







哨兵机制
哨兵机制的介绍
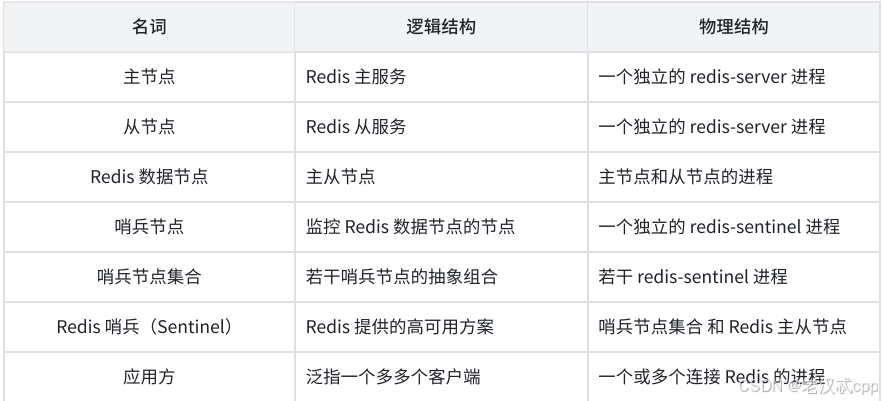
先来看一下Redis Sentinel 相关名词解释:
在之前的主从复制中,存在一个问题,那就是当主节点挂了后,通过人工干预的方式来解决是比较繁琐且不那么靠谱的。
在实际开发中,对于服务器后端开发,监控程序是很重要的。服务器要求高可用性,需要服务器保持7 * 24小时的长期运行,如果出了什么意外,这个意外啥时候出的,出的原因是什么,这些都需要程序员搞清楚,并且如果用人工的方式实时盯着服务器也不太现实,所以此时就需要一个监控程序来监控服务器的运行状态,往往还会搭配一个 “报警” 程序来提醒开发者出现问题了。
哨兵机制是通过独立的进程来实现的, redis-sentinel进程不负责存储数据,只是对其他的redis-server起到监控的效果。
通常哨兵节点也会搞成一个集合(多个哨兵节点构成的)。
手动恢复Redis主从复制的流程
这里再来回顾一下,当Redis主节点挂了后,程序员手动恢复的流程:
1.先看主节点还能不能抢救,好不好抢救,如果能就赶紧抢救好立马重启。
2. 如果主节点挂的原因不好定位,或者问题定位到了,但是短时间内难以解决,此时就需要挑一个从节点,使其成为新的主节点,此时又需要几步:
a:把选中的从节点,通过 slaveof no one的方式,先成为主节点。
b:把其他的从节点,通过slaveof ip port的方式来连接新的主节点。
c:告知客户端(修改客户端的配置文件),让客户端能够连接到新的主节点,从而能够完成修改数据的操作。
之前挂了的主节点修好之后,也不用空闲着,可以把它当作一个新的从节点挂到这组机器中。
此时我们就发现,一旦操作涉及到人工,那么不仅处理起来需要更长的时间,如果处理出错了还会导致问题更加严重。
自动恢复redis主从复制的流程
Redis Sentinel 架构:

如果是从节点挂了,其实还没什么问题。
但如果是主节点挂了,哨兵就要发挥作用了:
1. 此时,一个哨兵节点发现主节点挂了还不够,还需要与其他的哨兵节点共同确认这件事,目的就是为了防止误判。
2.如果这个主节点确实是挂了,那么这些哨兵节点就会选举出一个 “leader” 这样的哨兵节点,由这个 “leader”节点来从现有的从节点中,挑选出一个节点作为新的主节点。
3.挑选出新的主节点后,哨兵节点就会自动控制这个节点执行 slaveof no one命令,并且会控制其他从节点修改 slaveof 到新的主节点上。
4.哨兵节点会自动通知客户端程序,告知新的主节点是谁,这样后续客户端再进行写操作时,就会针对新的主节点进行操作了。
Redis哨兵节点的核心功能:
1.监控redis-server集群
2.会自动进行故障的转移。
3.自动通知客户端新的主节点。
另外,Redis哨兵节点只有一个也是可以的,不过就会存在一些问题:
1.如果哨兵节点只有一个,那么它自身也是容易出现问题的,万一这个哨兵节点挂了,并且后续Redis的节点也挂了,那么就无法进行自动恢复的过程了。
2.出现误判的可能性也比较高:因为网络传输数据是容易出现网络抖动或者延迟或者丢包的,如果只有一个哨兵节点,那么出现上述问题之后影响就比较大了。
所以在分布式系统中一般遵循一个原则:避免 “单点”。
使用docker搭建环境
docker简单介绍
我们这里为了演示3个redis-server,3个哨兵节点,本来应该是在6台机器上的,但是我们这里只有一台云服务器来完成这里的环境搭建。
在实际工作上,把上述节点放在一个服务器上是没有意义的。
由于这些节点比较多,依赖的端口号/配置文件/数据文件都避免冲突,当然如果在不同的主机上配置就比较容易了,在一个主机上的话可以使用docker来解决这个问题。
首先为什么要使用docker?
我们都知道虚拟机这个东西,它是通过 软件,在电脑上模拟出一些另外的硬件环境,就相当于构造了另一个电脑。有虚拟机这样的软件,就可以使用一个计算机来模拟出多个电脑的情况。
但是虚拟机有一个很大的问题:比较吃配置。对于轻量级的云服务器来说压力很大。
docker可以认为是一个轻量级的虚拟机,它起到了虚拟机这样隔离环境的效果,但是又没有吃很多硬件资源,所以即便是配置比较低的云服务器,也能通过docker构造出好几个这样的虚拟环境。
在docker中有一个重要的关键概念 “容器”,可以看作一个轻量级的虚拟机。
docker的安装及一些配置
安装docker:
需要先安装一些必要的依赖:
sudo apt-get install apt-transport-https ca-certificates curl software-properties-common lsb-release gnupg为了验证Docker软件包的签名,需要添加Docker官方的GPG密钥。可以使用以下命令:
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -接下来,需要将Docker的软件源添加到APT仓库中。输入以下命令:
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"添加完Docker软件源后,再次更新软件包索引:
sudo apt-get update现在,可以安装Docker CE(Docker社区版)了。输入以下命令:
sudo apt-get install docker-ce docker-ce-cli containerd.io安装完成后,可以通过运行以下命令来验证Docker是否安装成功:
sudo docker run hello-world# ubuntu
apt install docker-compose
# centos
yum install docker-compose2.停止之前的redis-server
3.使用docker获取到Redis镜像。
这里说下镜像:
docker中镜像和容器就类似于 “可执行程序” 和 “进程”的关系。
镜像可以自己构建,也可以直接拿别人构建好的。docker hub(类似git hub)上包含了很多大佬们已经构建好的镜像。也提供了Redis官方提供的镜像,我们只要直接拉取下来用就行了。
docker pull redis:5.0.9
拉取下来后,我们可以看一下
docker images
用docker开始搭建:



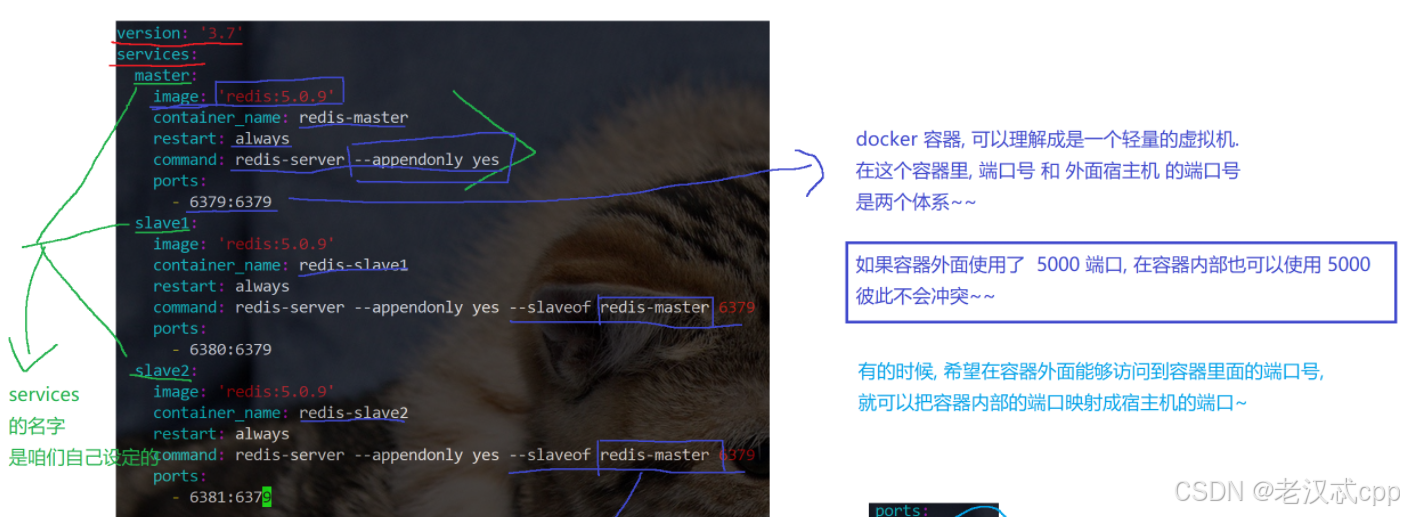
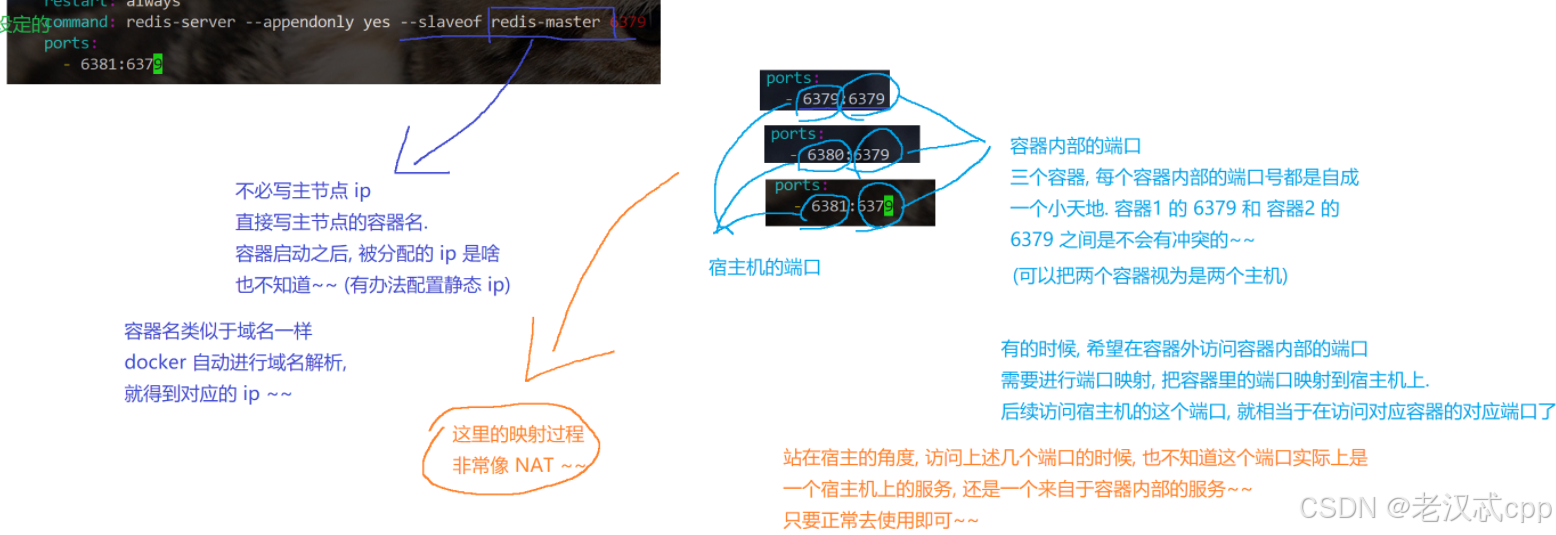
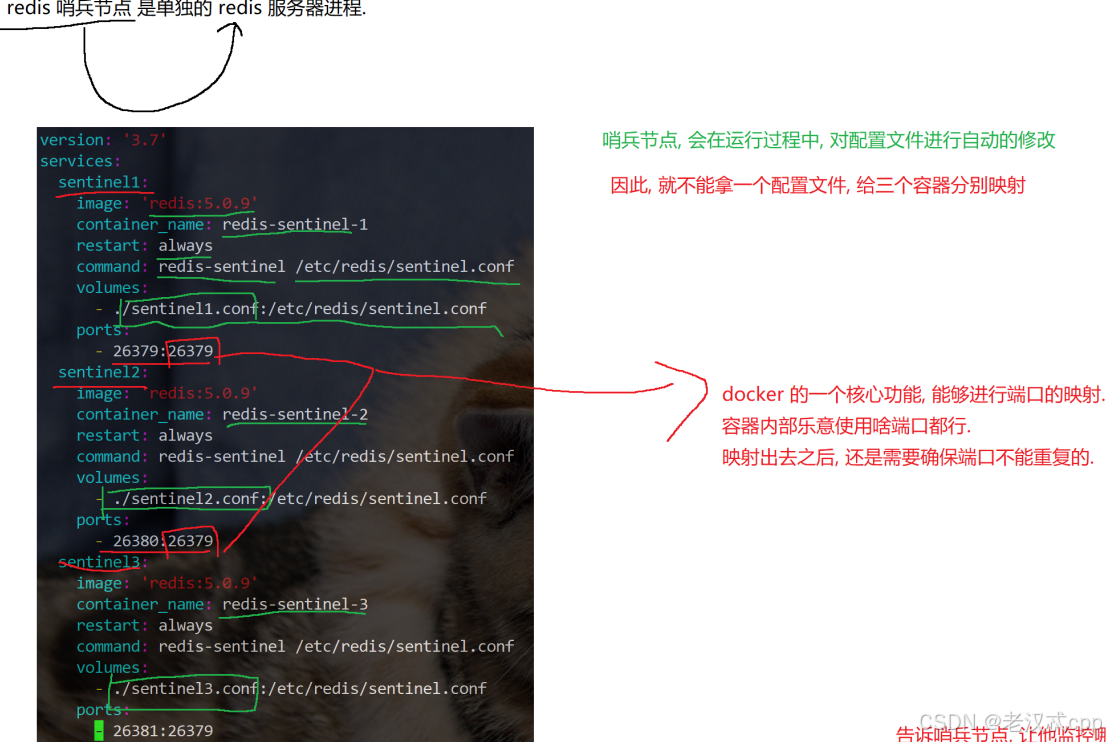
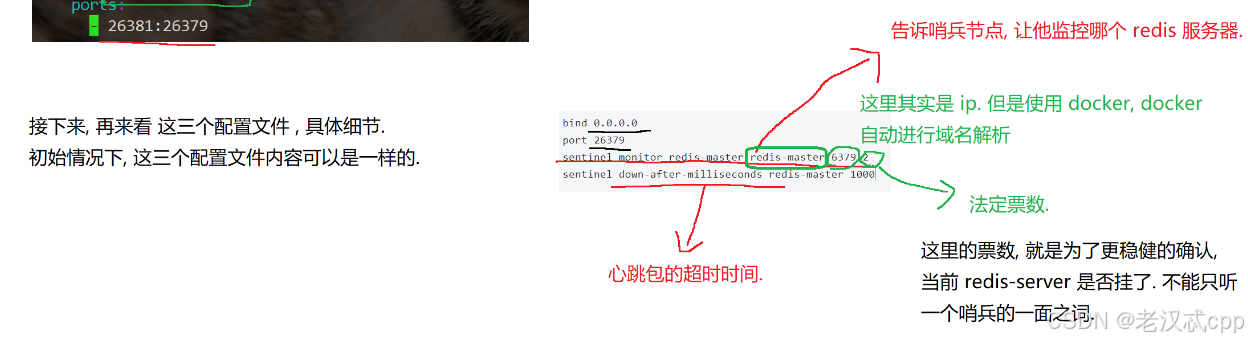

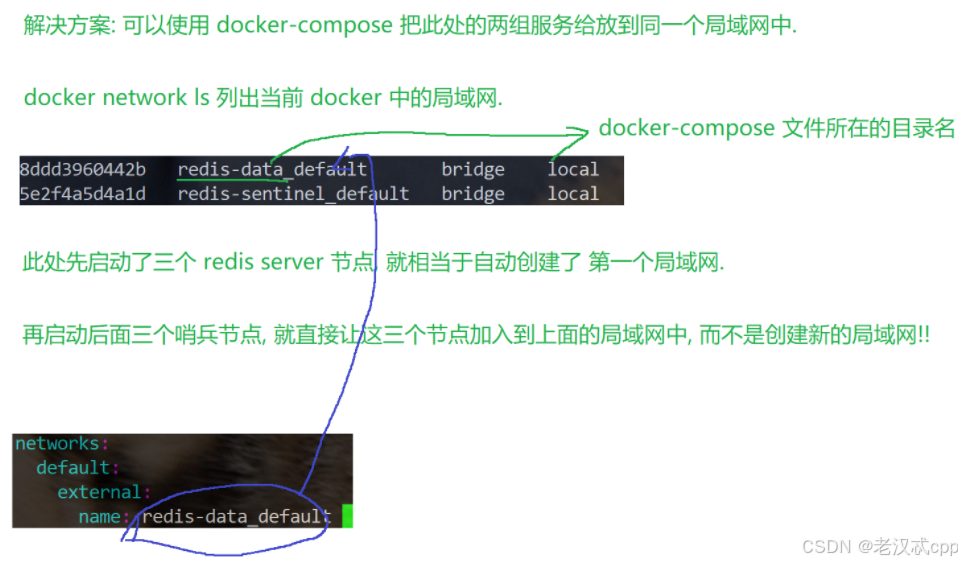
哨兵节点的作用演示
当我们手动停止redis-server master时,看一下哨兵节点1的日志:
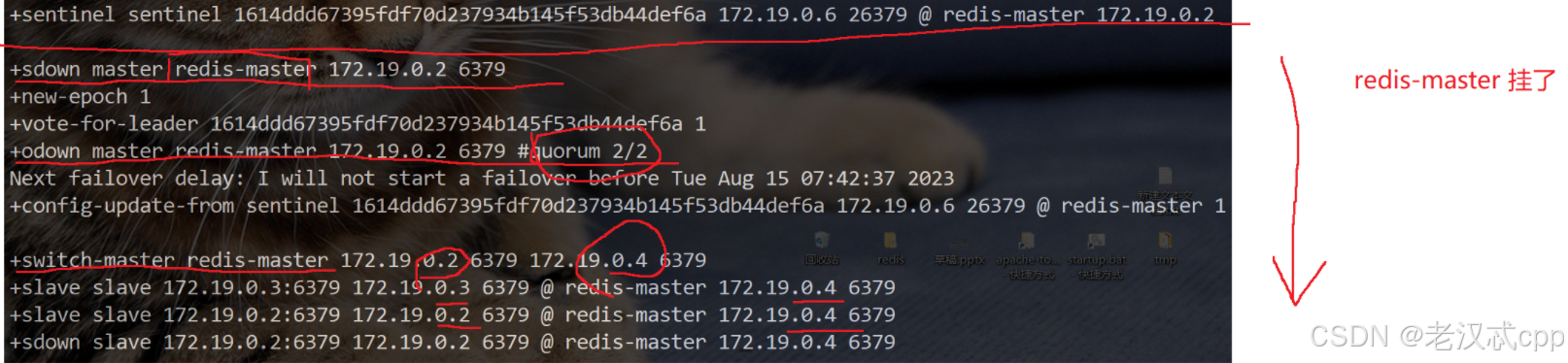
其中我们看到有sdown和odown:
sdown: 主观下线,本哨兵节点认为该主节点挂了。
odown:客观下线,好几个哨兵节点都认为主节点挂了。(达到法定票数了)
当客观认为主节点下线后,此时就需要先选出一个 “leader”哨兵节点,然后由这个哨兵节点选出一个从节点作为新的主节点。
在这个哨兵节点1的日志文件中我们看到,当它主观认为主节点下线后,立马就给自己投了一票(vote for leader 1614xxxxxxxxx。。。)
先看看这三个哨兵节点的id
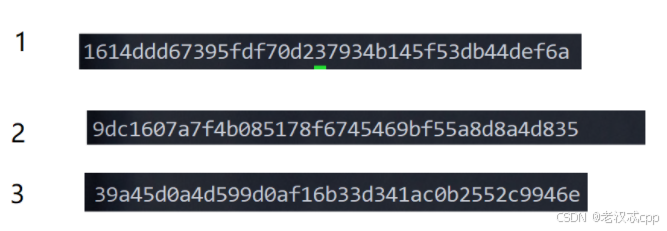
可以理解为,1号哨兵节点最先发现了主节点下线,然后在选举leader上立马给自己投了一票,并且也通知了其他的哨兵节点进行了主节点下线是否客观的投票,其他节点确认了主节点下线后,就纷纷将选举leader的票投给了最先给它通知的节点,于是1号哨兵就胜出成为了leader
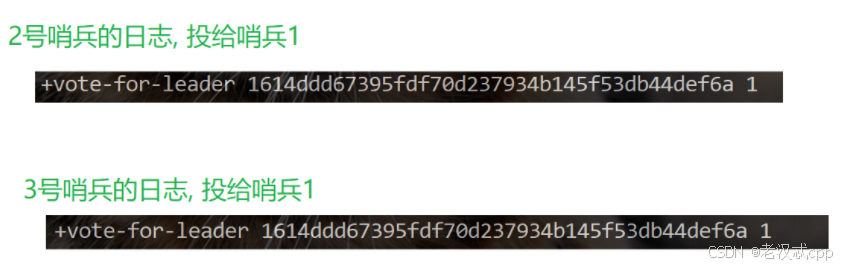
随后就开始了挑选新的主节点的行动

主从切换的具体流程
也就是哨兵重新选取主节点的流程:
1.主观下线:哨兵节点通过心跳包来判定redis服务器是否正常工作,当心跳包没有如约而至的时候,因为这里并不能排除网络波动的影响,所以就只能单方面认为redis节点挂了。
2.客观下线:多个哨兵节点都认为主节点挂了(认为主节点挂了的哨兵节点数量达到了法定票数),此时哨兵节点们就认为这个主节点是客观下线。
3.让多个哨兵节点选出一个 “leader”哨兵节点,每个节点可投出一票。选出leader节点后,由这个leader节点负责选一个从节点作为新的主节点。
关于这里的选leader,当哨兵1发现主节点是客观下线后,就立即给自己投了一票,并且告诉了哨兵2 3,因为它俩的反应慢了半拍,才发现是客观下线,看到哨兵1给它自己投票了,于是纷纷也把票投给哨兵1。 补充:假设哨兵2 3没有投出票的时候,只要收到拉票请求就会投出去,如果有多个拉票请求,那么就会把票投给最先到达的。
如果总的票数超过了哨兵节点的一半,那么就会选举就完成了。所以把哨兵节点的个数设为奇数个就是为了方便投票。

4. 当leader选举完后,此时就需要挑选一个从节点作为新的主节点了。这个挑选也是会先按一定的顺序标准的:
a:先看从节点的优先级:在每个redis数据节点,在配置文件中会有一个slave-priority的选项,这优先级高的节点就会胜出。
b:offset最大的胜出:如果每个节点的优先级都相同,那么就看offset,因为offset越大,说明它与原来主节点同步的进度越好,数据与主节点越接近。
c:run id最大的胜出:如果上述两个都是一样的,那么就看谁的run id最大,就选谁当主节点。
因为run id是每个redis节点启动后随机生成的数字,所以到这里其实就是随缘了。
在选择好新的主节点后,leader就会控制这个节点执行 slaveof no one来成为master,然后再控制其他的节点执行slaveof 让其他的节点以这个新的master作为主节点。
哨兵机制小总结:
这里大部分情况下三个就够用了,并且哨兵节点可以用一些低配机器来部署,但是不能把哨兵节点们都部署在一台机器上,如果这样就有点掩耳盗铃了。
而redis集群就是解决存储容量问题的有效方案。
补充:关于docker拉取镜像响应超时
依次执行:
vi /etc/docker/daemon.json
#在配置文件中进行以下
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://dockerhub.timeweb.cloud",
"https://huecker.io"
]
}在文件修改好之后,再依次执行:
sudo systemctl daemon-reload
sudo systemctl restart docker

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









