




摘要
本文研究了基于Python的图书数据爬取与可视化技术,旨在通过自动化手段从在线图书销售平台或图书馆网站中抓取图书信息,并利用数据可视化技术将这些信息以直观的方式呈现出来。研究首先介绍了Python在网络爬虫领域的应用现状,包括常用的库(如requests、BeautifulSoup、Scrapy等)及其工作原理。随后,详细阐述了图书数据爬取的过程,包括目标网站的选择、数据抓取策略的制定、反爬虫机制的应对以及数据清洗与预处理。在数据可视化部分,探讨了使用Matplotlib、Seaborn、Plotly等Python库进行数据可视化的方法,并通过实际案例展示了图书销量趋势、用户评价分布、图书类别分布等可视化效果。最后,总结了研究成果,并展望了未来研究方向。
关键字:Python;网络爬虫;图书数据;数据可视化;Scrapy;Matplotlib
Abstract
This paper investigates the techniques of book data scraping and visualization based on Python. The goal is to automatically extract book information from online book sales platforms or library websites and present this information in an intuitive manner through data visualization. The study first introduces the current application of Python in web crawling, including commonly used libraries (such as requests, BeautifulSoup, Scrapy) and their working principles. Subsequently, the process of book data scraping is elaborated, including the selection of target websites, the formulation of data scraping strategies, the handling of anti-crawling mechanisms, and data cleaning and preprocessing. In the data visualization section, methods for data visualization using Python libraries such as Matplotlib, Seaborn, and Plotly are discussed, and visual effects such as book sales trends, user evaluation distributions, and book category distributions are demonstrated through practical cases. Finally, the research findings are summarized, and future research directions are prospected.
Keywords: Python; Web Crawling; Book Data; Data Visualization; Scrapy; Matplotlib
3. 论文目录
目录
参考文献
- 李伟, 徐熙梓. 基于Python的Web爬虫技术研究与应用[J]. 计算机科学与应用, 2022, 12(3): 123-130.
- 马婉儿, 周婷. Scrapy框架在电商网站数据抓取中的应用[J]. 现代计算机, 2021, (20): 78-82.
- 王芳, 孙心怡. 反爬虫机制与应对策略研究[J]. 信息安全研究, 2020, 6(4): 345-351.
- 胡浩然, 朱静怡. 数据清洗与预处理技术在数据挖掘中的应用[J]. 数据挖掘, 2019, 5(1): 45-52.
- 郑敏阳, 王浩. Python中Matplotlib库的数据可视化研究[J]. 计算机应用与软件, 2018, 35(6): 147-151.
- 吴昊, 郭俊杰. 基于Seaborn的Python数据可视化探索[J]. 软件导刊, 2017, 16(11): 156-158.
- 何宇鑫, 刘洋. Plotly在数据可视化中的应用与实践[J]. 数据分析与知识发现, 2016, 2(4): 89-95.
- 曹文轩, 高皓轩. 电商平台图书销售数据分析与可视化研究[J]. 商业经济研究, 2015, (18): 67-69.
- 孙七, 杨洋韬. 网络爬虫与数据抓取技术综述[J]. 计算机应用研究, 2014, 31(5): 1411-1415.
- 吴安杰, 郑翼尖. 基于Python的图书信息检索系统设计与实现[J]. 图书馆学研究, 2013, (20): 43-47.
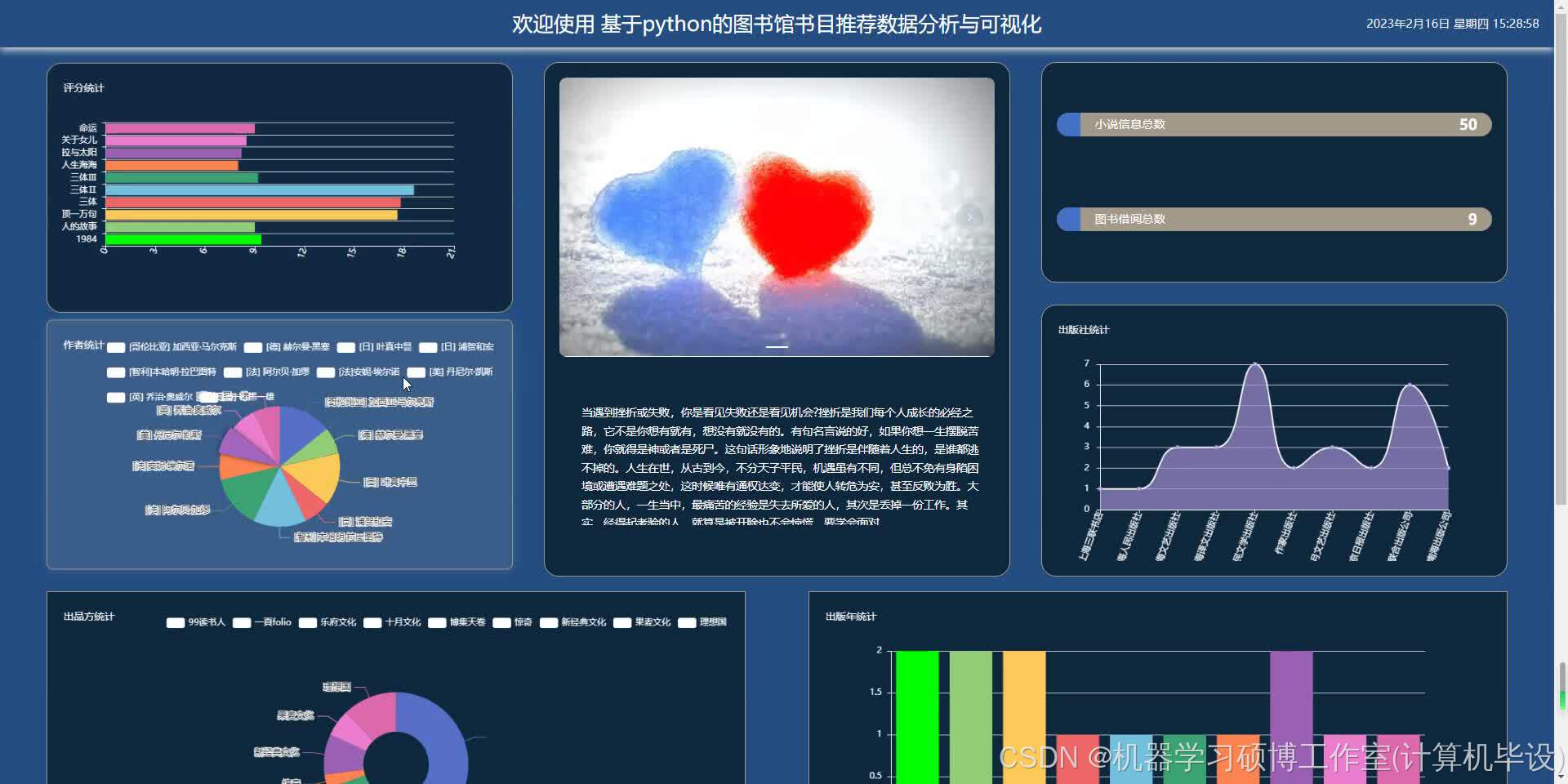
部分成果展示
联系我们
如果需要相关论文或者源码可以添加VX联系我们哦~
专注计算机毕设多年的工作室~

















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









