







因为模型跑起来太慢了,所以想要运用tensorrtx进行加速。但是这个是有难度的,且网络上的教程大多写的不是很好。我将以一个新人的视角,从头开始部署基于yolov5的tensorrtx加速。
知识补充:TensorRT和TensorRTX的区别
tensorRT是英伟达出的模型加速推理的SDK,tensorrtx是wangxinyu大佬自己写的通过tensorrt的API直接构建网络的进行模型部署的方案。简单来说就是tensorrtx是教你怎么用tensorRT部署模型的。你要做YOLOv5的模型部署,直接按照tensorrtx上的教程一步一步来就行了。
官方:
NVIDIA/TensorRT: NVIDIA® TensorRT™ is an SDK for high-performance deep learning inference on NVIDIA GPUs. This repository contains the open source components of TensorRT. (github.com)
一个大佬写的基于官方构建的API调用:wang-xinyu/tensorrtx: Implementation of popular deep learning networks with TensorRT network definition API (github.com)
一:TensorRT的安装
Windows+Anaconda配置TensorRT环境-优快云博客
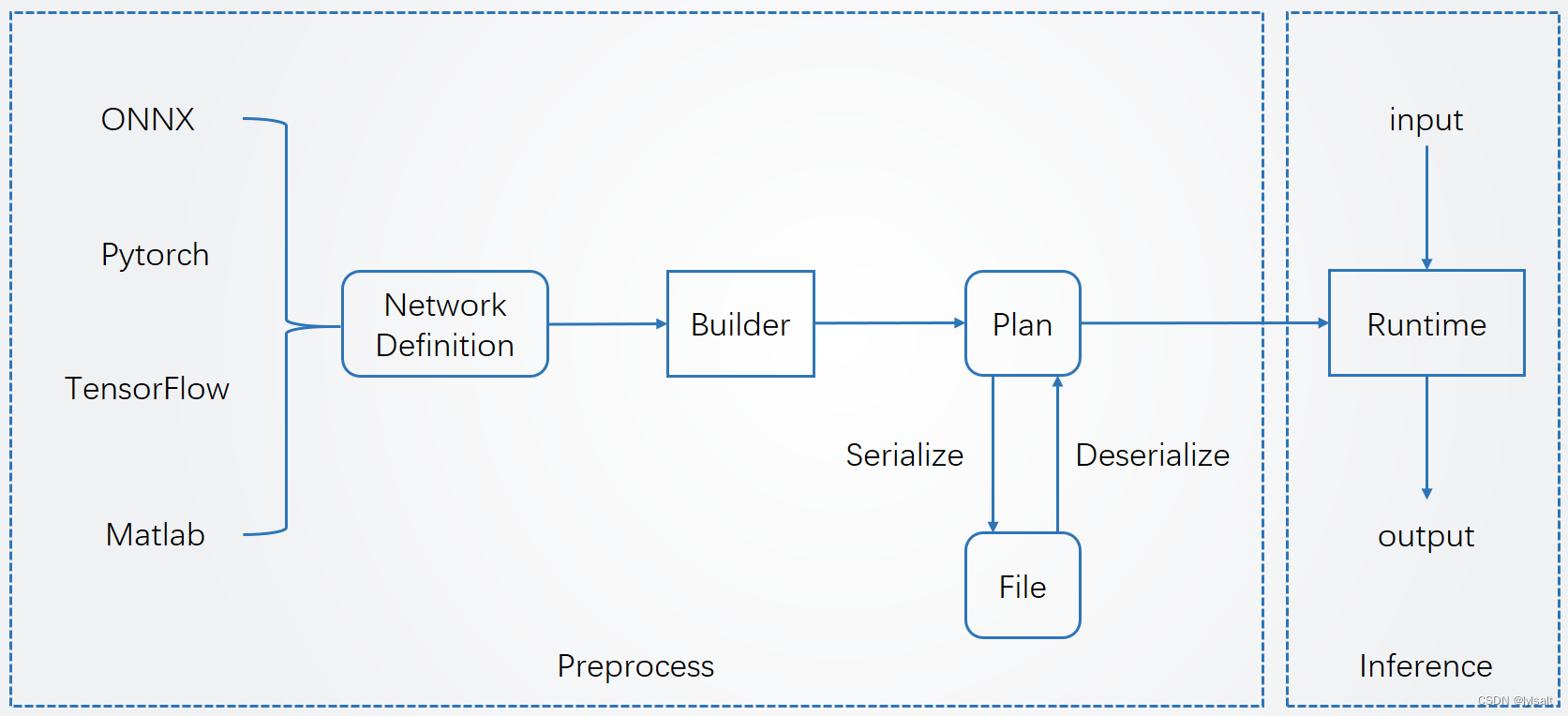
简要介绍一下TensorRT的使用流程
TensorRT的使用流程如下图所示,分为两个阶段:预处理阶段和推理阶段。其部署流程大致如下:1.导出网络定义以及相关权重 2.解析网络定义以及相关权重 3.根据显卡算子构造出最优执行计划 4.将执行计划序列化存储 5.反序列化执行计划 6.进行推理
可以从步骤3得知,tensorrt实际是和硬件关系密切的,所以在部署过程中,如果硬件(显卡)和软件(驱动、cudatoolkit、cudnn)发生了改变,那么从这一步开始就要重新走一遍了。
二:将Pytorch(.pt)模型转为onnx模型
这一步主要是为了将深度学习模型的结构和参数导出来。考虑到实际部署环境的精简性,我这里还是建议大家在使用中先将深度学习模型导出ONNX文件,然后拿着ONNX文件去部署就可以了。
原因很简单,因为ONNX不像Pytorch和TensorFlow那样,还需要安装这些框架运行的依赖包(比如 conda install pytorch,不然你没办法用pytorch的代码),TensorRT可以直接从ONNX文件中读取出网络定义和权重信息。
除此以外,ONNX更像是“通用语言”,ONNX的出现本身就是为了描述网络结构和相关权重,除此以外,还有专门的工具可以对ONNX文件进行解析,查看相关结构,例如网站:https://lutzroeder.github.io/netron/
可以直接将onnx文件拖进去,查看网络结构。
Yolov5 export.py实现onnx模型的导出-优快云博客
三:ONNX模型转换为TensorRT模型
3.1将ONNX转为TensorRT的格式
trtexec的介绍:
TensorRT入门:trtexec开发辅助工具的使用-优快云博客
将ONNX转成TensorRT engine的方式有多种,其中最简单的就是使用trtexec工具。在上面已经将Pyotrch中的.pt格式转成ONNX格式了,接下来可以直接使用trtexec工具将其转为TensorRT engine格式:
trtexec --onnx=resnet34.onnx --saveEngine=trt_output/resnet34.trt
其中:
- --onnx是指向生成的onnx模型文件路径
- --saveEngine是保存TensorRT engine的文件路径(发现一个小问题,就是保存的目录必须提前创建好,如果没有创建的话就会报错)
在进行trtexec之前,还需要将trtexec.exe即D:\TensorRT-8.6.1.6\bin添加到环境变量中,具体得添加过程就不赘述了,需要添加得路径如下图所示
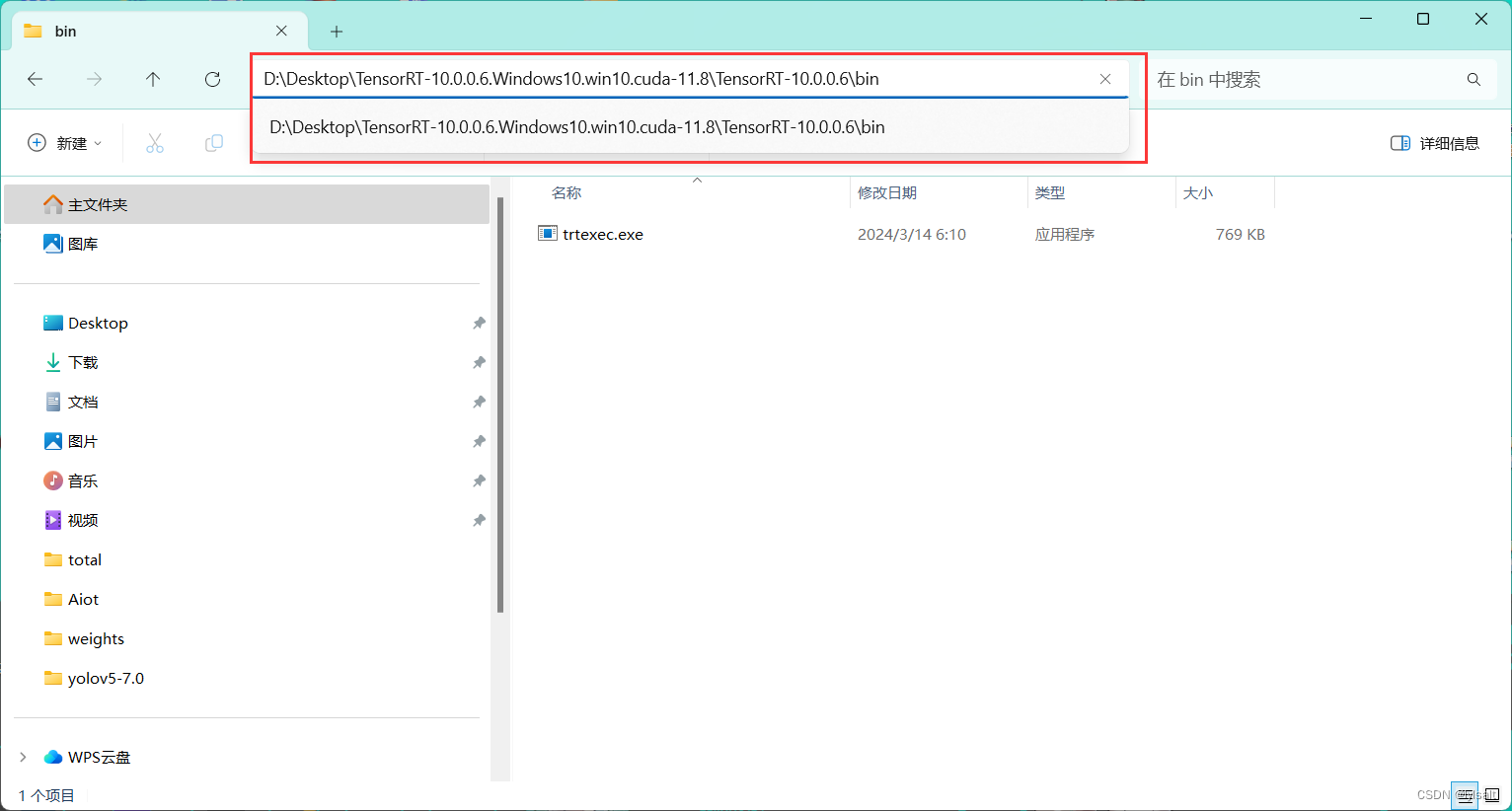
依次点击确定即可。
trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=D:/Desktop/yolov5-7.0/best(model).trt如果要使用FP16精度转换模型时加上--fp16参数即可。
然后在命令终端输入命令,执行结果如下所示
(yolov5) D:\Desktop\yolov5-7.0>trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=D:/Desktop/yolov5-7.0/best(model).trt
&&&& RUNNING TensorRT.trtexec [TensorRT v100000] # trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=D:/Desktop/yolov5-7.0/best(model).trt
[04/26/2024-11:27:08] [I] === Model Options ===
[04/26/2024-11:27:08] [I] Format: ONNX
[04/26/2024-11:27:08] [I] Model: D:/Desktop/yolov5-7.0/best(model).onnx
[04/26/2024-11:27:08] [I] Output:
[04/26/2024-11:27:08] [I] === Build Options ===
[04/26/2024-11:27:08] [I] Memory Pools: workspace: default, dlaSRAM: default, dlaLocalDRAM: default, dlaGlobalDRAM: default, tacticSharedMem: default
[04/26/2024-11:27:08] [I] avgTiming: 8
[04/26/2024-11:27:08] [I] Precision: FP32
[04/26/2024-11:27:08] [I] LayerPrecisions:
[04/26/2024-11:27:08] [I] Layer Device Types:
[04/26/2024-11:27:08] [I] Calibration:
[04/26/2024-11:27:08] [I] Refit: Disabled
[04/26/2024-11:27:08] [I] Strip weights: Disabled
[04/26/2024-11:27:08] [I] Version Compatible: Disabled
[04/26/2024-11:27:08] [I] ONNX Plugin InstanceNorm: Disabled
[04/26/2024-11:27:08] [I] TensorRT runtime: full
[04/26/2024-11:27:08] [I] Lean DLL Path:
[04/26/2024-11:27:08] [I] Tempfile Controls: { in_memory: allow, temporary: allow }
[04/26/2024-11:27:08] [I] Exclude Lean Runtime: Disabled
[04/26/2024-11:27:08] [I] Sparsity: Disabled
[04/26/2024-11:27:08] [I] Safe mode: Disabled
[04/26/2024-11:27:08] [I] Build DLA standalone loadable: Disabled
[04/26/2024-11:27:08] [I] Allow GPU fallback for DLA: Disabled
[04/26/2024-11:27:08] [I] DirectIO mode: Disabled
[04/26/2024-11:27:08] [I] Restricted mode: Disabled
[04/26/2024-11:27:08] [I] Skip inference: Disabled
[04/26/2024-11:27:08] [I] Save engine: D:/Desktop/yolov5-7.0/best(model).trt
[04/26/2024-11:27:08] [I] Load engine:
[04/26/2024-11:27:08] [I] Profiling verbosity: 0
[04/26/2024-11:27:08] [I] Tactic sources: Using default tactic sources
[04/26/2024-11:27:08] [I] timingCacheMode: local
[04/26/2024-11:27:08] [I] timingCacheFile:
[04/26/2024-11:27:08] [I] Enable Compilation Cache: Enabled
[04/26/2024-11:27:08] [I] errorOnTimingCacheMiss: Disabled
[04/26/2024-11:27:08] [I] Preview Features: Use default preview flags.
[04/26/2024-11:27:08] [I] MaxAuxStreams: -1
[04/26/2024-11:27:08] [I] BuilderOptimizationLevel: -1
[04/26/2024-11:27:08] [I] Calibration Profile Index: 0
[04/26/2024-11:27:08] [I] Weight Streaming: Disabled
[04/26/2024-11:27:08] [I] Debug Tensors:
[04/26/2024-11:27:08] [I] Input(s)s format: fp32:CHW
[04/26/2024-11:27:08] [I] Output(s)s format: fp32:CHW
[04/26/2024-11:27:08] [I] Input build shapes: model
[04/26/2024-11:27:08] [I] Input calibration shapes: model
[04/26/2024-11:27:08] [I] === System Options ===
[04/26/2024-11:27:08] [I] Device: 0
[04/26/2024-11:27:08] [I] DLACore:
[04/26/2024-11:27:08] [I] Plugins:
[04/26/2024-11:27:08] [I] setPluginsToSerialize:
[04/26/2024-11:27:08] [I] dynamicPlugins:
[04/26/2024-11:27:08] [I] ignoreParsedPluginLibs: 0
[04/26/2024-11:27:08] [I]
[04/26/2024-11:27:08] [I] === Inference Options ===
[04/26/2024-11:27:08] [I] Batch: Explicit
[04/26/2024-11:27:08] [I] Input inference shapes: model
[04/26/2024-11:27:08] [I] Iterations: 10
[04/26/2024-11:27:08] [I] Duration: 3s (+ 200ms warm up)
[04/26/2024-11:27:08] [I] Sleep time: 0ms
[04/26/2024-11:27:08] [I] Idle time: 0ms
[04/26/2024-11:27:08] [I] Inference Streams: 1
[04/26/2024-11:27:08] [I] ExposeDMA: Disabled
[04/26/2024-11:27:08] [I] Data transfers: Enabled
[04/26/2024-11:27:08] [I] Spin-wait: Disabled
[04/26/2024-11:27:08] [I] Multithreading: Disabled
[04/26/2024-11:27:08] [I] CUDA Graph: Disabled
[04/26/2024-11:27:08] [I] Separate profiling: Disabled
[04/26/2024-11:27:08] [I] Time Deserialize: Disabled
[04/26/2024-11:27:08] [I] Time Refit: Disabled
[04/26/2024-11:27:08] [I] NVTX verbosity: 0
[04/26/2024-11:27:08] [I] Persistent Cache Ratio: 0
[04/26/2024-11:27:08] [I] Optimization Profile Index: 0
[04/26/2024-11:27:08] [I] Weight Streaming Budget: -1 bytes
[04/26/2024-11:27:08] [I] Inputs:
[04/26/2024-11:27:08] [I] Debug Tensor Save Destinations:
[04/26/2024-11:27:08] [I] === Reporting Options ===
[04/26/2024-11:27:08] [I] Verbose: Disabled
[04/26/2024-11:27:08] [I] Averages: 10 inferences
[04/26/2024-11:27:08] [I] Percentiles: 90,95,99
[04/26/2024-11:27:08] [I] Dump refittable layers:Disabled
[04/26/2024-11:27:08] [I] Dump output: Disabled
[04/26/2024-11:27:08] [I] Profile: Disabled
[04/26/2024-11:27:08] [I] Export timing to JSON file:
[04/26/2024-11:27:08] [I] Export output to JSON file:
[04/26/2024-11:27:08] [I] Export profile to JSON file:
[04/26/2024-11:27:08] [I]
[04/26/2024-11:27:08] [I] === Device Information ===
[04/26/2024-11:27:08] [I] Available Devices:
[04/26/2024-11:27:08] [I] Device 0: "NVIDIA GeForce RTX 3060 Laptop GPU" UUID: GPU-938ea70e-da2c-0ee3-3b0b-cbaa56bf467e
[04/26/2024-11:27:08] [I] Selected Device: NVIDIA GeForce RTX 3060 Laptop GPU
[04/26/2024-11:27:08] [I] Selected Device ID: 0
[04/26/2024-11:27:08] [I] Selected Device UUID: GPU-938ea70e-da2c-0ee3-3b0b-cbaa56bf467e
[04/26/2024-11:27:08] [I] Compute Capability: 8.6
[04/26/2024-11:27:08] [I] SMs: 30
[04/26/2024-11:27:08] [I] Device Global Memory: 6143 MiB
[04/26/2024-11:27:08] [I] Shared Memory per SM: 100 KiB
[04/26/2024-11:27:08] [I] Memory Bus Width: 192 bits (ECC disabled)
[04/26/2024-11:27:08] [I] Application Compute Clock Rate: 1.605 GHz
[04/26/2024-11:27:08] [I] Application Memory Clock Rate: 7.001 GHz
[04/26/2024-11:27:08] [I]
[04/26/2024-11:27:08] [I] Note: The application clock rates do not reflect the actual clock rates that the GPU is currently running at.
[04/26/2024-11:27:08] [I]
[04/26/2024-11:27:08] [I] TensorRT version: 10.0.0
[04/26/2024-11:27:08] [I] Loading standard plugins
[04/26/2024-11:27:08] [I] [TRT] [MemUsageChange] Init CUDA: CPU +92, GPU +0, now: CPU 10058, GPU 1008 (MiB)
[04/26/2024-11:27:11] [I] [TRT] [MemUsageChange] Init builder kernel library: CPU +2601, GPU +310, now: CPU 12945, GPU 1318 (MiB)
[04/26/2024-11:27:11] [I] Start parsing network model.
[04/26/2024-11:27:11] [I] [TRT] ----------------------------------------------------------------
[04/26/2024-11:27:11] [I] [TRT] Input filename: D:/Desktop/yolov5-7.0/best(model).onnx
[04/26/2024-11:27:11] [I] [TRT] ONNX IR version: 0.0.7
[04/26/2024-11:27:11] [I] [TRT] Opset version: 12
[04/26/2024-11:27:11] [I] [TRT] Producer name: pytorch
[04/26/2024-11:27:11] [I] [TRT] Producer version: 2.3.0
[04/26/2024-11:27:11] [I] [TRT] Domain:
[04/26/2024-11:27:11] [I] [TRT] Model version: 0
[04/26/2024-11:27:11] [I] [TRT] Doc string:
[04/26/2024-11:27:11] [I] [TRT] ----------------------------------------------------------------
[04/26/2024-11:27:11] [I] Finished parsing network model. Parse time: 0.113777
[04/26/2024-11:27:11] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[04/26/2024-11:28:56] [I] [TRT] [GraphReduction] The approximate region cut reduction algorithm is called.
[04/26/2024-11:28:56] [I] [TRT] Detected 1 inputs and 4 output network tensors.
[04/26/2024-11:28:57] [I] [TRT] Total Host Persistent Memory: 469072
[04/26/2024-11:28:57] [I] [TRT] Total Device Persistent Memory: 0
[04/26/2024-11:28:57] [I] [TRT] Total Scratch Memory: 2458624
[04/26/2024-11:28:57] [I] [TRT] [BlockAssignment] Started assigning block shifts. This will take 243 steps to complete.
[04/26/2024-11:28:57] [I] [TRT] [BlockAssignment] Algorithm ShiftNTopDown took 10.2066ms to assign 8 blocks to 243 nodes requiring 54682624 bytes.
[04/26/2024-11:28:57] [I] [TRT] Total Activation Memory: 54681600
[04/26/2024-11:28:57] [I] [TRT] Total Weights Memory: 95714688
[04/26/2024-11:28:57] [I] [TRT] Engine generation completed in 105.756 seconds.
[04/26/2024-11:28:57] [I] [TRT] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 10 MiB, GPU 150 MiB
[04/26/2024-11:28:57] [I] [TRT] [MemUsageStats] Peak memory usage during Engine building and serialization: CPU: 3035 MiB
[04/26/2024-11:28:57] [I] Engine built in 105.873 sec.
[04/26/2024-11:28:57] [I] Created engine with size: 94.0234 MiB
[04/26/2024-11:28:58] [I] [TRT] Loaded engine size: 94 MiB
[04/26/2024-11:28:58] [I] Engine deserialized in 0.109136 sec.
[04/26/2024-11:28:58] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +52, now: CPU 0, GPU 143 (MiB)
[04/26/2024-11:28:58] [I] Setting persistentCacheLimit to 0 bytes.
[04/26/2024-11:28:58] [I] Created execution context with device memory size: 52.1484 MiB
[04/26/2024-11:28:58] [I] Using random values for input images
[04/26/2024-11:28:58] [I] Input binding for images with dimensions 1x3x640x640 is created.
[04/26/2024-11:28:58] [I] Output binding for output0 with dimensions 1x25200x6 is created.
[04/26/2024-11:28:58] [I] Starting inference
[04/26/2024-11:29:01] [I] Warmup completed 14 queries over 200 ms
[04/26/2024-11:29:01] [I] Timing trace has 357 queries over 3.00952 s
[04/26/2024-11:29:01] [I]
[04/26/2024-11:29:01] [I] === Trace details ===
[04/26/2024-11:29:01] [I] Trace averages of 10 runs:
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.90795 ms - Host latency: 9.13216 ms (enqueue 1.55493 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.06064 ms - Host latency: 8.28578 ms (enqueue 1.56004 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.03029 ms - Host latency: 8.25391 ms (enqueue 1.47085 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.13963 ms - Host latency: 8.3634 ms (enqueue 1.58833 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.0309 ms - Host latency: 8.25483 ms (enqueue 1.55824 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.04531 ms - Host latency: 8.26885 ms (enqueue 1.51385 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.06467 ms - Host latency: 8.28818 ms (enqueue 1.57804 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.03551 ms - Host latency: 8.25914 ms (enqueue 1.52687 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.04373 ms - Host latency: 8.26727 ms (enqueue 1.50027 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.11813 ms - Host latency: 8.34174 ms (enqueue 1.51915 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.23032 ms - Host latency: 8.45402 ms (enqueue 1.54312 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.52651 ms - Host latency: 8.7504 ms (enqueue 1.5062 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.24309 ms - Host latency: 8.46666 ms (enqueue 1.4837 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.10702 ms - Host latency: 8.33058 ms (enqueue 1.4693 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.03879 ms - Host latency: 8.26259 ms (enqueue 1.44951 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.07146 ms - Host latency: 8.295 ms (enqueue 1.57675 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.1048 ms - Host latency: 8.32841 ms (enqueue 1.5204 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.06532 ms - Host latency: 8.28881 ms (enqueue 1.52651 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.05559 ms - Host latency: 8.27917 ms (enqueue 1.49421 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.05702 ms - Host latency: 8.2808 ms (enqueue 1.45542 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.05911 ms - Host latency: 8.28274 ms (enqueue 1.45842 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.16184 ms - Host latency: 8.38567 ms (enqueue 1.5475 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.14116 ms - Host latency: 8.36775 ms (enqueue 1.56152 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.22236 ms - Host latency: 8.44607 ms (enqueue 1.51711 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.19099 ms - Host latency: 8.41472 ms (enqueue 1.45828 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.14692 ms - Host latency: 8.3707 ms (enqueue 1.52915 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.1093 ms - Host latency: 8.33281 ms (enqueue 1.51301 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.17473 ms - Host latency: 8.39856 ms (enqueue 1.53167 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.08308 ms - Host latency: 8.30681 ms (enqueue 1.56111 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.09421 ms - Host latency: 8.31775 ms (enqueue 1.56333 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.08149 ms - Host latency: 8.30522 ms (enqueue 1.6571 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.06111 ms - Host latency: 8.28621 ms (enqueue 1.57959 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.0446 ms - Host latency: 8.26824 ms (enqueue 1.61606 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.1146 ms - Host latency: 8.33862 ms (enqueue 1.57314 ms)
[04/26/2024-11:29:01] [I] Average on 10 runs - GPU latency: 8.10432 ms - Host latency: 8.32932 ms (enqueue 1.68594 ms)
[04/26/2024-11:29:01] [I]
[04/26/2024-11:29:01] [I] === Performance summary ===
[04/26/2024-11:29:01] [I] Throughput: 118.624 qps
[04/26/2024-11:29:01] [I] Latency: min = 8.21179 ms, max = 14.6308 ms, mean = 8.35859 ms, median = 8.2915 ms, percentile(90%) = 8.50903 ms, percentile(95%) = 8.67358 ms, percentile(99%) = 8.97955 ms
[04/26/2024-11:29:01] [I] Enqueue Time: min = 1.2749 ms, max = 2.08081 ms, mean = 1.53623 ms, median = 1.50171 ms, percentile(90%) = 1.69897 ms, percentile(95%) = 1.75952 ms, percentile(99%) = 1.85901 ms
[04/26/2024-11:29:01] [I] H2D Latency: min = 0.196045 ms, max = 0.209717 ms, mean = 0.196363 ms, median = 0.196167 ms, percentile(90%) = 0.196533 ms, percentile(95%) = 0.196777 ms, percentile(99%) = 0.201416 ms
[04/26/2024-11:29:01] [I] GPU Compute Time: min = 7.98804 ms, max = 14.4045 ms, mean = 8.13469 ms, median = 8.06714 ms, percentile(90%) = 8.28516 ms, percentile(95%) = 8.45007 ms, percentile(99%) = 8.75623 ms
[04/26/2024-11:29:01] [I] D2H Latency: min = 0.0268555 ms, max = 0.0409546 ms, mean = 0.0275316 ms, median = 0.0273438 ms, percentile(90%) = 0.027832 ms, percentile(95%) = 0.0280762 ms, percentile(99%) = 0.0288391 ms
[04/26/2024-11:29:01] [I] Total Host Walltime: 3.00952 s
[04/26/2024-11:29:01] [I] Total GPU Compute Time: 2.90409 s
[04/26/2024-11:29:01] [W] * GPU compute time is unstable, with coefficient of variance = 4.52781%.
[04/26/2024-11:29:01] [W] If not already in use, locking GPU clock frequency or adding --useSpinWait may improve the stability.
[04/26/2024-11:29:01] [I] Explanations of the performance metrics are printed in the verbose logs.
[04/26/2024-11:29:01] [I]
&&&& PASSED TensorRT.trtexec [TensorRT v100000] # trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=D:/Desktop/yolov5-7.0/best(model).trt
执行结果生成的trt模型如下图所示

3.2测试生成的tensorrt模型
这里主要参考官方提供的notebook教程:TensorRT/quickstart/SemanticSegmentation/tutorial-runtime.ipynb at main · NVIDIA/TensorRT · GitHub
下面是一个博主参考官方demo写的一个样例,在样例中对比ONNX和TensorRT的输出结果。
import numpy as np
import tensorrt as trt
import onnxruntime
import pycuda.driver as cuda
import pycuda.autoinit
def normalize(image: np.ndarray) -> np.ndarray:
"""
Normalize the image to the given mean and standard deviation
"""
#image = image.astype(np.float32)
image = image.astype(np.float16)
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
image /= 255.0
image -= mean
image /= std
return image
def onnx_inference(onnx_path: str, image: np.ndarray):
# load onnx model
ort_session = onnxruntime.InferenceSession(onnx_path)
# compute onnx Runtime output prediction
ort_inputs = {ort_session.get_inputs()[0].name: image}
res_onnx = ort_session.run(None, ort_inputs)[0]
return res_onnx
def trt_inference(trt_path: str, image: np.ndarray):
# Load the network in Inference Engine
trt_logger = trt.Logger(trt.Logger.WARNING)
with open(trt_path, "rb") as f, trt.Runtime(trt_logger) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
with engine.create_execution_context() as context:
# Set input shape based on image dimensions for inference
context.set_binding_shape(engine.get_binding_index("input"), (1, 3, image.shape[-2], image.shape[-1]))
# Allocate host and device buffers
bindings = []
for binding in engine:
binding_idx = engine.get_binding_index(binding)
size = trt.volume(context.get_binding_shape(binding_idx))
dtype = trt.nptype(engine.get_binding_dtype(binding))
if engine.binding_is_input(binding):
input_buffer = np.ascontiguousarray(image)
input_memory = cuda.mem_alloc(image.nbytes)
bindings.append(int(input_memory))
else:
output_buffer = cuda.pagelocked_empty(size, dtype)
output_memory = cuda.mem_alloc(output_buffer.nbytes)
bindings.append(int(output_memory))
stream = cuda.Stream()
# Transfer input data to the GPU.
cuda.memcpy_htod_async(input_memory, input_buffer, stream)
# Run inference
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# Transfer prediction output from the GPU.
cuda.memcpy_dtoh_async(output_buffer, output_memory, stream)
# Synchronize the stream
stream.synchronize()
res_trt = np.reshape(output_buffer, (1, -1))
return res_trt
# def main():
# image_h = 224
# image_w = 224
# onnx_path = r"D:\Desktop\yolov5-7.0\best(model).onnx"
# trt_path = r"D:\Desktop\yolov5-7.0\best(model).trt"
#
# image = np.random.randn(image_h, image_w, 3)
# normalized_image = normalize(image)
#
# # Convert the resized images to network input shape
# # [h, w, c] -> [c, h, w] -> [1, c, h, w]
# normalized_image = np.expand_dims(np.transpose(normalized_image, (2, 0, 1)), 0)
#
# onnx_res = onnx_inference(onnx_path, normalized_image)
# ir_res = trt_inference(trt_path, normalized_image)
# np.testing.assert_allclose(onnx_res, ir_res, rtol=1e-03, atol=1e-05)
# print("Exported model has been tested with TensorRT Runtime, and the result looks good!")
def main():
image_h = 640
image_w = 640
onnx_path = r"D:\Desktop\yolov5-7.0\best(model).onnx"
trt_path = r"D:\Desktop\yolov5-7.0\best(model).trt"
image = np.random.randn(image_h, image_w, 3)
normalized_image = normalize(image)
# Convert the resized images to network input shape
# [h, w, c] -> [c, h, w] -> [1, c, h, w]
normalized_image = np.expand_dims(np.transpose(normalized_image, (2, 0, 1)), 0)
onnx_res = onnx_inference(onnx_path, normalized_image)
ir_res = trt_inference(trt_path, normalized_image)
np.testing.assert_allclose(onnx_res, ir_res, rtol=1e-03, atol=1e-05)
print("Exported model has been tested with TensorRT Runtime, and the result looks good!")
if __name__ == '__main__':
main()

四:预约推理阶段
4.1 简述
在这一步骤的主要目的是,根据onnx所描述的模型结构和权重数值和当前的软硬件环境生成对应的执行计划,并且序列化为xxx.engine文件持久化保存,这一步时间比较长,所以需要序列化执行文件,这样在推理阶段直接加载此文件构造出Engine
以实现快速推理,这一步可以使用tensortrt安装包内自带的trtexec.exe实现,也可以用python代码自行实现。
4.2 trtexec.exe实现预推理(推荐)
使用trtexec.exe实现预推理需要系统安装好cudatoolkit和cudnn,否则无法正常运行
打开tensorrt安装包的子目录bin,如下图所示
搜索运行cmd,并且cd到此目录下,并且将需要部署的onnx文件复制到此目录下
输入以下指令:
trtexec --onnx=xxx.onnx --saveEngine=xxx.engine --fp16trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=best(model).engine --fp16参数解释
--fp16开启 float16精度的推理(推荐此模式,一方面能够加速,另一方面精度下降比较小)
--int8 开启 int8精度的推理(不太推荐,虽然更快,但是精度下降太厉害了)
--onnx onnx路径
--saveEngine执行计划(推理引擎)序列化地址
执行结果如下,过程可能会比较久,需要等待一会儿
(text-image) D:\Desktop\yolov5-7.0>trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=best(model).engine --fp16
&&&& RUNNING TensorRT.trtexec [TensorRT v100000] # trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=best(model).engine --fp16
[04/27/2024-15:22:50] [I] === Model Options ===
[04/27/2024-15:22:50] [I] Format: ONNX
[04/27/2024-15:22:50] [I] Model: D:/Desktop/yolov5-7.0/best(model).onnx
[04/27/2024-15:22:50] [I] Output:
[04/27/2024-15:22:50] [I] === Build Options ===
[04/27/2024-15:22:50] [I] Memory Pools: workspace: default, dlaSRAM: default, dlaLocalDRAM: default, dlaGlobalDRAM: default, tacticSharedMem: default
[04/27/2024-15:22:50] [I] avgTiming: 8
[04/27/2024-15:22:50] [I] Precision: FP32+FP16
[04/27/2024-15:22:50] [I] LayerPrecisions:
[04/27/2024-15:22:50] [I] Layer Device Types:
[04/27/2024-15:22:50] [I] Calibration:
[04/27/2024-15:22:50] [I] Refit: Disabled
[04/27/2024-15:22:50] [I] Strip weights: Disabled
[04/27/2024-15:22:50] [I] Version Compatible: Disabled
[04/27/2024-15:22:50] [I] ONNX Plugin InstanceNorm: Disabled
[04/27/2024-15:22:50] [I] TensorRT runtime: full
[04/27/2024-15:22:50] [I] Lean DLL Path:
[04/27/2024-15:22:50] [I] Tempfile Controls: { in_memory: allow, temporary: allow }
[04/27/2024-15:22:50] [I] Exclude Lean Runtime: Disabled
[04/27/2024-15:22:50] [I] Sparsity: Disabled
[04/27/2024-15:22:50] [I] Safe mode: Disabled
[04/27/2024-15:22:50] [I] Build DLA standalone loadable: Disabled
[04/27/2024-15:22:50] [I] Allow GPU fallback for DLA: Disabled
[04/27/2024-15:22:50] [I] DirectIO mode: Disabled
[04/27/2024-15:22:50] [I] Restricted mode: Disabled
[04/27/2024-15:22:50] [I] Skip inference: Disabled
[04/27/2024-15:22:50] [I] Save engine: best(model).engine
[04/27/2024-15:22:50] [I] Load engine:
[04/27/2024-15:22:50] [I] Profiling verbosity: 0
[04/27/2024-15:22:50] [I] Tactic sources: Using default tactic sources
[04/27/2024-15:22:50] [I] timingCacheMode: local
[04/27/2024-15:22:50] [I] timingCacheFile:
[04/27/2024-15:22:50] [I] Enable Compilation Cache: Enabled
[04/27/2024-15:22:50] [I] errorOnTimingCacheMiss: Disabled
[04/27/2024-15:22:50] [I] Preview Features: Use default preview flags.
[04/27/2024-15:22:50] [I] MaxAuxStreams: -1
[04/27/2024-15:22:50] [I] BuilderOptimizationLevel: -1
[04/27/2024-15:22:50] [I] Calibration Profile Index: 0
[04/27/2024-15:22:50] [I] Weight Streaming: Disabled
[04/27/2024-15:22:50] [I] Debug Tensors:
[04/27/2024-15:22:50] [I] Input(s)s format: fp32:CHW
[04/27/2024-15:22:50] [I] Output(s)s format: fp32:CHW
[04/27/2024-15:22:50] [I] Input build shapes: model
[04/27/2024-15:22:50] [I] Input calibration shapes: model
[04/27/2024-15:22:50] [I] === System Options ===
[04/27/2024-15:22:50] [I] Device: 0
[04/27/2024-15:22:50] [I] DLACore:
[04/27/2024-15:22:50] [I] Plugins:
[04/27/2024-15:22:50] [I] setPluginsToSerialize:
[04/27/2024-15:22:50] [I] dynamicPlugins:
[04/27/2024-15:22:50] [I] ignoreParsedPluginLibs: 0
[04/27/2024-15:22:50] [I]
[04/27/2024-15:22:50] [I] === Inference Options ===
[04/27/2024-15:22:50] [I] Batch: Explicit
[04/27/2024-15:22:50] [I] Input inference shapes: model
[04/27/2024-15:22:50] [I] Iterations: 10
[04/27/2024-15:22:50] [I] Duration: 3s (+ 200ms warm up)
[04/27/2024-15:22:50] [I] Sleep time: 0ms
[04/27/2024-15:22:50] [I] Idle time: 0ms
[04/27/2024-15:22:50] [I] Inference Streams: 1
[04/27/2024-15:22:50] [I] ExposeDMA: Disabled
[04/27/2024-15:22:50] [I] Data transfers: Enabled
[04/27/2024-15:22:50] [I] Spin-wait: Disabled
[04/27/2024-15:22:50] [I] Multithreading: Disabled
[04/27/2024-15:22:50] [I] CUDA Graph: Disabled
[04/27/2024-15:22:50] [I] Separate profiling: Disabled
[04/27/2024-15:22:50] [I] Time Deserialize: Disabled
[04/27/2024-15:22:50] [I] Time Refit: Disabled
[04/27/2024-15:22:50] [I] NVTX verbosity: 0
[04/27/2024-15:22:50] [I] Persistent Cache Ratio: 0
[04/27/2024-15:22:50] [I] Optimization Profile Index: 0
[04/27/2024-15:22:50] [I] Weight Streaming Budget: -1 bytes
[04/27/2024-15:22:50] [I] Inputs:
[04/27/2024-15:22:50] [I] Debug Tensor Save Destinations:
[04/27/2024-15:22:50] [I] === Reporting Options ===
[04/27/2024-15:22:50] [I] Verbose: Disabled
[04/27/2024-15:22:50] [I] Averages: 10 inferences
[04/27/2024-15:22:50] [I] Percentiles: 90,95,99
[04/27/2024-15:22:50] [I] Dump refittable layers:Disabled
[04/27/2024-15:22:50] [I] Dump output: Disabled
[04/27/2024-15:22:50] [I] Profile: Disabled
[04/27/2024-15:22:50] [I] Export timing to JSON file:
[04/27/2024-15:22:50] [I] Export output to JSON file:
[04/27/2024-15:22:50] [I] Export profile to JSON file:
[04/27/2024-15:22:50] [I]
[04/27/2024-15:22:50] [I] === Device Information ===
[04/27/2024-15:22:50] [I] Available Devices:
[04/27/2024-15:22:50] [I] Device 0: "NVIDIA GeForce RTX 3060 Laptop GPU" UUID: GPU-938ea70e-da2c-0ee3-3b0b-cbaa56bf467e
[04/27/2024-15:22:50] [I] Selected Device: NVIDIA GeForce RTX 3060 Laptop GPU
[04/27/2024-15:22:50] [I] Selected Device ID: 0
[04/27/2024-15:22:50] [I] Selected Device UUID: GPU-938ea70e-da2c-0ee3-3b0b-cbaa56bf467e
[04/27/2024-15:22:50] [I] Compute Capability: 8.6
[04/27/2024-15:22:50] [I] SMs: 30
[04/27/2024-15:22:50] [I] Device Global Memory: 6143 MiB
[04/27/2024-15:22:50] [I] Shared Memory per SM: 100 KiB
[04/27/2024-15:22:50] [I] Memory Bus Width: 192 bits (ECC disabled)
[04/27/2024-15:22:50] [I] Application Compute Clock Rate: 1.605 GHz
[04/27/2024-15:22:50] [I] Application Memory Clock Rate: 7.001 GHz
[04/27/2024-15:22:50] [I]
[04/27/2024-15:22:50] [I] Note: The application clock rates do not reflect the actual clock rates that the GPU is currently running at.
[04/27/2024-15:22:50] [I]
[04/27/2024-15:22:50] [I] TensorRT version: 10.0.0
[04/27/2024-15:22:50] [I] Loading standard plugins
[04/27/2024-15:22:50] [I] [TRT] [MemUsageChange] Init CUDA: CPU +86, GPU +0, now: CPU 7699, GPU 1008 (MiB)
[04/27/2024-15:22:57] [I] [TRT] [MemUsageChange] Init builder kernel library: CPU +2568, GPU +310, now: CPU 10562, GPU 1318 (MiB)
[04/27/2024-15:22:57] [I] Start parsing network model.
[04/27/2024-15:22:57] [I] [TRT] ----------------------------------------------------------------
[04/27/2024-15:22:57] [I] [TRT] Input filename: D:/Desktop/yolov5-7.0/best(model).onnx
[04/27/2024-15:22:57] [I] [TRT] ONNX IR version: 0.0.7
[04/27/2024-15:22:57] [I] [TRT] Opset version: 12
[04/27/2024-15:22:57] [I] [TRT] Producer name: pytorch
[04/27/2024-15:22:57] [I] [TRT] Producer version: 2.3.0
[04/27/2024-15:22:57] [I] [TRT] Domain:
[04/27/2024-15:22:57] [I] [TRT] Model version: 0
[04/27/2024-15:22:57] [I] [TRT] Doc string:
[04/27/2024-15:22:57] [I] [TRT] ----------------------------------------------------------------
[04/27/2024-15:22:57] [I] Finished parsing network model. Parse time: 0.101761
[04/27/2024-15:22:57] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[04/27/2024-15:28:03] [I] [TRT] Detected 1 inputs and 4 output network tensors.
[04/27/2024-15:28:08] [I] [TRT] Total Host Persistent Memory: 485648
[04/27/2024-15:28:08] [I] [TRT] Total Device Persistent Memory: 0
[04/27/2024-15:28:08] [I] [TRT] Total Scratch Memory: 4608
[04/27/2024-15:28:08] [I] [TRT] [BlockAssignment] Started assigning block shifts. This will take 129 steps to complete.
[04/27/2024-15:28:08] [I] [TRT] [BlockAssignment] Algorithm ShiftNTopDown took 4.0082ms to assign 10 blocks to 129 nodes requiring 25849344 bytes.
[04/27/2024-15:28:08] [I] [TRT] Total Activation Memory: 25849344
[04/27/2024-15:28:08] [I] [TRT] Total Weights Memory: 42015424
[04/27/2024-15:28:08] [I] [TRT] Engine generation completed in 311.164 seconds.
[04/27/2024-15:28:08] [I] [TRT] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 5 MiB, GPU 150 MiB
[04/27/2024-15:28:08] [I] [TRT] [MemUsageStats] Peak memory usage during Engine building and serialization: CPU: 3036 MiB
[04/27/2024-15:28:09] [I] Engine built in 311.279 sec.
[04/27/2024-15:28:09] [I] Created engine with size: 43.6518 MiB
[04/27/2024-15:28:10] [I] [TRT] Loaded engine size: 43 MiB
[04/27/2024-15:28:10] [I] Engine deserialized in 0.0934152 sec.
[04/27/2024-15:28:10] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +24, now: CPU 0, GPU 64 (MiB)
[04/27/2024-15:28:10] [I] Setting persistentCacheLimit to 0 bytes.
[04/27/2024-15:28:10] [I] Created execution context with device memory size: 24.6519 MiB
[04/27/2024-15:28:10] [I] Using random values for input images
[04/27/2024-15:28:10] [I] Input binding for images with dimensions 1x3x640x640 is created.
[04/27/2024-15:28:10] [I] Output binding for output0 with dimensions 1x25200x6 is created.
[04/27/2024-15:28:10] [I] Starting inference
[04/27/2024-15:28:13] [I] Warmup completed 21 queries over 200 ms
[04/27/2024-15:28:13] [I] Timing trace has 916 queries over 3.00605 s
[04/27/2024-15:28:13] [I]
[04/27/2024-15:28:13] [I] === Trace details ===
[04/27/2024-15:28:13] [I] Trace averages of 10 runs:
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.21642 ms - Host latency: 3.43999 ms (enqueue 1.18359 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.23929 ms - Host latency: 3.46318 ms (enqueue 1.16365 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.2294 ms - Host latency: 3.45301 ms (enqueue 1.18081 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.22433 ms - Host latency: 3.44792 ms (enqueue 1.18091 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.05655 ms - Host latency: 3.27994 ms (enqueue 1.19996 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.965 ms - Host latency: 3.1882 ms (enqueue 1.21602 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.94851 ms - Host latency: 3.17174 ms (enqueue 1.18539 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97754 ms - Host latency: 3.20223 ms (enqueue 1.19799 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99402 ms - Host latency: 3.2179 ms (enqueue 1.66606 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96964 ms - Host latency: 3.19292 ms (enqueue 1.2885 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.94816 ms - Host latency: 3.17271 ms (enqueue 1.19629 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96671 ms - Host latency: 3.19 ms (enqueue 1.23253 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95991 ms - Host latency: 3.18329 ms (enqueue 1.16576 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.02805 ms - Host latency: 3.25135 ms (enqueue 1.28087 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95455 ms - Host latency: 3.1778 ms (enqueue 1.17693 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95867 ms - Host latency: 3.18184 ms (enqueue 1.15242 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95679 ms - Host latency: 3.18015 ms (enqueue 1.22302 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96743 ms - Host latency: 3.19075 ms (enqueue 1.21404 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95872 ms - Host latency: 3.18201 ms (enqueue 1.19864 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96332 ms - Host latency: 3.18707 ms (enqueue 1.24236 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95793 ms - Host latency: 3.18127 ms (enqueue 1.1601 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96026 ms - Host latency: 3.1835 ms (enqueue 1.17762 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96046 ms - Host latency: 3.18368 ms (enqueue 1.21059 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96169 ms - Host latency: 3.18496 ms (enqueue 1.16614 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.989 ms - Host latency: 3.21216 ms (enqueue 1.32877 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95852 ms - Host latency: 3.18192 ms (enqueue 1.24979 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95424 ms - Host latency: 3.17754 ms (enqueue 1.1894 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96451 ms - Host latency: 3.18782 ms (enqueue 1.20511 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97194 ms - Host latency: 3.19541 ms (enqueue 1.23422 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.98411 ms - Host latency: 3.20736 ms (enqueue 1.19506 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.01698 ms - Host latency: 3.24016 ms (enqueue 1.17496 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.04755 ms - Host latency: 3.2709 ms (enqueue 1.18257 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.03575 ms - Host latency: 3.26061 ms (enqueue 1.18081 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.00596 ms - Host latency: 3.2293 ms (enqueue 1.18369 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99415 ms - Host latency: 3.2176 ms (enqueue 1.19225 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.98525 ms - Host latency: 3.20859 ms (enqueue 1.18877 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.01307 ms - Host latency: 3.23645 ms (enqueue 1.25167 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97517 ms - Host latency: 3.19874 ms (enqueue 1.19918 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96205 ms - Host latency: 3.18527 ms (enqueue 1.20704 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97325 ms - Host latency: 3.19653 ms (enqueue 1.1921 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96044 ms - Host latency: 3.18362 ms (enqueue 1.1775 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96693 ms - Host latency: 3.19152 ms (enqueue 1.17813 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97719 ms - Host latency: 3.20033 ms (enqueue 1.1683 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96801 ms - Host latency: 3.19122 ms (enqueue 1.21566 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96733 ms - Host latency: 3.19062 ms (enqueue 1.15092 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96086 ms - Host latency: 3.18402 ms (enqueue 1.18087 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97767 ms - Host latency: 3.20103 ms (enqueue 1.177 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.00447 ms - Host latency: 3.22769 ms (enqueue 1.20704 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95411 ms - Host latency: 3.17737 ms (enqueue 1.26493 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96362 ms - Host latency: 3.18687 ms (enqueue 1.1781 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.95208 ms - Host latency: 3.17338 ms (enqueue 1.20109 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96753 ms - Host latency: 3.18988 ms (enqueue 1.18854 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97266 ms - Host latency: 3.19705 ms (enqueue 1.18549 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.9771 ms - Host latency: 3.20175 ms (enqueue 1.20049 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96548 ms - Host latency: 3.18875 ms (enqueue 1.1838 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.96741 ms - Host latency: 3.19197 ms (enqueue 1.16281 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97987 ms - Host latency: 3.20309 ms (enqueue 1.17471 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.98271 ms - Host latency: 3.20613 ms (enqueue 1.18618 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99216 ms - Host latency: 3.21548 ms (enqueue 1.17896 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.03435 ms - Host latency: 3.25781 ms (enqueue 1.20732 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.0155 ms - Host latency: 3.23879 ms (enqueue 1.2217 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.01116 ms - Host latency: 3.23584 ms (enqueue 1.19126 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99612 ms - Host latency: 3.21941 ms (enqueue 1.18384 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.01101 ms - Host latency: 3.23467 ms (enqueue 1.23186 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99653 ms - Host latency: 3.21973 ms (enqueue 1.15752 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.9916 ms - Host latency: 3.21631 ms (enqueue 1.17678 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.00212 ms - Host latency: 3.22688 ms (enqueue 1.18572 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99431 ms - Host latency: 3.21755 ms (enqueue 1.19741 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99321 ms - Host latency: 3.21765 ms (enqueue 1.17122 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.98489 ms - Host latency: 3.20823 ms (enqueue 1.19355 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99863 ms - Host latency: 3.2219 ms (enqueue 1.19856 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97773 ms - Host latency: 3.201 ms (enqueue 1.20198 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97459 ms - Host latency: 3.19785 ms (enqueue 1.18 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.9792 ms - Host latency: 3.20249 ms (enqueue 1.18252 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.98313 ms - Host latency: 3.20642 ms (enqueue 1.21011 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97922 ms - Host latency: 3.20247 ms (enqueue 1.16492 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97029 ms - Host latency: 3.19355 ms (enqueue 1.18601 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97227 ms - Host latency: 3.19539 ms (enqueue 1.20554 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97869 ms - Host latency: 3.20195 ms (enqueue 1.17554 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.98743 ms - Host latency: 3.21209 ms (enqueue 1.22659 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97312 ms - Host latency: 3.19636 ms (enqueue 1.18545 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97686 ms - Host latency: 3.20029 ms (enqueue 1.19436 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.00347 ms - Host latency: 3.22688 ms (enqueue 1.21401 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.9688 ms - Host latency: 3.19211 ms (enqueue 1.24478 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97896 ms - Host latency: 3.20222 ms (enqueue 1.21899 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.97073 ms - Host latency: 3.19399 ms (enqueue 1.18323 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.98745 ms - Host latency: 3.21082 ms (enqueue 1.17527 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.9999 ms - Host latency: 3.22312 ms (enqueue 1.17632 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99458 ms - Host latency: 3.21792 ms (enqueue 1.19541 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 3.00327 ms - Host latency: 3.22661 ms (enqueue 1.24326 ms)
[04/27/2024-15:28:13] [I] Average on 10 runs - GPU latency: 2.99648 ms - Host latency: 3.2199 ms (enqueue 1.20044 ms)
[04/27/2024-15:28:13] [I]
[04/27/2024-15:28:13] [I] === Performance summary ===
[04/27/2024-15:28:13] [I] Throughput: 304.719 qps
[04/27/2024-15:28:13] [I] Latency: min = 3.11609 ms, max = 3.6795 ms, mean = 3.21576 ms, median = 3.20142 ms, percentile(90%) = 3.25195 ms, percentile(95%) = 3.41205 ms, percentile(99%) = 3.46069 ms
[04/27/2024-15:28:13] [I] Enqueue Time: min = 0.871704 ms, max = 2.06769 ms, mean = 1.20278 ms, median = 1.19122 ms, percentile(90%) = 1.27881 ms, percentile(95%) = 1.32275 ms, percentile(99%) = 1.50241 ms
[04/27/2024-15:28:13] [I] H2D Latency: min = 0.186157 ms, max = 0.221069 ms, mean = 0.196148 ms, median = 0.196075 ms, percentile(90%) = 0.196289 ms, percentile(95%) = 0.196411 ms, percentile(99%) = 0.19696 ms
[04/27/2024-15:28:13] [I] GPU Compute Time: min = 2.90405 ms, max = 3.45602 ms, mean = 2.99229 ms, median = 2.97778 ms, percentile(90%) = 3.02905 ms, percentile(95%) = 3.18872 ms, percentile(99%) = 3.23688 ms
[04/27/2024-15:28:13] [I] D2H Latency: min = 0.0258789 ms, max = 0.0408936 ms, mean = 0.0273182 ms, median = 0.0270996 ms, percentile(90%) = 0.0275879 ms, percentile(95%) = 0.0275879 ms, percentile(99%) = 0.0400391 ms
[04/27/2024-15:28:13] [I] Total Host Walltime: 3.00605 s
[04/27/2024-15:28:13] [I] Total GPU Compute Time: 2.74094 s
[04/27/2024-15:28:13] [W] * GPU compute time is unstable, with coefficient of variance = 2.13647%.
[04/27/2024-15:28:13] [W] If not already in use, locking GPU clock frequency or adding --useSpinWait may improve the stability.
[04/27/2024-15:28:13] [I] Explanations of the performance metrics are printed in the verbose logs.
[04/27/2024-15:28:13] [I]
&&&& PASSED TensorRT.trtexec [TensorRT v100000] # trtexec --onnx=D:/Desktop/yolov5-7.0/best(model).onnx --saveEngine=best(model).engine --fp16生成的文件
4.3python代码实现预推理
# 导入必用依赖
import tensorrt as trt
# 创建logger:日志记录器
logger = trt.Logger(trt.Logger.WARNING)
# 创建构建器builder
builder = trt.Builder(logger)
# 预创建网络
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
# 加载onnx解析器
parser = trt.OnnxParser(network, logger)
success = parser.parse_from_file(onnx_path)
for idx in range(parser.num_errors):
print(parser.get_error(idx))
if not success:
pass # Error handling code here
# builder配置
config = builder.create_builder_config()
# 分配显存作为工作区间,一般建议为显存一半的大小
config.max_workspace_size = 1 << 30 # 1 Mi
serialized_engine = builder.build_serialized_network(network, config)
# 序列化生成engine文件
with open(engine_path, "wb") as f:
f.write(serialized_engine)
print("generate file success!")报错如下:
(yolov5) D:\Desktop\yolov5-7.0>python "pre python code detect.py"
Traceback (most recent call last):
File "pre python code detect.py", line 24, in <module>
config.max_workspace_size = 1 << 7 # 1 Mi
AttributeError: 'tensorrt.tensorrt.IBuilderConfig' object has no attribute 'max_workspace_size'包括前面测3.2试生成的tensorrt模型,也会出现同样的问题,由于TensorRT的更新,某些模块的更新或者不用了,都会导致之前的代码报错。确实有的时候不是版本越新越好。
TensorRT版本:8.4
从网上下载的代码,运行报错,如上述标题。
1、错误:AttributeError: ‘tensorrt.tensorrt.Builder‘ object has no attribute ‘max_workspace_size‘
原因:tensorrt8.0以上删除了max_workspace_size属性。
解决方案:(1)将tensorRT降低为7.x版本(不推荐)
(2)使用如下命令替换:
# builder.max_workspace_size = 1 << 20
config = builder.create_builder_config()
config.max_workspace_size = 1 << 20
以上亲测有效。这个是那个博主亲测有效果,但其实我还是会报错的。算了,暂时不管他了。
这个是TensorRT的官方文档,,用来查找相关资料
文档存档 :: NVIDIA Deep Learning TensorRT Documentation
五:如何部署
用Tensorrt加速有两种思路,一种是构建C++版本的代码,生成engine,然后用C++的TensorRT加速。另一种是用Python版本的加速,Python加速有两种方式,网上基本上所有的方法都是用了C++生成的engine做后端,只用Python来做前端,这里另一个博主提供了另外一个用torchtrt加速的版本。由于我部署的python,所以C++的教程就省略了。
参考一个博主测评的推理速度的对比图
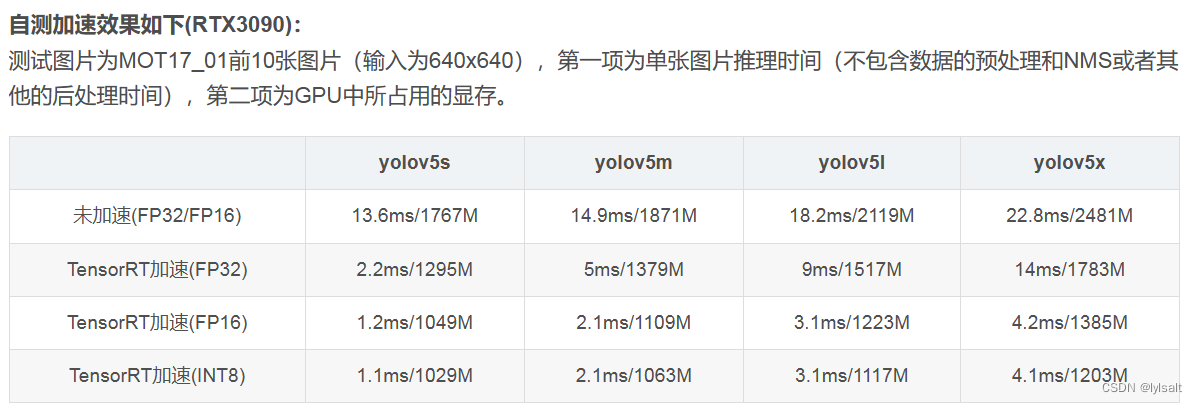
⭐在使用INT8模型之前需要做一些校准(calibration),位数太少了,校准可以保证尽可能保证分布,但是校准对校准的数据集要求比较高,如果选取不好很难保证泛化性。
校准方法:tensorrtx/yolov5 at master · wang-xinyu/tensorrtx · GitHub
校准原理:TensorRT(5)-INT8校准原理 | arleyzhang
根据难易度,我认为选择FP16可能会比较好一些。
速度的增加和内存的减少还是挺可观的,FP16和FP32相对于原来的方法有很大的显存下降和推理速度的提高。而且从可视化来看基本上没有太大的差别。但是INT8就差上很多了,基本上丢失了很多的目标。一开始怀疑是校准没有弄好,但是用了三种方法(github给出的COCO校准/MOT同一个序列的100张图片/直接用测试的那10张图片),效果均差不多,这可能说明校准真的是个技术活。。INT8不咋丢失精度可能在检测上还比较难搞。
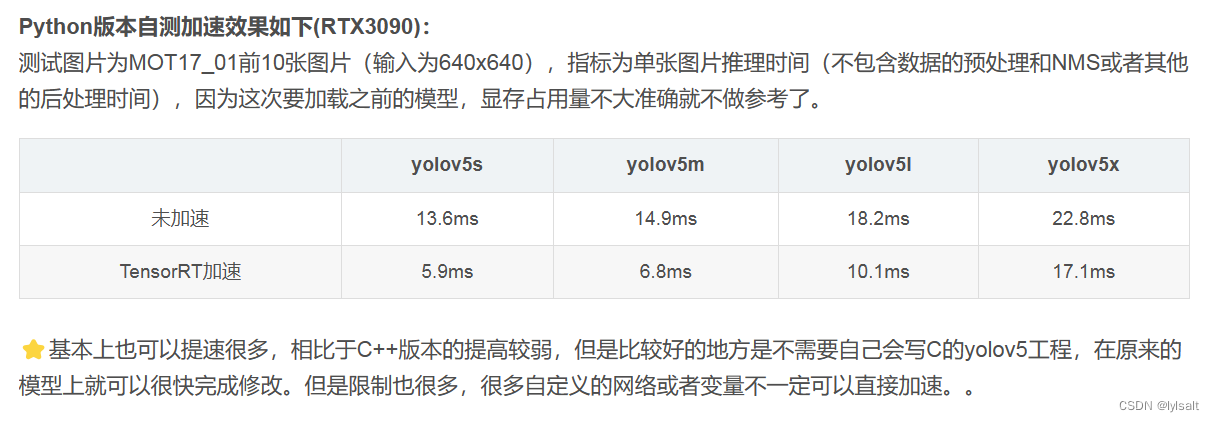
python版本的部署方法:
(1)第一种依然来自于github:tensorrtx/yolov5 at master · wang-xinyu/tensorrtx · GitHub
这个实际上和之前的没有改变啥好像,就是依然需要写C++的后端才行,只是把后处理这些放到python中了,依然不利于python的直接部署。这种方法加速后的效果和之前的C++的没有太大的区别。
(2)第二种GitHub - NVIDIA-AI-IOT/torch2trt: An easy to use PyTorch to TensorRT converter
 (3)关于Tensorrt加速自己的工作
(3)关于Tensorrt加速自己的工作
C++的加速效果更好,但是涉及到要会用C++把自己的工作写一遍才行,现在开源出来包括网上很多方法都是用C++来加速的,这个方法更加灵活,适应性更强(多输入多输出之类),而且最终只会生成一个engine,看起来很简洁。
这部分如果有C++基础的真的强烈推荐,可以参考如下工程:
yolov5:tensorrtx/yolov5 at master · wang-xinyu/tensorrtx · GitHub
yoloX:https://github.com/Megvii-BaseDetection/YOLOX
不会C++可以考虑用Torchtrt来加速,上述就提供了一个加速yolov5的例子,当然需要把一些加速不了的东西拿出来。此外,这个方法遇到多输入多输出也可以用一些折中的方法进行加速,比如把可以加速的部分划分成多个模型加速,加速不了的用原来的方法计算,这样依然可以获得很高的速度收益。
这类方法简单有效,适合不精通C++但需要加速的人群,可以参考如下工程:
yoloX:https://github.com/Megvii-BaseDetection/YOLOX
Ocean:https://github.com/researchmm/TracKit/blob/master/lib/tutorial/Ocean/ocean.md
五:参考资料
TensorRT 学习(二):Pytorch 模型转 TensorRT C++ 流程_trt模型推理结果导出c++-优快云博客
TensorRT(一)Windows+Anaconda配置TensorRT环境 (Python版 )_conda tensorrt-优快云博客
windows上使用anconda安装tensorrt环境 - 知乎 (zhihu.com)
Yolov5的3种tensorRT加速方式及3090测评结果(C++版和Python torchtrt版)_yolov5 tensorrt 和 pytorch 速度一样-优快云博客 【CV学习笔记】tensorrtx-yolov5 逐行代码解析 - 知乎 (zhihu.com)
TensorRT安装记录(8.2.5)_tensorrt 8.2 ga update 4 for linux x86 64 and cuda-优快云博客


















 3466
3466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











