



书接上回 零基础网络爬虫技术(二)
废话不多说.直接来实战讲解
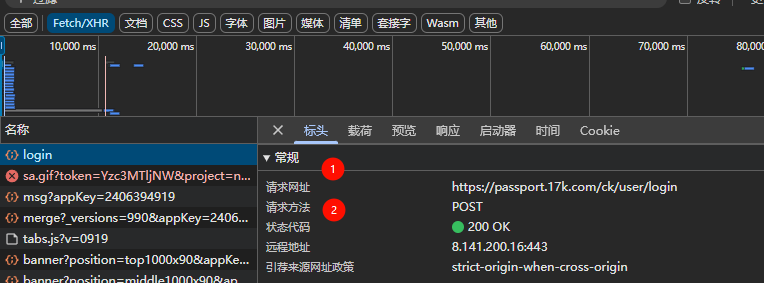
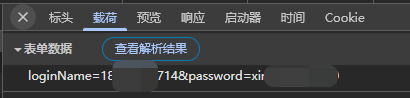
尝试抓取一下登录方法,发现采用的是post自己的信息,并且图2中可以看到需要post什么东西
import os
import requests
import dotenv
dotenv.load_dotenv()
# 建⽴session(会话)
session = requests.session()
# 准备⽤户名密码
data = {
"loginName": os.getenv("USERNAME"), # 填入账号
"password": os.getenv("PASSWORD"), # 填入密码
}
# UA
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36"
}
# 1. 登录
url = "https://passport.17k.com/ck/user/login"
resp = session.post(url, data=data, headers=headers)
print(resp.text)
print(resp.cookies)
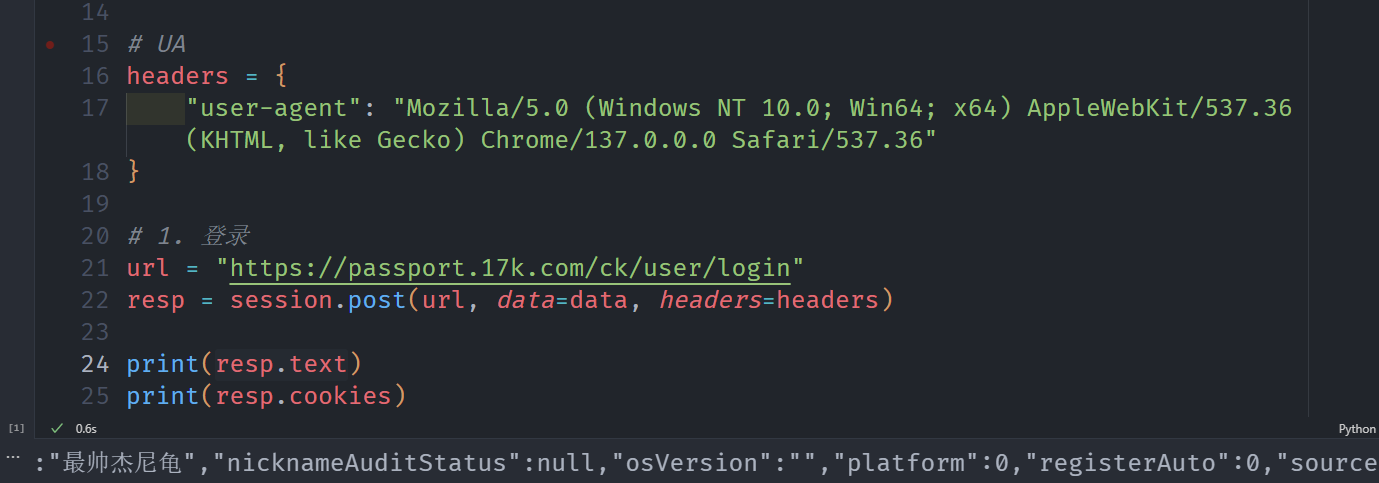
成功登录!
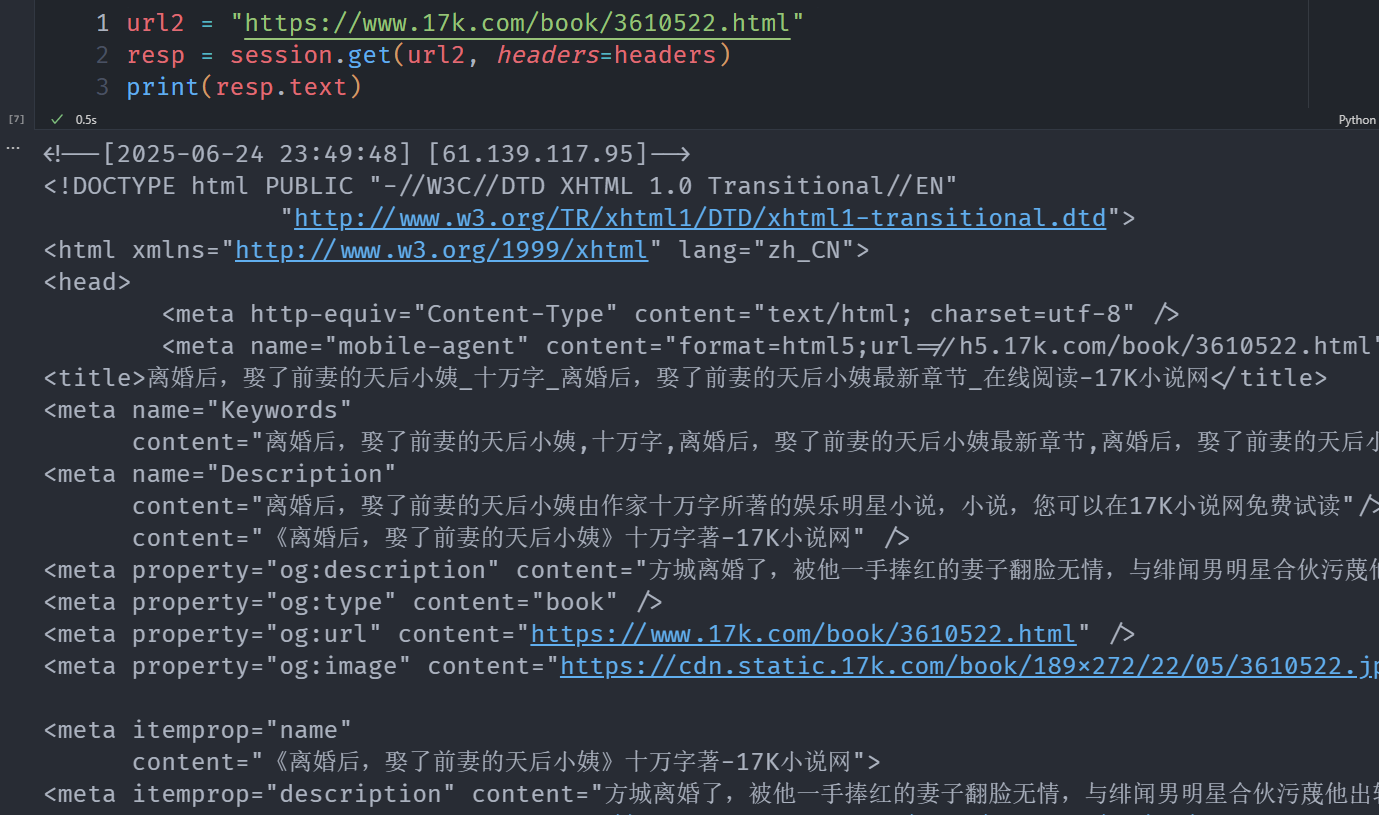
接下来只需要不停的用session.get ,就会一直带着cookies信息,不需要我们手动重复输入.接下来就可以为所欲为,为所欲为了.例如随便点击一本书,就可以拿下小姨子了.
url2 = "https://www.17k.com/book/3610522.html"
resp = session.get(url2, headers=headers)
print(resp.text)
和requests.get相比,二者差别如下,可以优先考虑``
| 特性 | requests.get | requests.Session.get |
|---|---|---|
| 连接方式 | 每次调用创建新连接 | 复用同一个会话(持久连接) |
| 性能 | 较低(每次需建立/关闭连接) | 较高(复用连接,减少开销) |
| Cookie 管理 | 不自动处理 Cookie | 自动处理 Cookie(会话级存储) |
| Headers 设置 | 每次请求需单独设置 | 可在 Session 中统一设置默认 Headers |
| 代理设置 | 每次请求需单独设置 | 可在 Session 中统一设置代理 |
| 适用场景 | 简单、独立的请求 | 需要复用连接或保持状态的多次请求 |
| 示例代码 | requests.get(url) | s = requests.Session(); s.get(url) |
接下来,实战一下爬虫下载视频
简单查看一下视频的实际网址
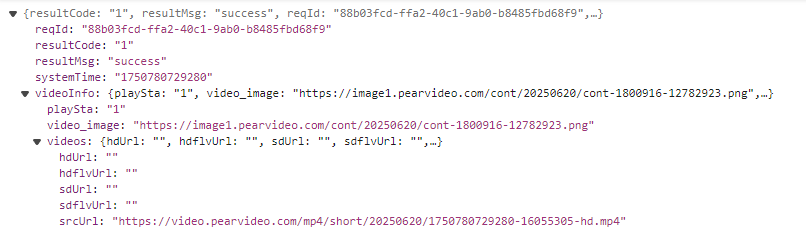
刷新一下再次查看.发现明显出现了不同
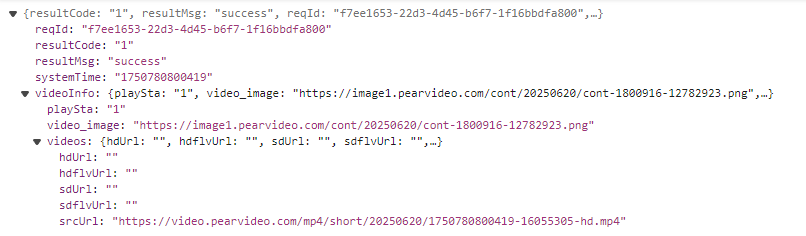
显然,这个175就是systemTime,然后看看还有没有其他需要注意的,在这里有Referer,服务器可以检查 Referer,确保请求来自允许的域名(例如图片、视频等资源只允许从自己的网站加载,防止其他网站直接盗用)
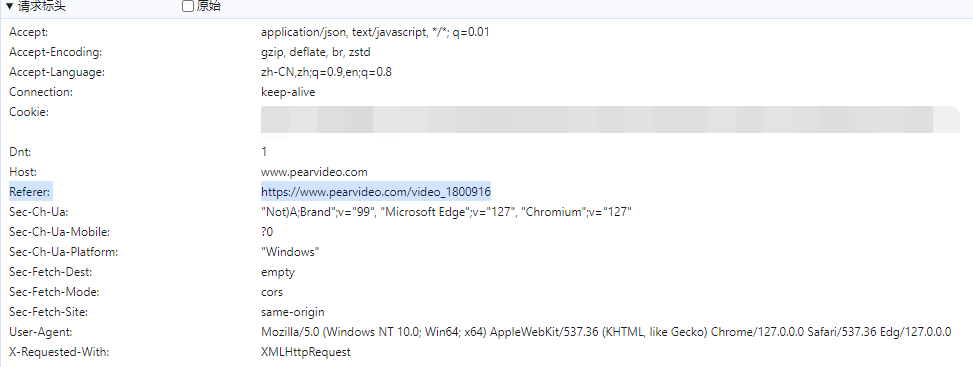
在 requests 库中,可以通过 headers 手动设置 Referer:
import requests
headers = {
"Referer": "https://www.page.com/source-page",
}
response = requests.get("https://target.com", headers=headers)
Session里面自然也可以
session = requests.Session()
session.headers.update({"Referer": "https://www.page.com"})
response = session.get("https://target.com")
接下来我们尝试一下
import requests
import random
# 拉取视频的网址
url = "https://www.pearvideo.com/video_1800916"
contId = url.split("_")[1]
# print(contId)
random_num = random.random()
mrd = "{0:.17f}".format(random_num)
# 发现就是个17位的随机数,暂时.
videoStatusUrl = rf"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd={str(mrd)}"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
# 防盗链: 溯源, 当前本次请求的上一级是谁
# 防盗链,意义:本次请求是由哪个url产⽣的
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()
# print(dic)
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}") # 拼接真正的视频url地址
# print(srcUrl)
# 下载视频
with open("a.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
轻松拿下,成功下载视频. 一定要注意Referer会把其他的请求给阻挡!

















 1724
1724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









