




 本文介绍了高斯混合模型(GMM),其中参数通过EM算法求解。详细阐述了EM算法的E步和M步,包括确定隐藏参数、计算响应度、更新模型参数的步骤,并指出在后续博客中将应用GMM于自动化肿瘤分割任务。
本文介绍了高斯混合模型(GMM),其中参数通过EM算法求解。详细阐述了EM算法的E步和M步,包括确定隐藏参数、计算响应度、更新模型参数的步骤,并指出在后续博客中将应用GMM于自动化肿瘤分割任务。
1. 前言
高斯混合模型是使用高斯分布对原始数据进行估计,其中高斯函数的均值μ\muμ和方差σ\sigmaσ以及各个高斯函数分量占的比例α\alphaα这些参数是未知的。对于它们的求解是通过EM算法实现的。
高斯混合模型可以表述为如下的概率分布模型:
P(y∣θ)=∑k=1Kαkϕ(y∣θk)P(y|\theta)=\sum_{k=1}^{K}\alpha_k\phi(y|\theta_k)P(y∣θ)=k=1∑Kαkϕ(y∣θk)
其中,αk\alpha_kαk是系数,αk≥0\alpha_k\ge0αk≥0,∑k=1Kαk=1\sum_{k=1}^K\alpha_k=1∑k=1Kαk=1;ϕ(y∣θk)\phi(y|\theta_k)ϕ(y∣θk)是高斯分布密度,θk=(μk,σk2)\theta_k=(\mu_k,\sigma_k^2)θk=(μk,σk2)
ϕ(y∣θk)=12πσkexp(−(y−μk)22σk2)\phi(y|\theta_k)=\frac{1}{\sqrt{2\pi}\sigma_k}exp(-\frac{(y-\mu_k)^2}{2\sigma_k^2})ϕ(y∣θk)=2πσk1exp(−2σk2(y−μk)2)
称为第K个分模型。
2. 推导
2.1 确定隐藏参数
假设观测数据y1,y2,…,yNy_1,y_2,\dots,y_Ny1,y2,…,yN是由高斯混合模型生成
P(y∣θ)=∑k=1Kαkϕ(y∣θk)P(y|\theta)=\sum_{k=1}^{K}\alpha_k\phi(y|\theta_k)P(y∣θ)=k=1∑Kαkϕ(y∣θk)
其中,参数θ=(α1,α2,…,αk;θ1,θ2,…,θk)\theta=(\alpha_1,\alpha_2,\dots,\alpha_k;\theta_1,\theta_2,\dots,\theta_k)θ=(α1,α2,…,αk;θ1,θ2,…,θk)。是高斯混合模型中直观需要求解的未知变量。但是高斯混合模型中就只有这两类变量是未知的么?
对于观测数据yjy_jyj,j=1,2,…,Nj=1,2,\dots,Nj=1,2,…,N,是这样产生的:首先依据概率αk\alpha_kαk选择第kkk个高斯分布模型ϕ(y∣θk)\phi(y|\theta_k)ϕ(y∣θk);然后依据第kkk个分模型的概率分布ϕ(y∣θk)\phi(y|\theta_k)ϕ(y∣θk)生成观测数据yjy_jyj。这个时候观测数据yjy_jyj,j=1,2,…,Nj=1,2,\dots,Nj=1,2,…,N,是已知的;但是呢,反映观测数据yjy_jyj具体是来自第kkk个分模型的数据是未知的。k=1,2,…,Kk=1,2,\dots,Kk=1,2,…,K,这里以隐变量γjk\gamma_{jk}γjk表示,可以将其定义为:
γjk={1,第j个观测数据来自第k个分模型0,否则
\gamma_{jk}=
\begin{cases}
1, & \text{第$j$个观测数据来自第$k$个分模型} \\
0, & \text{否则}
\end{cases}
γjk={1,0,第j个观测数据来自第k个分模型否则
其中,j=1,2,…,N;k=1,2,…,Kj=1,2,\dots,N;k=1,2,\dots,Kj=1,2,…,N;k=1,2,…,K,显然γjk\gamma_{jk}γjk是属于典型的0-1随机变量。因而完整的观测数据就可以写为:
(yj,γj1,γj2,…,γjK),j=1,2,…,N(y_j, \gamma_{j1},\gamma_{j2},\dots,\gamma_{jK}),j=1,2,\dots,N(yj,γj1,γj2,…,γjK),j=1,2,…,N
2.2 得到似然函数,确定Q函数
于是,可以写出完全数据的似然函数:
P(y,γ∣θ)=∏j=1NP(yj,γj1,γj2,…,γjK)=∏j=1N∏k=1K[αkϕ(yj∣θk)]γjk=∏k=1Kαknk∏j=1N[ϕ(yj∣θk)]γjk=∏k=1Kαknk∏j=1N[12πσkexp(−(y−μk)22σk2)]γjk
\begin{aligned}
P(y,\gamma|\theta) & = \prod_{j=1}^NP(y_j,\gamma_{j1},\gamma_{j2},\dots,\gamma_{jK}) \\
& = \prod_{j=1}^N\prod_{k=1}^K[\alpha_k\phi(y_j|\theta_k)]^{\gamma_{jk}}\\
& =\prod_{k=1}^K\alpha_k^{n_k}\prod_{j=1}^N[\phi(y_j|\theta_k)]^{\gamma_{jk}} \\
& =\prod_{k=1}^K\alpha_k^{n_k}\prod_{j=1}^N[\frac{1}{\sqrt{2\pi}\sigma_k}exp(-\frac{(y-\mu_k)^2}{2\sigma_k^2})]^{\gamma_{jk}}
\end{aligned}
P(y,γ∣θ)=j=1∏NP(yj,γj1,γj2,…,γjK)=j=1∏Nk=1∏K[αkϕ(yj∣θk)]γjk=k=1∏Kαknkj=1∏N[ϕ(yj∣θk)]γjk=k=1∏Kαknkj=1∏N[2πσk1exp(−2σk2(y−μk)2)]γjk
其中,nk=∑j=1Nγjkn_k=\sum_{j=1}^{N}\gamma_{jk}nk=∑j=1Nγjk,N=∑k=1KnkN=\sum_{k=1}^{K}n_kN=∑k=1Knk
因而,完全数据的对数似然函数为:
logP(y,γ∣θ)=∑k=1K{nklogαk+∑j=1Nγjk[log(12π)−logαk−12π(yj−μk)2]}logP(y,\gamma|\theta)=\sum_{k=1}^K \{n_klog\alpha_k+\sum_{j=1}^N\gamma_{jk}[log(\frac{1}{\sqrt{2\pi}})-log\alpha_k-\frac{1}{\sqrt{2\pi}}(y_j-\mu_k)^2]\}logP(y,γ∣θ)=k=1∑K{nklogαk+j=1∑Nγjk[log(2π1)−logαk−2π1(yj−μk)2]}
在上面得到了完全数据的对数似然函数,接下来就需要使用EM算法求解模型中的未知参数了。首先是EM算法的E步,也就是求解期望,得到Q函数。
Q(θ,θ(i))=E[logP(y,γ∣θ)∣y,θ(i)]=E{∑k=1K{nklogαk+∑j=1Nγjk[log(12π)−logαk−12π(yj−μk)2]}}=∑k=1K{∑j=1N(Eγjk)logαk+∑j=1N(Eγjk)[log(12π)−logαk−12π(yj−μk)2]}
\begin{aligned}
Q(\theta,\theta^{(i)}) & = E[logP(y,\gamma|\theta)|y,\theta^{(i)}]\\
& = E\{\sum_{k=1}^K \{n_klog\alpha_k+\sum_{j=1}^N\gamma_{jk}[log(\frac{1}{\sqrt{2\pi}})-log\alpha_k-\frac{1}{\sqrt{2\pi}}(y_j-\mu_k)^2]\}\}\\
& =\sum_{k=1}^K \{\sum_{j=1}^N(E\gamma_{jk})log\alpha_k+\sum_{j=1}^N(E\gamma_{jk})[log(\frac{1}{\sqrt{2\pi}})-log\alpha_k-\frac{1}{\sqrt{2\pi}}(y_j-\mu_k)^2]\} \\
\end{aligned}
Q(θ,θ(i))=E[logP(y,γ∣θ)∣y,θ(i)]=E{k=1∑K{nklogαk+j=1∑Nγjk[log(2π1)−logαk−2π1(yj−μk)2]}}=k=1∑K{j=1∑N(Eγjk)logαk+j=1∑N(Eγjk)[log(2π1)−logαk−2π1(yj−μk)2]}
这里记γjk^=E(γjk∣y,θ)\hat{\gamma_{jk}}=E(\gamma_{jk}|y,\theta)γjk^=E(γjk∣y,θ),则:
γjk^=αkϕ(yj∣θk)∑k=1Kαkϕ(yj∣θk)\hat{\gamma_{jk}}=\frac{\alpha_k\phi(y_j|\theta_k)}{\sum_{k=1}^{K}\alpha_k\phi(y_j|\theta_k)}γjk^=∑k=1Kαkϕ(yj∣θk)αkϕ(yj∣θk)
γjk^\hat{\gamma_{jk}}γjk^是在当前模型参数下第jjj个观测数据来自第kkk个分模型的概率,成为分模型k对观测数据yjy_jyj的响应度。
将γjk^=Eγjk\hat{\gamma_{jk}}=E\gamma_{jk}γjk^=Eγjk及nk=∑k=1NEγjkn_k=\sum_{k=1}^{N}E\gamma_{jk}nk=∑k=1NEγjk,可得:
Q(θ,θ(i))=∑k=1K{nklogαk+∑j=1Nγjk^[log(12π)−logαk−12π(yj−μk)2]}Q(\theta,\theta^{(i)})=\sum_{k=1}^K \{n_klog\alpha_k+\sum_{j=1}^N\hat{\gamma_{jk}}[log(\frac{1}{\sqrt{2\pi}})-log\alpha_k-\frac{1}{\sqrt{2\pi}}(y_j-\mu_k)^2]\}Q(θ,θ(i))=k=1∑K{nklogαk+j=1∑Nγjk^[log(2π1)−logαk−2π1(yj−μk)2]}
2.3 EM算法M步
之后,便是使用EM算法的M步求Q(θ,θ(i))Q(\theta,\theta^{(i)})Q(θ,θ(i))对θ\thetaθ的极大值,即求新一轮迭代的模型参数
θi+1=argmaxθQ(θ,θ(i))\theta^{i+1}=arg\max_{\theta}Q(\theta,\theta^{(i)})θi+1=argθmaxQ(θ,θ(i))
这里用μk^,σk2^,αk^\hat{\mu_k},\hat{\sigma_k^2},\hat{\alpha_k}μk^,σk2^,αk^来表示θi+1\theta^{i+1}θi+1中的各参数。对于参数μk^,σk2^\hat{\mu_k},\hat{\sigma_k^2}μk^,σk2^可以通过上述的Q函数对应求导取极值得到;对于αk^\hat{\alpha_k}αk^是在∑k=1K=1\sum_{k=1}^K=1∑k=1K=1条件下求偏导数并令其为0得到。因而可以得到如下的参数更新公式
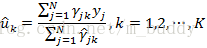
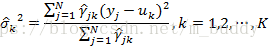
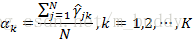
3. 高斯混合模型参数估计的EM算法
输入:观测数据y1,y2,…,yNy_1,y_2,\dots,y_Ny1,y2,…,yN,高斯混合模型
输出:高斯混合模型中的参数
step1:取参数的初始值开始迭代
step2:E步,依据当前模型的参数,计算分模型kkk对观测数据yjy_jyj的响应度
γjk^=αkϕ(yj∣θk)∑k=1Kαkϕ(yj∣θk)\hat{\gamma_{jk}}=\frac{\alpha_k\phi(y_j|\theta_k)}{\sum_{k=1}^{K}\alpha_k\phi(y_j|\theta_k)}γjk^=∑k=1Kαkϕ(yj∣θk)αkϕ(yj∣θk)
step3:M步,计算新一轮迭代的模型参数
step4:重复step2和step3,直到收敛。
后记:本篇博客主要讲了高斯混合模型的推导以及演算的过程,没有讲解相关的实用例子,在后面的博客中将会讲到使用高斯混合模型实现自动化肿瘤分割的任务。这里将其记录下来,留作后用。


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









