




 《DeepVideoMVS》论文提出了结合空间和时间信息的多视图立体匹配方法,通过FPN和ConvLSTM对视频深度进行连续估计。PairNet仅处理空间信息,而FusionNet通过ConvLSTM引入时间维度,提高了深度估计的稳定性。实验结果显示,该方法在资源占用和性能上优于其他深度估计技术。
《DeepVideoMVS》论文提出了结合空间和时间信息的多视图立体匹配方法,通过FPN和ConvLSTM对视频深度进行连续估计。PairNet仅处理空间信息,而FusionNet通过ConvLSTM引入时间维度,提高了深度估计的稳定性。实验结果显示,该方法在资源占用和性能上优于其他深度估计技术。
参考代码:deep-video-mvs
1. 概述
介绍:这篇文章针对视频深度估计提出一种基于multi-view的连续深度估计方法,该方法有效利用了spatial和temporal上的特征表达,构建一个可以预测具有深度一致性的视频深度估计pipeline。
1)在spatial上的表达:其通过FPN网络从输入图像帧中抽取图像特征,之后在stride=2的特征图上通过预先计算好的相机位姿、内参和深度先验bins构建multi-view上的cost-volume;
2)在temporal上的表达:其通过在网络高纬度特征上添加ConvLSTM实现对于前序视频序列信息的有效利用,此外上一帧预测深度基础上通过相机位姿、内参将ConvLSTM中的隐层特征 H H H进行warp使网络编码的几何信息更加丰富;
对于这篇文章来讲除了刚才提到的图像帧特征抽取之外,还对之前得到的cost-volume使用shortcut和U型网络结构(ConvLSTM是添加在U型网络结构的底部)实现对原始cost-volume的spatial维度上正则化操作,并在U型网络的解码器部分使用逐级深度预测的形式refine深度估计结果。
这里将文章的方法与其它的一些深度估计方法进行对比,见下图所示:

可以看到文章的方法在深度估计效果和资源占用上更优,其生成的视频深度效果在其训练的场景下还是很不错的,可以前往GitHub仓库查看。不过文章的方法都是在已知相机位姿和每帧对应深度(ScanNet数据集) 的情况下监督计算得来的,如何使其更加易用和泛化能力更强是一个值得细究的课题。
2. 方法设计
文章的方法是在给定一个视频序列基础上实现对深度的估计,既是实现视频预测深度值与GT深度差异最小化:
D
^
t
=
f
θ
(
I
t
,
I
t
−
1
,
…
,
I
t
−
δ
,
T
t
,
T
t
−
1
,
…
,
T
t
−
δ
,
K
)
\hat{D}_t=f_{\theta}(I_t,I_{t-1},\dots,I_{t-\delta},T_t,T_{t-1},\dots,T_{t-\delta},K)
D^t=fθ(It,It−1,…,It−δ,Tt,Tt−1,…,Tt−δ,K)
θ
∗
=
arg min
θ
l
(
D
^
t
,
D
t
)
\theta^{*}=\argmin_{\theta}l(\hat{D}_t,D_t)
θ∗=θargminl(D^t,Dt)
其中,
D
,
T
,
K
D,T,K
D,T,K分别代表深度、相机位姿、相机内参。同时按照是否引入时序上的特征可以将文章的方法分为PairNet和FusionNet,不过需要注意的是对于当前帧预测的时候其会使用相邻的帧从而构建multi-view预测机制,其给出的indices文件下便引用了其它视频帧图像:
00009.png 00003.png
00012.png 00009.png 00003.png
00013.png 00012.png 00009.png 00003.png
00014.png 00012.png 00013.png 00009.png
00016.png 00014.png 00013.png 00012.png
2.1 PairNet
文章给出的这部分实现是只包含了spatial上的信息处理的,没有包含时序上信息引入,其网络结构见下图所示:
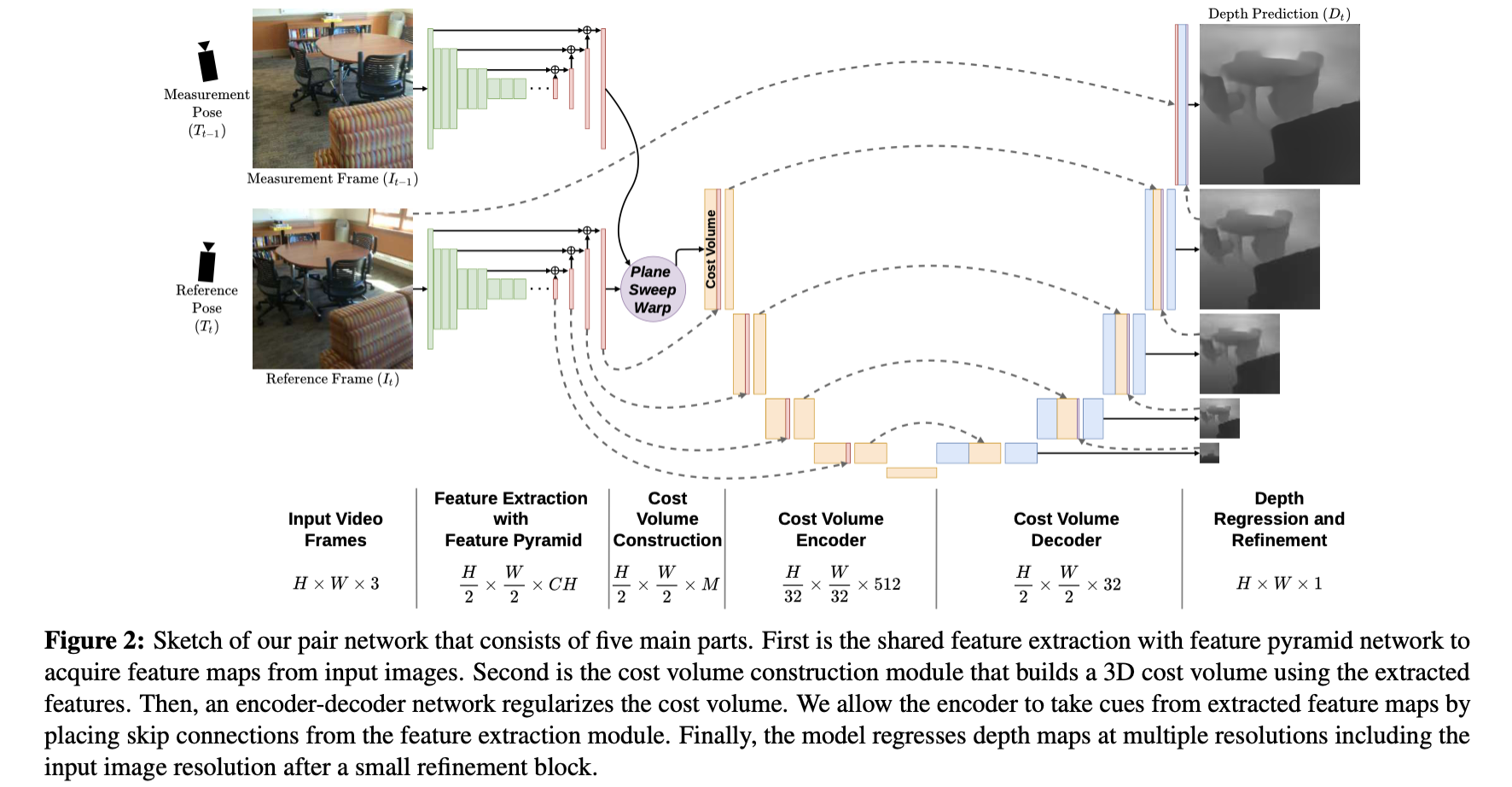
特征抽取:
对于给定的图像文章的算法是通过MnasNet完成特征图抽取,之后使用FPN网络进行特征优化,最后输出的特征图stride=2。后面对于cost-volume的构建也是建立在该特征图之上的。
cost-volume构建:
对于cost-volume的计算这里是在给定内参、相机位姿基础上通过在预先定义的深度范围上按照设定深度划分
M
=
64
M=64
M=64计算cost-volume,其计算实现参考:
# dvmvs/utils.py#L45
def calculate_cost_volume_by_warping(image1, image2, pose1, pose2, K, warp_grid, min_depth, max_depth, n_depth_levels, device, dot_product):
...
对于超参数
M
M
M对性能的影响见下表:

这里引入相机位姿是为了处理以当前帧为reference的multi-view感知,其在计算cost-volume的时候不同view的cost-volume是相叠加的形式。这部分可以参考:
# dvmvs/utils.py#L93
for pose2, image2 in zip(pose2s, image2s):
cost_volume = calculate_cost_volume_by_warping(...)
fused_cost_volume += cost_volume
fused_cost_volume /= len(pose2s)
U型编解码器:
这部分是在cost-volume的基础上通过添加一个U型网络(通过shortcut与之前特征抽取网络相连),对于其作用文章给出的解释是实现对cost-volume在spatial上的正则化。
损失函数:
对于深度的监督论文给出其使用的是L1损失监督。
2.2 FusionNet
在PairNet满足spatial信息感知的基础上,文章通过在上述提到的U型网络底部添加ConvLSTM从而能感知时序信息,则得到如下的网络结构:
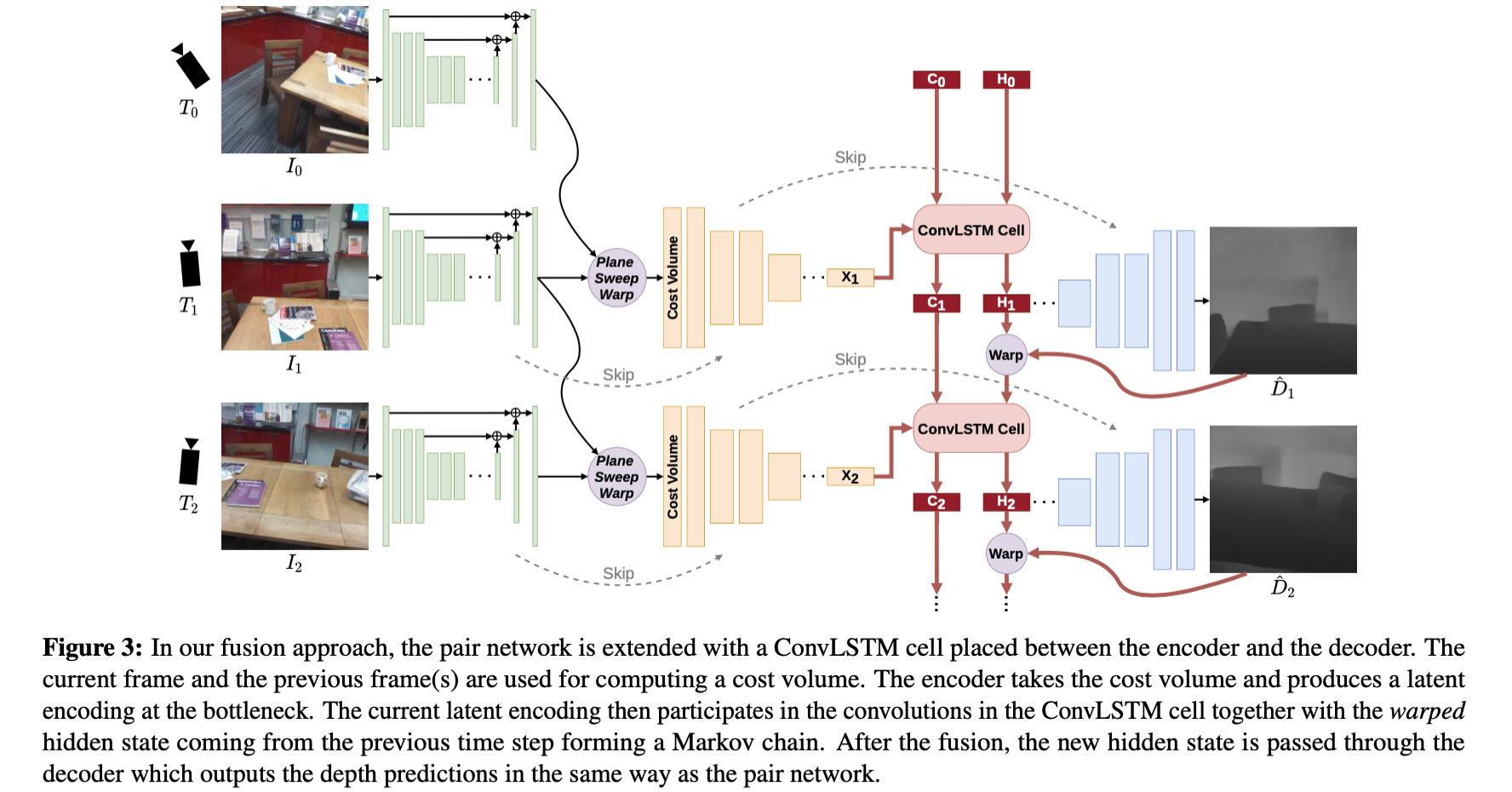
对于添加了ConvLSTM之后深度预测的流程变为了如下的步骤:

但是,在实际的过程中发现对于隐变量
H
t
−
1
H_{t-1}
Ht−1也让它能感知视场的变化,那么预测出来的深度将更加稳定,因而在上述过程的基础上使用内参、深度和相机位姿对隐变量
H
t
−
1
H_{t-1}
Ht−1进行视场的变换得到
H
ˉ
t
−
1
\bar{H}_{t-1}
Hˉt−1,则新的深度估计流程可以描述为:

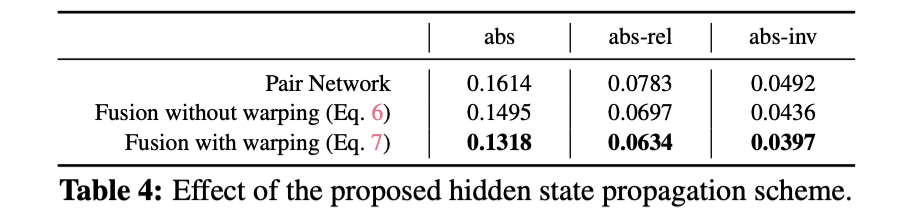
具体对隐变量是否有效,可以见下表的对比结果 :
3. 实验结果
文章的方法在各数据集下的性能表现:



















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









