







写在前面
当我们拿到适用于机器学习的数据,为避免数据质量的参差不齐导致学习到的结果不理想,数据处理通常是不可避免的第一步。在这一篇文章中,我们将聚焦对于各种数据形式的各种处理方式。
- 1.python基础;
- 2.ai模型概念+基础;
- 3.数据预处理;
- 4.机器学习模型--1.编码(嵌入);2.聚类;3.降维;4.回归(预测);5.分类;
- 5.正则化技术;
- 6.神经网络模型--1.概念+基础;2.几种常见的神经网络模型;
- 7.对回归、分类模型的评价方式;
- 8.简单强化学习概念;
- 9.几种常见的启发式算法及应用场景;
- 10.机器学习延申应用-数据分析相关内容--1.A/B Test;2.辛普森悖论;3.蒙特卡洛模拟;
- 11.数据挖掘--关联规则挖掘
- 12.数学建模--决策分析方法,评价模型
- 13.主动学习(半监督学习)
- 以及其他的与人工智能相关的学习经历,如数据挖掘、计算机视觉-OCR光学字符识别、大模型等。
本文目录
SMOTE(Synthetic Minority Over-sampling Technique)
对抗样本生成(Adversarial Training)(负面样本)
数据清洗
数据清洗是数据处理中的关键步骤,旨在识别并纠正数据中的错误或不一致,以提高数据质量。
处理缺失数据
- 删除缺失值: 直接删除包含缺失值的记录或列(适用于缺失值很少的情况)。
- 填充缺失值: 用均值、中位数、众数、前/后一个值或插值等方法填补缺失数据。
- 插值: 对时间序列数据,使用线性插值或更复杂的方法填补缺失值。
- 使用模型填补: 使用回归或机器学习模型预测缺失值。
import pandas as pd
df = pd.DataFrame(data)
df.dropna() # 删除包含缺失值的行
df.fillna(df.mean()) # 用均值填充缺失值处理重复数据
- 查找和删除重复记录: 删除数据集中重复的行,以防止数据偏差。
df.drop_duplicates() # 删除重复的行识别和处理异常值
- 箱线图法(IQR): 使用四分位距识别和处理异常值。
- Z分数法: 使用Z分数(标准化值)来识别异常值。
- 手动处理: 根据业务知识和背景判断并处理异常值。
# 使用IQR法处理异常值
Q1 = df['column_name'].quantile(0.25) #计算了column_name列的第一四分位数(Q1),即数据中25%位置的值。
Q3 = df['column_name'].quantile(0.75) #计算了column_name列的第三四分位数(Q3),即数据中75%位置的值。
IQR = Q3 - Q1 #计算了四分位距(Interquartile Range, IQR),即Q3与Q1的差值。IQR表示数据中间50%的范围,是一个衡量数据集中分散程度的指标。
df = df[~((df['column_name'] < (Q1 - 1.5 * IQR)) | (df['column_name'] > (Q3 + 1.5 * IQR)))] #先计算上下两个边界,在取反,舍去在边界外的异常值箱体图(Boxplot)
箱线图是一种用于显示数据分布的统计图表,常用于观察数据的集中趋势、离散程度及异常值。箱线图的主要组成部分包括:
- 最小值:数据的最小值,通常是第一个"须"的起点。
- 第一四分位数(Q1):即数据的下四分位数,表示数据中25%的值小于它。
- 中位数(Q2):即数据的中值,表示数据50%处的值。
- 第三四分位数(Q3):即上四分位数,表示数据中75%的值小于它。
- 最大值:数据的最大值,通常是第二个"须"的终点。
- 异常值(离群点):位于箱体以外的值,通常被标记为独立点。
图中关键部分:
- 箱体:由Q1到Q3形成,显示中间50%数据的分布范围,箱体的长度称为四分位距(IQR)。
- 中位数线:位于箱体内,表示数据的中位数。
- “须”:从箱体延伸到数据的最小值和最大值(不包括离群点)。
- 离群点:位于“须”之外的值,表示异常数据。
箱线图帮助快速识别数据中的对称性、偏态、异常值以及上下四分位数之间的差异。
标准化与归一化
- 标准化: 将数据转换为均值为0、方差为1的标准正态分布,适用于特征分布不同的情况。
- 归一化: 将数据缩放到指定范围(通常是 [0, 1] 或 [-1, 1]),适用于确保特征值在相同范围内的情况。 x =(x-xmin)/(xmax-xmin)
- 目的:得到更平坦的优化地形
- 平坦最小值(好) v.s. 尖锐最小值
- 批量归一化、层归一化、单个实例归一化、多个实例归一化
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df[['column1', 'column2']])
normalizer = MinMaxScaler()
df_normalized = normalizer.fit_transform(df[['column1', 'column2']])处理不一致的数据
- 格式统一: 确保日期、时间、货币等格式一致。
- 拼写纠正: 识别并纠正拼写错误,尤其是分类变量。
- 数据类型转换: 转换数据类型,如将字符串类型的数字转换为数值类型。
df['date_column'] = pd.to_datetime(df['date_column']) # 转换为日期类型
df['numeric_column'] = pd.to_numeric(df['numeric_column'], errors='coerce') # 转换为数值类型,errors='coerce':某个值无法转换为数值时自动替换为NaN处理数据中的噪声
- 平滑: 使用移动平均、回归等方法平滑数据中的噪声。
- 聚合: 将数据聚合到更高的层次以减少噪声。
df['smoothed'] = df['column_name'].rolling(window=3).mean() # 移动平均平滑
#移动平均法通过取一段数据的平均值来替换当前数据点的值,从而消除短期的波动,可能削弱数据的细节和极值,窗口大小的选择对结果影响较大特征工程
- 创建/转换特征: 通过计算、合并或分解创建新的特征,或转换现有特征。
- 编码分类变量: 将分类变量转换为数值(如独热编码(会在第四篇《聚类》中具体介绍)、标签编码)。
df['new_feature'] = df['feature1'] * df['feature2'] # 创建新特征 (组合)
df = pd.get_dummies(df, columns=['category_column']) # 独热编码处理相关性高的特征
- 去除冗余特征: 使用相关性矩阵(线性代数概念)去除高度相关的特征,以简化模型。
corr_matrix = df.corr().abs()
upper_triangle = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool_))
to_drop = [column for column in upper_triangle.columns if any(upper_triangle[column] > 0.95)]
df.drop(columns=to_drop, inplace=True) #删除相关性很高的列数据转换
- 数据变换: 通过对数变换、Box-Cox变换等技术处理非正态分布的数据。
df['log_transformed'] = np.log(df['column_name'] + 1) # 对数变换整合和分割数据
- 合并数据集: 使用合并、连接、拼接等技术将多个数据集整合成一个。
- 数据分割: 将数据集按训练集、验证集和测试集分割。
自动化数据清洗
- 使用自动化工具: 利用Pandas Profiling、Great Expectations等工具自动化数据清洗过程,生成报告和验证规则。
Pandas Profiling是一个用于快速生成数据集的探索性数据分析 (Exploratory Data Analysis, EDA) 报告的 Python 库。可以快速了解数据集的结构、变量分布、数据类型、缺失值、统计信息、相关性等。
Pandas Profiling 生成的报告包含了以下内容:
- 数据概览:包括数据的行数、列数、缺失值数目等基本信息。
- 变量描述:针对每个变量,提供数据类型、唯一值、缺失值百分比、最小值、最大值、平均值、标准差等统计信息。
- 警告提示:如果数据中存在高相关性、过多的缺失值、异常值等情况,会给出相应的警告。
- 相关性分析:展示变量之间的相关性矩阵,并标记出高相关性变量。
- 交互式可视化:通过图表和交互式内容,更好地理解数据分布和特征。
对于非常大的数据集,生成报告可能会比较耗时,或者生成的报告文件可能过大。可以通过启用 minimal=True 或者对数据进行采样来解决这个问题。
import pandas_profiling
profile = pandas_profiling.ProfileReport(df, explorative=True) #explorative: 启用更加详细和交互性的分析(默认为 False)
profile.to_file("output.html")数据增强
数据增强是通过对原始数据进行多种变换,生成新的数据样本,以增加训练数据的多样性,提高模型的泛化能力。
图像数据增强
除以下我列出的这些外,还有专门用于“数字图像处理”的数据增强方式,如灰度变换、直方图均衡化、选择滤波等等,详细可以见我的另一个专栏《从0开始数字图像处理》。
旋转
- 随机旋转图像一定角度。
- 常用的旋转范围为 -30° 到 30°。
from PIL import Image
# 打开图像
image = Image.open('your_image.jpg')
# 旋转图像(参数为旋转的角度,expand=True用于避免裁剪)
rotated_image = image.rotate(45, expand=True)
# 保存旋转后的图像
rotated_image.save('rotated_image.jpg')
# 展示旋转后的图像
rotated_image.show()
翻转
- 随机水平或垂直翻转图像。
- 水平翻转较为常用,垂直翻转则视情况使用。
# 水平翻转图像
flipped_image = image.transpose(Image.FLIP_LEFT_RIGHT)
#################################################
# 垂直翻转图像
flipped_image = image.transpose(Image.FLIP_TOP_BOTTOM)缩放
- 随机缩放图像的尺寸,可以是放大或缩小。
- 通常保持图像的纵横比不变。
# 缩放图像到新的宽度和高度(例如 200x300)将图像缩放到200像素宽和300像素高。
scaled_image = image.resize((200, 300))
#################################################
# 计算新的尺寸以保持宽高比
width, height = image.size
aspect_ratio = width / height
new_width = 200
new_height = int(new_width / aspect_ratio)
# 缩放图像并保持宽高比
scaled_image = image.resize((new_width, new_height))
平移
- 随机平移图像的水平或垂直位置。
- 平移范围通常为图像尺寸的10%-20%。
- Pillow库本身没有直接的平移方法,但可以通过创建一个新的空白图像,并将原图像粘贴到指定的偏移位置来实现平移。
# 获取原图像尺寸
width, height = image.size
# 创建一个新的空白图像,大小与原图像相同
translated_image = Image.new('RGB', (width, height))
# 设置平移的偏移量(比如向右移动50像素,向下移动30像素)
x_offset = 50
y_offset = 30
# 将原图像粘贴到新图像上的偏移位置
translated_image.paste(image, (x_offset, y_offset))剪切
- 以一定角度随机剪切图像,使图像形变。剪切角度一般在 0° 到 20° 之间。
- 也指从原图像中截取出一个指定的矩形区域。
# 定义裁剪区域(左,上,右,下)
crop_area = (100, 50, 300, 250)
# 剪切图像
cropped_image = image.crop(crop_area)亮度调整
- 随机调整图像的亮度,使其变亮或变暗。
# 创建一个亮度增强对象
enhancer = ImageEnhance.Brightness(image)
# 调整亮度(1.0为原始亮度,0.5为降低亮度,2.0为增加亮度)
brightness_factor = 1.5 # 将亮度增加50%
brightened_image = enhancer.enhance(brightness_factor)对比度调整
- 随机调整图像的对比度,使亮区更亮,暗区更暗,或反之。
# 创建一个对比度增强对象
contrast_enhancer = ImageEnhance.Contrast(image)
# 调整对比度(1.0 为原始对比度,0.5 为降低对比度,2.0 为增加对比度)
contrast_factor = 1.8 # 将对比度增加 80%
enhanced_image = contrast_enhancer.enhance(contrast_factor)噪声添加
- 在图像中随机添加高斯噪声、椒盐噪声等,增加数据的多样性。
高斯噪声:
一种符合高斯分布(或正态分布)的噪声,通常用来模拟传感器噪声或背景噪声。在图像中,它表现为像素值的随机偏移,偏移量服从高斯分布,即某个像素值会增加或减少一个符合正态分布的随机值。均匀地影响图像中所有像素,造成平滑的随机变化。
def add_gaussian_noise(image, mean=0, std=25):
"""
向图像添加高斯噪声
:param image: 输入图像,类型为numpy数组
:param mean: 高斯噪声的均值
:param std: 高斯噪声的标准差
:return: 添加噪声后的图像
"""
# 生成高斯噪声
gaussian_noise = np.random.normal(mean, std, image.shape)
noisy_image = image + gaussian_noise
# 将像素值剪辑到0-255范围内
noisy_image = np.clip(noisy_image, 0, 255).astype(np.uint8)
return noisy_image椒盐噪声:
是一种随机出现的黑白噪声,类似于图像上撒了黑色和白色的“盐”和“胡椒”,因此得名。它表现为图像中某些像素值被随机地设置为最大值(白色)或最小值(黑色),通常用于模拟图像传输中的数据丢失或错误。只影响图像中的一部分像素,使得部分像素突然变得完全黑或完全白。
def add_salt_and_pepper_noise(image, amount=0.05, salt_vs_pepper=0.5):
"""
向图像添加椒盐噪声
:param image: 输入图像,类型为numpy数组
:param amount: 添加噪声的比例
:param salt_vs_pepper: 盐噪声(白色)与胡椒噪声(黑色)的比例
:return: 添加噪声后的图像
"""
noisy_image = image.copy()
num_salt = np.ceil(amount * image.size * salt_vs_pepper)
num_pepper = np.ceil(amount * image.size * (1.0 - salt_vs_pepper))
# 添加盐噪声(白色)
coords = [np.random.randint(0, i - 1, int(num_salt)) for i in image.shape]
# numpy.random.randint(low, high=None, size=None, dtype=int) 生成随机数
# 会生成两组长度为 int(num_salt) 的随机整数:
noisy_image[coords] = 255
# 添加胡椒噪声(黑色)
coords = [np.random.randint(0, i - 1, int(num_pepper)) for i in image.shape]
noisy_image[coords] = 0
return noisy_image颜色抖动
- 随机调整图像的色调、饱和度和亮度,使其颜色分布发生变化。
- Pillow库没有直接提供一个"抖动"的方法,但可以使用其
convert()方法来对图像进行颜色抖动处理,尤其是将图像转换为更少的颜色数时。
# 使用抖动将图像转换为调色板模式(P模式,减少颜色数)
dithered_image = image.convert('P', dither=Image.FLOYDSTEINBERG)
#FLOYDSTEINBERG 是常用的抖动算法,它通过调整周围像素来平滑过渡。
# 保存抖动后的图像
dithered_image.save('dithered_image.jpg')
##### Image.ORDERED: 使用有序抖动算法。裁剪
- 随机裁剪图像的某个区域,并将其缩放到原始尺寸。
插值
- 将两张图像按一定比例进行加权混合,生成新的图像。
# 目标尺寸
new_size = (400, 300)
# 使用最近邻插值进行缩放,适合处理较简单的图像,速度快。
nearest_image = image.resize(new_size, Image.NEAREST)
nearest_image.save('nearest_image.jpg')
# 使用双线性插值进行缩放,平滑程度较高。
bilinear_image = image.resize(new_size, Image.BILINEAR)
bilinear_image.save('bilinear_image.jpg')
# 使用双三次插值进行缩放,质量更高,适合放大图像。
bicubic_image = image.resize(new_size, Image.BICUBIC)
bicubic_image.save('bicubic_image.jpg')
# 使用Lanczos插值进行缩放,适合图像缩小时的高质量插值。
lanczos_image = image.resize(new_size, Image.LANCZOS)
lanczos_image.save('lanczos_image.jpg')
文本数据增强
同义词替换
- 使用同义词替换文本中的某些单词,以产生新的句子。
- Python库NLTK(英文)、使用预训练的Word2Vec模型(会在第四章《聚类中具体介绍》)、 手动同义词替换
import nltk
from nltk.corpus import wordnet
import random
# 下载WordNet数据
nltk.download('wordnet')
nltk.download('omw-1.4')
# 同义词替换函数
def synonym_replacement(sentence, n):
words = sentence.split()
new_sentence = words.copy()
# 找出句子中的可替换词(名词、动词、形容词等)
replaceable_words = [word for word in words if len(wordnet.synsets(word)) > 0]
# 如果没有可以替换的词,直接返回原句子
if len(replaceable_words) == 0:
return sentence
# 随机选择n个单词进行替换
random_words = random.sample(replaceable_words, min(n, len(replaceable_words)))
for word in random_words:
synonyms = wordnet.synsets(word)
lemmas = set([lemma.name() for syn in synonyms for lemma in syn.lemmas()])
# 从同义词集中随机选择一个,避免与原单词相同
if lemmas:
lemmas.discard(word)
if len(lemmas) > 0:
new_word = random.choice(list(lemmas))
new_sentence = [new_word if w == word else w for w in new_sentence]
return ' '.join(new_sentence)
# 示例
sentence = "The quick brown fox jumps over the lazy dog"
augmented_sentence = synonym_replacement(sentence, n=2)
print("Original:", sentence)
print("Augmented:", augmented_sentence)
示例输出:
Original: The quick brown fox jumps over the lazy dog
Augmented: The agile brown fox jumps over the lazy dog
随机插入
- 随机选择一些单词,插入到文本中的随机位置。
随机交换
- 随机交换文本中两个单词的位置。
优点:
- 提高模型适应性:通过打乱单词顺序,模型能够学习到更灵活的特征表示,适应不同的句子结构和排列方式。
- 增强理解能力:模型在训练时接触到不同的表达方式,能够理解同一语义下的多种表达形式,从而提升理解能力。
- 防止过拟合:与随机删除类似,随机交换生成的句子与原句不同,有助于增加训练样本的多样性,减少模型对特定输入的记忆。
随机删除
- 随机删除文本中的某些单词。
优点:
- 减少过拟合:通过生成不同的训练样本,减少模型对特定输入的依赖,从而降低过拟合的风险。
- 增强模型鲁棒性:模型在训练时接触到不完整的输入,可以提高其对缺失信息的鲁棒性,在实际应用中面对缺失或不完整数据时表现更好。
- 多样性:生成的句子保留了大部分原始句子的结构和语义,同时引入了变化,增加了数据集的多样性。
随机删除和随机交换在文本数据增强中起到的作用主要体现在:
- 增强数据集的多样性:通过不同的操作生成新的训练样本,使模型在训练过程中看到更多的变化。
- 提高模型的泛化能力:帮助模型适应更广泛的输入,减少对特定模式的过拟合,从而在真实世界中表现得更加稳健。
- 增强鲁棒性:使模型对输入数据中的噪声和不完整性更加敏感,增强其处理现实场景中的变异能力。
回译
- 将文本翻译成另一种语言,再翻译回原语言,以生成不同的句子结构。
音频数据增强方法
对于音频数据,我还没接触到过具体试验,因此这些仅存在理论上。
时间平移
- 随机平移音频信号,模拟录音延迟等情况。
加噪声
- 在音频中添加背景噪声,如白噪声或环境噪声。
时间拉伸
- 改变音频的播放速度,而不改变音调。
音调调整
- 随机升高或降低音频的音调。
裁剪
- 随机裁剪音频片段。
常用于结构化数据的增强方法
插值
- 使用现有数据点插值生成新的数据点。
噪声注入
- 在数值特征中添加随机噪声,模拟数据的轻微变化。
混合(组合)
- 将两个样本的特征和标签按一定比例混合,生成新的样本。
- 在统计具有因果关系或现实意义时的数据分析较为常用。
SMOTE(Synthetic Minority Over-sampling Technique)
- 通过生成少数类样本,解决类别不平衡问题。
其他数据增强方法
对抗样本生成(Adversarial Training)(负面样本)
- 通过生成对抗样本,增强模型的鲁棒性。
- 通过利用梯度信息生成微小扰动,模型能够在训练过程中接触到更多的变化形式,并学习如何应对这些变化。这在实际应用中,尤其是安全相关领域(如图像识别、自动驾驶等)具有重要意义。
最常用的对抗样本生成方法包括:
- FGSM(Fast Gradient Sign Method)
- PGD(Projected Gradient Descent)
import torch
import torch.nn as nn
# 定义对抗样本生成函数(FGSM)
def fgsm_attack(model, loss_fn, data, target, epsilon):
# 确保输入的数据有梯度
data.requires_grad = True
# 前向传播获取模型输出
output = model(data)
# 计算损失
loss = loss_fn(output, target)
# 反向传播计算输入的梯度
model.zero_grad()
loss.backward()
# 计算梯度的符号
data_grad = data.grad.data
sign_data_grad = data_grad.sign()
# 生成对抗样本
perturbed_data = data + epsilon * sign_data_grad
# 保证对抗样本的像素值在合法范围内
perturbed_data = torch.clamp(perturbed_data, 0, 1)
return perturbed_data
# 示例使用
# 假设有一个模型和数据
model = ... # 神经网络模型
loss_fn = nn.CrossEntropyLoss()
data = ... # 输入数据
target = ... # 真实标签
epsilon = 0.1 # 扰动强度
# 生成对抗样本
adv_data = fgsm_attack(model, loss_fn, data, target, epsilon)
#(PGD)
def pgd_attack(model, loss_fn, data, target, epsilon, alpha, num_iter):
# 初始化对抗样本为原始输入
perturbed_data = data.clone().detach()
for i in range(num_iter):
perturbed_data.requires_grad = True
# 前向传播获取模型输出
output = model(perturbed_data)
# 计算损失
loss = loss_fn(output, target)
# 反向传播计算输入的梯度
model.zero_grad()
loss.backward()
# 计算梯度的符号并更新对抗样本
data_grad = perturbed_data.grad.data
perturbed_data = perturbed_data + alpha * data_grad.sign()
# 投影步骤,确保对抗样本不超出合法范围
perturbation = torch.clamp(perturbed_data - data, -epsilon, epsilon)
perturbed_data = torch.clamp(data + perturbation, 0, 1).detach()
return perturbed_data
Dropout
- 随机忽略数据中的某些特征或部分信息,以提高模型的鲁棒性。
相关性分析
对于大数据样本,在处理完数据(异常值)后,较为常用的一个步骤便是对数据做相关性分析。皮尔逊系数和斯皮尔曼系数便是两个最常用的指标。我们首先来看如何判断数据是否属于正态分布:
正态分布判断
判断数据是否服从正态分布可以通过统计检验和图形分析两种方式。
统计检验方式
Shapiro-Wilk检验
该检验用于检验样本是否来自正态分布。其零假设是样本来自正态分布,p值越小(通常小于0.05),则拒绝零假设(概率论与数理统计内容),说明数据不符合正态分布。
from scipy import stats
# 生成数据示例(正态分布)
data = stats.norm.rvs(size=1000, loc=0, scale=1) # 生成正态分布数据
# 进行Shapiro-Wilk检验
shapiro_test = stats.shapiro(data)
print(f"Shapiro-Wilk test statistic: {shapiro_test[0]}")
print(f"p-value: {shapiro_test[1]}")
if shapiro_test[1] > 0.05:
print("样本可能符合正态分布")
else:
print("样本可能不符合正态分布")
Kolmogorov-Smirnov检验
该检验用于比较样本分布与参考分布(如正态分布)之间的差异。零假设是样本分布与参考分布一致,如果p值小于0.05,表示拒绝零假设,说明样本不符合正态分布。
from scipy import stats
# 生成数据示例(正态分布)
data = stats.norm.rvs(size=1000, loc=0, scale=1) # 生成正态分布数据
# 进行Kolmogorov-Smirnov检验(与标准正态分布进行比较)
ks_test = stats.kstest(data, 'norm')
print(f"Kolmogorov-Smirnov test statistic: {ks_test[0]}")
print(f"p-value: {ks_test[1]}")
if ks_test[1] > 0.05:
print("样本可能符合正态分布")
else:
print("样本可能不符合正态分布")
图形分析方式
Q-Q图(Quantile-Quantile Plot)
通过绘制理论分位数与样本分位数的对比,观察数据是否沿着45度直线分布。如果点大致沿直线分布,则说明数据可能符合正态分布。
import matplotlib.pyplot as plt
import scipy.stats as stats
# 生成数据示例(正态分布)
data = stats.norm.rvs(size=1000, loc=0, scale=1)
# 绘制Q-Q图
stats.probplot(data, dist="norm", plot=plt)
plt.show()
皮尔逊系数
概念:
皮尔逊系数(通常用 r 表示)衡量的是线性相关性,它描述了两个变量是否具有线性关系。其值介于 -1 和 1 之间:
- r=1:完全正线性相关,说明一个变量增大时,另一个变量也成比例增大。
- r=−1:完全负线性相关,说明一个变量增大时,另一个变量成比例减小。
- r=0:无线性相关,说明两个变量之间没有明显的线性关系。
计算公式:
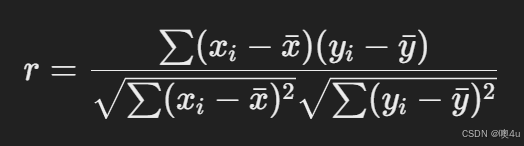
其中:
- xi,yi是样本数据的观测值。
- xˉ,yˉ 是样本数据的均值。
适用场景:
- 数据满足正态分布,且关注的是两个变量之间的线性关系。
import numpy as np
from scipy.stats import pearsonr
# 生成两个变量的数据
x = np.random.rand(100)
y = np.random.rand(100)
# 计算皮尔逊相关系数
corr, p_value = pearsonr(x, y)
print(f"Pearson correlation coefficient: {corr}")
print(f"p-value: {p_value}")
斯皮尔曼系数
概念:
斯皮尔曼系数(通常用 ρ 表示)是一种基于秩(rank)的相关系数,用于衡量两个变量的单调关系(即当一个变量增大时,另一个变量要么总是增大,要么总是减小)。斯皮尔曼系数适用于非线性数据,并且不要求数据服从特定分布。其取值范围与皮尔逊系数相同,也是介于 -1 和 1 之间。
- ρ=1:完全正单调相关。
- ρ=−1:完全负单调相关。
- ρ=0:无单调相关。
斯皮尔曼系数是通过将原始数据转换为秩数据(对每个变量的值进行排序),然后计算这些秩的皮尔逊相关系数来确定的。
计算公式:
斯皮尔曼系数的简化公式如下:
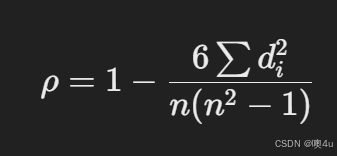
其中:
- di 是两个变量对应数据点的秩之差。
- n 是数据点的数量。
斯皮尔曼系数用于非参数数据分析,因为它不假设数据满足特定的分布,并且更适合非线性关系的情况。
适用场景:
- 数据不满足正态分布,或者关心的是变量之间的单调关系而非线性关系。
from scipy.stats import spearmanr
# 生成两个变量的数据
x = np.random.rand(100)
y = np.random.rand(100)
# 计算斯皮尔曼相关系数
corr, p_value = spearmanr(x, y)
print(f"Spearman correlation coefficient: {corr}")
print(f"p-value: {p_value}")
实战
数据表格形式
题源自2024年亚太杯中文赛项B题,感兴趣的同学可以去网上搜索完整的题目。

这里,首先对数据进行清洗,检查是否存在异常值
import pandas as pd
import seaborn as sns
sns.set_theme(font="SimHei")
# 读取数据
train_csv = r"文件地址"
test_csv = r"文件地址"
train_data = pd.read_csv(train_csv, encoding="utf8")
test_data = pd.read_csv(test_csv, encoding="utf8")
# 查看数据基本信息(行数、列数、数据类型、非空值数)
print("\n数据基本信息:")
print(train_data.info())
# 查看数据的描述性统计(数值列)
print("\n描述性统计:")
print(train_data.describe())
# 检查缺失值
print("\n缺失值检查:")
print(train_data.isnull().sum())
# 查看每一列的独特值数量
print("\n每列的独特值数量:")
print(train_data.nunique())输出如:
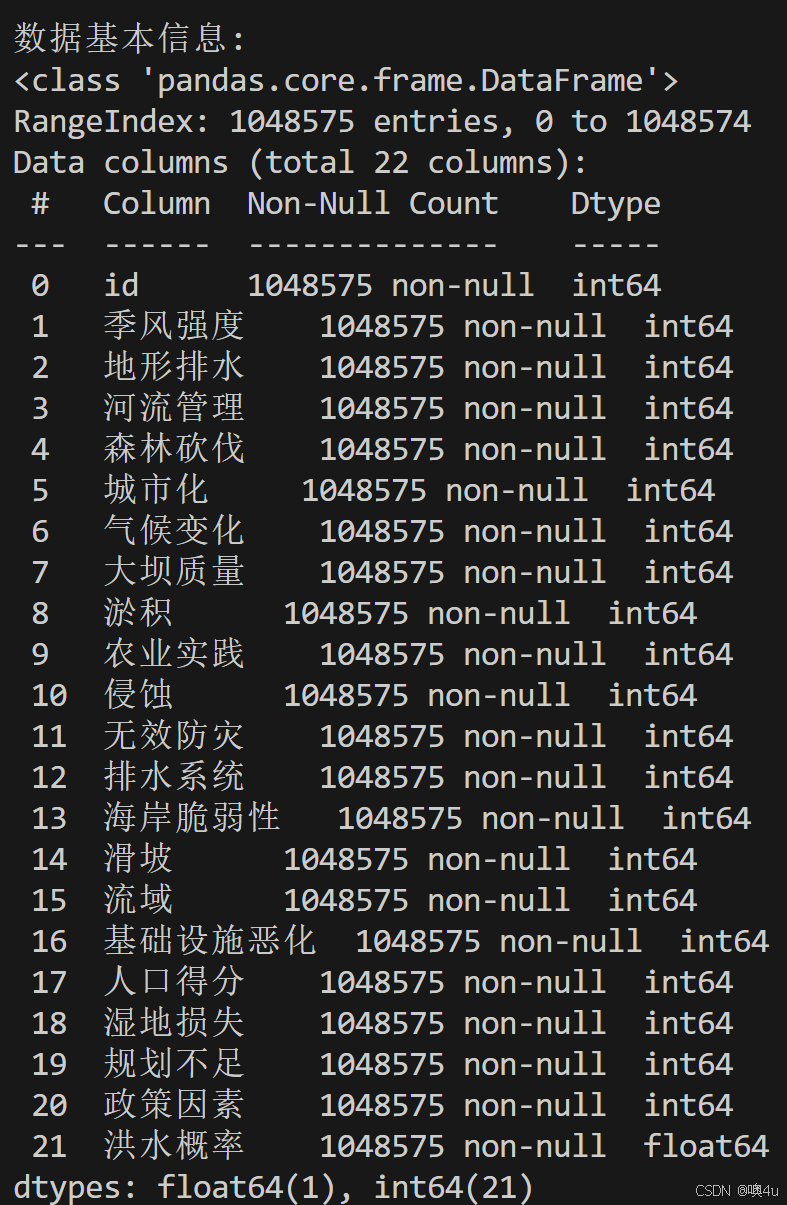
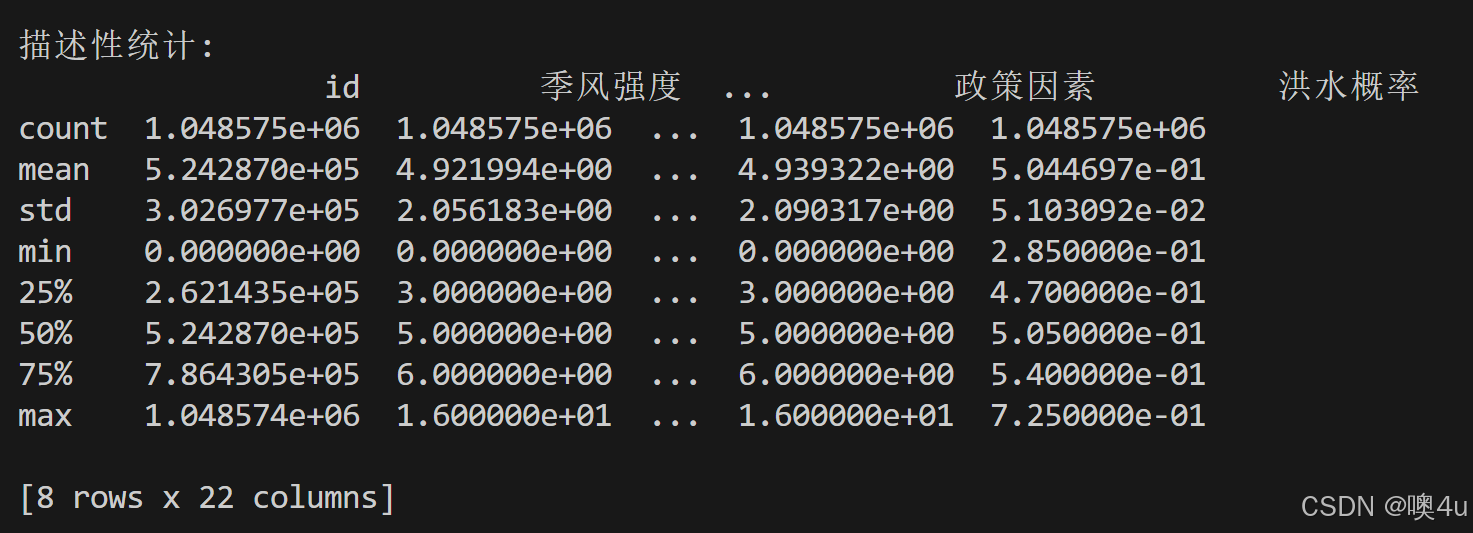
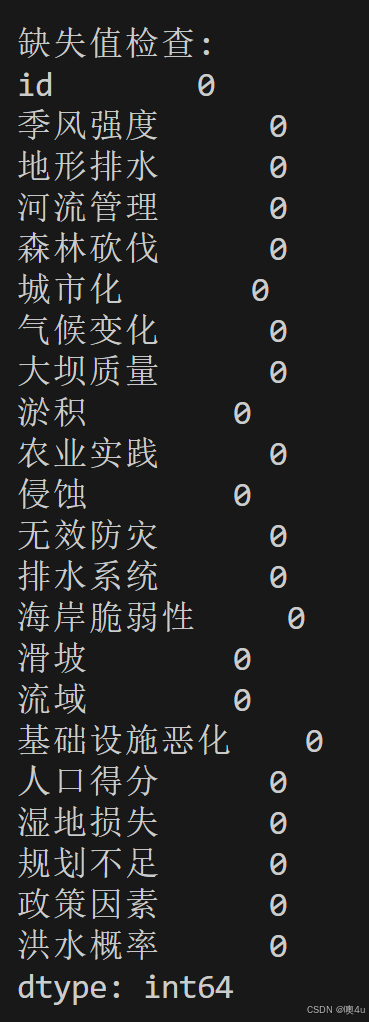
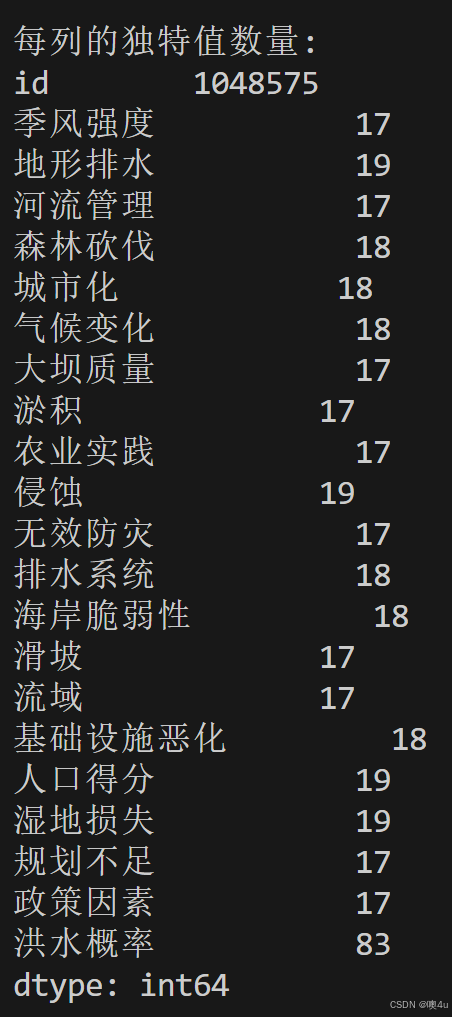
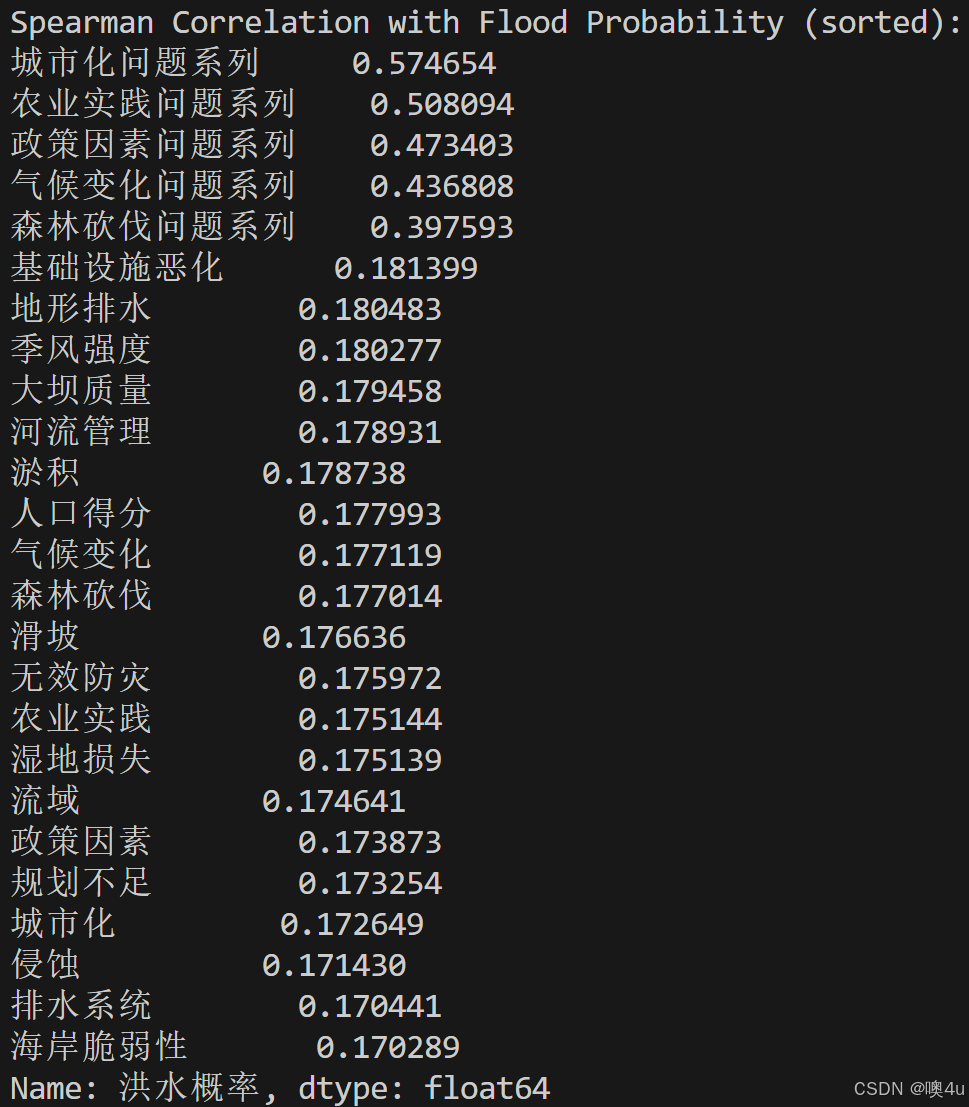
可以得到不存在缺失值和异常值和结论,再进行下一步分析:与“洪水发生概率”列相关性分析。
首先,经过统计检验,得该组数据不符合正态分布,故使用斯皮尔曼系数作为指标。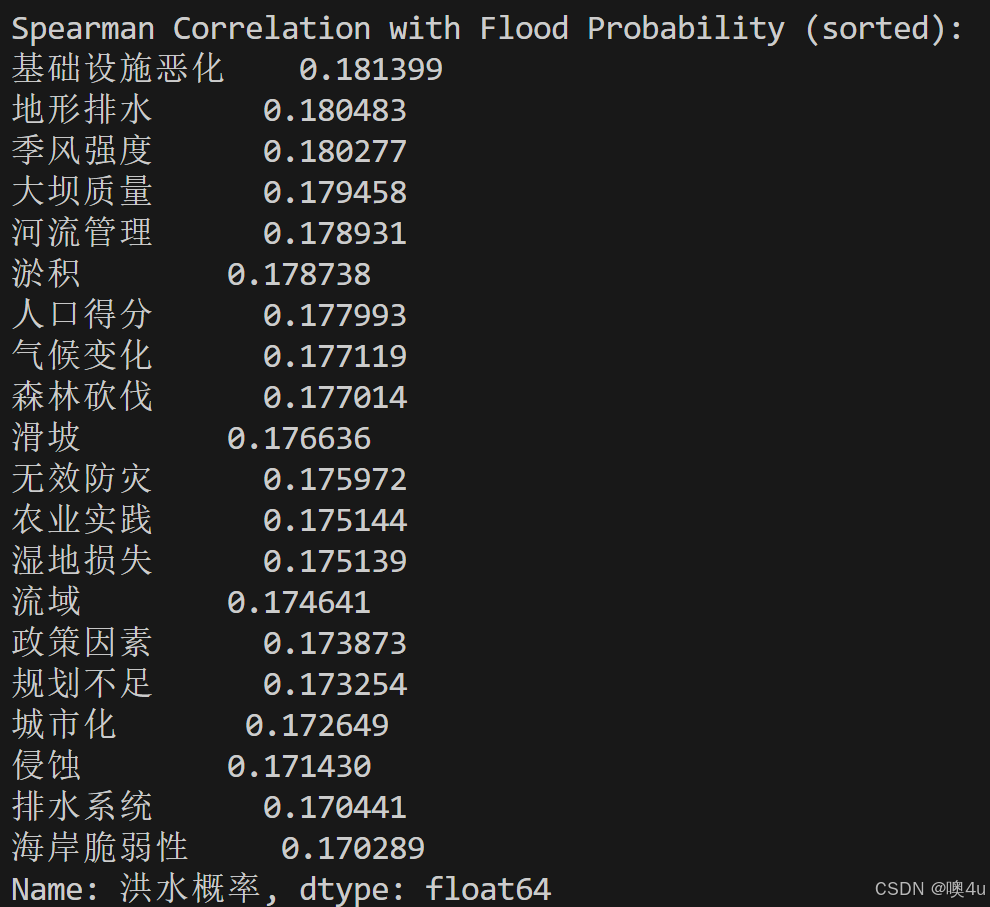
我们可以看到。初步分析得结果,每一项指标与“洪水发生概率”的相关性都很接近且都很小,为了验证这一初步结论是否正确,可以引入OLS线性回归模型检验以下,从下图的数据中,确实能够验证初步结论的合理性。
# ols线性回归模型 计算方差、偏度、峰度,得出所有指标与洪水概率的相关性很接近
import statsmodels.api as sm
import pandas as pd
# 分离目标变量和自变量
train_csv = r"文件路径"
train_data = pd.read_csv(train_csv, encoding="utf8")
X = train_data.drop(columns=["id", "洪水概率"])
y = train_data["洪水概率"]
# 添加常数项,以便在模型中包含截距
X = sm.add_constant(X)
# 构建OLS模型
ols_model = sm.OLS(y, X)
# 拟合模型
results = ols_model.fit()
# 输出模型摘要
print(results.summary())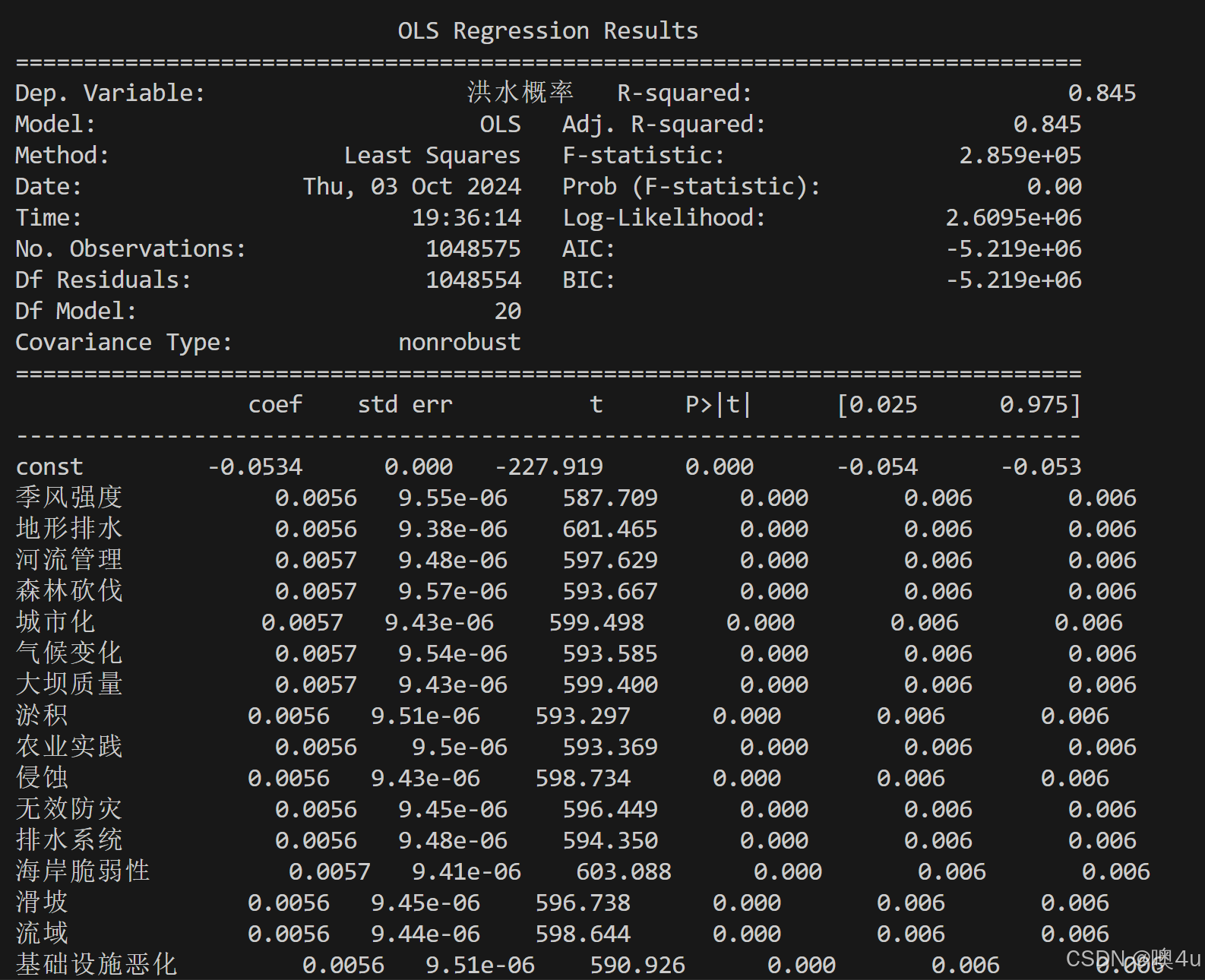 因此进行数据增强的处理,考虑到现实意义中这20个因素中有互成因果关系的组合,便参考文献指定合理的组合,得出如下结果和可视化部分:
因此进行数据增强的处理,考虑到现实意义中这20个因素中有互成因果关系的组合,便参考文献指定合理的组合,得出如下结果和可视化部分:
import matplotlib.pyplot as plt
# 新增组合列
train_data['城市化问题系列'] = (
train_data['城市化'] +
train_data['排水系统'] +
train_data['无效防灾'] +
train_data['农业实践'] +
train_data['气候变化'] +
train_data['湿地损失'] +
train_data['森林砍伐'] +
train_data['规划不足'] +
train_data['人口得分'] +
train_data['政策因素']
)
train_data['气候变化问题系列'] = (
train_data['气候变化'] +
train_data['海岸脆弱性'] +
train_data['季风强度'] +
train_data['湿地损失'] +
train_data['基础设施恶化'] +
train_data['流域']
)
train_data['森林砍伐问题系列'] = (
train_data['森林砍伐'] +
train_data['气候变化'] +
train_data['地形排水'] +
train_data['侵蚀'] +
train_data['淤积']
)
train_data['农业实践问题系列'] = (
train_data['农业实践'] +
train_data['流域'] +
train_data['地形排水'] +
train_data['侵蚀'] +
train_data['淤积'] +
train_data['森林砍伐'] +
train_data['海岸脆弱性'] +
train_data['政策因素']
)
train_data['政策因素问题系列'] = (
train_data['政策因素'] +
train_data['流域'] +
train_data['大坝质量'] +
train_data['海岸脆弱性'] +
train_data['河流管理'] +
train_data['基础设施恶化'] +
train_data['规划不足']
)
# 计算每个指标与洪水概率的斯皮尔曼等级相关系数
spearman_correlations = (
train_data.drop(columns=["id"])
.corr(method="spearman")["洪水概率"]
.drop(["洪水概率"])
)
# 按相关性从高到低排序
spearman_sorted = spearman_correlations.sort_values(ascending=False)
# 打印排序后的结果
print("\nSpearman Correlation with Flood Probability (sorted):")
print(spearman_sorted)
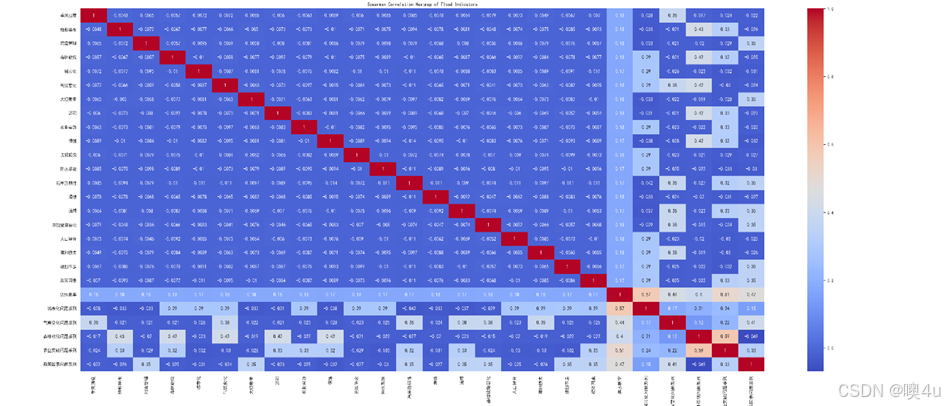
# 绘制斯皮尔曼相关系数的热图
correlation_matrix_spearman = train_data.drop(columns=["id"]).corr(method="spearman")
plt.figure(figsize=(18, 18))
sns.heatmap(correlation_matrix_spearman, annot=True, cmap="coolwarm")
plt.title("Spearman Correlation Heatmap of Flood Indicators")
plt.tight_layout()
plt.show()
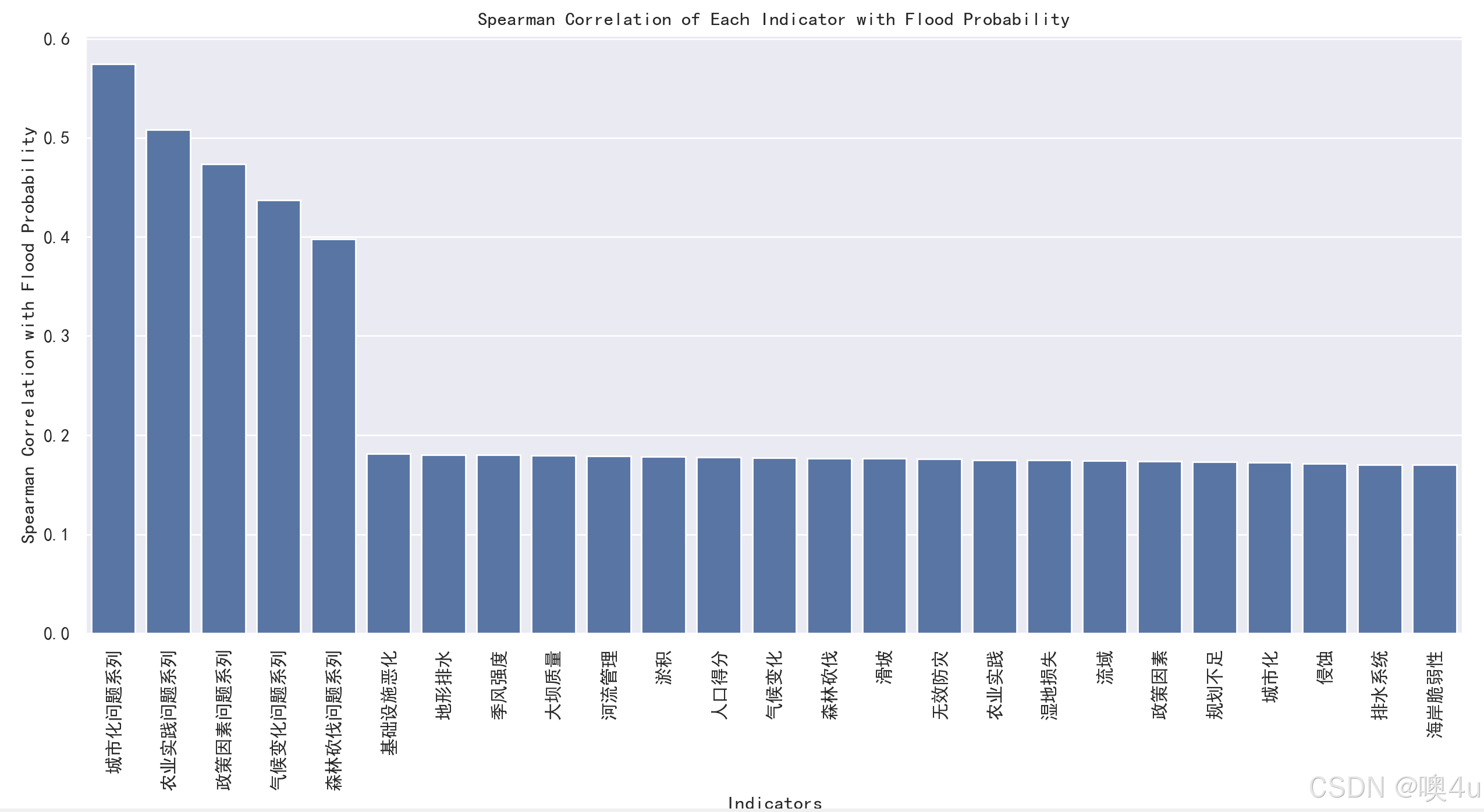
# 绘制斯皮尔曼相关系数的条形图
plt.figure(figsize=(12, 8))
sns.barplot(x=spearman_sorted.index, y=spearman_sorted.values)
plt.xticks(rotation=90) # 旋转x轴标签以防止重叠
plt.xlabel("Indicators")
plt.ylabel("Spearman Correlation with Flood Probability")
plt.title("Spearman Correlation of Each Indicator with Flood Probability")
plt.tight_layout()
plt.show()
# 绘制斯皮尔曼相关系数的散点图
plt.figure(figsize=(12, 8))
plt.scatter(spearman_sorted.index, spearman_sorted.values)
plt.xticks(rotation=90) # 旋转x轴标签以防止重叠
plt.xlabel("Indicators")
plt.ylabel("Spearman Correlation with Flood Probability")
plt.title("Spearman Correlation of Each Indicator with Flood Probability")
plt.tight_layout()
plt.show()结果如下:
图像形式

问题是需要按序识别出这三幅图中的文字内容,我使用的是EasyOCR(会在最后OCR的部分有所涉及),但EasyOCR识别文字是按照文字在坐标中的顺序,即如最左图,会先输出“12319”再输出“报修电话:”(因为12319文本框的纵坐标值再报修电话文本框之上),显然不满足题意,因此需要进行图像预处理。
首先进行旋转,旋转角度由检测到图片中水平线的平均倾斜角度来决定。便有如下代码:
import cv2
import numpy as np
import os
# 获取当前工作目录
current_dir = os.getcwd()
# 获取所有 .jpg 文件
image_files = [f for f in os.listdir(current_dir) if f.endswith('.jpg')]
# 遍历每张图片
for image_file in image_files:
# 读取图像
image_path = os.path.join(current_dir, image_file)
image = cv2.imread(image_path)
# 将图像转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用自适应阈值处理 边缘检测优化
adaptive_thresh = cv2.adaptiveThreshold(gray, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
# 使用Canny边缘检测
edges = cv2.Canny(adaptive_thresh, 100, 200)
# 使用霍夫变换检测直线
lines = cv2.HoughLinesP(edges, 1, np.pi/180, threshold=250, minLineLength=250, maxLineGap=10)
new_lines = []
# 绘制只包含水平方向的直线
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
# 计算直线的斜率,如果斜率接近 0,认为是水平线
if x2 - x1 != 0 and abs(y2 - y1) / (x2 - x1) < 1: # 斜率接近0的情况
# 绘制水平直线,颜色为红色,线条宽度为2
new_lines.append(line)
cv2.line(image, (x1, y1), (x2, y2), (0, 0, 255), 2)
# 计算图像中的倾斜角度
angles = []
for line in new_lines:
x1, y1, x2, y2 = line[0]
angle = np.arctan2(y2 - y1, x2 - x1) * 180 / np.pi
angles.append(angle)
# 取所有检测到直线的平均倾斜角度
if angles:
average_angle = np.mean(angles)
else:
average_angle = 0 # 没有检测到水平直线时,不做旋转
# 旋转图像进行矫正
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, average_angle, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
# 保存旋转后的图像到本地,文件名为 rotated_原图片名.jpg
rotated_image_path = os.path.join(current_dir, f'rotated_{image_file}')
cv2.imwrite(rotated_image_path, rotated)其中,“自适应阈值处理 边缘检测优化”的部分可以看作数据增强,通过对图像的局部区域计算阈值,可以更好地应对光照不均匀的情况。具体的算法在这一篇中不过多涉及,只需知道使用该方法后可以检测到更多直线即可。
总结
数据处理是机器学习中至关重要的一步,确保模型在干净、高质量的数据上进行训练。处理缺失值可以通过删除或填充来完成,重复数据需要识别并移除,异常值则可通过统计方法如IQR或Z分数处理。标准化和归一化有助于数据的尺度统一,格式不一致或拼写错误等需要修正。通过平滑、聚合等方式处理噪声后,还可以进行特征工程,如编码、组合特征或去除冗余特征。数据增强进一步提升模型的泛化能力,如图像的旋转、平移、噪声添加等。

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









