







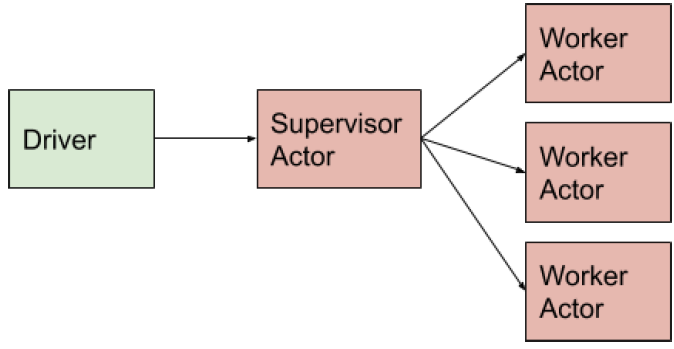
1. Tree of Actors
在Tree of Actors模式中,Ray actor可以监督很多个Ray worker actor。
supervisor参与者的一次调用会触发对子参与者的多个方法调用的分派,在返回之前,supervisor可以处理结果或更新子参与者。
注意:
如果supervisor死亡(driver死亡),worker actor仍会自动工作。
actors可以被嵌套到多个层次以形成一棵树。
示例:
你想要同时训练3个模型,同时能够检查它的状态。
import ray
#定义工人类
@ray.remote(num_cpus=1)
class Worker :
def work (self):
return "done"
#定义监督类
@ray.remote(num_cpus=1)
class Supervisor :
#构造函数
def __init__ (self):
self.workers = [Worker.remote() for _ in range( 3 )] #workers是对象的id
def work (self):
return ray.get([w.work.remote() for w in self.workers]) #通过对象id获取对象的内容
#初始化
ray.init()
sup = Supervisor.remote()
print(ray.get(sup.work.remote())) # outputs ['done', 'done', 'done']
2. Tree of Tasks
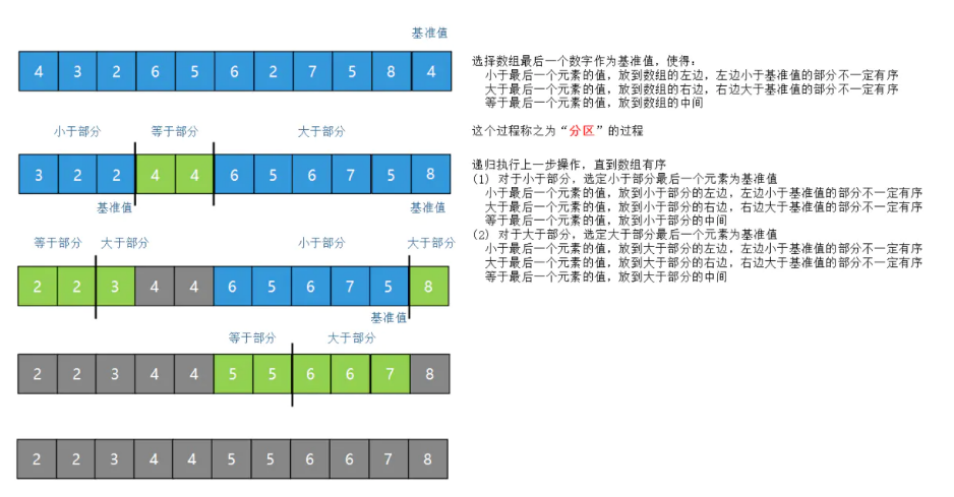
在Tree of Tasks模式中,以递归方式生成远程任务,以对列表进行排序。
在远程函数的定义中,可以调用它自己(quick_sort_distribute .remote)。
对任务的单个调用会触发多个任务的分派。
我们在两次Ray函数调用之后调用Ray.get(),这可以让你最大化工作负载中的并行性。

示例
对4000000长度的列表进行排序,算法是快速排序。
import ray
ray.init()
# 每一次选基点,比大小分区的过程
def partition (collection):
# 使用最后一个元素作为第一个主元
pivot = collection.pop()
# 分别存放大于主元和小于主元的元素
greater, lesser = [], []
for element in collection:
if element > pivot:
greater.append(element)
else:
lesser.append(element)
return lesser, pivot, greater
def quick_sort(collection):
if len(collection) <= 200000 : # magic number
return sorted(collection)
else:
# 递归调用的思想
lesser, pivot, greater = partition(collection)
lesser = quick_sort(lesser)
greater = quick_sort(greater)
# time.sleep(1)
return [lesser]+ [pivot] + [greater]
@ray.remote
def quick_sort_distributed (collection):
if len(collection) <= 200000 : # magic number
return sorted(collection)
else:
# 递归调用的思想
lesser, pivot, greater = partition(collection)
"只有这两句可以并行"
lesser = quick_sort_distributed.remote(lesser)
greater = quick_sort_distributed.remote(greater)
# time.sleep(1)
return ray.get(lesser) + [pivot] + ray.get(greater)
if __name__ == "__main__" :
from numpy import random
import time
unsorted = random.randint( 1000000 , size=( 4000000 )).tolist()
s = time.time()
ray.get(quick_sort_distributed.remote(unsorted))
print( "分布式快速排序: " + str(time.time() - s))
s = time.time()
quick_sort(unsorted)
print( "快速排序: " + str(time.time() - s))

分布式快速排序的时间比快速排序时间长的原因:
快速排序算法本身是一个分而治之的算法,每一层的逻辑结构是不能变的,可以分布式计算的只是左右两边的列表,其他的过程是不可以并行的,具体可以看上面快速排序的示意图。
上面代码中200000是一个魔术数字,因为当是200000时,对4000000的列表调用分布式快速排序, 如果是对半分的话,最多4次,期间来回调用分布式函数,每次分布式计算[2,4,8,16]次,按递归的方式依次循环,反复共享参数,分布计算减少的时间远远小于4次共享数据的时间。当魔术数字为2000000时,只需要分两次,这两次并行计算,时间比魔术数字是200000少,但是仍比快速排序慢。(也可以用谷歌打开网址localhost:8265,查看ray并行计算的过程)。
当递归的次数比较多(叶子节点比较多),分布式计算是有优势的,只是该排序每一次迭代的计算量太小。
在sorted()函数后面添加sleep(1)函数,魔术数字是200000,效果如下:

下面对上述代码做改动:
注:函数的嵌套:@ray.remote内层,外层不一定用。
"更改代码:对排序函数sorted()使用了remote注释"
@ray.remote
def ray_sorted(collection):
return sorted(collection)
def quick_sort_distributed (collection):
if len(collection) <= 200000 : # magic number
sorted_collection = ray_sorted.remote(collection)
return ray.get(sorted_collection)
else:
# 递归调用的思想
lesser, pivot, greater = partition(collection)
lesser = quick_sort_distributed(lesser)
greater = quick_sort_distributed(greater)
return lesser + [pivot] + greater
if __name__ == "__main__" :
from numpy import random
import time
unsorted = random.randint( 1000000 , size=( 4000000 )).tolist()
s = time.time()
quick_sort_distributed(unsorted)
print( "分布式快速排序: " + str(time.time() - s))
s = time.time()
quick_sort(unsorted)
print( "快速排序: " + str(time.time() - s))


再一次分析原因:
分布式计算不是左右两个列表同时计算,而是对小于魔术数字的列表做分布式排序,结果并没有比快速排序的时间短 (猜想:sorted()函数没办法分布式计算,或者效果不明显,因为排序必须是有顺序关系的,查看下面的图也能看到只有一个PID3711起主要作用)但是比上面的分布式排序的时间要短,这再次验证了上面的结论。
3. Map and Reduce
Map and Reduce模式是通过Map任务把一个大任务分成很多小任务,关键就是这些小任务是同时运行的,然后再通过Reduce任务,把很多小任务的结果汇总起来,最后输出汇总结果。
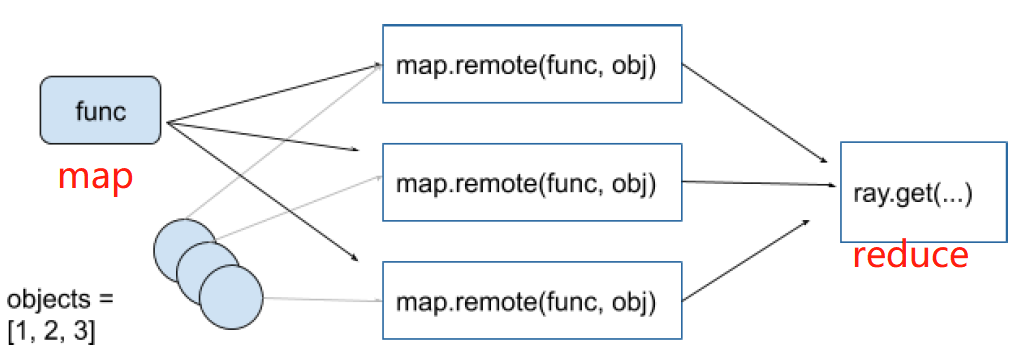
实现通用的map和reduce功能:对0-99之间的每个元素平方求和。
import time
import ray
import numpy as np
#=======================单线程的map:依次计算每个元素的平方=====================
s = time.time()
items = list(range( 100 ))
map_func = lambda i : i* 2
output = [map_func(i) for i in items]
print( "单线程map: " + str(time.time() - s))
#=======================单线程的reduce==========================================
s = time.time()
items = list(range( 100 ))
map_func = lambda i : i* 2
output = sum([map_func(i) for i in items])
print( "单线程reduce: " + str(time.time() - s))
ray.init()
#=======================Ray-多线程map:同时计算每个元素的平方===================
@ray.remote
def map (obj, f):
return f(obj)
s = time.time()
items = list(range( 100 ))
map_func = lambda i : i* 2
output = ray.get([map.remote(i, map_func) for i in items])
print( "Ray-多线程map: " + str(time.time() - s))
#=======================Ray-多线程reduce========================================
@ray.remote
def map (obj, f):
return f(obj)
@ray.remote
def sum_results (*elements):
return np.sum(elements)
items = list(range( 100 ))
map_func = lambda i : i* 2
remote_elements = [map.remote(i, map_func) for i in items]
# simple reduce
s = time.time()
remote_final_sum = sum_results.remote(*remote_elements)
result = ray.get(remote_final_sum)
print( "Ray-多线程simple reduce: " + str(time.time() - s))
# tree reduce
s = time.time()
intermediate_results = [sum_results.remote(
*remote_elements[i * 20 : (i + 1 ) * 20 ]) for i in range( 5 )]
remote_final_sum = sum_results.remote(*intermediate_results)
result = ray.get(remote_final_sum)
print( "Ray-多线程tree reduce: " + str(time.time() - s))

结论:
分布式计算数据之间没有太多的共享数据,只是共享一个数值,而不是上一个例子中的列表。
4. 使用ray.wait 限制进行中的任务数量
当您提交一个ray任务或actor调用时,ray将确保worker可以使用数据。 然而,如果你迅速地提交太多的任务,worker可能会超载并耗尽内存。您应该使用ray.wait()来阻塞,直到有一定数量的任务准备就绪。Ray Serve使用此模式来限制每个进行中的worker的查询数。
import time
import ray
import numpy as np
ray.init()
#Without backpressure
@ray.remote
class Actor :
def heavy_compute (self, large_array):
return 0
#taking long time...
actor = Actor.remote()
result_refs = []
s=time.time()
for i in range(100):
large_array = np.zeros(100)
result_refs.append(actor.heavy_compute.remote(large_array))
results = ray.get(result_refs)
print( "没有使用ray.wait(): " + str(time.time() - s))
可以简单的修改上面的示例,以便上一个任务完成时自适应地启动新任务。
ready_ids, remaining_ids=ray.wait(result_refs, num_returns=num_ready)
ready_ids是一个对象IDs列表,它对应的任务已完成执行,而remaining_ids是剩余的对象IDs列表。
当result_refs=12时,10个在ready_ids中,2个在remaining_ids;当result_refs=22时,第一次的10个有结束的,往后顺延直到10个,比如顺延到19,则num_ready=3。
#With backpressure
result_refs = []
s=time.time()
for i in range(100):
large_array = np.zeros(100)
if len(result_refs) > 10 :
num_ready = i -10
ready_ids, remaining_ids=ray.wait(result_refs, num_returns=num_ready)
result_refs.append(actor.heavy_compute.remote(large_array))
print( "使用ray.wait(): " + str(time.time() - s))


















 2243
2243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









