






 UniDistill提出了一种在BEV空间进行知识蒸馏的方法,用于3D目标检测,解决了不同模态输入导致的特征不匹配问题。方法包括在低级和高级特征以及预测头上进行蒸馏,利用目标边界点和高斯掩模进行更聚焦的蒸馏,同时通过adapter层缓解错误信息传递。实验表明这种方法能有效提升学生网络的性能。
UniDistill提出了一种在BEV空间进行知识蒸馏的方法,用于3D目标检测,解决了不同模态输入导致的特征不匹配问题。方法包括在低级和高级特征以及预测头上进行蒸馏,利用目标边界点和高斯掩模进行更聚焦的蒸馏,同时通过adapter层缓解错误信息传递。实验表明这种方法能有效提升学生网络的性能。
参考代码:UniDistill
1. 概述
介绍:这篇文章为BEV下3D目标检测领域提出了一种知识蒸馏方案,无论是Lidar还是Camera作为数据输入,它们均可以在BEV空间下实现特征对齐,则可以不用考虑前级网络由于不同模态输入而导致特征不匹配问题。对于刚完成到BEV视角转换的特征称为low-level特征,经过BEV编码器之后得到high-level特征,之后检测任务才能在high-level上得到感知结果。这篇文章的具体方法便是在上数BEV涉及的3个维度进行特征蒸馏,具体是通过在目标上采点和使用高斯掩膜实现蒸馏,采点的好处是对目标的scale鲁棒,高斯掩膜的好处是蒸馏更加聚焦。
2. 具体方法
2.1 整体结构和思路
下图展示了文章算法的大体蒸馏思路:

可以看到文章方法进行知识蒸馏的维度都是在BEV特征下完成的,对应到上图便是在low-level、high-level和预测头部分实现特征蒸馏。在说明具体蒸馏方法之前需要明确如下问题:
3D目标特征蒸馏思路:
对于个3D目标其位置在BEV特征图下是固定的,则忽略目标的高度信息,则可以在BEV的XY平面上得到一个矩形区域,则以该矩形4定点+4边中点+1中心点可以构建由9个点描述的检测目标。对于蒸馏的区域是选择在前景区域,而不会对噪声很大的背景区域也选择蒸馏。对于前景区域按照9个点描述可以避免目标大小影响蒸馏偏向性,从而导致小目标蒸馏效果差。
教师网络性能拉垮时的处理:
万一教师网络在某些case上性能拉垮导致传递错误信息给学生网络,对此通过在学生网络对应特征输出部分添加一层卷积作为adapter,这样缓解错误信息引导,这个机制会在low-level和high-level的时候使用。
2.2 具体蒸馏方法
low-level特征蒸馏:
对于adapter之后的特征(目标边界上的9个点组成)采用L1损失的方式进行蒸馏:
L
f
e
a
=
1
9
∑
i
=
1
9
∣
F
M
T
l
o
w
(
x
i
,
y
j
)
−
F
M
S
l
o
w
(
x
i
,
y
j
)
∣
L_{fea}=\frac{1}{9}\sum_{i=1}^9|F_{MT}^{low}(x_i,y_j)-F_{MS}^{low}(x_i,y_j)|
Lfea=91i=1∑9∣FMTlow(xi,yj)−FMSlow(xi,yj)∣
high-level特征蒸馏:
high-level比low-level包含了更多的上下文信息,则直接使用L1损失已经不太合适,则这里采用9个点之间构建特征关联矩阵
R
e
l
M
a
t
∈
R
9
∗
9
RelMat\in R^{9*9}
RelMat∈R9∗9来进行描述:
R
e
l
M
a
t
i
,
j
M
S
=
Φ
(
F
M
S
h
i
g
h
(
x
i
,
y
i
)
,
F
M
S
h
i
g
h
(
x
j
,
y
j
)
)
RelMat_{i,j}^{MS}=\Phi(F_{MS}^{high}(x_i,y_i),F_{MS}^{high}(x_j,y_j))
RelMati,jMS=Φ(FMShigh(xi,yi),FMShigh(xj,yj))
其中,
Φ
\Phi
Φ代表余弦相似度。得到教师和学生网络的特征关联矩阵之后便是需要最小化这俩矩阵的差异:
L
R
e
l
=
1
81
∑
1
≤
i
,
j
≤
9
∣
R
e
l
M
a
t
i
,
j
M
S
−
R
e
l
M
a
t
i
,
j
M
T
∣
L_{Rel}=\frac{1}{81}\sum_{1\le i,j\le9}|RelMat_{i,j}^{MS}-RelMat_{i,j}^{MT}|
LRel=8111≤i,j≤9∑∣RelMati,jMS−RelMati,jMT∣
感知头部分蒸馏:
感知头部分具有分类和回归两个任务,首先对于回归部分求去分类概率最大的分类特征表达:
F
m
a
x
c
l
s
(
i
,
j
)
=
max
1
≤
k
≤
C
F
c
l
s
(
i
,
j
,
k
)
F_{max}^{cls}(i,j)=\max_{1\le k\le C}F^{cls}(i,j,k)
Fmaxcls(i,j)=1≤k≤CmaxFcls(i,j,k)
这个特征与回归分支的特征concat起来得到心的特征表达
F
M
T
r
e
s
p
F_{MT}^{resp}
FMTresp,之后感知头部分的蒸馏便是在这个维度上做的。不过相比之前点采样的方式进行蒸馏,这里采用一个高斯掩膜的方式重点关注目标区域:
L
R
e
s
p
=
∑
1
≤
i
≤
H
,
1
≤
j
≤
W
∣
F
M
T
r
e
s
p
(
i
,
j
)
−
F
M
S
r
e
s
p
(
i
,
j
)
∣
∗
M
a
s
k
(
i
,
j
)
L_{Resp}=\sum_{1\le i\le H,1\le j\le W}|F_{MT}^{resp}(i,j)-F_{MS}^{resp}(i,j)|*Mask(i,j)
LResp=1≤i≤H,1≤j≤W∑∣FMTresp(i,j)−FMSresp(i,j)∣∗Mask(i,j)
最后蒸馏部分的损失便是上面几个损失的组合了。上面这仨项对蒸馏效果的影响:
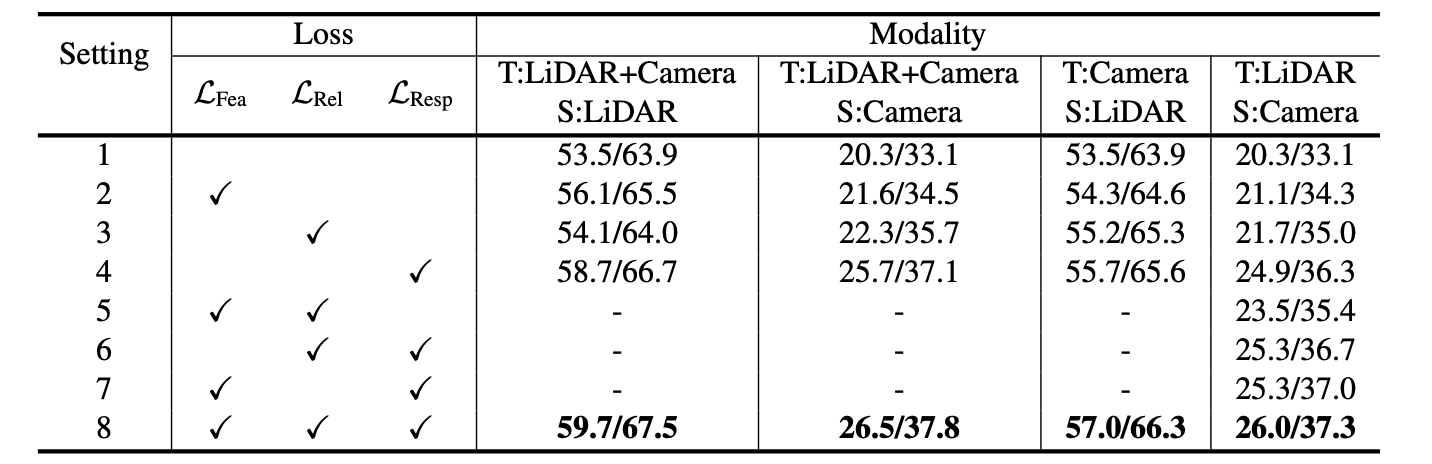
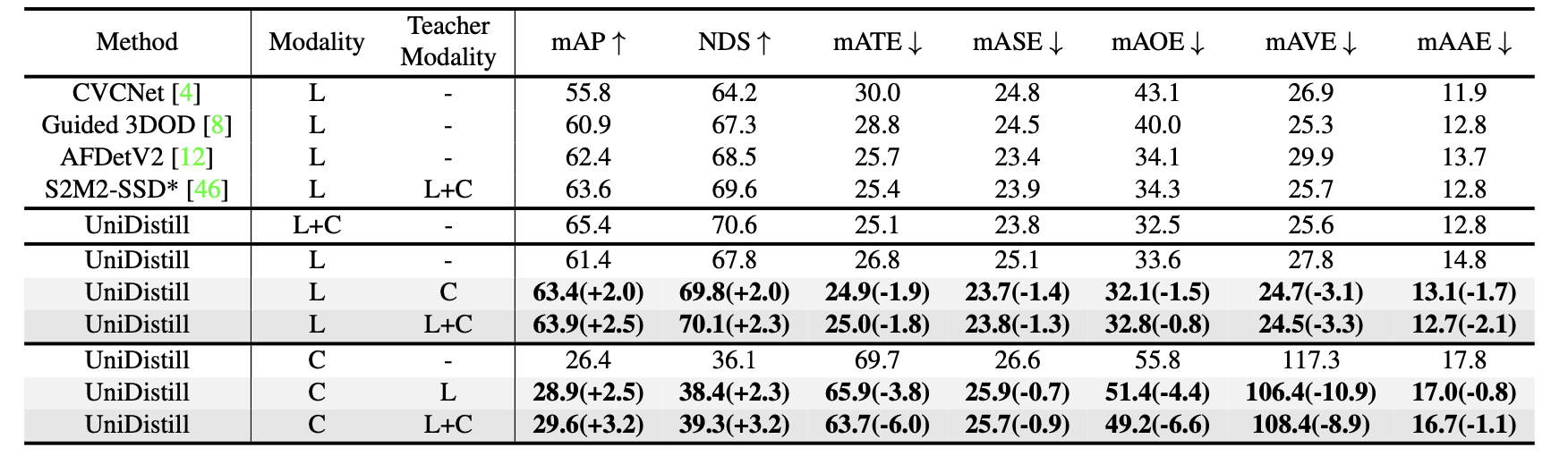
3. 实验结果


















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









