







本博客会从一个从未部署过任何环境的电脑上一步步复现如何本地训练自定义模型并成功部署到Maixcam上实现数字识别的功能。
文章中会引用到我当时学习是参考到的文章,都会在下面列出来,在此对这些向我提供过帮助的博主表示感谢!!
本文中默认读者已经了解过相对应的知识,一些非常详细的操作我会引用一些文章。
写在前面:
参考一下我自己的电脑版本
| 系统 | Windows11 |
| 显卡 | NVIDA Geforce 3060 Laptop |
1.1 Pytorch框架的搭建
截至至本文书写当前,所用的软件版本如下
| Anaconda版本 | Anaconda3-2024.06-1-Windows-x86_64 |
| 用于虚拟环境的Python版本 | 3.10.15 |
教程已经写的非常明白了,我在下面贴上自己所使用的Pytorch版本,挂梯子打开页面~

配置清华下载源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
常用的指令我就直接放在下面了~
conda info --envs //查看配置的所有虚拟环境信息
conda create -n yolov5_test python=3.10 //创建一个名为yolov5_test的环境,其使用python版本为3.10
conda activate yolov5_test //激活yolov5_test环境,这个时候我们看见最左边的括号变为pytorch
conda deactivate //退出当前激活的虚拟环境
conda remove -n yolov5_test --all //移除yolov5_test环境
我在这里创建了一个基于python3.10.15的虚拟环境,命名为yolov5_test,里面已经安装好了Pytorch框架。
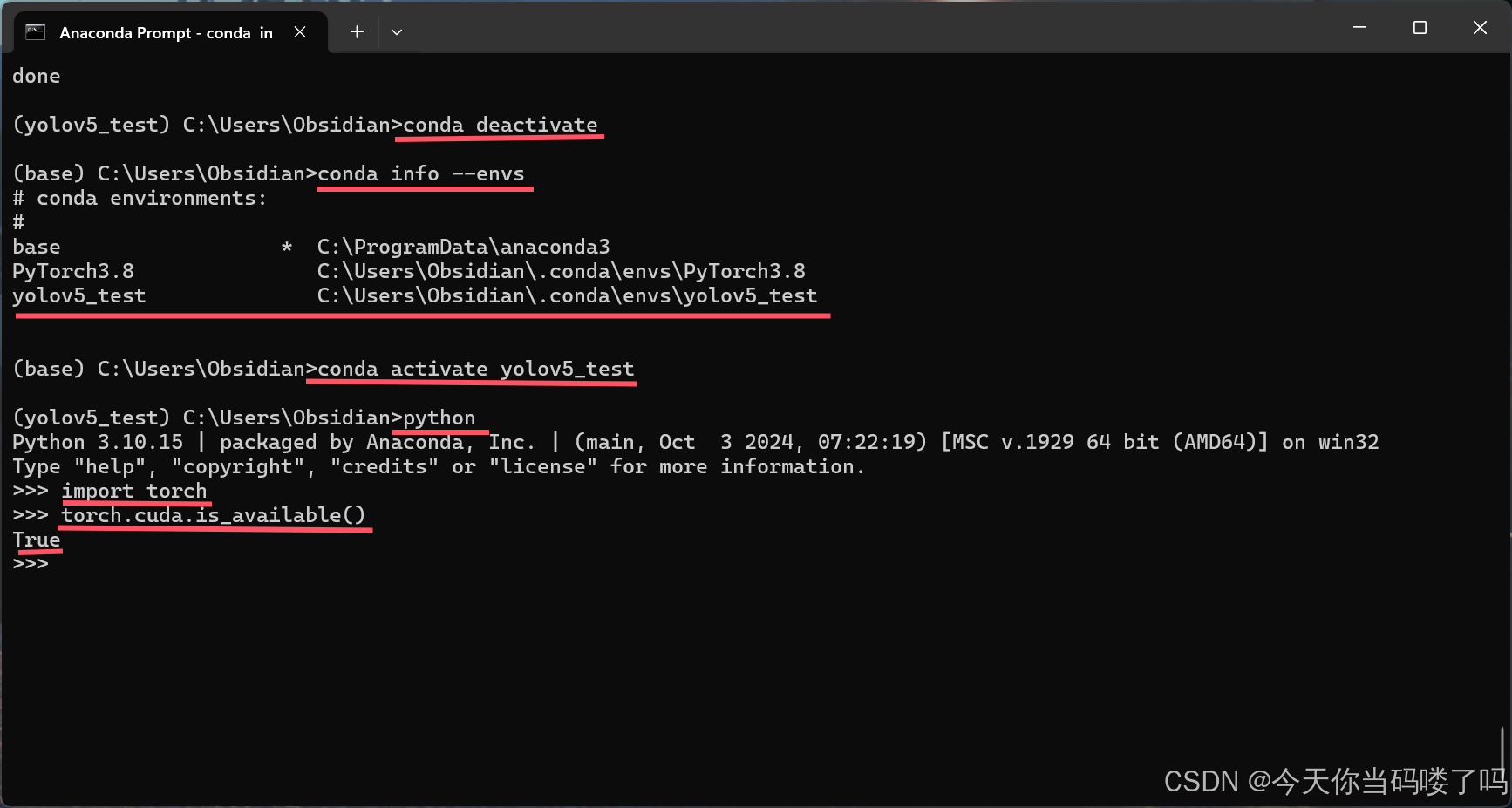
验证是否安装成功
在yolov5_test环境下输入python
依次输入
import torch
torch.cuda.is_available()
若返回True则说明安装成功
1.2 CUDA+CUDNN的安装
这里附上我所使用的CUDA和CUDNN的版本
| CUDA版本 | cuda_11.8.0_522.06_windows |
| CUDNN版本 | cudnn-windows-x86_64-8.9.6.50_cuda11-archive |
具体的安装教程可以参考这篇博客:CUDA安装教程(超详细)
Tips:尽量安装在默认路径!!!不然出现一些莫名其妙的错误还是得卸了重装。

建议尽量与我的版本保持一致。
1.3 下载Pycharm
请自行到微信公众号或者其它网站上搜索下载方法,这里不做讲解。
1.4 拉取Yolov5s的源码
上GitHub拉取一下源码 https://github.com/ultralytics/yolov5

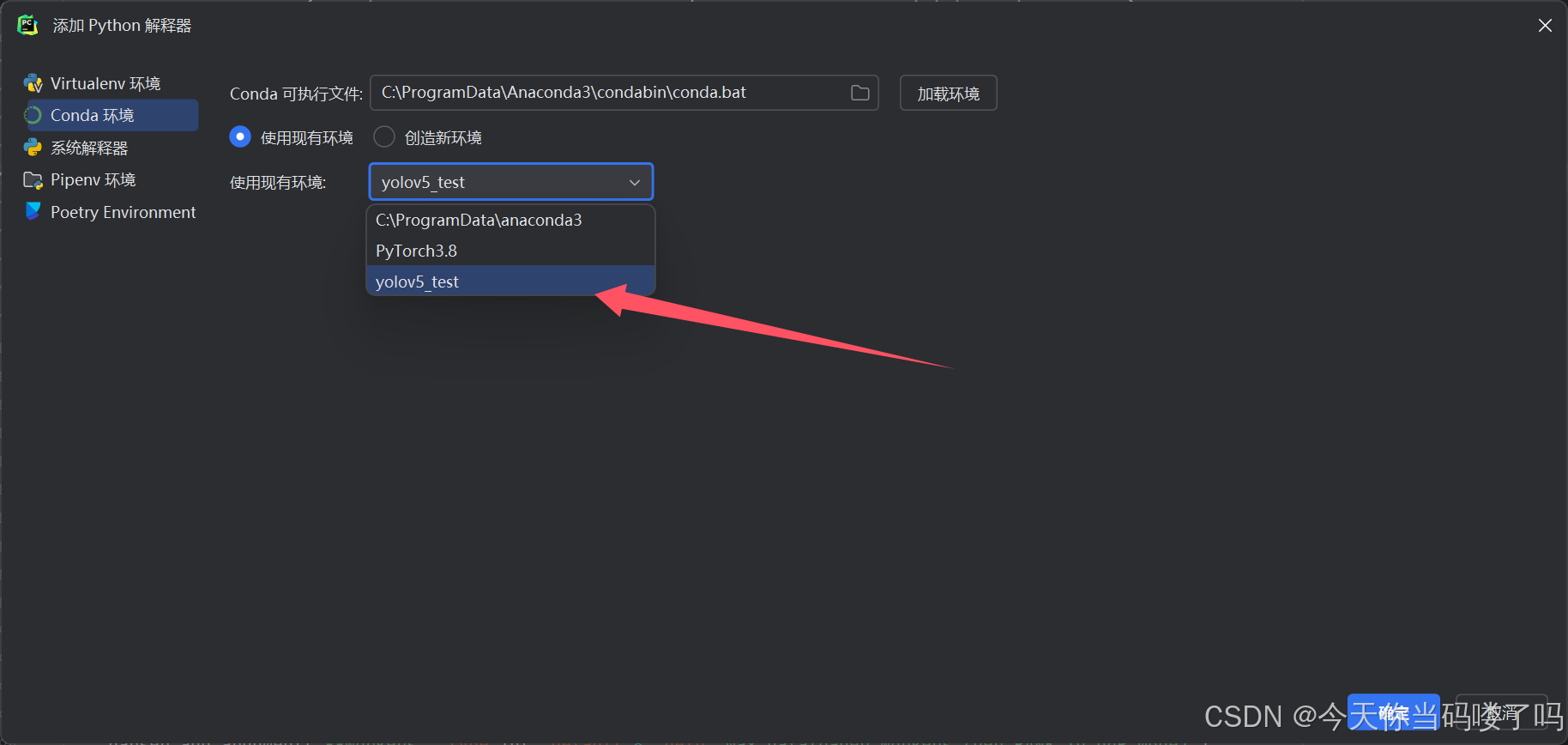
将下载的压缩包解压之后放在自己存放python代码的文件夹中,用pycharm打开后,打开设置,将刚刚创建好的Conda环境添加进来作为解释器,如下图。
双击打开项目中requirements.txt文件,可以发现,这个文件是运行yolov5所必需的一些软件包,我们在终端-本地中运行下列代码,即可正常安装所需要的软件包
Tips:当挂载镜像源下载的时候千万不要挂梯子!
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

1.5 测试能否运行示例
安装完成后,我们双击打开detect.py文件并运行
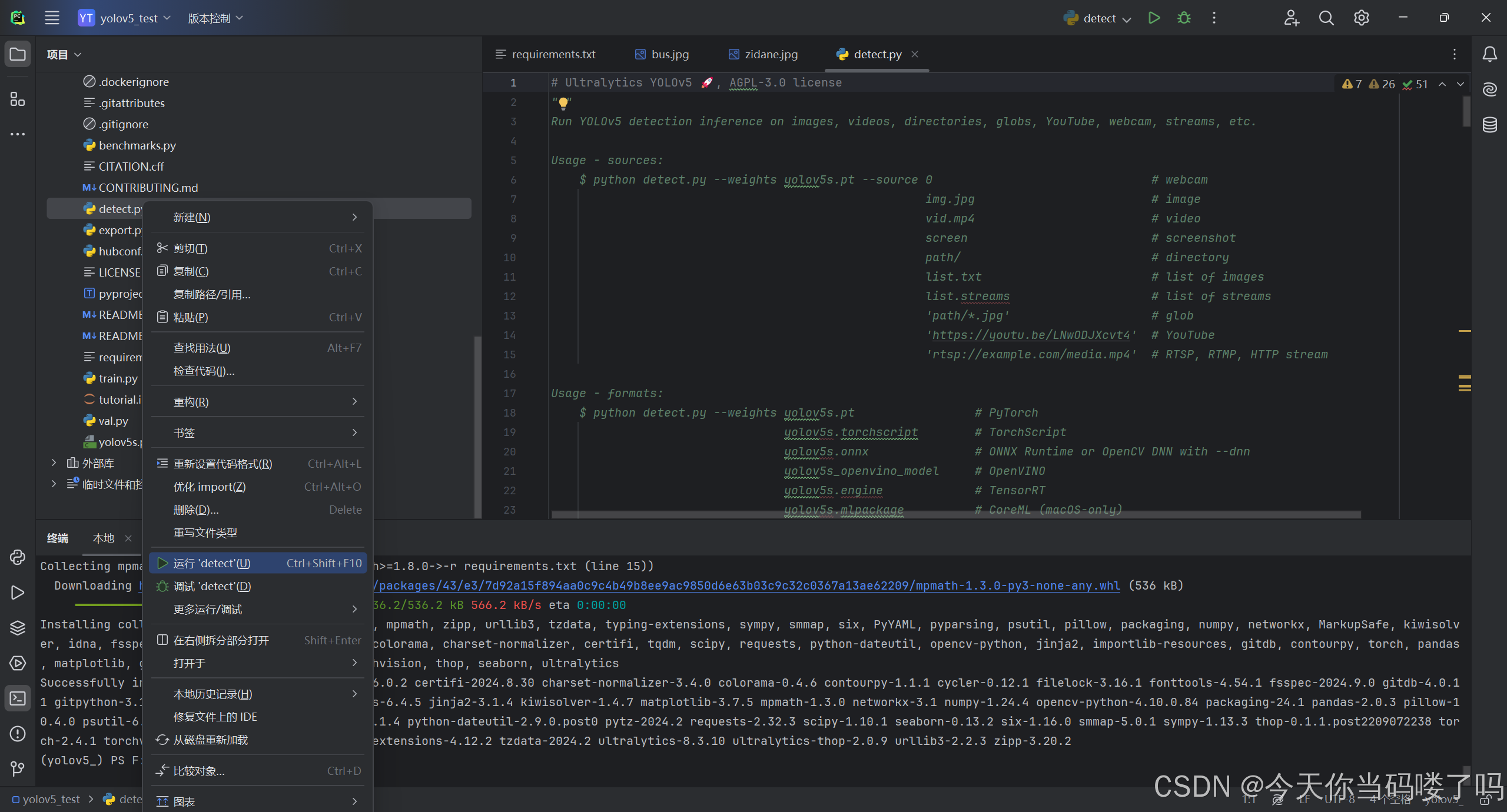
由于此时我们并没有下载预训练权重文件,而运行detect.py需要,如果是在线下载的话速度过慢,故我们直接通过github的连接下载。
获得预训练权重
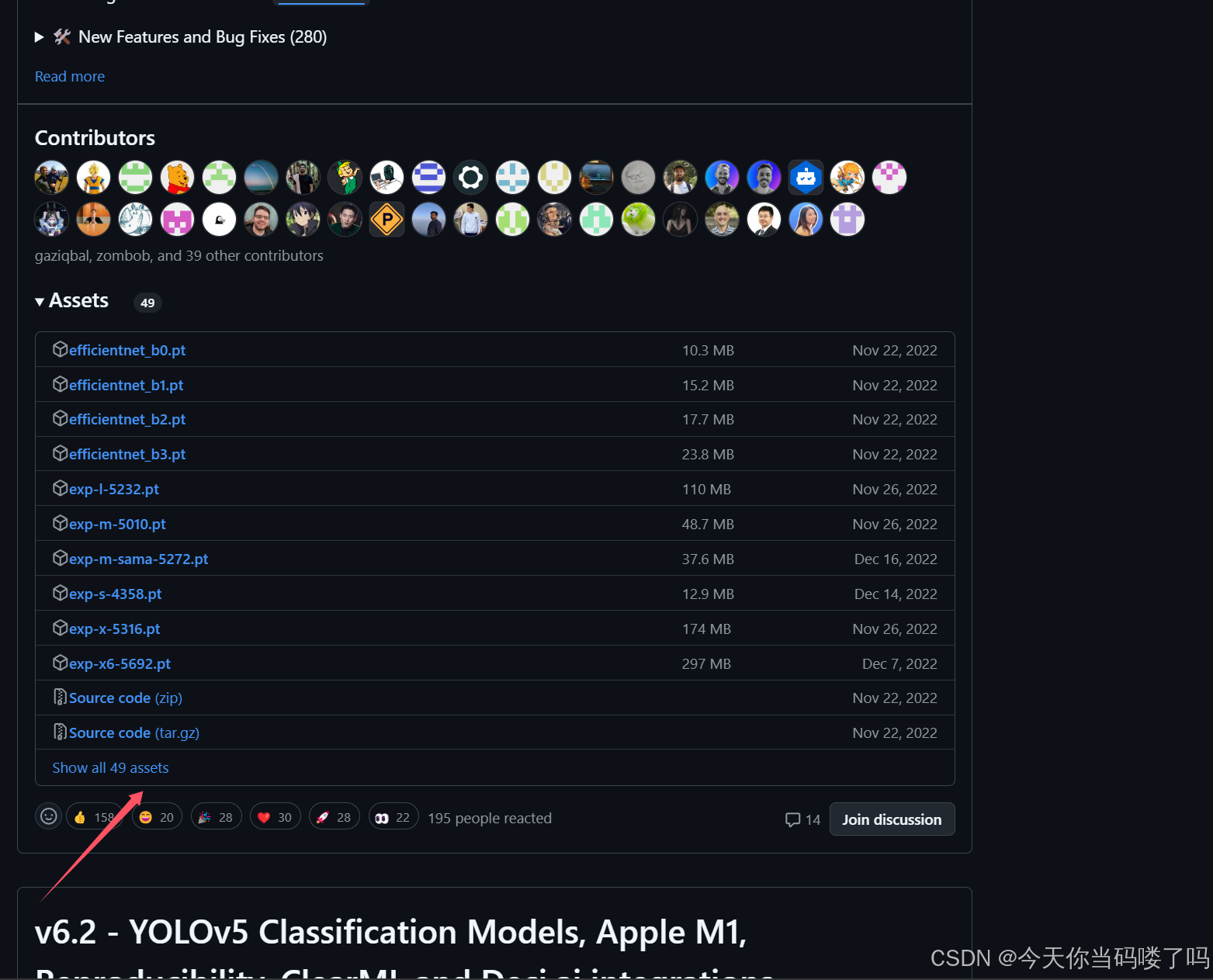
一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过下面给出的网址进行下载,本次测试示例和训练自己的数据集用的预训练权重为yolov5s.pt。
https://github.com/ultralytics/yolov5/releases
我们点击 Show all 49 assets,展开后即可找到yolov5s.pt 下载后移动至项目文件夹即可。
运行detect.py完成后,可以通过查看runs文件夹下的detect/exp查看对应的预测照片。
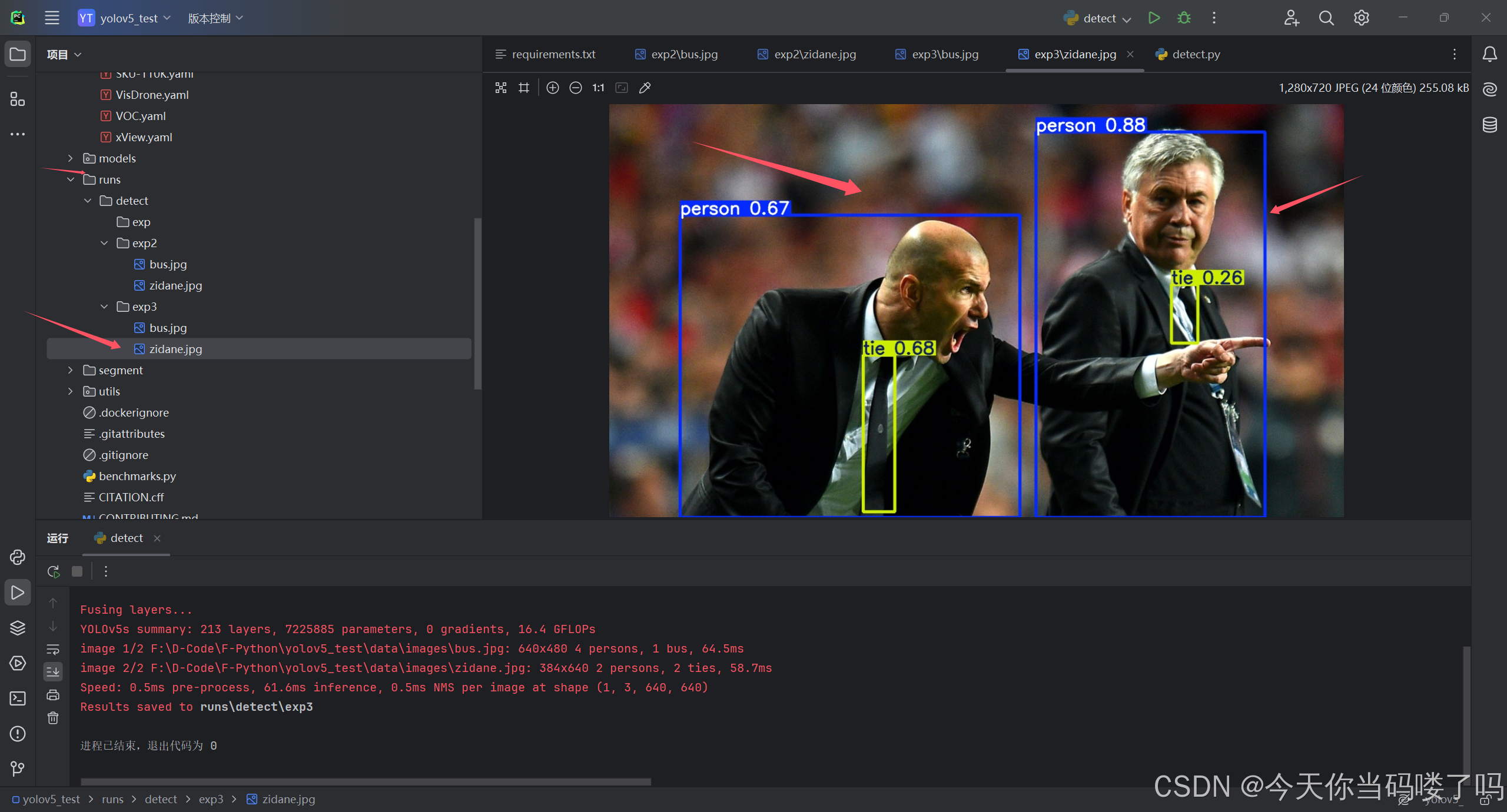
至此,我们的拉取源码,环境配置检测部分已经结束了,接下来的部分就是自己训练自定义模型的过程。
资料如图所示:
通过百度网盘分享的文件:资料.zip
链接:https://pan.baidu.com/s/16h4Th9UbOF9YfJEgItYwYA?pwd=6969
提取码:6969

















 2307
2307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









