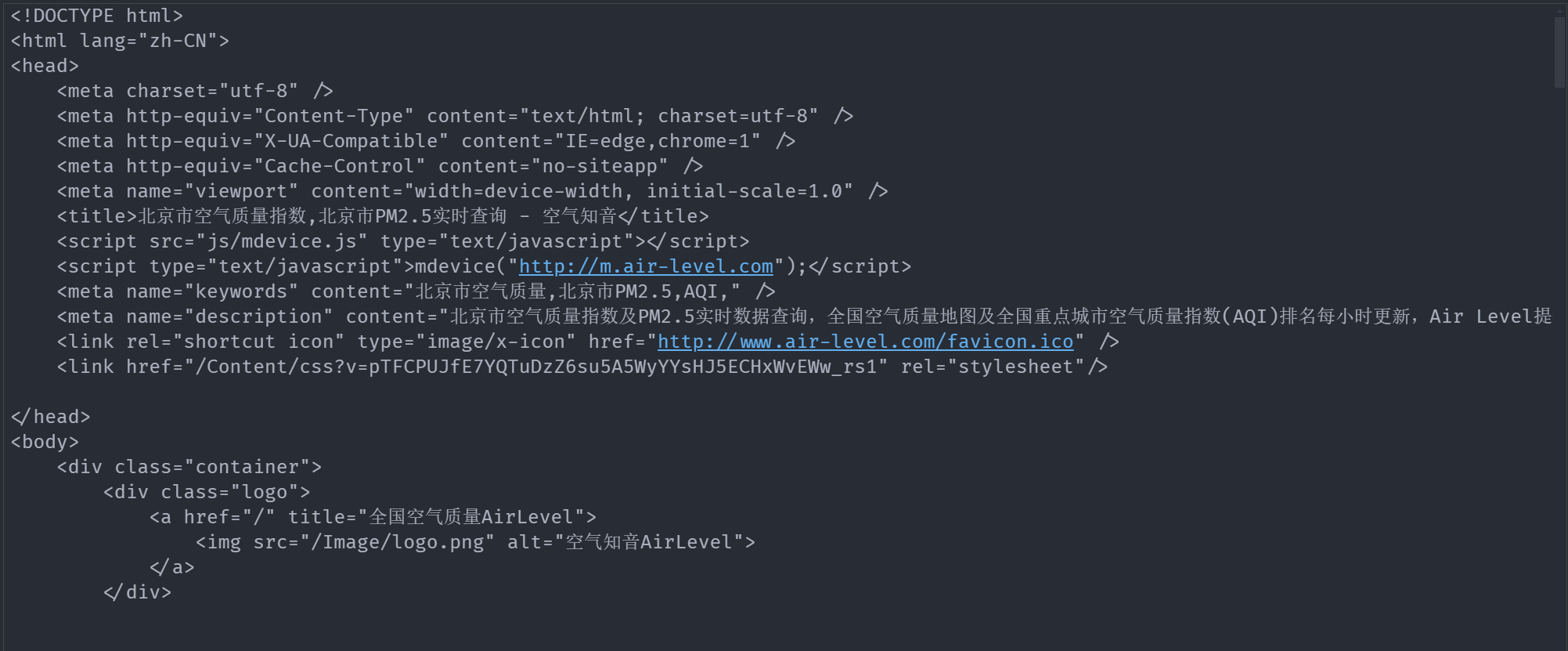
解析代码
获取表头
from bs4 import BeautifulSoup
soup = BeautifulSoup(resp.text, "html.parser")
air_table = soup.find_all(class_="table text-center")[0]
air_list = air_table.find_all("tr")
# print(air_list)
air_header = air_list[0]
# print(air_header)
air_header_list = []
for i in air_header:
# print(i.text)
if '\n' not in i.text:
air_header_list.append(i.text)
print(air_header_list)
"""
['监测站', 'AQI', '空气质量等级', 'PM2.5', 'PM10', '首要污染物']
"""
获取数据
body_list = []
for i in air_list[1:]:
temp_body = i.find_all("td")
temp_list = []
for j in temp_body:
#print(j.text)
temp_list.append(j.text)
if len(temp_list) > 0:
body_list.append(temp_list)
print(body_list)
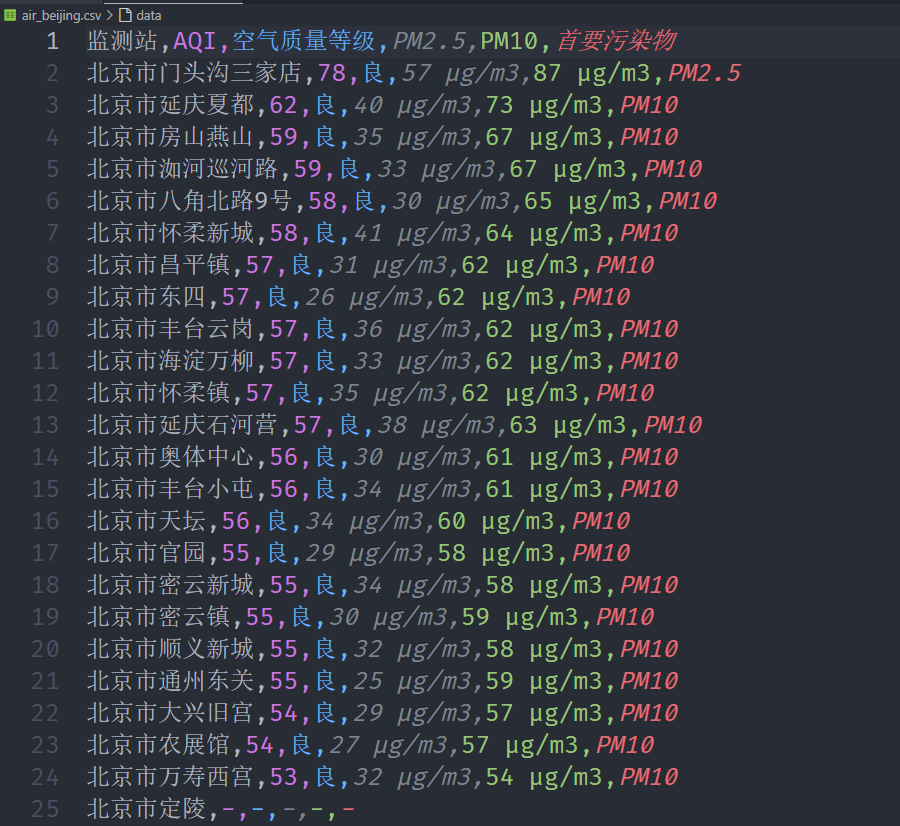
"""
[['北京市门头沟三家店', '78', '良', '57 μg/m3', '87 μg/m3', 'PM2.5'], ['北京市延庆夏都', '62', '良', '40 μg/m3', '73 μg/m3', 'PM10'],...
"""
最后把结果写入文件
import pandas as pd
df = pd.DataFrame(body_list, columns=air_header_list)
df.to_csv(
"air_beijing.csv",
index=False,
header=True,
)
结果令人满意
三、爬取北京2022年每天天气
观察网页
https://tianqi.2345.com/today-54511.htm
实际需要的信息:
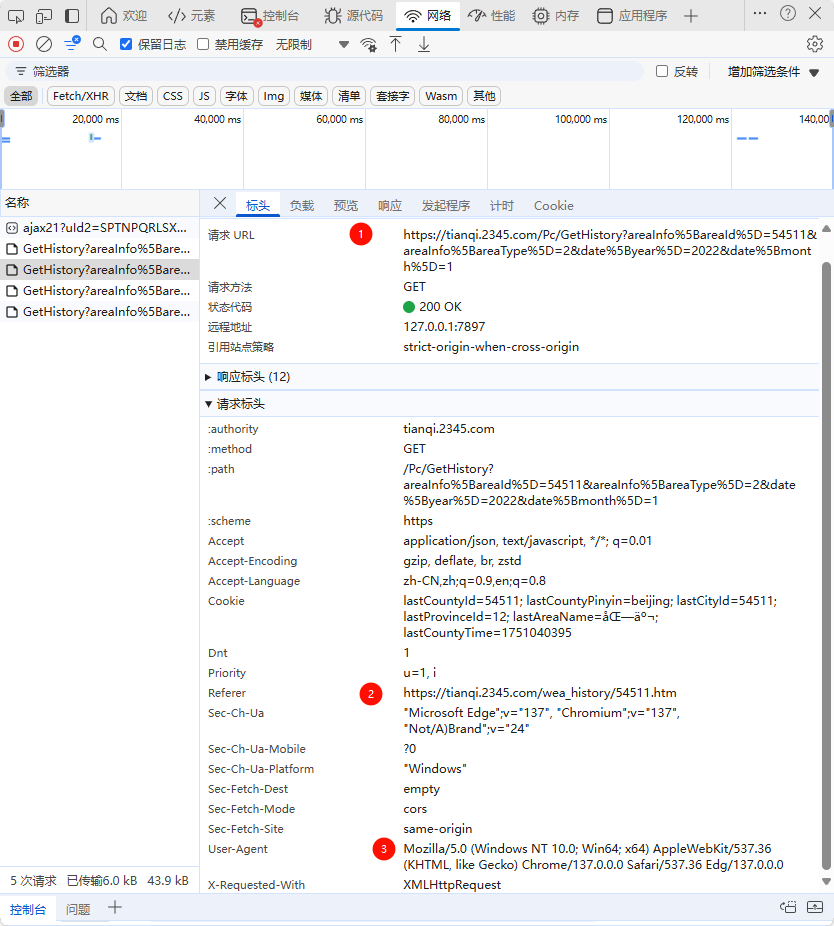
构造代码
以1月份为例,2到12月只需要把data[month]分别改为2到12即可
import requests
url = r"https://tianqi.2345.com/Pc/GetHistory"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://tianqi.2345.com",
}
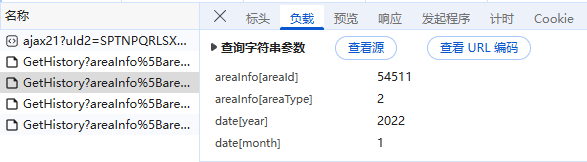
params = {
"areaInfo[areaId]": "54511",
"areaInfo[areaType]": "2",
"date[year]": "2022",
"date[month]": "1",
}
session = requests.Session()
resp = session.get(url=url, headers=headers,params=params)
我们实际需要解析的部分是data
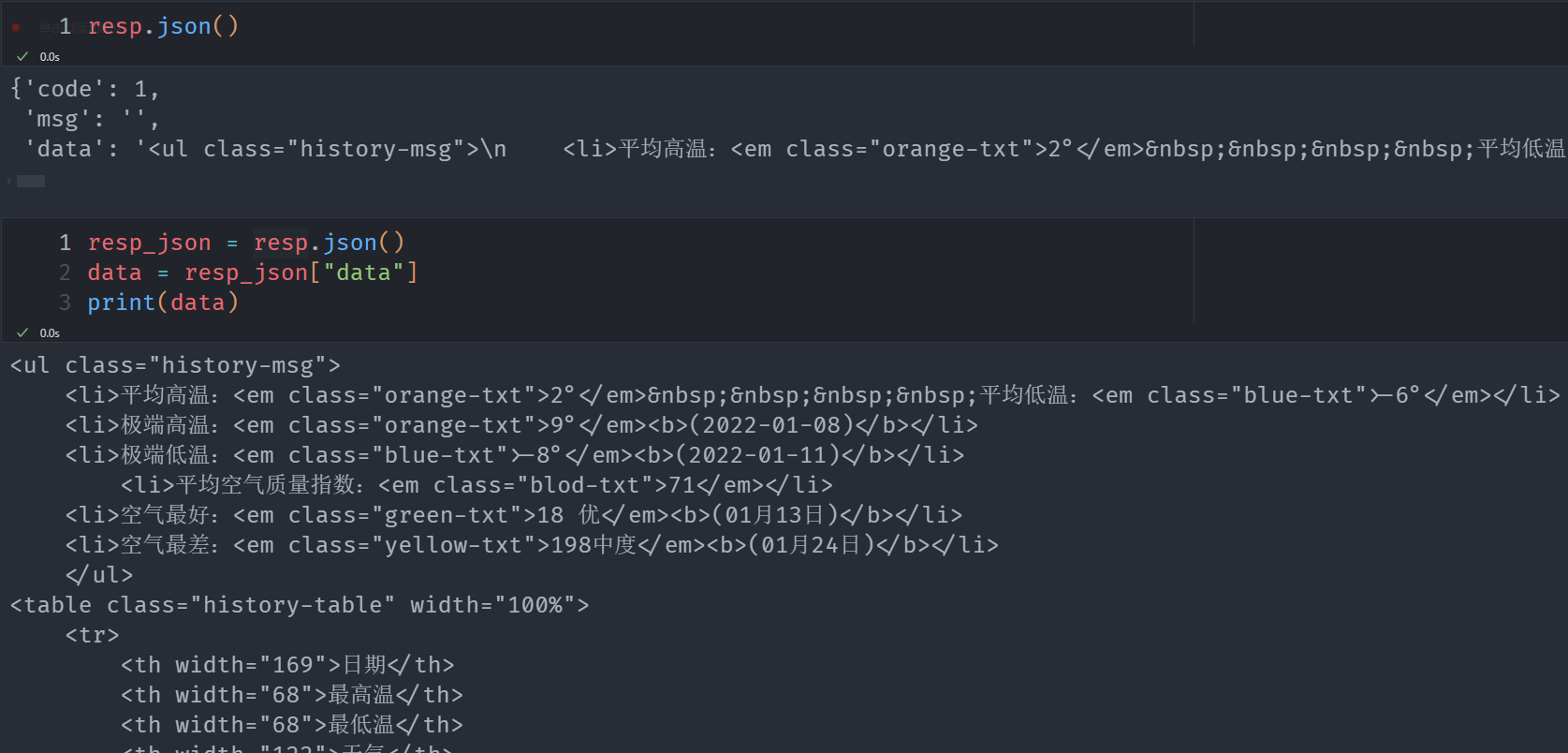
解析代码
用bs4进行解析
from bs4 import BeautifulSoup
resp_json = resp.json()
data = resp_json["data"]
soup = BeautifulSoup(data, "html.parser")
print(soup)
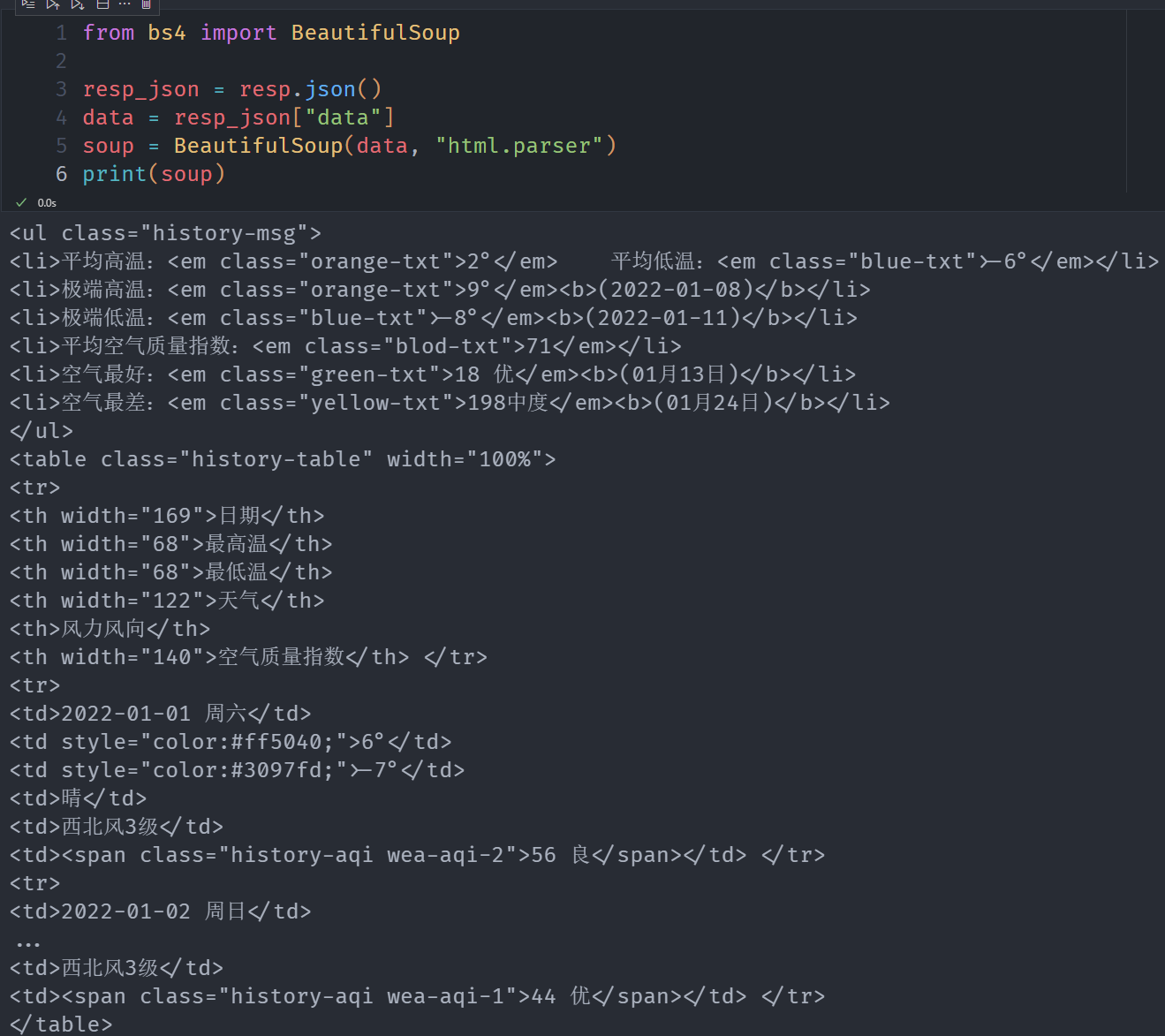
构造表头
daily_info = soup.find_all("tr")
header_list = [i.text.strip() for i in daily_info[0].find_all("th")]
header_list
"""
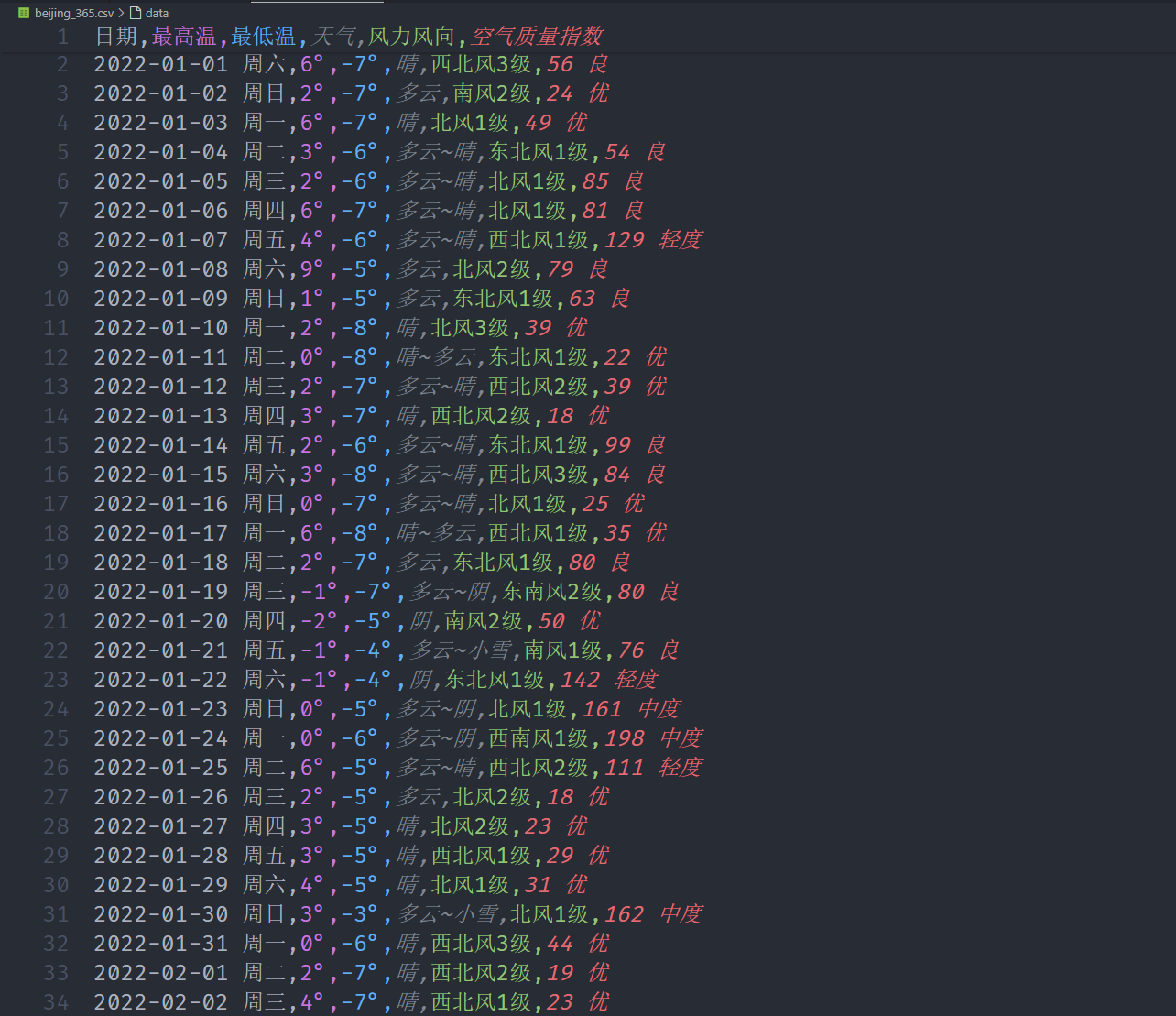
['日期', '最高温', '最低温', '天气', '风力风向', '空气质量指数']
"""
尝试提取数据
for i in daily_info[1:3]:
for j in i.find_all('td'):
print(j.get_text().strip())
"""
2022-01-01 周六
6°
-7°
晴
西北风3级
56 良
2022-01-02 周日
2°
-7°
多云
南风2级
24 优
"""
构建数据
for i in daily_info[1:]:
temp_list = []
for j in i.find_all("td"):
temp_list.append(j.get_text().strip())
print(temp_list)
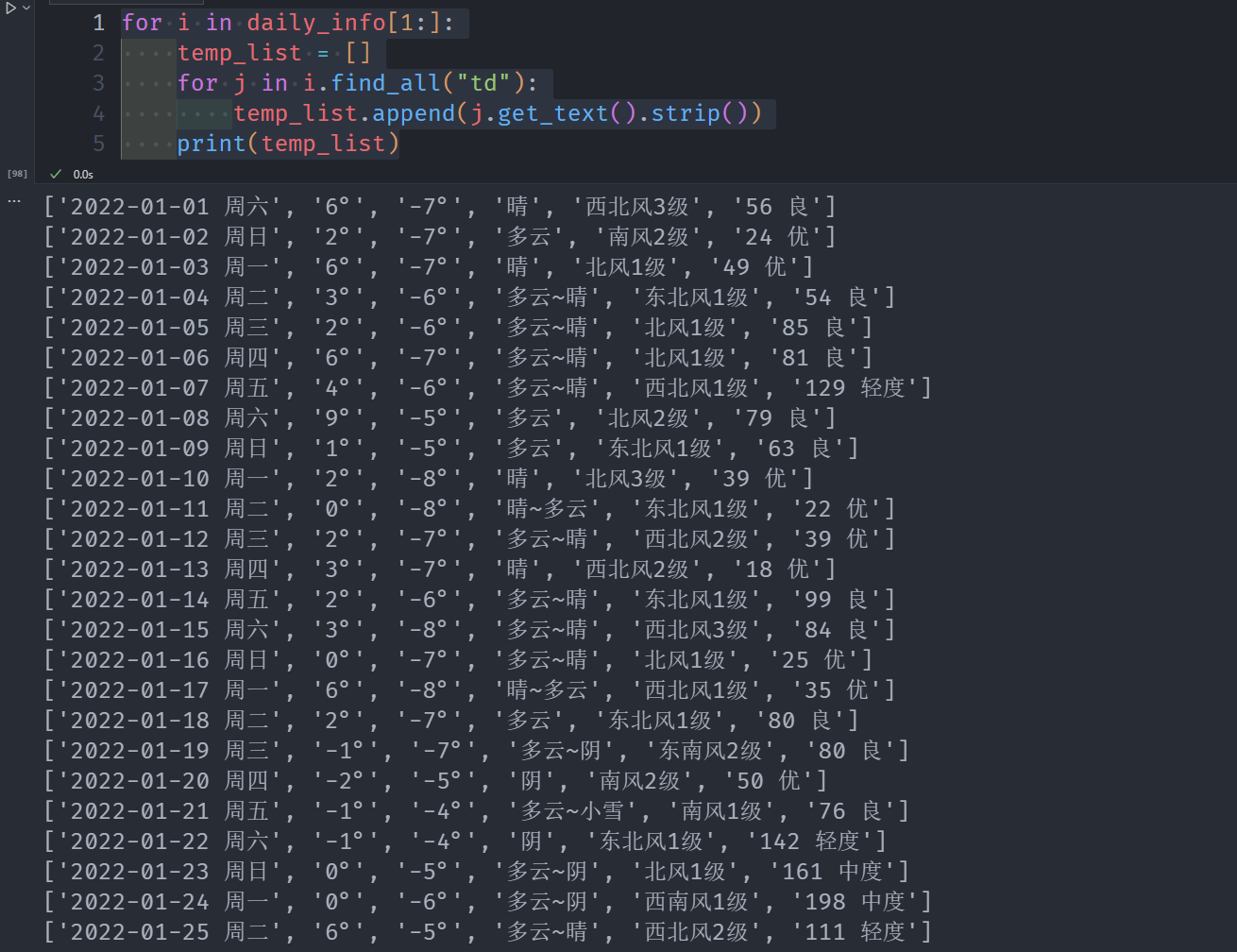
接下来把他们封装为一个函数,输入月份,输出月列表
import requests
import time
from bs4 import BeautifulSoup
def get_month_weather_list(month):
url = r"https://tianqi.2345.com/Pc/GetHistory"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://tianqi.2345.com",
}
params = {
"areaInfo[areaId]": "54511",
"areaInfo[areaType]": "2",
"date[year]": "2022",
"date[month]": month,
}
session = requests.Session()
resp = session.get(url=url, headers=headers, params=params)
resp_json = resp.json()
data = resp_json["data"]
soup = BeautifulSoup(data, "html.parser")
daily_info = soup.find_all("tr")
header_list = [i.text.strip() for i in daily_info[0].find_all("th")]
month_info = []
month_info.append(header_list)
for i in daily_info[1:]:
temp_list = []
for j in i.find_all("td"):
temp_list.append(j.get_text().strip())
month_info.append(temp_list)
time.sleep(3)
return month_info
beijing_weather = []
for i in range(1, 13):
month_info = get_month_weather_list(i)
beijing_weather.append(month_info)
print(month_info)
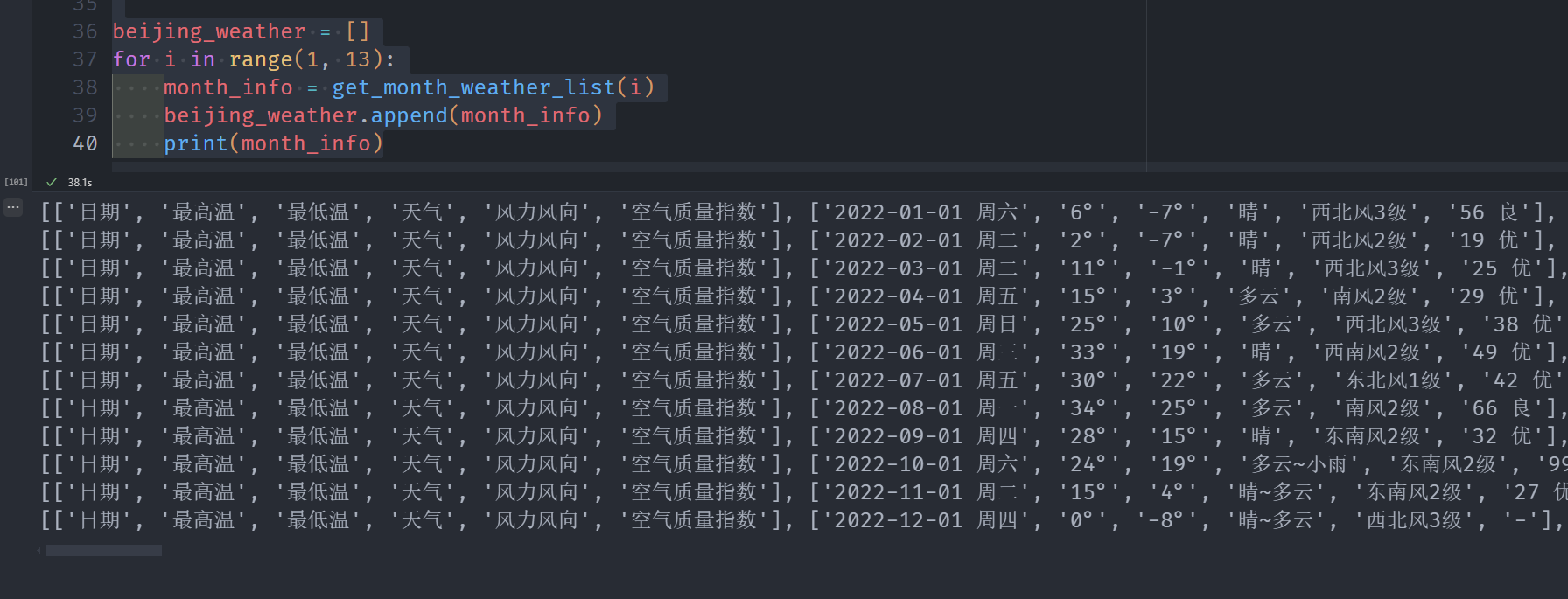
如果要爬取其他地区,只需要简单的修改地区名称和对应的id就好
最后整合到一个csv
import pandas as pd
csv_header = beijing_weather[0][0] # 第一个月的第一行
data_list = []
for month in beijing_weather:
for day in month[1:]:
data_list.append(day)
df = pd.DataFrame(data_list, columns=csv_header)
df.to_csv('beijing_365.csv', index=False)
成功拿下!
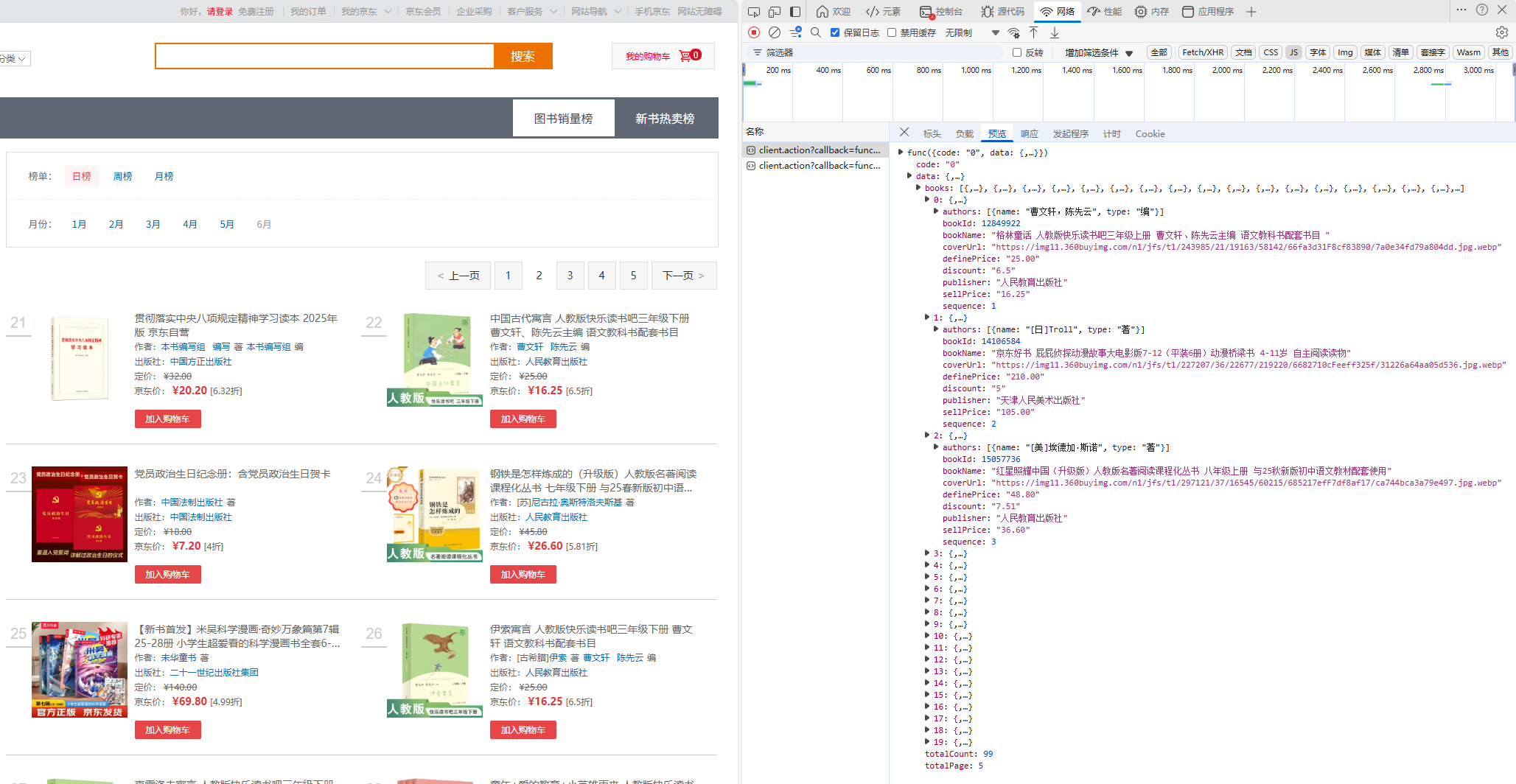
四、爬取京东图书销量榜日榜
观察网页
观察一下需要爬取的内容在哪里
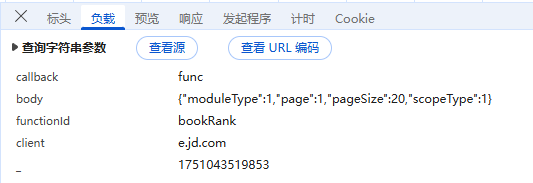
构造代码
import requests
url = r"https://gw-e.jd.com/client.action"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://book.jd.com/",
}
params = {
"callback": "func",
"body": '{"moduleType":1,"page":1,"pageSize":20,"scopeType":1}',
"functionId": "bookRank",
"client": "e.jd.com",
"_": "1751043519853",
}
session = requests.Session()
resp = session.get(url=url, headers=headers, params=params)
通过格式化一下resp能得到需要解析的部分
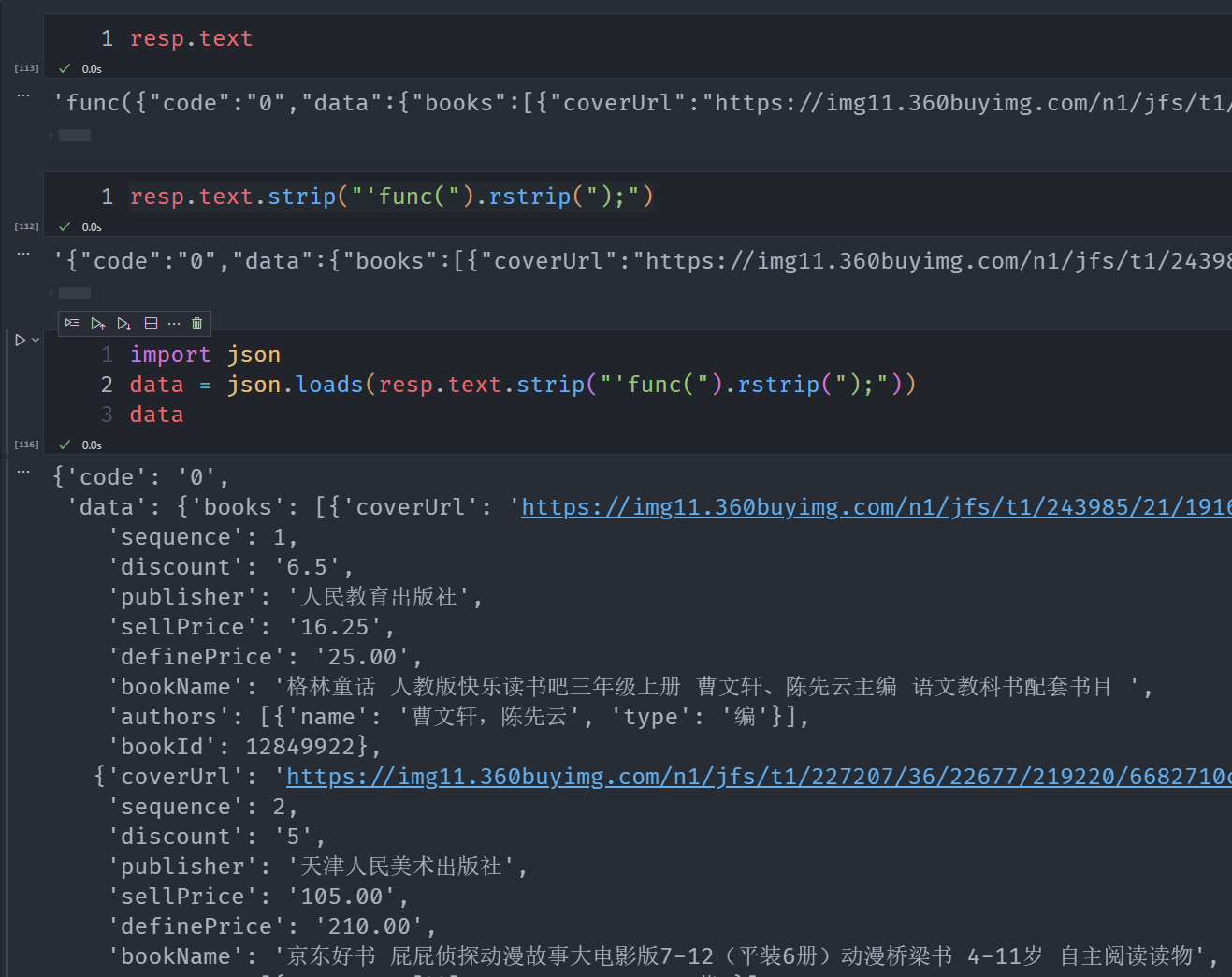
解析代码
既然直接返回了json我们就不需要bs4解析了。直接提取需要的数据
book_list = []
for book in data["data"]['books']:
book_info = {
"排名": book.get("sequence", "未知"),
"书名": book.get("bookName", "未知"),
# "封面URL": book.get("coverUrl", "无"),
"出版社": book.get("publisher", "未知"),
"折扣": book.get("discount", "无") + "折",
"原价": f"{float(book.get('definePrice', 0)):0.2f}元",
"售价": f"{float(book.get('sellPrice', 0)):0.2f}元",
"作者": "",
}
authors = book.get("authors", [])
if authors:
book_info['作者'] = authors[0].get("name", "未知")
else:
book_info['作者'] = "未知"
book_list.append(book_info)
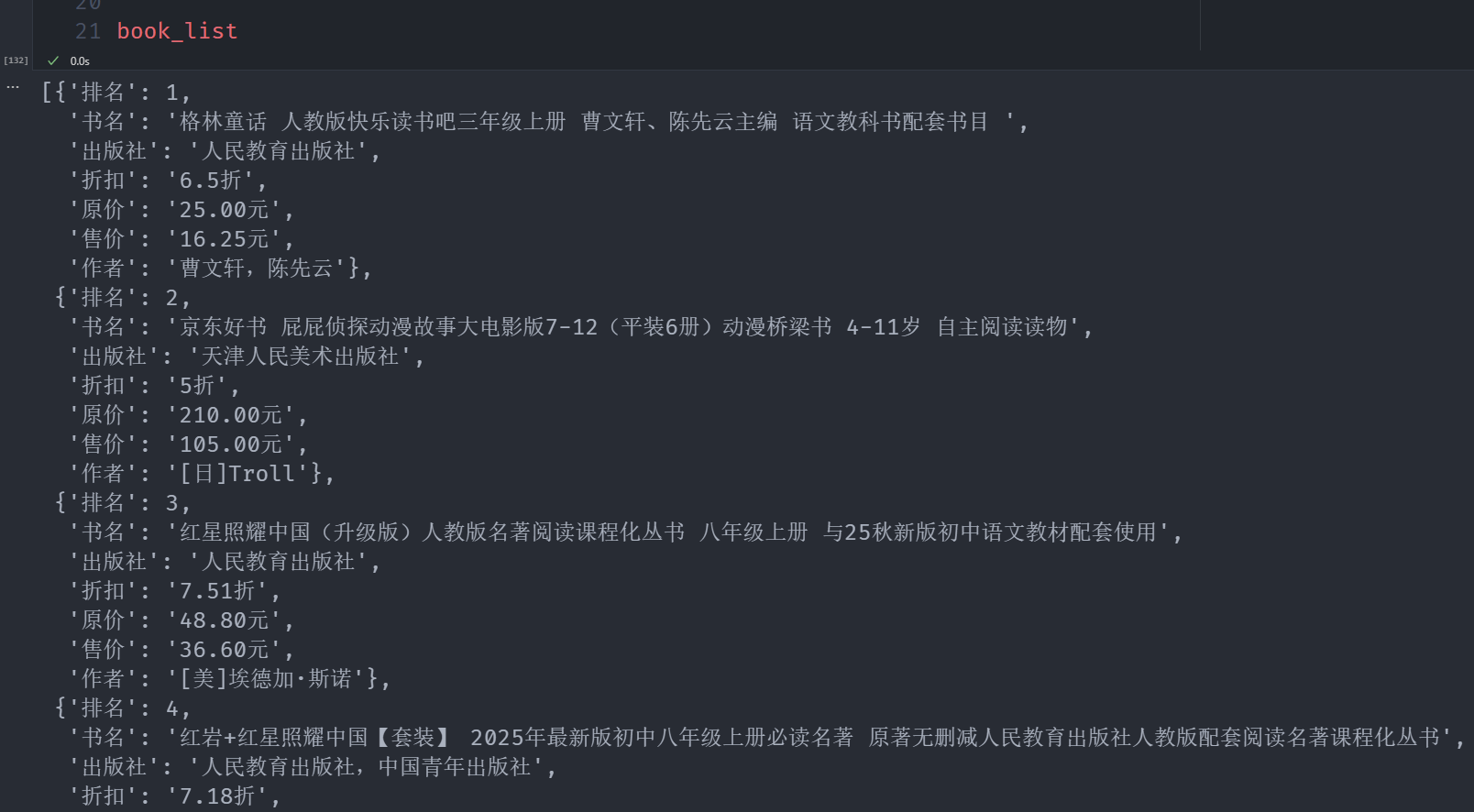
接下来还是封装成一个函数就好,然后发现,_参数对应的其实是时间戳。我们需要手动构造
import datetime
dt = datetime.datetime.fromtimestamp(time.time())
print(dt)
timestamp = str(int(dt.timestamp() * 1000))
print(timestamp)
"""
2025-06-28 01:27:33.214367
1751045253214
"""
然后注意下转义json就好。其他没有太复杂的地方
最终完整代码如下
import requests
import json
import time
import datetime
import pandas as pd
def create_timestamp():
dt = datetime.datetime.fromtimestamp(time.time())
timestamp = str(int(dt.timestamp() * 1000))
return timestamp
def get_page_info(page_num):
url = r"https://gw-e.jd.com/client.action"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://book.jd.com/",
}
timestamp = create_timestamp()
body_str = json.dumps(
{
"moduleType": 1,
"page": str(page_num),
"pageSize": 20,
"scopeType": 1,
}
)
params = {
"callback": "func",
"body": body_str,
"functionId": "bookRank",
"client": "e.jd.com",
"_": timestamp,
}
session = requests.Session()
resp = session.get(url=url, headers=headers, params=params)
return resp
def format_data(resp):
data = json.loads(resp.text.strip("'func(").rstrip(");"))
book_list = []
for book in data["data"]["books"]:
book_info = {
"排名": book.get("sequence", "未知"),
"书名": book.get("bookName", "未知").split(" ")[0],
# "封面URL": book.get("coverUrl", "无"),
"出版社": book.get("publisher", "未知"),
"折扣": book.get("discount", "无") + "折",
"原价": f"{float(book.get('definePrice', 0)):0.2f}元",
"售价": f"{float(book.get('sellPrice', 0)):0.2f}元",
"作者": "",
}
authors = book.get("authors", [])
if authors:
book_info["作者"] = authors[0].get("name", "未知")
else:
book_info["作者"] = "未知"
book_list.append(book_info)
return book_list
def save_data(book_list):
df = pd.DataFrame(book_list)
df.to_csv("jd_book_rank.csv", index=False)
print("Done")
def main():
book_list = []
for page_num in range(1, 6):
resp = get_page_info(page_num)
time.sleep(3)
book_list.extend(format_data(resp))
save_data(book_list)
if __name__ == "__main__":
main()

有些书名可能还需要进一步处理,不过这些作为爬取下来的初步内容已经是绰绰有余了。
五、爬取4K风景图片
观察网页
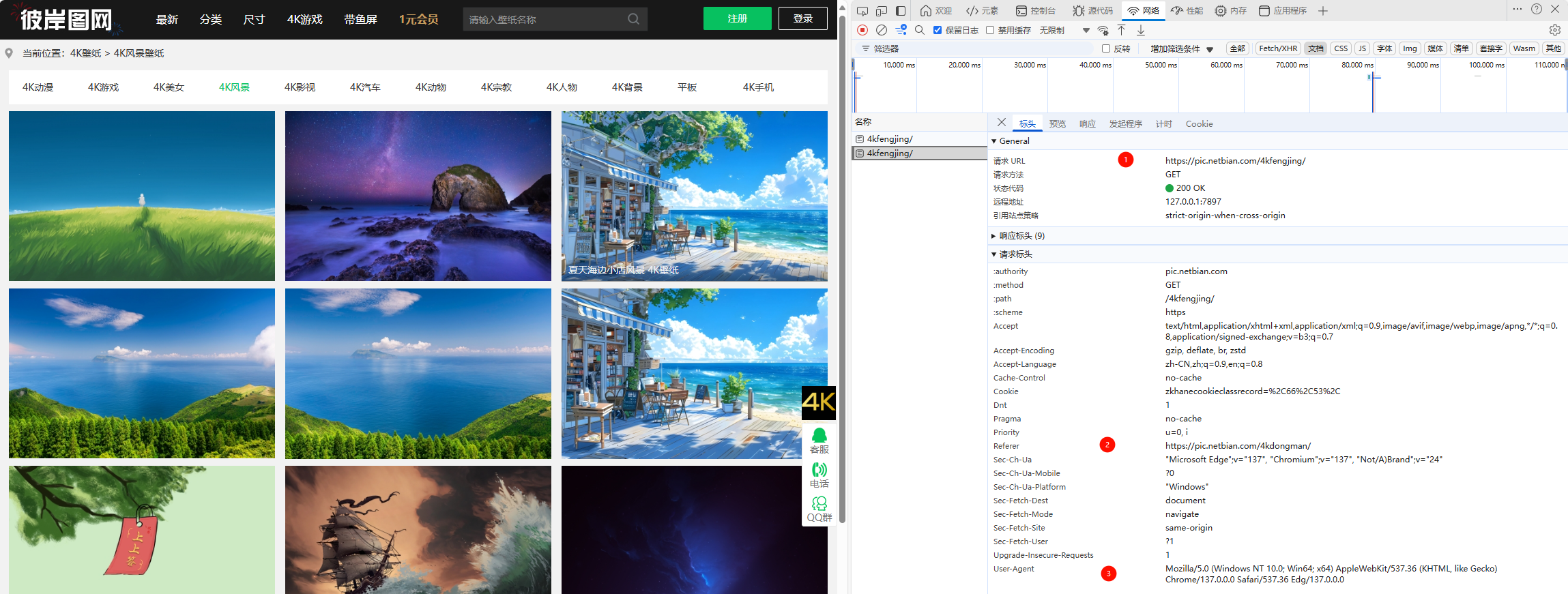
构造代码
import requests
url = r"https://pic.netbian.com/4kfengjing/"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://pic.netbian.com/4kdongman/",
}
session = requests.Session()
resp = session.get(url=url, headers=headers)
非常的简单
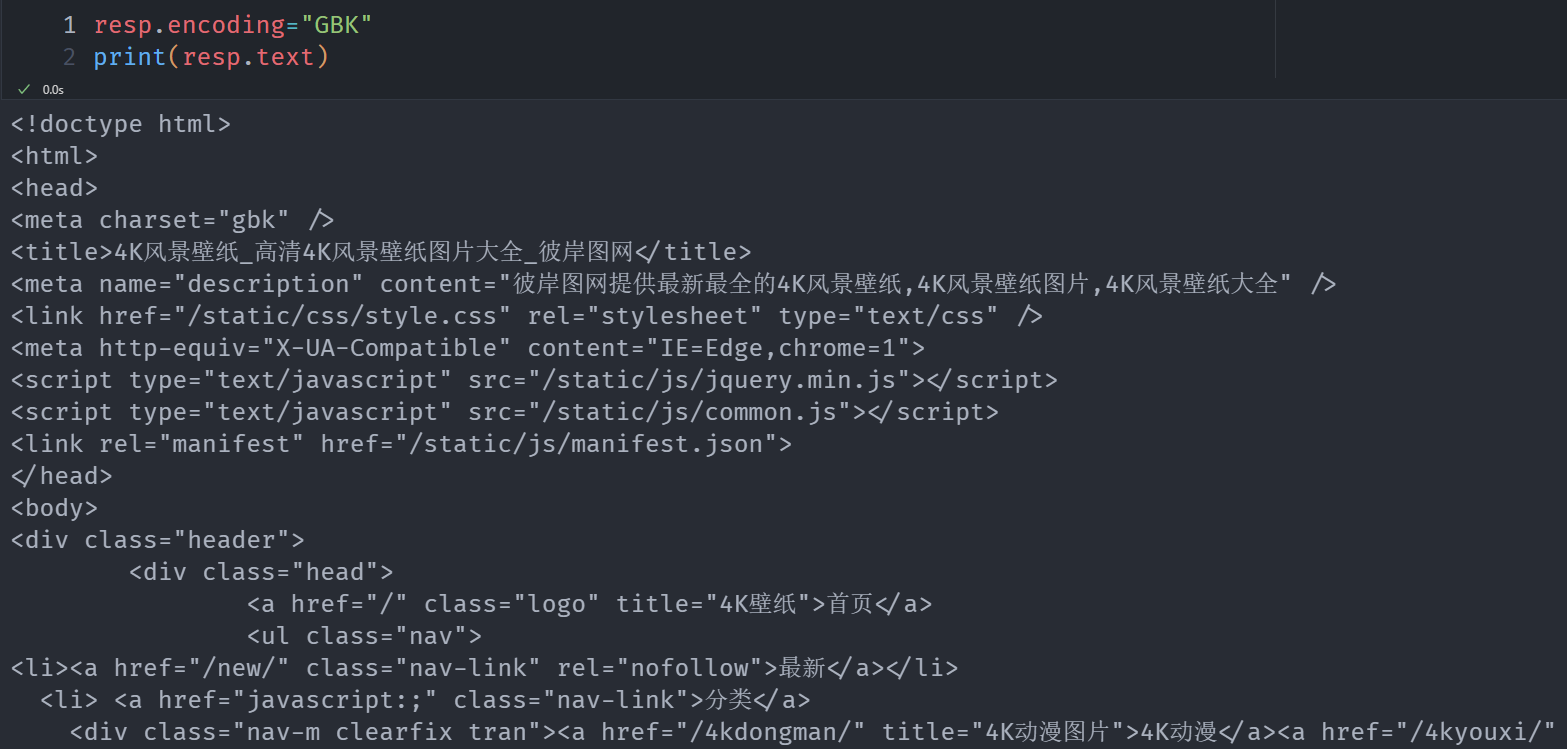
解析代码
from bs4 import BeautifulSoup
soup = BeautifulSoup(resp.text, "html.parser")
pic_list = soup.find_all("img")
pic_list
不难看出,除了最后三个之外剩下的就是我们需要的
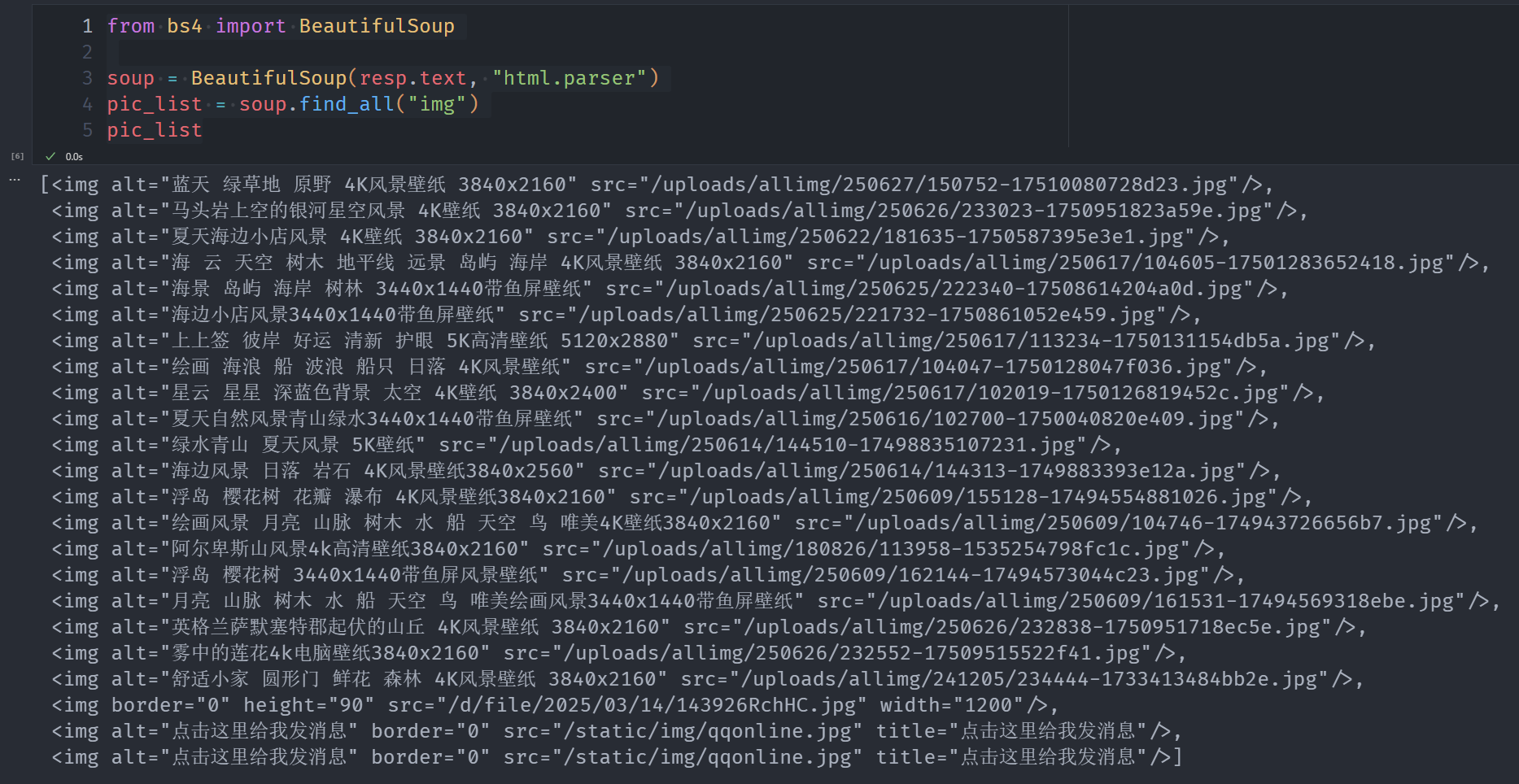
这东西我们用正则表达式分别提取标题和图片地址就好
import re
from turtle import title
for pic in pic_list[:-3]:
title = re.findall(r"<img alt=\"(.*?)\d", str(pic))[0]
link = "https://pic.netbian.com"+re.findall(r"src=\"(.*?)\"", str(pic))[0]
print(title, link)
with open(f"img/{title}.jpg", "wb") as f:
f.write(requests.get(link).content)
整体还是比较简单的。
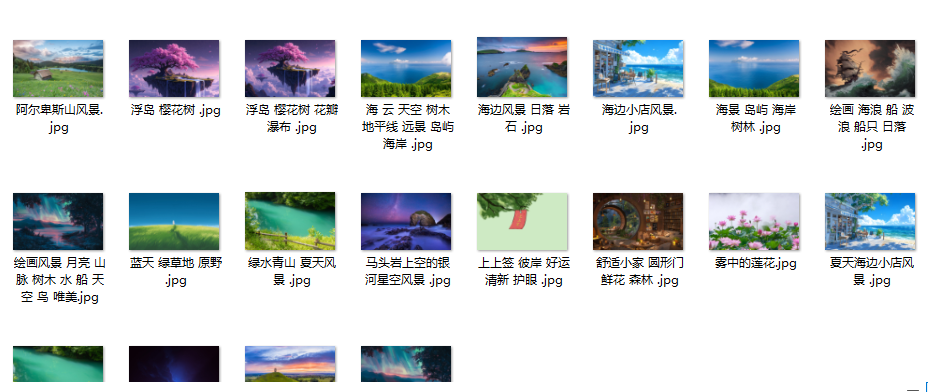
完整代码如下
import requests
import re
from bs4 import BeautifulSoup
def download_images():
url = r"https://pic.netbian.com/4kfengjing/"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"Referer": r"https://pic.netbian.com/4kdongman/",
}
session = requests.Session()
resp = session.get(url=url, headers=headers)
resp.encoding = "GBK"
soup = BeautifulSoup(resp.text, "html.parser")
pic_list = soup.find_all("img")
def process_image(pic):
title = re.findall(r"<img alt=\"(.*?)\d", str(pic))[0]
link = "https://pic.netbian.com" + re.findall(r"src=\"(.*?)\"", str(pic))[0]
print(title, link)
with open(f"img/{title}.jpg", "wb") as f:
f.write(requests.get(link).content)
for pic in pic_list[:-3]:
process_image(pic)
if __name__ == '__main__':
download_images()
完结🎉

















 2755
2755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









