




 本文探讨了视频深度估计问题,指出单帧图像深度估计在视频场景中出现的闪烁问题,并介绍了几种解决方案。包括基于后处理的CVD系列方法,如Consistent Video Depth Estimation和Robust Consistent Video Depth Estimation,以及基于学习的视频深度估计方法,如ST-CLSTM、TCMonoDepth和DeepVideoMVS。这些方法通过利用时序信息、光流估计和深度先验来提高深度预测的连续性和准确性。
本文探讨了视频深度估计问题,指出单帧图像深度估计在视频场景中出现的闪烁问题,并介绍了几种解决方案。包括基于后处理的CVD系列方法,如Consistent Video Depth Estimation和Robust Consistent Video Depth Estimation,以及基于学习的视频深度估计方法,如ST-CLSTM、TCMonoDepth和DeepVideoMVS。这些方法通过利用时序信息、光流估计和深度先验来提高深度预测的连续性和准确性。
1. 概述
前言: 如今CV在2D领域取得较为不错的结果,随着自动驾驶的兴起越来愈多的注意力被吸引到3D场景下的各式任务中去,其中深度估计算是一种2D到3D的转换桥梁,赋予了2D图像更多信息。在这本篇文章中将会围绕深度估计算法讨论在视频场景下的深度估计任务,并根据本人在该方向上的一些浅薄认知介绍几种适用于视频场景的连续深度估计方法,不足或不全请见谅。
单帧图像场景下的深度估计与存在的问题:
对于单张图像的深度估计任务在之前的很多文章里面已经介绍过了,如经典监督学习方法Midas和自监督学习方法MonoDepeth2,这些方法在对应单帧图像深度估计任务中表现出了很好的性能,也切实满足了一些实际业务场景需求。但是将这些适用于单帧图像深度估计的算法用于拥有连续视频帧的视频场景时便会出现图像中系统区域深度估计不一致的情况,具体表现出来的现象便是深度结果闪烁,这必然将会对后序的处理带来较大影响。
视频场景下的深度估计:
直接将适用于单帧图像的深度估计模型运用于视频场景会存在闪烁的问题,那么一个很自然的想法便是在现有深度估计网络的基础上使用offline fine-tune的形式去优化深度估计的结果。但是这样的方法存在处理耗时长的问题,对此最为直接的方式便是使得网络能够感知到视频场景下物体的运动,并通过网络学习的形式产生连续深度估计结果,这样就可以排除掉耗时的后处理部分。
在深度估计应用基础上使用稳像技术:
一般来讲深度估计任务都是另外一些后期任务的基础,若是实在通过技术手段无法生成对应深度,那么造成后期视频效果问题可以通过视频稳像的方式进行优化。在这里给出几篇文献作为引子,对应的稳像技术可以在此基础上进行扩展探索:
- Blind Video Temporal Consistency
- Learning Blind Video Temporal Consistency
- deep-video-prior (DVP): Blind Video Temporal Consistency via Deep Video Prior
对于稳像这部分内容不是这篇文章需要讨论的,这里不做进步展开。
2. 基于后处理的视频深度估计
2.1 CVD系列视频深度后处理
CVD系列方法是属于视频深度后处理的方法,都是需要一个预先训练的好的深度估计模型去估计视频帧的深度结果,在此之外或使用COLMAP、Ceres、FlowNet之类的附加处理工具参与到连续深度的约束中。
Consistent Video Depth Estimation:
像下图展示的便是经典CVD方法的pipeline:
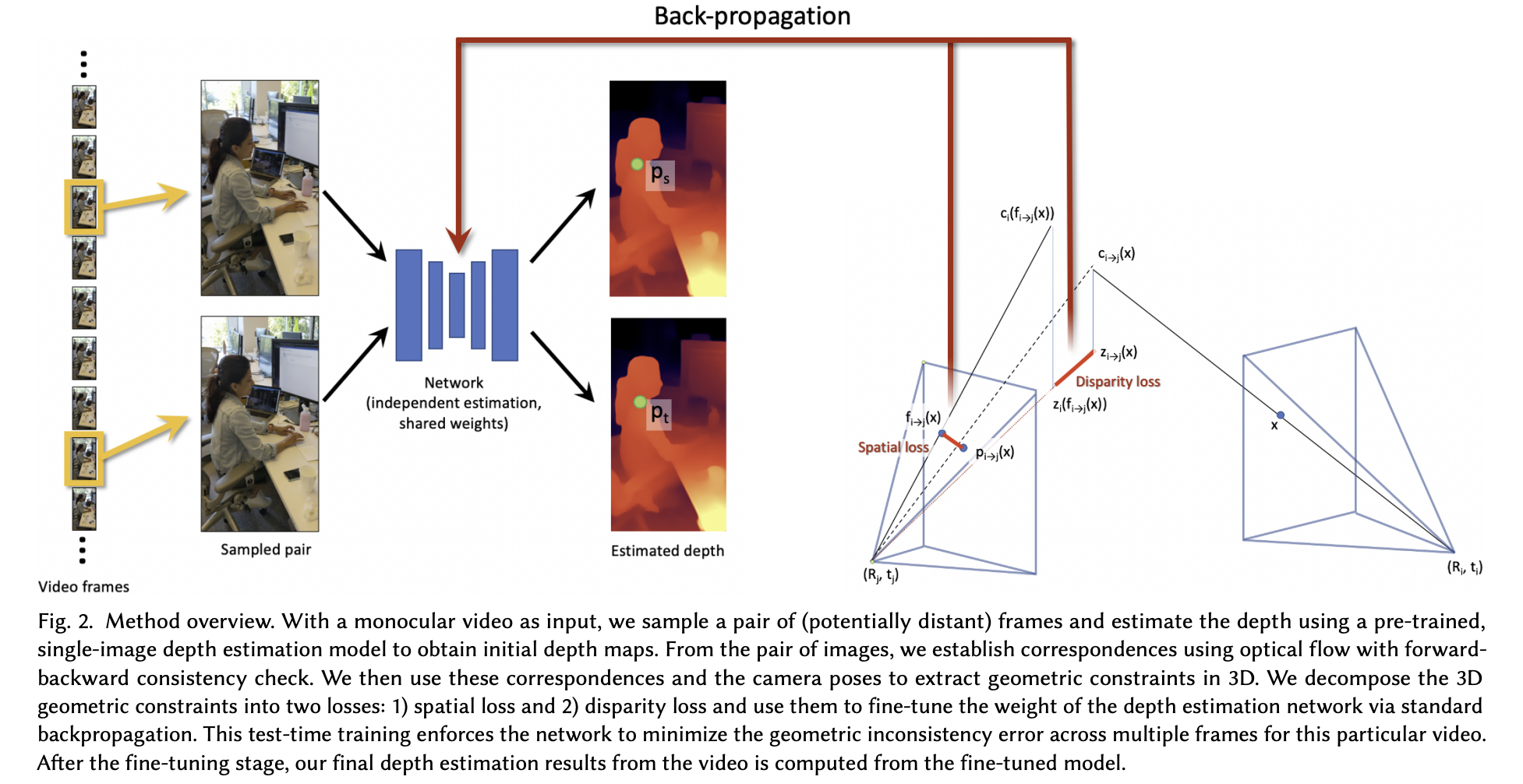
对照上图中对整体pipeline的描述,其需要如下组件:
- 1)一个初始深度估计网络,用于估计输入视频帧的深度;
- 2)一个光流估计网络(FlowNet),用于寻找视频帧之间像素的偏移映射关系;
- 3)COLMAP用于解算视频帧的相机位姿;
- 4)一套基于spatial和disparity的约束度量,实现深度网络的梯度反传;
论文:Consistent Video Depth Estimation
项目地址:Consistent Video Depth Estimation
Robust Consistent Video Depth Estimation:
这篇文章的思路与前面降到的CVD有一定类似,不过其在处理pipeline上与CVD方法不同,这里是固定了深度估计网络部分,着力于视频帧的后处理,其pipeline见下图所示:
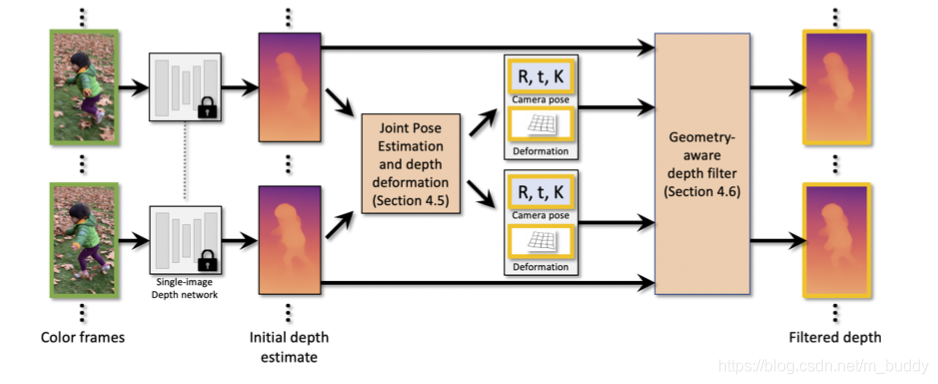
对照上图pipeline的处理流程,其处理流程可以大致划分为3步:
- 1)使用MiDas作为单帧深度估计方法,从而估计得到单帧图像的初始深度信息。使用Ceres Library等从视频序列中去计算初始相机位姿;
- 2)使用finetune训练的形式从输入的视频序列中交替优化深度估计结果与相机位姿信息,在相机位姿估计过程中使用样条差值的形式实现深度对齐,从而使得相机位姿估计的结果稳定;
- 3)使用几何感知的深度滤波器在多帧之间进行滤波保留和优化深度估计中的高频信息;
论文:Robust Consistent Video Depth Estimation
论文笔记:《Robust Consistent Video Depth Estimation》论文笔记
2.2 dynamic-video-depth
这篇文章关注的还是在后处理阶段的深度一致性研究,这篇文章在其中使用了更多和更高维度的信息用于约束深度的一致性。其在fine-tune阶段会同更新深度估计部分网络参数
F
θ
s
F_{\theta_s}
Fθs,以及通过多个全连接层构成的的3D维度点云偏移向量预测网络
G
θ
s
G_{\theta_s}
Gθs(这一点有点类似NERF的思想,也通过位置编码输入之后经过全连接层得到最后输出)。其整体的pipeline流程见下图所示:
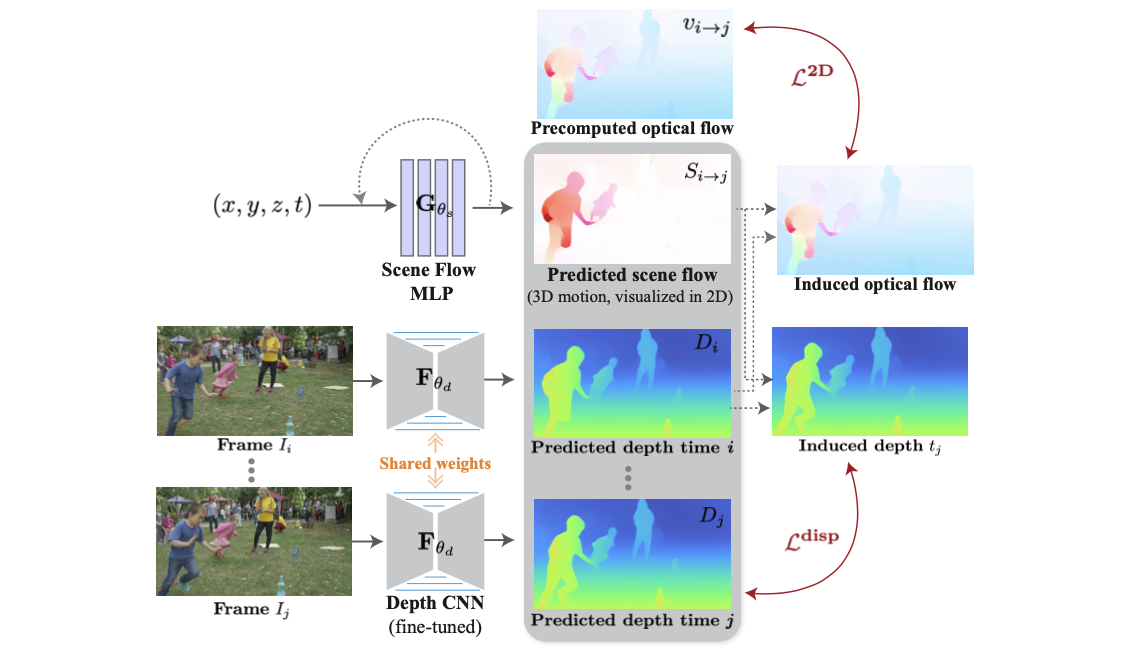
在前期数据处理阶段,会首先使用ORB SLAM2对视频帧进行处理得到每一帧的相机位姿,之后使用该相机位姿作为COLMAP的初始值从而得到每张图的稀疏深度图
D
i
s
f
m
D_i^{sfm}
Disfm。得到上述信息之后还会使用深度估计网络估计得到初始深度与使用光流估计网络得到光流信息。那么接下来重要的流程便是建立约束关系了,这里建立的约束关系主要可以划分为3个分量。
2D层面的约束:
这部分的约束是建立在图像像素偏移的基础上的,只不错这里的偏移使用的两种实现路径:
- 1)光流方式:在这部分约束中会首先使用 i i i到 j j j的光流信息实现像素的偏移: p i → j = x + v i → j p_{i\rightarrow j}=x+v_{i\rightarrow j} pi→j=x+vi→j;
- 2)3D点偏移方式:这里会借用之前 i i i处估计出的深度、相机相对位姿和 G θ s G_{\theta_s} Gθs(3D维度的偏移),实现从2D到3D再添加偏移之后从3D到2D的映射,这里将其描述为: M j ( X x → j ( x ) ) M_j(X_{x\rightarrow j}(x)) Mj(Xx→j(x));
则经过上述2种方式得到的像素映射结果应该是一致的,因而第一个约束被描述为:
L
i
→
j
2
D
(
x
)
=
∣
∣
M
j
(
X
x
→
j
(
x
)
)
−
p
i
→
j
∣
∣
1
L_{i\rightarrow j}^{2D}(x)=||M_j(X_{x\rightarrow j}(x))-p_{i\rightarrow j}||_1
Li→j2D(x)=∣∣Mj(Xx→j(x))−pi→j∣∣1
disparity层面的约束:
上面讲到的是warp之后像素值的约束,则对应匹配点经过warp之后像素在深度维度应该也是一致的,则这部分的约束被描述为:
L
i
→
j
d
i
s
p
(
x
)
=
∣
∣
1
D
i
→
j
(
x
)
−
1
D
j
(
p
i
→
j
(
x
)
)
∣
∣
1
L_{i\rightarrow j}^{disp}(x)=||\frac{1}{D_{i\rightarrow j}(x)}-\frac{1}{D_j(p_{i\rightarrow j}(x))}||_1
Li→jdisp(x)=∣∣Di→j(x)1−Dj(pi→j(x))1∣∣1
3D运动平滑先验约束:
在视频帧场景下其3D维度的运动应该遵循无跳变原则,也就是过度会比较平滑,则像素从
i
→
(
i
+
1
)
i\rightarrow(i+1)
i→(i+1)的3D运动场应与
(
i
+
1
)
→
(
i
+
2
)
(i+1)\rightarrow(i+2)
(i+1)→(i+2)平滑,则对应的约束被描述为:
L
i
p
r
i
o
r
(
x
)
=
∣
∣
S
i
→
(
i
+
1
)
(
x
)
−
G
θ
s
(
X
i
(
x
)
+
S
i
→
(
i
+
1
)
(
x
)
,
i
+
1
)
∣
∣
1
L_i^{prior}(x)=||S_{i\rightarrow(i+1)}(x)-G_{\theta_s}(X_i(x)+S_{i\rightarrow(i+1)}(x),i+1)||_1
Liprior(x)=∣∣Si→(i+1)(x)−Gθs(Xi(x)+Si→(i+1)(x),i+1)∣∣1
则结合上述3个分量上的约束文章的整体损失函数被描述为:
L
=
L
2
D
+
α
L
d
i
s
p
+
β
L
p
r
i
o
r
L=L^{2D}+\alpha L^{disp} + \beta L^{prior}
L=L2D+αLdisp+βLprior
主页:dynamic-video-depth
论文:Consistent Depth of Moving Objects in Video
参考代码:dynamic-video-depth
3. 基于学习的视频深度估计
3.1 ST-CLSTM
在之前一些工作中使用到的单帧图像完成深度估计模型都完成的是spatial维度的监督,而对于视频场景其本身是具备时序特性的,对此一个很自然的想法便是设法将时序信息引入到深度估计网络中。对此,在具体实现上便是使用ConvLSTM的形式实现前后帧的关联,从而实现连续视频深度估计,具体的代表方法是下面这篇文章:
论文:Exploiting temporal consistency for real-time video depth estimation
参考代码:ST-CLSTM
在这篇文章中对不同时序帧的图像都会先进行spatial-wise上的特征图抽取,之后送入ConvLSTM网络关联前后帧信息,最后得到对应帧的输出结果。其整体网络结构见下图所示:
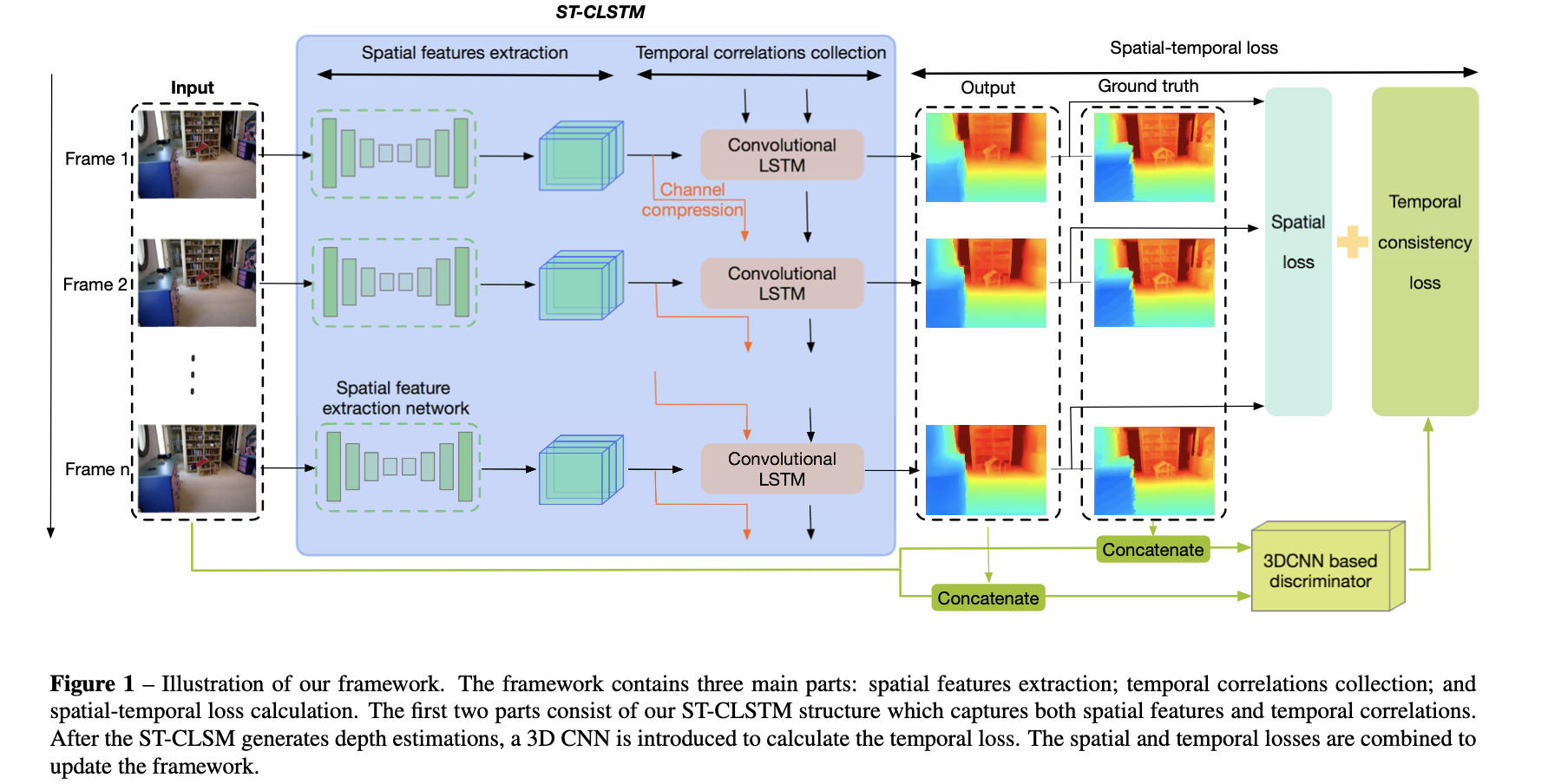
在上图中可以看到除了使用ConvLSTM实现spatial-wise上的深度监督之外,文章还对深度的时序一致性进行约束,也就是使用GAN的思想对深度temporal-wise一致性进行约束,其判别网络的结构见下图所示:
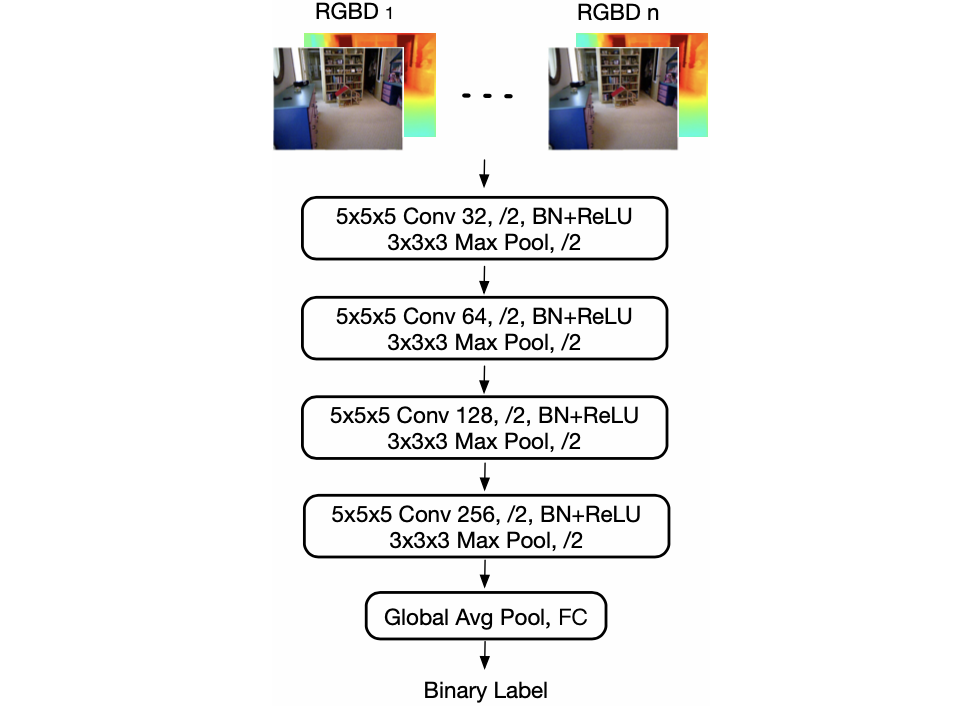
则这篇文章整体的损失函数也就被描述成为了2个部分:
L
=
L
s
p
a
t
i
a
l
+
0.1
∗
L
t
e
m
p
o
r
a
l
L=L_{spatial}+0.1*L_{temporal}
L=Lspatial+0.1∗Ltemporal
3.2 TCMonoDepth
对于视频深度估计中存在深度估计值闪烁的问题,文章这篇文章分析为其对应的区域存在较大偏移导致的,因而需要网络具备对应像素偏移的感知能力,也就是需要一个光流网络去估计光流信息(文章中使用为PWC-Net)。此外,像ST-CLSTM这样的网络是需要大量连续的深度视频才能实现网络训练的,在这篇文章中可以在有标注的视频深度数据集(NYU、ScanNet)上完成训练,也可以在无标注的大量视频数据上实现训练(其对应的训练GT D i ∗ D_i^{*} Di∗使用MiDas进行预测)。而且这里只需要逐渐输入单帧图像便可以得到对应连续深度结果,并不需要ConvLSTM网络去捕获时序信息。这篇文章的链接与参考代码为:
论文:Exploiting temporal consistency for real-time video depth estimation
参考代码:TCMonoDepth
在下图中展示了这篇文章提出方法的网络结构:
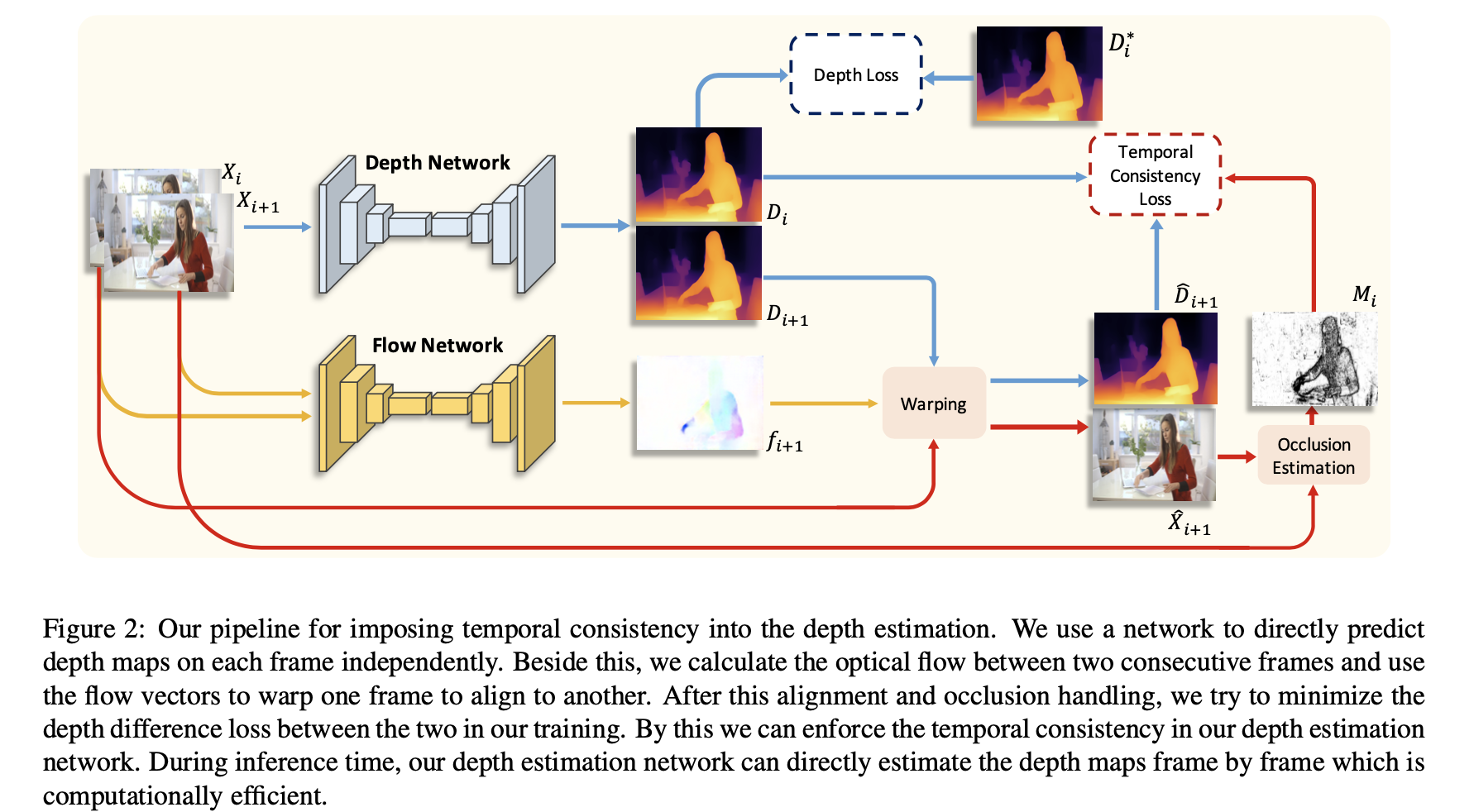
在上图中可以看到网络输入是输入两张连续帧,只有其中的预测结果
D
i
D_i
Di会参与深度估计的监督约束。同时给出的连续两帧会在光流网络预测结果下进行warp操作(从帧
X
i
+
1
X_{i+1}
Xi+1warp到
X
i
X_i
Xi),从而得到
D
^
i
+
1
\hat{D}_{i+1}
D^i+1和
X
^
i
+
1
\hat{X}_{i+1}
X^i+1。那么按照之前的假设,warp之后的像素其相似度越高,那么其对应的深度值应该更为一致。反应到对应的深度结果上应该在对应区域深度一致,则可以对这个相似度表示为一致性约束的权重参数,也就是:
M
i
=
e
x
p
−
σ
⋅
(
∣
∣
X
i
−
X
^
i
+
1
∣
∣
)
M_i=exp^{-\sigma\cdot(||X_i-\hat{X}_{i+1}||)}
Mi=exp−σ⋅(∣∣Xi−X^i+1∣∣)
那么整体上深度一致性约束可以被描述为:
L
i
T
C
=
M
i
⋅
∣
∣
D
i
−
D
^
i
+
1
∣
∣
L_i^{TC}=M_i\cdot||D_i-\hat{D}_{i+1}||
LiTC=Mi⋅∣∣Di−D^i+1∣∣
在将
D
i
D_i
Di的深度监督函数组合起来那么这篇文章的整体损失函数为:
L
=
∑
i
(
L
i
D
+
L
i
T
C
)
L=\sum_i(L_{i}^D+L_i^{TC})
L=i∑(LiD+LiTC)
将文章的视频深度估计结果与其它的一些深度估计方法进行比较,得到的结果见下表所示:
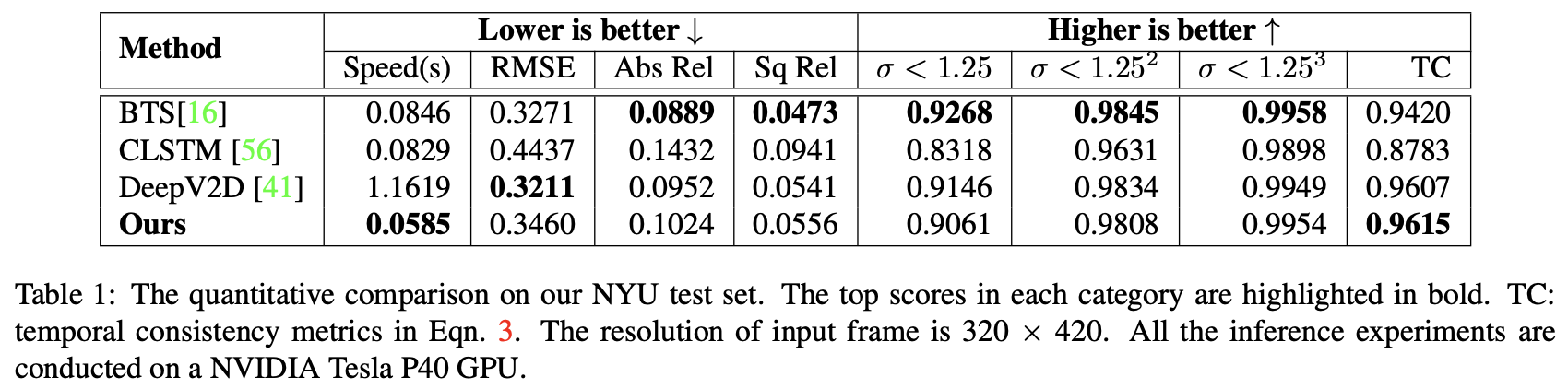
3.3 DeepVideoMVS
在上述的两种视频深度估计方法中其通过连续GT深度或像素偏移跟踪作为约束,从而实现生成连续深度估计结果,也在对应的场景下取得了不错的效果。但是其还是缺少更加符合几何变换特性的隐式先验与约束。而在这篇文章中指出,在视频场景下的深度估计需要充分利用相机相对位姿变换关系、深度先验、左右多帧数据融合(MVS)、时序信息传递实现,从而生成更加鲁棒的视频深度估计结果。其整体的网络结构见下图所示:
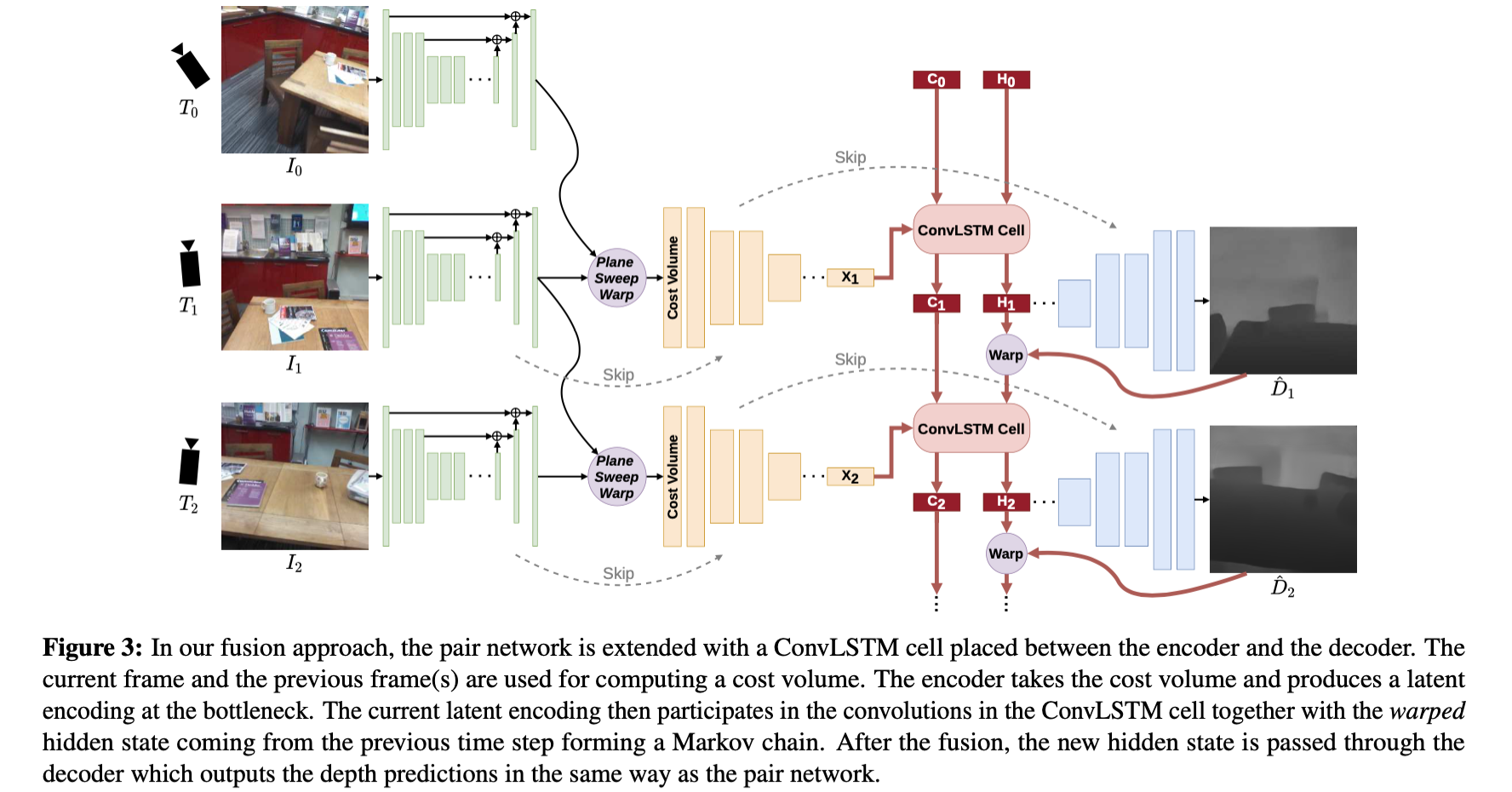
对照上图网络结构可以看到其通过Plane Sweep Warp 实现多帧信息与深度先验整合输入,用以生成更加准确的深度估计结果。之后通过ConvLSTM整合时序信息,生成更加鲁棒深度估计结果。
论文:DeepVideoMVS:Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
论文笔记:《DeepVideoMVS:Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion》论文笔记
4. 为视频深度研究提供的开源数据集
这里为研究视频场景下的深度估计任务给出了一些适用的数据集,其中 TUM、ScanNet、NYU数据集是较为经常适用和比较的。


















 799
799




 到【灌水乐园】发言
到【灌水乐园】发言







