







写在前面
自然语言处理是人工智能领域的一个重要分支,旨在使计算机能够理解、处理和生成人类语言。随着信息技术的飞速发展,全球范围内的文本数据呈指数级增长,如何高效地处理和分析这些海量语言信息成为了一个亟待解决的问题。NLP的研究不仅涉及语言学、计算机科学、认知科学等多个学科的交叉,还在机器翻译、信息检索、自动文摘、问答系统等实际应用中展现出巨大的潜力。然而,自然语言的复杂性、歧义性以及不断变化的语言现象也给NLP带来了诸多挑战。通过结合理性主义和经验主义的研究方法,NLP正在逐步突破技术瓶颈,为人类提供更加智能化的语言处理服务。
封面图片来源:百度图片
本系列文章是我的学习笔记,涵盖了入门的基础知识与模型以及对应的上机实验,截图截取自老师的课程ppt。
- 概论
- 词汇分析
- 句法分析
- 语篇分析
- 语义分析
- 语义计算
- 语言模型
- 文本摘要
- 情感分析
- 部分对应上机实验
目录
基本概念
- 语言学(linguistics):研究语言的本质、结构和发展规律的科学。 -商务印书馆,《现代汉语词典》,1996
- 语音和文字是语言的两个基本属性。
- 语音学 (phonetics):研究人类发音特点,特别是语音发音特点,并提出各种语音描述、分类和转写方法的科学。-戴维•克里斯特尔,《现代语言学词典》,1997
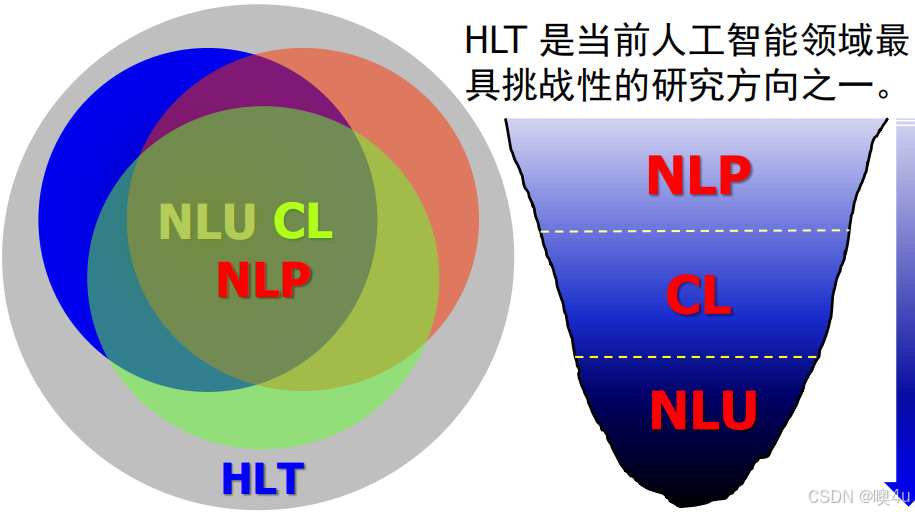
- 计算语言学(Computational Linguistics, CL):通过建立形式化的计算模型来分析、理解和生成自然语言的学科,是人工智能和语言学的分支学科。与内容接近的学科自然语言处理相比较,计算语言学更加侧重基础理论和方法的研究。-《计算机科学技术百科全书》(常宝宝)
- 自然语言理解(Natural Language Understanding, NLU):自然语言理解是探索人类自身语言能力和语言思维活动的本质,研究模仿人类语言认知过程的自然语言处理方法和实现技术的一门学科。是当今“人工智能皇冠上的明珠” 。- 《计算机科学技术百科全书》(宗成庆)
- 自然语言处理(Natural Language Processing, NLP):自然语言处理是研究如何利用计算机技术对语言文本(句子、篇章或话语等)进行处理和加工的一门学科,研究内容包括对词法、句法、语义和语用等信息的识别、分类、提取、转换和生成等各种处理方法和实现技术。专门针对中文的语言信息技术研究成为中文信息处理。- 《计算机科学技术百科全书》(宗成庆) 以下是三个不同的语系:
- 屈折语(fusional language/ inflectional language): 用词的形态变化表示语法关系,如英语、法语等。
- 黏着语(agglutinative language): 词内有专门表示语法意义的附加成分,词根或词干与附加成分的结合不紧密,如日语、韩语、土耳其语等。
- 孤立语(analytic language)(分析语, isolating language): 形态变化少,语法关系靠词序和虚词表示,如汉语。
研究内容
自然语言处理的研究内容非常广泛,涵盖了从基础的语言理解到实际应用的多个方面。以下是主要的研究内容及其举例:
1. 机器翻译(Machine Translation, MT):
- 定义:实现一种语言到另一种语言的自动翻译。
- 举例:Google翻译、百度翻译等。
2. 信息检索(Information Retrieval):
- 定义:利用计算机系统从大量文档中找到符合用户需要的相关信息。
- 举例:Google、百度等搜索引擎。
3. 自动文摘(Automatic Summarization):
- 定义:将原文档的主要内容或某方面的信息自动提取出来,形成摘要。观点挖掘 (Opinion mining) 。
- 举例:新闻摘要生成、论文摘要生成、电子图书管理等。
4. 问答系统(Question-Answering System):
- 定义:通过计算机系统对人提出的问题进行理解,并自动求解答案。
- 举例:百度知道、IBM Watson自动问答系统。
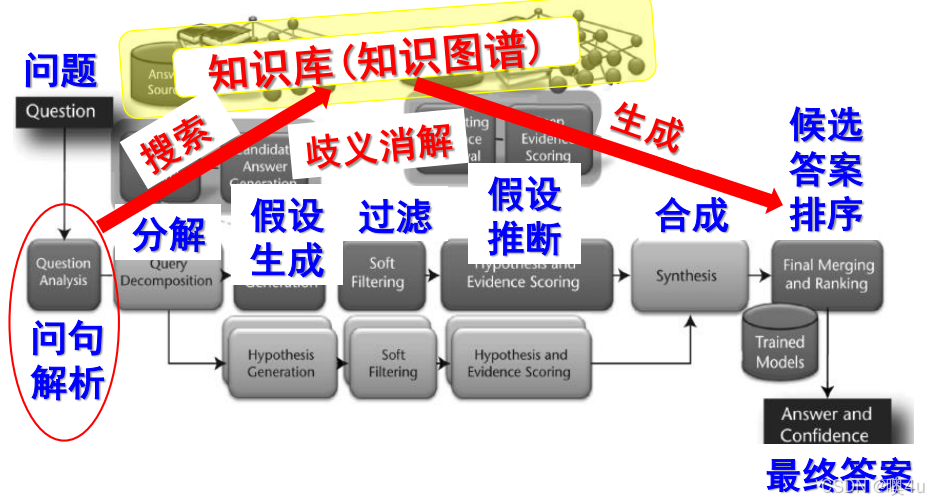
5. 信息过滤(Information Filtering):
- 定义:通过计算机系统自动识别和过滤满足特定条件的文档信息。
- 举例:垃圾邮件过滤、社交媒体内容过滤。
6. 信息抽取(Information Extraction):
- 定义:从指定文档或海量文本中抽取出用户感兴趣的信息。
- 举例:实体关系抽取、从新闻中抽取人名、地名、事件等。
7. 文档分类(Document Categorization):
- 定义:利用计算机系统对大量文档按照一定的分类标准实现自动归类。
- 举例:新闻分类、情感分类(如正面、负面评论)。
8. 文字编辑和自动校对(Automatic Proofreading):
- 定义:对文字拼写、用词、语法、文档格式等进行自动检查、校对和编辑。
- 举例:Word的拼写检查、Grammarly。
9. 语音识别(Automatic Speech Recognition, ASR):
- 定义:将输入语音信号自动转换成书面文字。
- 举例:语音输入法、语音助手(如Siri、Alexa)。
10. 语音合成(Text-to-Speech Synthesis):
- 定义:将书面文本自动转换成对应的语音表征。
- 举例:朗读系统、语音导航。
11. 说话人识别/验证(Speaker Recognition/Verification):
- 定义:对语音样品进行声学分析,推断说话人的身份。
- 举例:语音解锁、身份验证
基本问题和主要困难
自然语言处理面临许多基本问题和困难,主要包括以下几个方面:
1. 形态学(Morphology)问题:
- 定义:研究词的构成问题,特别是词素(morphemes)的组合。
- 词素:词根、前缀、后缀、词尾
- 举例:单词的识别/ 汉语的分词问题。(如“自动化研究所”可以分成“自动化/研究所”或“自动化/研究/所”)。
2. 句法(Syntax)问题:
- 定义:研究句子结构成分之间的相互关系和组成句子序列的规则。
- 举例:句法歧义(如“苹果吃了我”和“我吃了苹果”)。
3. 语义(Semantics)问题:
- 定义:研究如何从语句中词的意义和句法结构推导出语句的意义。
- 举例:语义歧义(如“苹果不吃了”可以理解为“不吃苹果”或“苹果坏了”)。
4. 语用学(Pragmatics)问题:
- 定义:研究在不同上下文中语句的应用,以及上下文对语句理解的影响。
- 举例:语用歧义(如“火,火!”可以表示火灾或强调某事物)。
5. 语音学(Phonetics)问题:
- 定义:研究语音特性、语音描述、分类及转写方法等。
- 举例:同音词(如“花”和“华”)。
6. 歧义(Ambiguity)问题:
- 定义:语言中存在大量的歧义现象,包括词法歧义、句法歧义、语义歧义和语音歧义。
- 举例:词法歧义(如“自动化研究所取得的成就”可以理解为“自动化/研究所”或“自动化/研究/所”)。词性奇异(如“Time flies like an arrow.”,到底是“光阴似箭”还是“一种叫Times的苍蝇喜欢箭头”?)。结构起义(如“关于/鲁迅的文章”还是“关于鲁迅的/文章”)......
7. 未知语言现象:
- 定义:新词、新术语、新用法和新句型等不断出现,尤其在网络语言中。
- 举例:新词“苹果”(手机)等。
归纳起来,NLU 所面临的挑战主要有:普遍存在的不确定性、未知语言现象的不可预测性、始终面临的数据不充分性、语言知识表达的复杂性(隐喻表达(如“把权力装进制度的笼子”))、机器翻译中映射单元的不对等性(词法表达不相同、 句法结构不一致、语义概念不对等(如英语“ICE BOX”翻译成汉语“冰箱”))
研究现状
(1)部分问题得到了解决,可以为人们提供辅助性的帮助
(2)基础问题研究仍任重而道远
(3)社会需求日益迫切
(4)许多技术离真正实用的目标还有相当的距离,尚未建立起有效、完善的理论体系。
大语言模型(如GPT-3、BERT等)的词语划分方式与人类学习语言的方式目前仍然存在显著差异,主要体现在以下几个方面:
1. 词语划分方式
- 大语言模型:通常使用子词划分(Subword Tokenization)技术,如Byte Pair Encoding (BPE) 或 WordPiece。这些方法将词汇分解为更小的子词单元,以平衡词汇表大小和模型处理能力。例如,单词“unhappiness”可能被分解为“un”、“happi”、“ness”。
- 人类学习语言:人类通常以完整词汇为单位学习语言,并结合上下文理解词义。例如,儿童通过反复听到“unhappiness”这个词,逐渐理解其含义和用法,而不是将其分解为子词。
2. 上下文理解
- 大语言模型:依赖大量文本数据,通过统计规律学习词语之间的关系,但缺乏对语义的深层理解。例如,模型可能通过共现频率知道“unhappiness”与“sadness”相关,但无法真正理解情感。
- 人类学习语言:结合语境、情感和实际经验理解语言。例如,人类不仅能理解“unhappiness”的字面意思,还能通过情感体验理解其深层含义。
3. 学习过程
- 大语言模型:通过大规模数据训练,学习词语的统计分布和模式。例如,模型通过大量文本学习“unhappiness”常出现在负面情感的上下文中。
- 人类学习语言:通过互动、实践和认知发展逐步掌握语言。例如,儿童通过与父母对话、阅读书籍等方式学习词汇和语法。
基本研究方法
自然语言处理的研究方法主要分为两大类:理性主义方法和经验主义方法。
-
理性主义方法:
- 定义:通过建立形式化的规则和符号系统来处理自然语言。
- 基本思路:基于规则的分析方法,建立符号处理系统。
- 举例:利用语法规则进行句法分析,生成句法树。如翻译句子:There is a book on the desk.
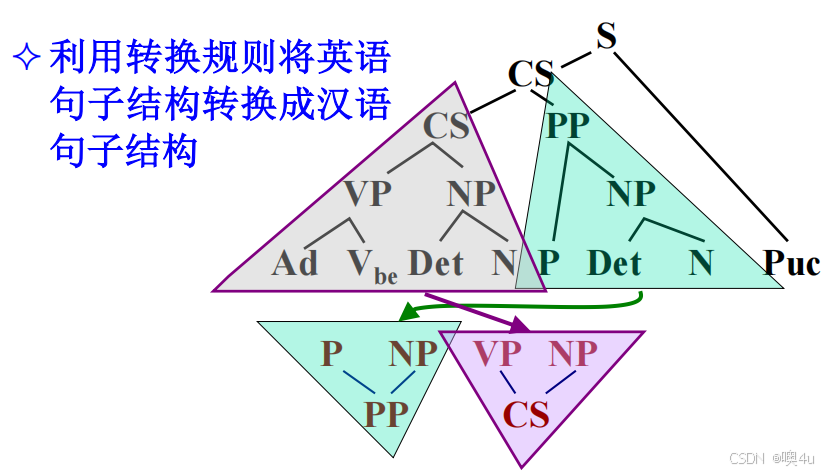
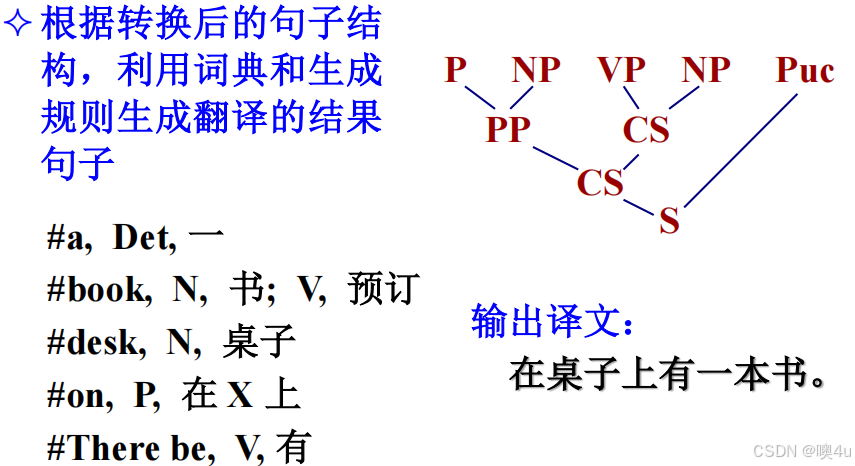
- 步骤:
- 规则库开发(如 N+N→NP)。
- 词典标注(如“工作”标注为名词或动词)。
- 推导算法设计(如归约、推导、歧义消解方法)。
-
经验主义方法:
-
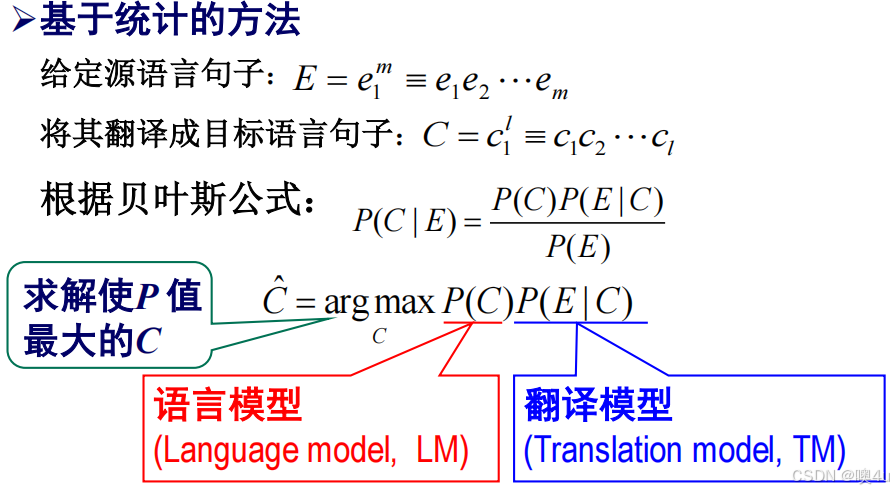
定义:通过大规模真实语料的统计分析来处理自然语言。
-
基本思路:基于大规模真实语料建立统计模型。
-
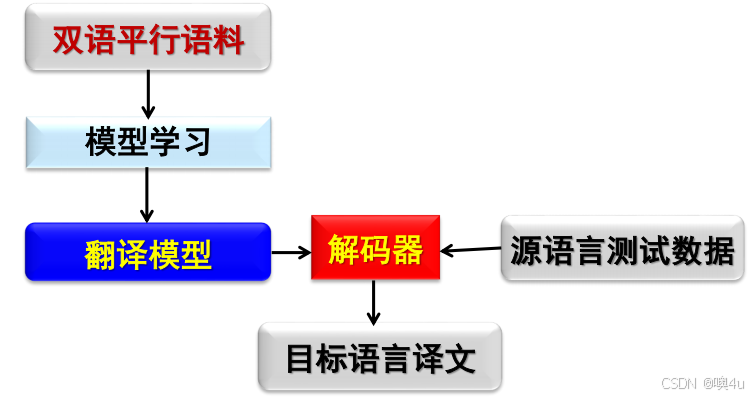
举例:利用统计模型进行机器翻译。

-
步骤:
- 大规模真实数据的收集和标注。
- 统计模型的建立(如语言模型、翻译模型)。
- 参数训练与模型优化。
-
-
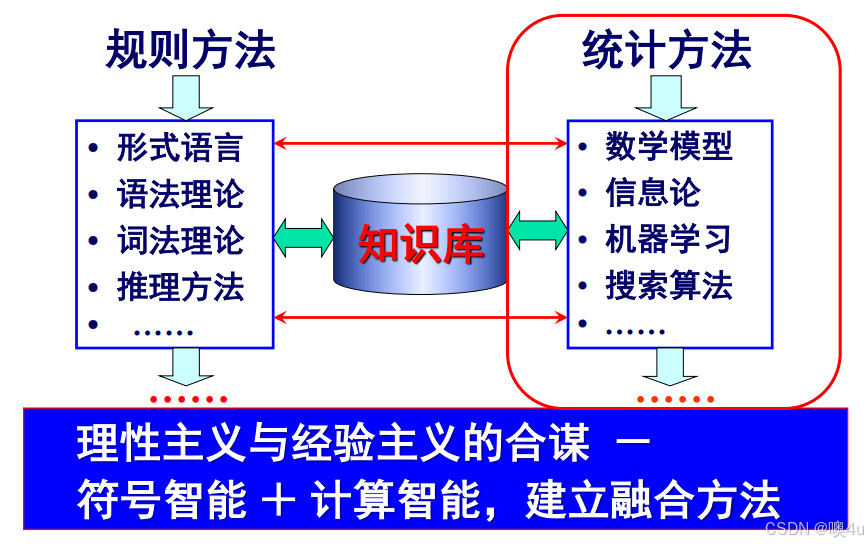
融合方法:
-
定义:结合理性主义和经验主义的方法,利用符号智能和计算智能的优势。
-
举例:结合规则和统计模型进行机器翻译。
-
步骤:
- 利用规则进行初步分析。
- 利用统计模型进行优化和调整。
-
预热实验-字串处理(汉字的熵)
熵的介绍具体见《机器学习》专栏-《信息论研讨》
实验要求
- 1. 给出前100个汉字高频字的频率统计结果;
- 2. 分别给出前1、20、100、600、2000、3000汉字的字频总和;
- 3. 计算汉字的熵值;
设计思路(简述)
1. 文本预处理
- 打开并读取 txt 文件的内容(以utf-8格式)。
- 利用正则表达式提取所有中文汉字(Unicode 范围通常为 \u4e00-\u9fff)。
2. 统计汉字频率
- 使用Python内置的collections.Counter对所有汉字进行计数。
- 使用most_common方法获取前100个出现频率最高的汉字及频数。
3. 计算部分统计量
- 对于前 1、20、100、600、2000、3000 个汉字,分别计算它们出现次数的总和。
- 当汉字种类少于某个阈值时,可直接累加所有可用的汉字频数。
4. 计算汉字熵值
- 根据频率计算每个汉字出现的概率:p = frequency/total_count。
- 计算所有汉字的熵值。
import re
import math
from collections import Counter
def read_chinese_text(file_path):
"""读取文件并提取所有中文汉字"""
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# text = f.read().lower() # 若是英文单词,先全部转为小写,以便统计单词数量。
# 正则匹配中文字符
chinese_chars = re.findall(r'[\u4e00-\u9fff]', text)
# 若是英文:利用正则表达式匹配英文单词,排除标点
# words = re.findall(r"\b[a-z]+(?:'[a-z]+)*\b", text) # 非单词+[a-z]+"'"(若有)+[a-z]+非单词
return chinese_chars
# return words # 若是英文
def calculate_frequency(chars):
"""统计每个汉字出现频率"""
counter = Counter(chars)
return counter
def print_top_n(counter, n=100):
"""打印前 n 个高频汉字及其频率"""
top_n = counter.most_common(n)
total = sum(counter.values())
print(f"前 {n} 个高频汉字及频率:")
for char, count in top_n:
print(f"{char}: {count/total}")
return top_n
def sum_top_n(counter, n):
"""计算前 n 个高频汉字的频数总和"""
top_n = counter.most_common(n)
return sum(count for _, count in top_n)
def calculate_entropy(counter):
"""计算汉字熵值"""
total = sum(counter.values())
entropy = 0.0
for count in counter.values():
p = count / total
entropy -= p * math.log(p, 2)
return entropy
if __name__ == '__main__':
file_path = 'ch.txt'
# 读取文件并提取汉字
chinese_chars = read_chinese_text(file_path)
# 统计频率
counter = calculate_frequency(chinese_chars)
# 1. 输出前100个汉字高频统计结果
top_100 = print_top_n(counter, 100)
# 2. 分别给出前1、20、100、600、2000、3000汉字的字频总和
thresholds = [1, 20, 100, 600, 2000, 3000]
print("\n各阈值下的汉字频数总和:")
for t in thresholds:
total_sum = sum_top_n(counter, t)
print(f"前 {t} 个汉字总频数: {total_sum}")
# 3. 计算汉字的熵值
entropy_value = calculate_entropy(counter)
print(f"\n汉字熵值: {entropy_value:.4f}")
汉字所传达的信息量也是很大的。比如汉语中的多音字以及一词多义。其中特别以文言文和诗词为代表。汉字相比于其他语言,在一定程度上也有更多的信息量。比如唐朝诗人李白的《赠汪伦》,“李 白 乘 舟 将 欲 行 , 忽 闻 岸 上 踏 歌 声 。 桃 花 潭 水 深 千 尺 , 不 及 汪 伦 送 我 情 。”如果译为英文的话,“I'm on board; We're about to sail, When there's stamping and singing on shore; Peach Blossom Pool is a thousand feet deep, Yet not so deep,Wang Lun,as your love for me. ”同样的内容,汉字平均携带的信息量更大。
可以证明,当汉字容量超过12370以后, 随着汉字容量的继续扩大, 熵值不会有显著的增加,包含在一个汉字中的熵为9.65比特。并且,如果再进一步扩大汉字容量, 这个熵值不会再增加。因而9.65比特就是在全部现代汉语书面语文句中, 包含在一个汉字中的熵。
在《赠汪伦》的汉语及英译中,汉字为28个,英文字母不计空格为131个,此时中文本中一个汉字大约相当于英译本中的4.6786个英文字母。用同样的方法,有人通过《毛泽东选集》中文本和英译本部分文章的初步统计测出,当中文本英译时, 中文本中一个汉字大约相当于英译本中的3.8 个英文字母。而有统计表明,随着文本容量的逐渐增大, 英文原文中英语字母数与相应汉语译文中的汉字数比值逐渐趋于稳定, 基本上稳定在2.7左右。综合考虑英译中与中译英的情况,同样内容的英语文本中的英语字母数与汉语文本中的汉字数之比, 应该取3.8与2.7的平均值3.25。
一般说来, 具有相同内容的英语文章和汉语文章, 其中所包含的全部信息量是应该相等的。例如, 一篇英语文章及其相应的汉语译文,或者一篇汉语文章及其相应的英语译文, 其中所包含的全部信息量应该相等。
国外学者已经求出包含在一个英语字母中的极限熵大约在0.9296比特到1.5460比特,平均为1.245比特。也就是说,每当我们读到一个汉字,我们获得的信息量的平均值为4.0462比特,这就是汉字的极限熵。
为验证“汉字容量与汉字熵值”之间的关系,本实验选取了如下的不同规模的语料重复上述中文部分的实验,每篇文章的汉字容量(不重复的汉字数量)、汉字熵值如下图和下表所示。汉字熵值大体随着总字数的增加而增加,且当汉字容量比较小的时候,随着汉字容量的扩大,熵值相应地迅速增大,而当汉字容量继续扩大时,熵值的增加就变得比较迟缓了。

| 文章名 | 汉字容量 | 熵值 | 文章名 | 汉字容量 | 熵值 |
| 爱莲说 | 119 | 6.4657 | 离骚 | 2489 | 8.3580 |
| 琵琶行 | 254 | 5.8283 | 笑傲江湖-序 | 4495 | 8.5693 |
| 蜀道难 | 394 | 7.4182 | 野草-后一半 | 7407 | 8.8293 |
| 岳阳楼记 | 450 | 7.5439 | 野草-前一半 | 8142 | 8.6609 |
| 阿房宫赋 | 513 | 7.6877 | 骆驼祥子7-9 | 13777 | 8.5493 |
| 出师表 | 624 | 7.7351 | 骆驼祥子4-6 | 14348 | 8.5528 |
| 滕王阁序 | 773 | 7.6715 | 骆驼祥子1-3 | 14714 | 8.6255 |
| 过秦论 | 894 | 8.6136 | 骆驼祥子13 | 15932 | 8.6746 |
| 孔雀东南飞 | 1840 | 8.1000 | 笑傲江湖-4 | 19267 | 8.7674 |
| 从百草园到三味书屋 | 2152 | 8.3192 | 笑傲江湖-5 | 27807 | 8.8831 |
总结
自然语言处理的研究内容涵盖了从基础的语言理解到实际应用的多个方面,如机器翻译、信息检索、自动文摘等。其基本问题包括形态学、句法、语义、语用学和语音学等问题,主要困难在于歧义、未知语言现象、数据不充分性和语言知识表达的复杂性等。研究方法则主要分为理性主义方法和经验主义方法,近年来逐渐趋向于两者的融合。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}