







目录
露出点破绽吧,让我知道你也在想我
—— 25.3.10
一、邻接矩阵的概念
1.邻接矩阵的定义
由于图是由顶点和边(或弧)两部分组成的。顶点可以用一个一维的顺序表来存储,但是边(或弧)由于是顶点与顶点之间的关系,一维搞不定,所以可以考虑用一个二维的顺序表来存储,而二维的顺序表就是一个矩阵。
对于一个有 n 个顶点的图 G,邻接矩阵是一个n x n的方阵(方阵就是行列数相等的矩阵)。对于邻接矩阵而言,不需要去考虑是有向的还是无向的,统一都可以理解成有向的,因为有向图可以兼容无向图,对于无向图而言,只不过这个矩阵是按照主对角线对称的,因为 A 到 B 有边,则必然 B 到 A 有边。
对带权图和无权图,邻接矩阵的表示略有差别
2.无权图的邻接矩阵
对于一个 n × n 的方阵 adj[n][n],在这样一个矩阵里:
① 矩阵的行和列都对应图中的一个顶点
② 如果顶点 A 到顶点 B 有一条边(这里是单向的),则对应矩阵单元为 1
③ 如果顶点 A 到顶点 B 没有边(这里同样是单向的),则对应的矩阵单元就为 0
例:
对于一个有四个顶点的无权图,首先需要有一个顺序表来存储所有的顶点(A、B、C、D),图的邻接矩阵如下“
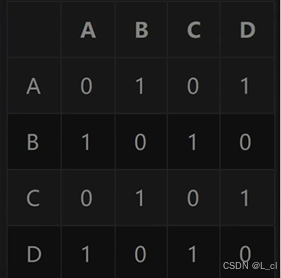
从矩阵中我们可以看出:
A 能够到 B、D;
B 能够到 A、C;
C能够到 B、D;
D 能够到 A、C

对于矩阵的主对角线的值 adj[0][0]、adj[1][1]、adj[2][2]、adj[3][3] 全为0、因为这个图中,不存在顶点自己到自己的边,adj[0][1] = 1 是因为 A 到 B 的边存在,而 adj[2][0] = 0 是因为 C 到 A 的边不存在,对于无向图而言,它的邻接矩阵是一个对称矩阵
有了这个矩阵我们可以很容易的知道图中的信息
① 我们要判定任意两顶点之间是否有边就非常容易
② 我们要知道某个顶点的度,其实就是这个顶点在邻接矩阵中 j 行的元素之和
3.带权图的邻接矩阵
在带权图的邻接矩阵中,每个矩阵元素表示一个有向边的权值。如果不存在从一个节点到另一个节点的边,则通常将其表示为特殊的值,如0,-1或无穷。
例:
假设有一个有向带权图,它有 4 个顶点(A,B, C, D),边及其权重如下:
①·边 A->B 的权重是3
② 边 A->C 的权重是7
③ 边 B->A 的权重是4
④ 边 B->D 的权重是1
⑤ 边 C->D 的权重是2
⑥ 边 D->A 的权重是1
我们可以将这个有向带权图表示为以下的邻接矩阵:
A B C D
A 0 3 7 0
B 4 0 0 1
C 0 0 0 2
D 1 0 0 0在这个矩阵中,行表示起始顶点,列表示目标顶点。矩阵元素的值代表起始顶点到目标顶点的边的权重。如果没有边存在,我们用0来表示。
例如:第一行表示从A到各点的边的权重,可以看出有从A到B的边,权重为3,有从A到C的边,权重为7,没有从A出发到达D的边,所以为0。
当然,什么情况下不能用 0 来代表边不存在的情况?
大多数情况下边权是正值,但个别时候真的有可能就是0,甚至有可能是负值。因此必须要用一个不可能的值来代表不存在。
4.邻接矩阵的优点
① 简单直观:
邻接矩阵是一个二维顺序表,通过矩阵中的元素值可以直接表示顶点之间的连接关系,非常直观和易于理解。
② 存储效率高:
对于小型图,邻接矩阵的存储效率较高,因为它可以一次性存储所有顶点之间的连接关系,不需要额外的空间来存储边的信息。
③ 算法实现简单:
许多图算法可以通过邻接矩阵进行简单而高效的实现,例如:遍历图、检测连通性等。
5.邻接矩阵的缺点
① 空间复杂度高:
对于大型图,邻接矩阵的空间复杂度较高,因为它需要存储一个 n x n 的矩阵,这可能导致存储空间的浪费和效率问题。
② 不适合稀疏图 :
邻接矩阵对于稀疏图(即图中大部分顶点之间没有连接)的表示效率较低,因为它会浪费大量的存储空间来存储零元素。
二、Python中的邻接矩阵
1.邻接矩阵数据结构实现
Ⅰ、邻接矩阵选择
代码使用二维列表adj作为邻接矩阵,通过n×n的矩阵存储顶点间的边权。矩阵中每个元素adj[i][j]表示顶点i到顶点j的边权重,inf(即-1)表示两顶点间无边。这种实现方式适合稠密图,因为空间复杂度为O(n^2),但查询边存在性的时间复杂度为O(1)。
Ⅱ、初始化逻辑
在构造函数__init__中,通过二重循环初始化全为inf的矩阵,确保所有顶点初始状态下互不相连
Ⅲ、功能方法
① add_edge(u, v, w):直接修改矩阵中对应位置的值为权重w,适合快速更新边权
② printGraph():按行打印矩阵,便于调试时直观查看图结构
inf = -1
class Graph:
def __init__(self, n):
self.n = n
self.adj = []
# 通过二层循环初始化邻接表
for i in range(n):
l = []
for j in range(n):
l.append(inf)
self.adj.append(l)
# u:邻接矩阵的横坐标 v:邻接矩阵的纵坐标 w:权重
def add_edge(self, u, v, w):
self.adj[u][v] = w
def printGraph(self):
for i in range(self.n):
for j in range(self.n):
print(self.adj[i][j], end=' ')
print()2.测试用例
inf = -1
class Graph:
def __init__(self, n):
self.n = n
self.adj = []
# 通过二层循环初始化邻接表
for i in range(n):
l = []
for j in range(n):
l.append(inf)
self.adj.append(l)
# u:邻接矩阵的横坐标 v:邻接矩阵的纵坐标 w:权重
def add_edge(self, u, v, w):
self.adj[u][v] = w
def printGraph(self):
for i in range(self.n):
for j in range(self.n):
print(self.adj[i][j], end=' ')
print()
def Test():
graph = Graph(5)
graph.add_edge(0, 1, 1)
graph.add_edge(0, 2, 2)
graph.add_edge(1, 2, 3)
graph.add_edge(1, 3, 4)
graph.add_edge(2, 3, 5)
graph.printGraph()
Test()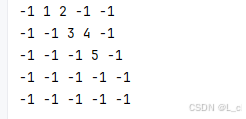


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









