






以上是原文,以下是笔者笔记
由于笔者对这一部分原理比较了解,所以本文只对代码进行整理记录,可根据需要查看。
本文的主要内容:神经网络的骨架Module,各种layer(卷积层,池化层,线性层)的构造,激活函数的使用,loss(损失),backward(反向传播),optimizer(优化器)
以及对现有模型的使用和修改,网络模型的保存与读取
一,卷积层
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
# 构造卷积层
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
# 首先让x经过一个卷积层
x=self.conv1(x)
return x
mymodule=MyModule()
writer=SummaryWriter("logs")
for i in range(10):
img,target=test_set[i]
input=img #彩色图像所以in_channels=3,符合要求 input:1*3*32*32
output = mymodule(input) #output:1*6*30*30
# 由于writer.add_image输入只能是 1*3*h*w add_images输入只能是x*3*h*w 所以要把output尺寸改一下
output=torch.reshape(output,(-1,3,30,30)) #batch_size channel h w
# -1 的意思是让它自己算这里应该是什么值,而不是真的是-1
# 这里算出来是2 也就是说batch_size=2 那就要用add_images(),而不是add_image()
writer.add_images("output_conv",output,i)
writer.close()
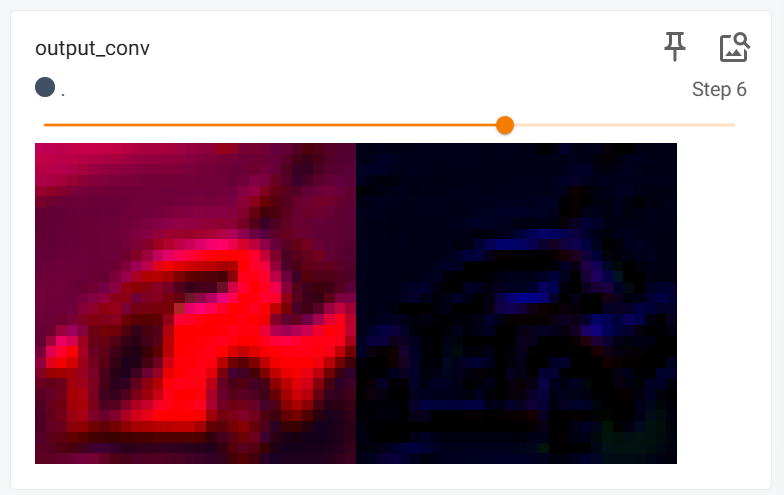


也可以把下面的部分改成这样
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
test_loader=DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
# 构造卷积层
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
# 首先让x经过一个卷积层
x=self.conv1(x)
return x
mymodule=MyModule()
writer=SummaryWriter("logs")
for idx,(imgs,targets) in enumerate(test_loader):
input=imgs #彩色图像所以in_channels=3,符合要求 input:64*3*32*32
output = mymodule(input) #output:64*6*30*30
# 由于writer.add_image输入只能是 1*3*h*w add_images输入只能是x*3*h*w 所以要把output尺寸改一下
output=torch.reshape(output,(-1,3,30,30)) #batch_size channel h w
# -1 的意思是让它自己算这里应该是什么值,而不是真的是-1
# 这里算出来是128 也就是说batch_size=128 那就要用add_images(),而不是add_image()
writer.add_images("output_conv",output,idx)
writer.close()




二,各种layer的构造,激活函数的使用
最大池化层相关参数解释
Kernel_size是指核的大小,如果只输入一个数n,则为n*n大小的核
stride默认是Kernel_size大小
padding默认为零
ceil_model: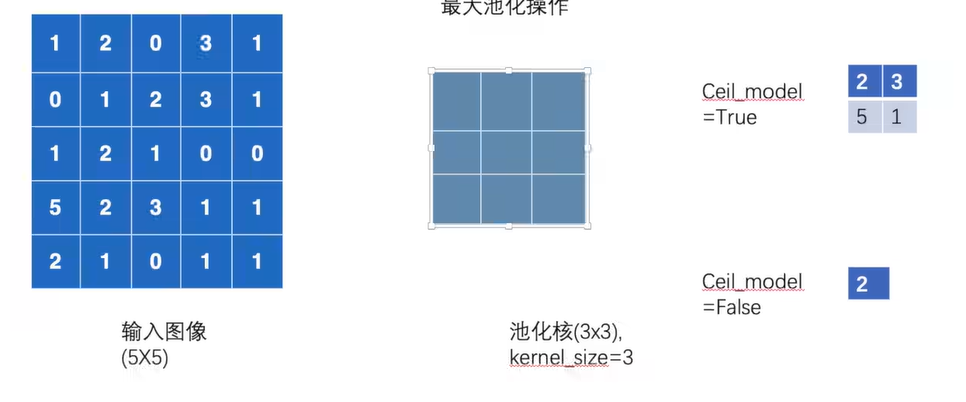
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, ReLU
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
test_loader=DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
# 构造卷积层
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
# 池化层
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=False)
# 展平
self.flatten=Flatten()
# 线性层
self.linear1=Linear(600,64)
# 非线性激活函数
self.relu=ReLU()
# 再经过一个线性层,十分类任务,所以为10
self.linear2=Linear(64,10)
def forward(self,x):
# 首先让x经过一个卷积层
x=self.conv1(x)
# 再让x经过一个池化层
x=self.maxpool1(x)
# 把x展平变为batch_size*1*1*1
x=self.flatten(x)
x=self.linear1(x)
x=self.relu(x)
x=self.linear2(x)
return x
mymodule=MyModule()
for imgs,targets in test_loader:
input=imgs
#彩色图像所以in_channels=3,符合要求 input:64*3*32*32
#经过一层卷积 output:64*6*30*30
#经过一层最大池化 output:64*6*10*10
#展平 output:64*600(64是batch_size) (当然这一步也可以通过reshape来实现->(64,1,1,-1)->64*1*1*600)
#64*600->64*64->64*10
output = mymodule(input) #output:64*10
print(output.shape)
writer = SummaryWriter("logs")
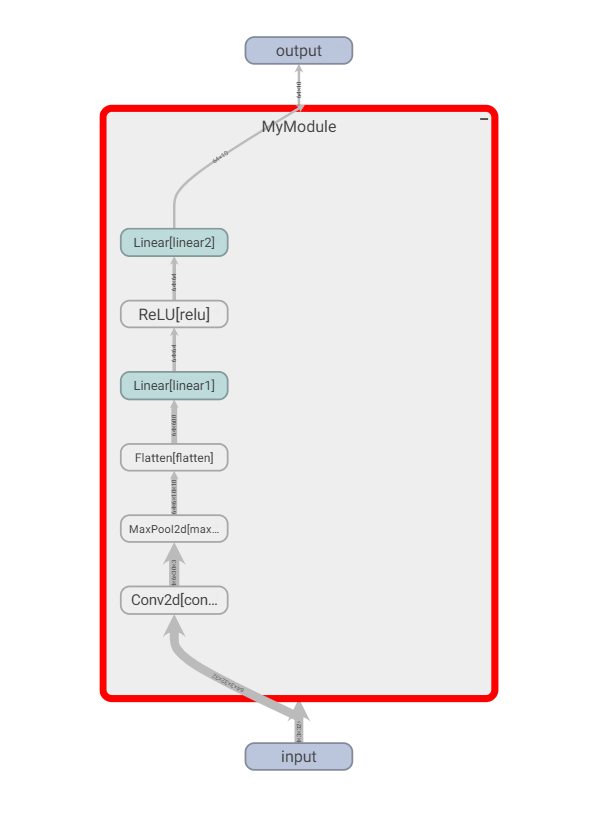
writer.add_graph(mymodule, input)
writer.close()
break
结果:![]()
也可以使用sequential,简化代码
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, ReLU, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
test_loader=DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0),
MaxPool2d(kernel_size=3, ceil_mode=False),
Flatten(),
Linear(600, 64),
ReLU(),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
mymodule=MyModule()
for imgs,targets in test_loader:
input=imgs
output = mymodule(input) #output:64*10
print(output.shape)
writer = SummaryWriter("logs")
writer.add_graph(mymodule, input)
writer.close()
break
三,loss,backward,optimizer
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, ReLU, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
test_loader=DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0),
MaxPool2d(kernel_size=3, ceil_mode=False),
Flatten(),
Linear(600, 64),
ReLU(),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
mymodule=MyModule()
loss=nn.CrossEntropyLoss() #交叉熵损失
optim=torch.optim.SGD(mymodule.parameters(),lr=0.01)
# 前一个参数指明需要更新的参数是那些 后一参数是指学习率learning rate
for epoch in range(4):
loss=0
for imgs,targets in test_loader:
outputs = mymodule(imgs) #output:64*10
result_loss=loss(outputs,targets)
optim.zero_grad() # 把梯度清零
result_loss.backward() # 反向传播计算梯度
optim.step() # 根据反向传播计算出的梯度对参数进行更新
loss+=result_loss
print(loss)
我报错了,大家猜猜什么原因
![]()
原因竟然是因为loss!!!!!!是函数名也是变量名,我哭了,把变量名改一下就好了
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, ReLU, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
test_loader=DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0),
MaxPool2d(kernel_size=3, ceil_mode=False),
Flatten(),
Linear(600, 64),
ReLU(),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
mymodule=MyModule()
loss=nn.CrossEntropyLoss() #交叉熵损失
optim=torch.optim.SGD(mymodule.parameters(),lr=0.01)
# 前一个参数指明需要更新的参数是那些 后一参数是指学习率learning rate
for epoch in range(4):
total_loss=0
for imgs,targets in test_loader:
outputs = mymodule(imgs) #output:64*10
result_loss=loss(outputs,targets)
optim.zero_grad() # 把梯度清零
result_loss.backward() # 反向传播计算梯度
optim.step() # 根据反向传播计算出的梯度对参数进行更新
total_loss+=result_loss
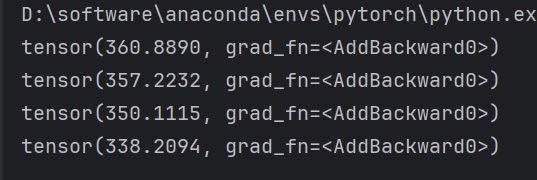
print(total_loss)
好啦,结果如下
三,对现有模型的使用和修改,网络模型的保存与读取
import torchvision
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_true=torchvision.models.vgg16(pretrained=True)
print(vgg16_false)
print(vgg16_true)pretrained是是否加载预训练权重的意思
vgg16_false和vgg16_true模型的结构一样只是模型的权重参数不同
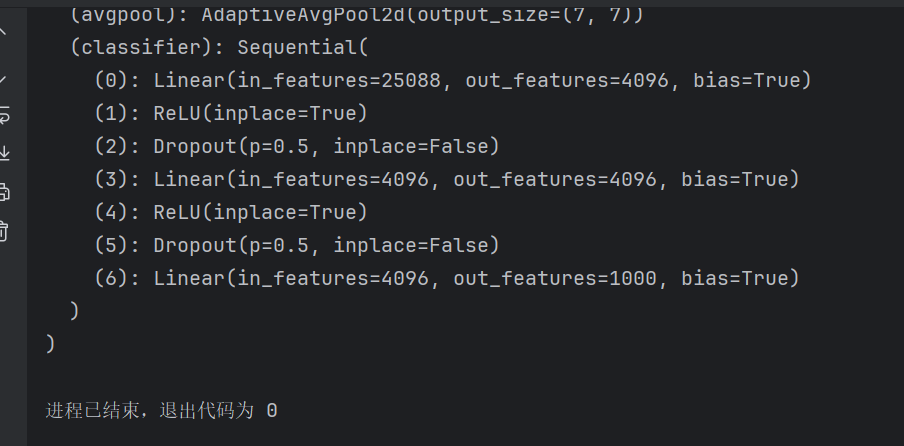
可以看到该模型是个1000分类问题,如果我们想把它应用到十分类问题上,可以这样修改
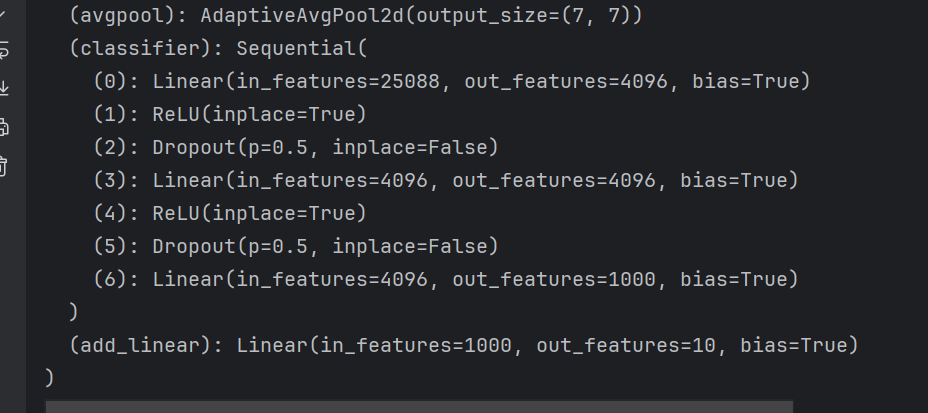
vgg16_true.add_module('add_linear',nn.Linear(1000,10))这样的话模型的结构为:
也可以这样:
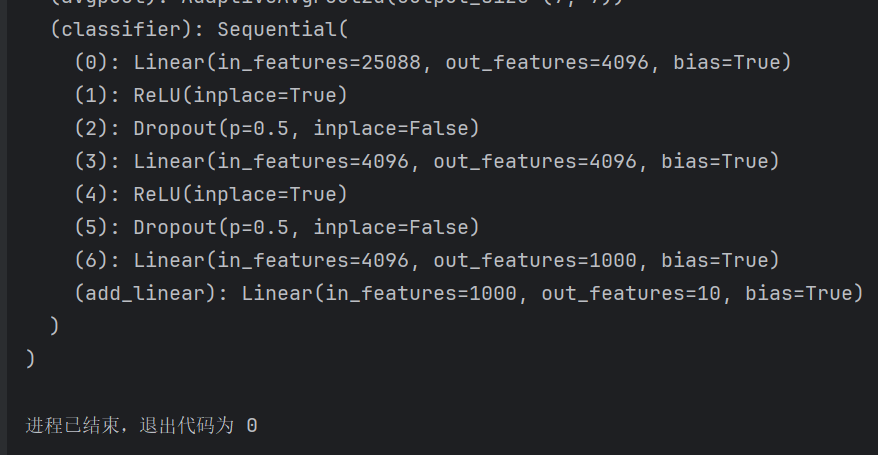
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))这样的话模型的结构为:
如果我们想保存刚刚修改好的模型可以这样做:
import torchvision
import torch
from torch import nn
vgg16_true=torchvision.models.vgg16(pretrained=True)
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
# 保存方式一:保存模型结构+参数
torch.save(vgg16_true,"vgg16_true_med1.pth")
# 保存方式二:仅保存模型参数(且保存为了字典形式)
torch.save(vgg16_true.state_dict(),"vgg16_true_med2.pth")不一定非要保存成.pth文件,但是习惯上会这么做
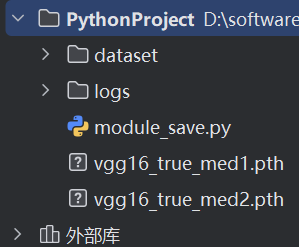
可以看到模型已经保存了:
模型的保存与加载:
model_save.py:
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear, ReLU
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.model1=Sequential(
Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0),
MaxPool2d(kernel_size=3, ceil_mode=False),
Flatten(),
Linear(600, 64),
ReLU(),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
mymodule=MyModule()
# 保存模型
# 方式一(保存模型结构和参数)
torch.save(mymodule,"mymodule_med1.pth")
# 方式二(保存模型的参数)
torch.save(mymodule.state_dict(),"mymodule_med2.pth")
model_load.py:
import torch
from model_save import *
# 加载模型
# 加载通过方式一保存的模型(保存了模型结构和参数)
model=torch.load("mymodule_med1.pth",weights_only=False)
print(model)
# 打印的是模型的结构
# 但其实model中有模型的参数和结构,而且参数是训练好的
# (假设model.py保存模型的时候,模型已经训练好了)
# 加载通过方式二保存的模型(保存了模型的参数)
model=torch.load("mymodule_med2.pth",weights_only=False)
print(model)
# 打印的是一个字典型的
# 此时model只包含了模型的参数,参数是训练好的
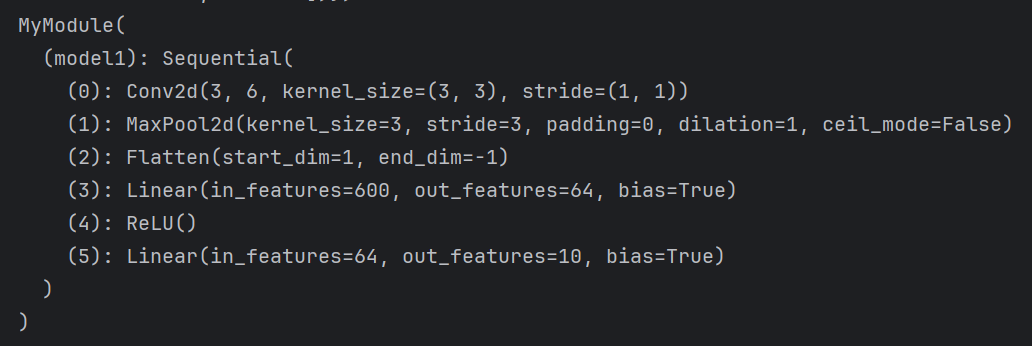
mymodule.load_state_dict(model)
# 相当于结合了mymodule的结构和model的参数
print(mymodule)
# 打印的是模型的结构 但此时mymodel中有模型的参数和结构,而且参数是训练好的第一个print的结果:
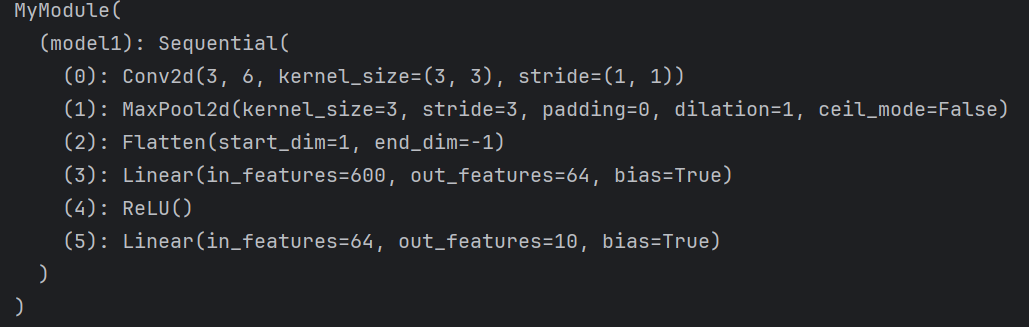 第二个print的结果:
第二个print的结果:
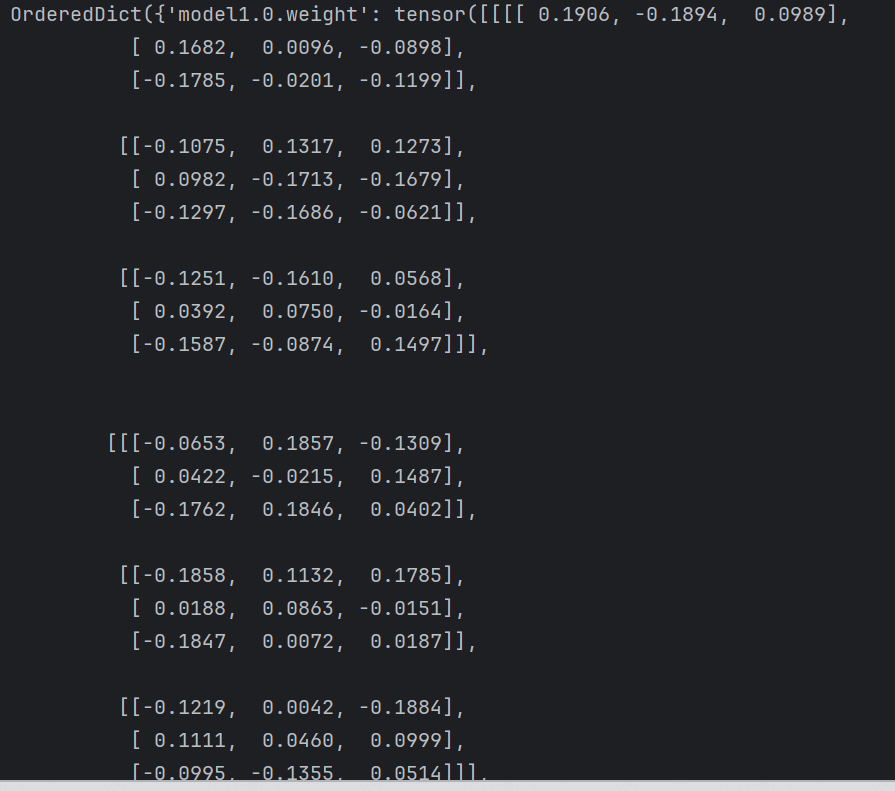
第三个print的结果:

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









