 细粒度特征模仿:提升目标检测器性能
细粒度特征模仿:提升目标检测器性能







 本文介绍了如何使用知识蒸馏改进轻量级目标检测网络的性能,重点在于选择有效的特征区域(Fine-Gained)进行指导。通过在Faster R-CNN基础上进行改进,使用教师网络的特征和RPN输出结合,指导学生网络学习,实现在VGG11上比基线提升15%的性能。实验表明,这种方法简单但有效。
本文介绍了如何使用知识蒸馏改进轻量级目标检测网络的性能,重点在于选择有效的特征区域(Fine-Gained)进行指导。通过在Faster R-CNN基础上进行改进,使用教师网络的特征和RPN输出结合,指导学生网络学习,实现在VGG11上比基线提升15%的性能。实验表明,这种方法简单但有效。
代码地址:Distilling-Object-Detectors
1. 概述
导读:这篇文章是在two stage检测网络Faster RCNN基础上使用知识蒸馏改进亲轻量级网络性能。其中的核心思想是teacher网络中需要传递给student网络的应该是有效的信息,而非无效的背景区域信息,因而文章将backbone输出的特征图与RPN网络输出的结果进行组合,从而得到student网络应该学习的特征,从而指导student网络产生对应的分布从而提升检测的性能。其在VGG11上使用文章的方法实现了相对baseline 15%的提升,整体上文章的思想比较简单,但是实际证明还是很有效的。
在下图中展示了文章网络的大致结构,其中可以看出文章使用Fine-Gained特征图来指导student网络的学习。
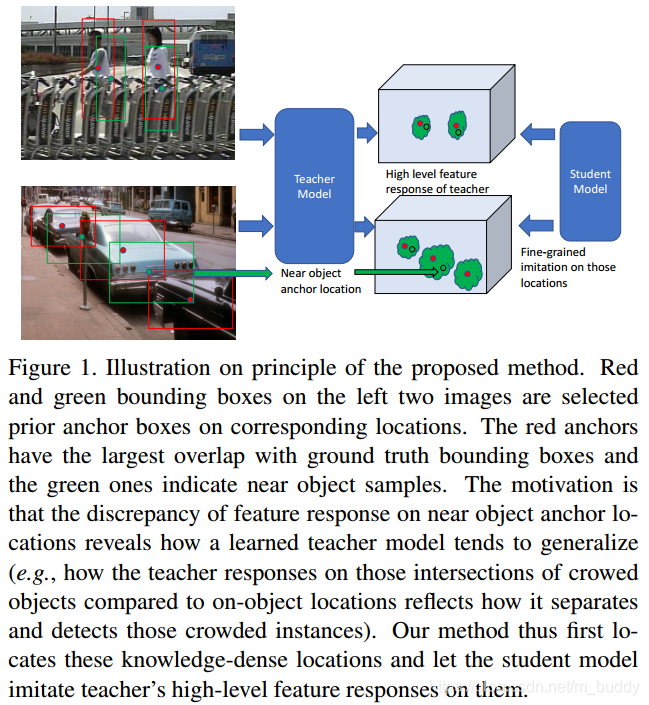
以下参考:CVPR19-检测模型蒸馏
之前有两个工作有类似的探索,但是都比较局限于特定框架,且未公布代码,对于具体实现存在一定疑惑。
- 1)论文:Learning efficient object detection models with knowledge distillation,文中使用两个蒸馏的模块:第一,全feature imitation(由FitNets: Hints for Thin Deep Nets 文中提出,用于检测模型蒸馏), 但是实验发现全feature imitation会导致student 模型performance反而下降,推测是由于检测模型feature 比较大,不同于classification,这其中包含大量的background, 存在大量的noise, 最后通过per-channel vairance 的验证基本确定这个情况。第二,对detection head的蒸馏,这里存在一个很大的问题,就是teacher 和student 的proposal set 不相同,如何进行匹配以便于施加distillation文中没有详述。
- 2)论文:Mimicking very efficient network for object detection.
这篇文章report 的蒸馏效果确实不错,但是框架仍然比较限定,且蒸馏区域取决于rpn的输出。
2. 方法设计
2.1 Fine-Gained区域提取
文章给出对于有效特征区域提取的流程见下图所示:
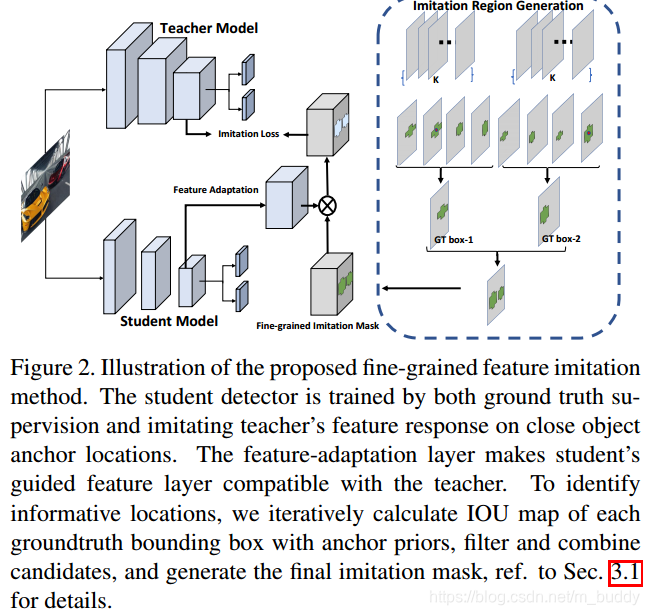
对于backbone输出的特征图,假设其大小为
W
∗
H
W*H
W∗H,网络中使用的anchor数量为
K
K
K,则文章对于Fine-Gained区域的提取步骤可以归纳如下(上图中的右边所示):
- 1)对于给定的特征图按照设置好的anchor信息,生成 W ∗ H ∗ K W*H*K W∗H∗K个框,将这些框与GT计算IoU;
- 2)对于这些IoU值,在其中选择最大的IoU值M,在此基础上引入一个参数 ψ ∈ [ 0 , 1 ] \psi \in[0,1] ψ∈[0,1],文中将这个参数设置为经验值 ψ = 0.5 \psi=0.5 ψ=0.5,这个参数与最大IoU值相乘得到一个IoU的阈值 F = ψ ∗ M F=\psi * M F=ψ∗M,用以控制什么样框(框对应的特征)会被采纳参与知识蒸馏;
- 3)对于所有生成框使用阈值 F F F进行过滤,之后将这些过滤之后的值进行组合得到一个掩码 I I I,后面计算蒸馏损失也是按照这个掩码进行的。
2.3 蒸馏损失
这里注意到student网络在引入teacher label进行学习的时候是添加了一个feature adaptation的,这里添加这个的原因有两点:
- 1)student与teacher在对应特征层级上其channel是不对应的,这里需要进行维度平衡;
- 2)既是在维度匹配的前提下,若是直接将损失加在student的backbone上会导致蒸馏效果的减弱,从而得到次优的效果;
这里对于蒸馏的损失是在对应的feature上使用平方损失计算得到的,因而将之前选择到的Fine-Gained的特征引入,得到损失的定义为:
L
i
m
i
t
a
t
i
o
n
=
1
2
N
p
∑
i
=
1
W
∑
j
=
1
H
∑
c
=
1
C
I
i
j
(
f
a
d
a
p
(
s
)
i
j
c
−
t
i
j
c
)
2
L_{imitation}=\frac{1}{2N_p}\sum_{i=1}^{W}\sum_{j=1}^{H}\sum_{c=1}^{C}I_{ij}(f_{adap}(s)_{ijc}-t_{ijc})^2
Limitation=2Np1i=1∑Wj=1∑Hc=1∑CIij(fadap(s)ijc−tijc)2
其中,
N
p
=
∑
i
=
1
W
∑
j
=
1
H
I
i
,
j
N_p=\sum_{i=1}^W\sum_{j=1}^HI_{i,j}
Np=∑i=1W∑j=1HIi,j。因而,总的损失函数被描述为:
L
=
L
g
t
+
λ
L
i
m
i
t
a
t
i
o
n
L=L_{gt}+\lambda L_{imitation}
L=Lgt+λLimitation
3. 实验结果
文章的方法在几个不同backbone上进行实验得到的结果,其结果显示文章的方法总体带来的收益还是很不错的:
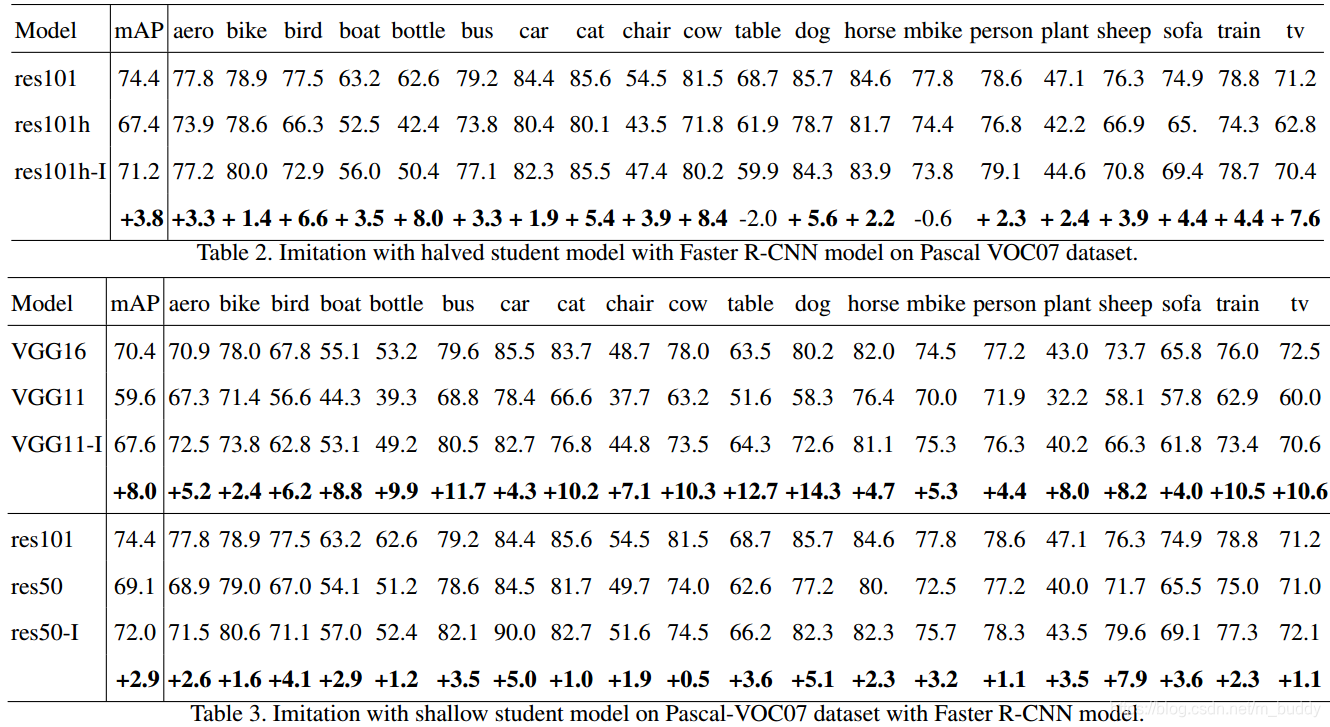


















 2348
2348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









