 Light-Head R-CNN:轻量级检测网络优化
Light-Head R-CNN:轻量级检测网络优化





 文章针对Faster R-CNN与R-FCN网络头部计算量大的问题,提出Light-Head R-CNN进行优化。分析了原网络计算量大的原因,介绍了Light-Head R-CNN的设计,阐述使用的技巧,如设置图像尺寸、平衡损失值等,最后给出了检测性能和速度方面的实验结果。
文章针对Faster R-CNN与R-FCN网络头部计算量大的问题,提出Light-Head R-CNN进行优化。分析了原网络计算量大的原因,介绍了Light-Head R-CNN的设计,阐述使用的技巧,如设置图像尺寸、平衡损失值等,最后给出了检测性能和速度方面的实验结果。
1. 概述
首先分析了Faster R-CNN与R-FCN两个网络为什么计算量巨大的问题,首先对于Faster R-CNN在RoI Pooling之后存在两个全连接层用于目标框的回归及分类,而对于R-FCN是其具有一个巨大的分数图,也就造成了较为庞大的头部结构,致使这两个网络运算速度较慢,即使经过基础网络剪裁,占计算量大头的头部结构仍然计算量巨大。
那么在这篇文章中就针对头部过大的问题进行了针对优化,从而得到了一个轻量级的检测网络头部,使用较少的feature map与较小的R-CNN子网络(池化以及单全连接层),最后的网络在COCO数据集上获得了30.7mmAP,帧率为102FPS。
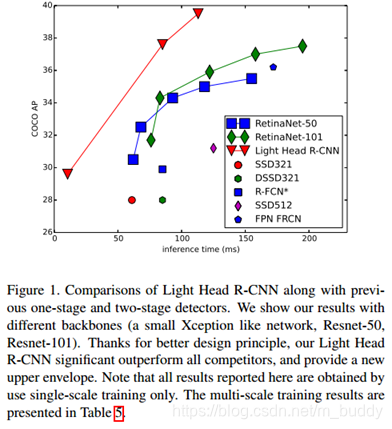
作者在文中说到在RFCN中使用特殊的卷积去减少分值矩阵的维度(原为:classes∗p∗pclasses*p*pclasses∗p∗p)到α∗p∗p\alpha*p*pα∗p∗p,其中α≤10\alpha \le 10α≤10,ppp是池化的尺寸。使用文章的方法去缩小检测头部得到的网络性能与当前的检测网络速度与检测准性能的比较见下图:
2. Light-Head R-CNN设计
首先,直接来看看文章提出的网络结构与Faster R-CNN、R-FCN之间的区别吧。
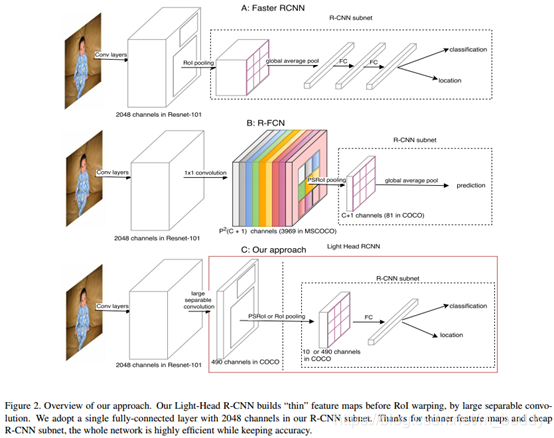
Faster R-CNN网络头部中大量的计算量来自于全连接层,而且每个proposal都会去运算一遍,在proposal量比较大的时候整个计算过程就变得相当耗时。一个思路就是将原有的连接RoI Wraping的全连接替换为全局均值池化替换,但是这样会影响空间定位的性能。对于R-FCN,它在position-sensitive pooling之后直接将预测结果池化,其性能由于没有RoI-wise计算层因而通常不如Faster R-CNN强大。由于R-FCN也存在为RoI Pooling而产生的分数图,这样整个网络也会消耗时间与存储。
文章所讲的Light-Head R-CNN在R-FCN的基础上使用较少的通道数量去减小计算量,在下面的内容里面将会讨论如何创建这样的RoI warping。
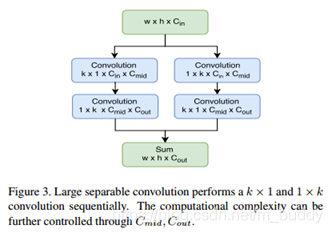
这里对于R-FCN中基础网络C5C_5C5到分支图矩阵使用矩阵分解的形式实现,这里的CoutC_{out}Cout变为10∗p∗p10*p*p10∗p∗p。在文章中后面调大Cmid,kC_{mid},kCmid,k之后性能得到一定的提升。
3. 使用的技巧
3.1 共同基础部分
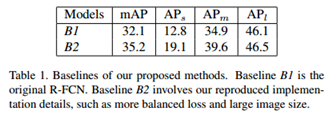
将原有的R-FCN网络使用B1代表,文章的改进方法使用B2代表,文章使用过的方法现在相对原有方法又如何不同:
1)将短边设置为800像素,长边限制在1200像素以内,这只了5个anchor;
2)由于边界框回归的loss小于分类的loss,这里对边界框回归的loss乘以了系数去平衡损失值;
3)在反向传播中选用排序的256个样本进行回传,训练的时候使用2000个RoIs,测试的时候使用1000个RoIs。
最后的结果呢,比原始的方法高了3个点。
3.2 使用较少channel的特征
这里将原有的3969(81∗3∗381*3*381∗3∗3)缩小到490(10∗7∗710*7*710∗7∗7),其中的3和7是池化的尺寸,从而达到缩小计算量,但是也会带来一定的性能损失:
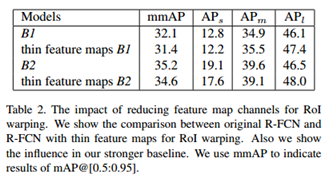
3.3 其它的一些改进
1)将短边提升到800,加大图像的输入尺寸;
2)使用多尺度图像训练,提升了1个点mmPA;
3)使用0.5的阈值替换0.3的NMS阈值,提升了0.6个点mmPA;
4)使用改进的xception基础网络提升网络速度;
4. 实验结果
检测性能方面:
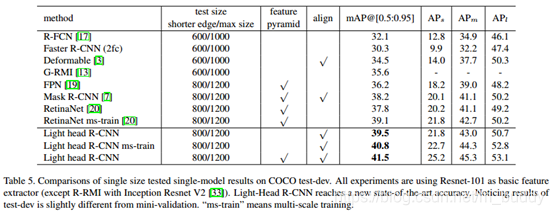
速度方面:
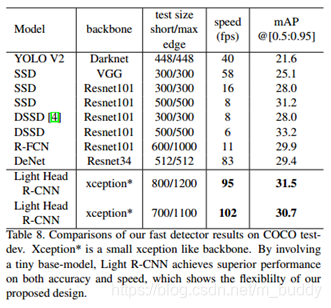

















 2462
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









