






〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
🚀 一句话理解:
Ray 就像 Python 的分布式“多线程池”,但能跑在多台机器、多张卡上,支持机器学习任务的调度、资源隔离和弹性扩展。
Ray 是一个开源的 分布式计算框架,让你可以轻松地将 Python 代码并行化和分布式运行,不管是在一台机器上,还是一整个 GPU 集群上。

🧠 一、Ray 是什么?核心理念
Ray 最初由 UC Berkeley 的 RISELab 实验室开发,目标是解决“大规模异构机器学习任务的调度难题”——也就是你在训练、推理、搜索、数据预处理时,常常需要不同类型的并行能力:
-
多进程?不好扩展。
-
Celery?太重。
-
Kubernetes?门槛高、写 YAML 太烦。
-
Spark?Python 不友好,不支持 GPU。
于是 Ray 的愿景是:
“一个通用的分布式计算平台,用 Python 就能表达异构分布式任务,并且具备极强的扩展性。”
UC Berkeley 教授 Ion Stoica 曾写过一篇文章:《The Future of Computing is Distributed》,探讨了分布式计算的未来趋势,详细介绍了Ray诞生的缘由。
大数据和AI正快速改变世界,但要实现其潜力,需克服应用需求与硬件能力之间日益增长的差距。分布式应用是解决方案,这需要新的软件工具、框架和课程来培训开发者,Anyscale公司正在开发相关工具和分布式系统。
Ion Stoica是加州大学伯克利分校计算机科学教授、RISELab首席研究员,因开发分布式计算框架Spark和Ray而闻名,同时是Databricks和Anyscale的联合创始人兼执行主席,他在分布式系统、云计算和互联网服务质量等领域有着深厚的研究背景,并成功将学术成果转化为商业应用,对现代计算架构发展产生了深远影响。
🧱 二、Ray 的核心架构和模块组成
2.1 Ray的系统架构
Ray的架构包括(1)一个实现API的应用层(2)一个提供高可伸缩性和容错能力的系统层。
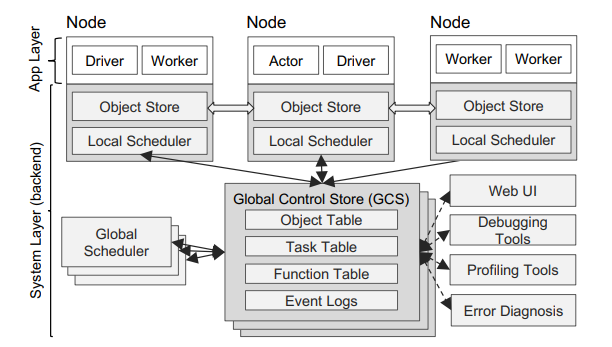
2.1.1 应用层
应用层由三种类型的进程组成:
● 驱动程序:执行用户程序的进程。
● 工作者:一种由系统自动启动的无状态进程,用于连续执行由驱动程序或其他工作程序调用的远程函数任务,不维护跨任务的本地状态。
● 执行者:一个有状态的进程,在被调用时仅执行它所暴露的方法。与工作者不同,执行者由工作者或驱动显式实例化。与工作者一样,执行者也串行执行方法,除了每个方法依赖于前一个方法执行的结果状态。
2.1.2 系统层
系统层由三个主要组件组成:全局控制存储、分布式调度器和分布式对象存储。所有组件都是水平可扩展且容错的。
全局控制存储(GCS):全局控制存储是一个带有发布订阅功能的键值存储系统,通过分片和链式复制实现容错和扩展,负责维护系统的全部控制状态,简化了系统设计并支持低延迟和高容错性。
自底向上分布式调度器:自底向上分布式调度器采用两级调度架构,任务首先在本地调度器尝试调度,若失败则提交至全局调度器,通过节点负载和任务约束优化调度决策,实现高可扩展性和低延迟任务调度。

内存中的分布式对象存储:内存中的分布式对象存储通过在每个节点的共享内存中存储任务输入输出,支持零拷贝数据共享,采用LRU策略管理内存,确保低延迟和高吞吐量,同时通过不可变数据设计简化容错机制。
2.2 Ray 的核心模块组成

Ray Client/API:为用户提供 Python API、Ray Dashboard 等交互入口。
Ray Core:Ray 的核心调度和分布式执行引擎,负责任务调度、资源管理、对象存储等。
Tune:用于超参数调优,支持各种搜索算法(如 Grid、Bayesian、PBT)。
Train:用于分布式训练,支持 PyTorch、TensorFlow,支持多机多卡。
Serve:用于模型部署,具备高可用性、低延迟特性,支持自动扩缩容与流量分发。
⚙️ 三、Ray Core:分布式执行的心脏
3.1 @ray.remote:最核心的装饰器
用它声明一个可以“远程执行”的函数或类。
import ray
ray.init()
@ray.remote
def slow_square(x):
import time; time.sleep(1)
return x * x
futures = [slow_square.remote(i) for i in range(10)]
results = ray.get(futures)
print(results)✨ 你写的每一个 .remote() 调用,其实就是一个分布式任务(任务图节点)。
3.2 Actor 模式
Ray 支持状态持久的远程类对象(像分布式服务实例):
@ray.remote
class Counter:
def __init__(self):
self.count = 0
def inc(self):
self.count += 1
def get(self):
return self.count
counter = Counter.remote()
ray.get(counter.inc.remote())
print(ray.get(counter.get.remote())) # 13.3 资源调度系统
Ray 支持对 CPU/GPU/自定义资源的调度控制:
@ray.remote(num_cpus=2, num_gpus=1)
def train_on_gpu():
...
@ray.remote(resources={"TPU": 1})
def train_on_tpu():
...你也可以用 ray status, ray list nodes, ray memory 等查看集群状态。
📦 四、高级模块详解
4.1 Ray Train(分布式训练)
提供统一接口支持:
-
PyTorch、TensorFlow、XGBoost
-
多卡 / 多机 / 混合训练
-
报告进度 + 保存 checkpoint
from ray.train.torch import TorchTrainer
from ray.train import ScalingConfig
def train_func(config):
model = ...
# PyTorch 训练代码
trainer = TorchTrainer(
train_func,
scaling_config=ScalingConfig(num_workers=4, use_gpu=True)
)
result = trainer.fit()4.2 Ray Tune(超参搜索神器)
支持 Grid Search、Random Search、Bayesian、Optuna、HyperOpt 等:
from ray import tune
def train(config):
acc = your_model(config)
tune.report(mean_accuracy=acc)
tune.run(
train,
config={"lr": tune.grid_search([0.01, 0.001])}
)🔥 自动记录、可视化、早停、调度资源,非常适合实验管理。
4.3 Ray Serve(模型部署框架)
构建微服务风格的 ML API,非常适合和 FastAPI 结合:
from ray import serve
import starlette.requests
@serve.deployment
def my_model(request: starlette.requests.Request):
data = await request.json()
return {"result": your_model(data)}
serve.start()
my_model.deploy()💡 你可以部署多个模型、设置路由、热更新、A/B 实验等。
📌 总览:Ray Serve + FastAPI + vLLM 是什么关系?
Ray Serve 原生支持和 FastAPI、vLLM 结合,可以帮你部署高吞吐、可扩展的大模型推理服务。
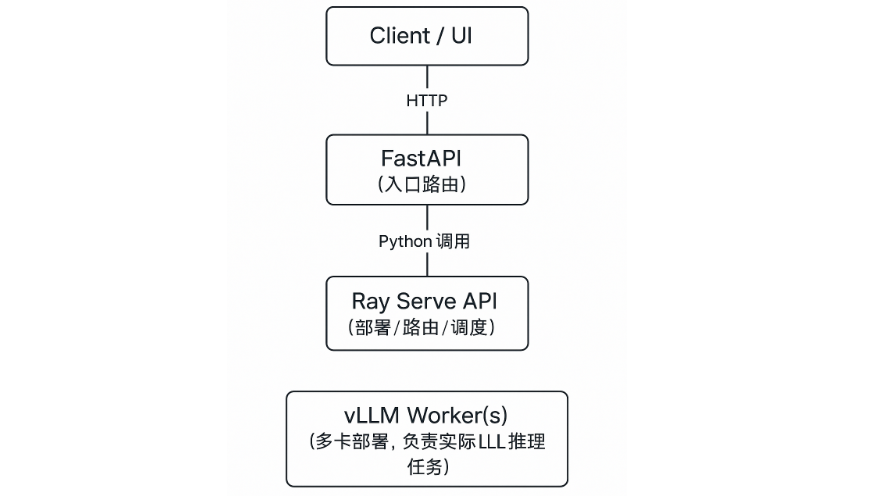
Ray Serve 是一个模型服务框架,能让你像搭积木一样组织模型、API 路由、负载均衡,并部署在多张 GPU 上。它支持将:
-
FastAPI 用作 HTTP 层的路由框架;
-
vLLM 用作实际的大语言模型推理引擎;
-
Ray Serve 做调度和服务组合管理。
🚀 想象成:FastAPI 是前台接待员,vLLM 是模型大脑,Ray Serve 是调度和交通指挥。
1、安装依赖
pip install ray[serve] fastapi uvicorn vllm2、FastAPI + Ray Serve 路由例子
# app.py
import ray
from fastapi import FastAPI, Request
from ray import serve
from vllm import LLM, SamplingParams
ray.init()
app = FastAPI()
@serve.deployment
@serve.ingress(app)
class LLMService:
def __init__(self):
self.llm = LLM(model="meta-llama/Llama-2-7b-chat-hf") # 替换成你要的模型
self.sampling_params = SamplingParams(temperature=0.7, top_p=0.9)
@app.post("/chat")
async def chat(self, request: Request):
data = await request.json()
prompt = data["prompt"]
output = self.llm.generate(prompt, self.sampling_params)
return {"output": output[0].outputs[0].text}
# 启动 Serve
serve.run(LLMService.bind())
3、Ray Serve + vLLM 的真实用法(官方支持)
vLLM 提供了内建的 Ray Serve 模式。命令如下:
python -m vllm.entrypoints.openai.api_server \
--model facebook/opt-13b \
--tensor-parallel-size 2 \
--served-model-name opt \
--distributed-executor-backend ray \
--host 0.0.0.0 \
--port 8000这条命令背后做了什么?
✅ 启动一个 FastAPI OpenAI-compatible 接口
✅ 使用 Ray Serve 管理多个 vLLM Worker(可以横跨多张卡)
✅ 支持多模型部署、多版本、滚动更新(只要你在 Ray Serve 中配置)
Ray为未来AI应用的开发提供了一个灵活、高性能和易用的平台。
技术交流
加入「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶、具身智能、Agent等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
欢迎加入「AIGCmagic社区知识星球」,2025年惊喜特价,扫码领取优惠价格!!
推荐阅读
► AGI新时代的探索之旅:2025 AIGCmagic社区全新启航
► 项目应用:开源视界
► 技术专栏: 多模态大模型最新技术解读专栏 | AI视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏 | 从零走向AGI系列
► 技术综述: 一文掌握视频扩散模型 | YOLO系列的十年全面综述 | 人体视频生成技术:挑战、方法和见解 | 一文读懂多模态大模型(MLLM)|一文搞懂RAG技术范式演变及Agentic RAG|强化学习技术全面解读 SFT、RLHF、RLAIF、DPO|一文搞懂DeepSeek的技术演进之路


















 1715
1715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









