






1.准备一张表
t_sales_info
#创建表
create table if not exists t_sales_info(
customer_id VARCHAR(10),
order_date DATE,
`year` VARCHAR(4),
product_id VARCHAR(10),
product_price DECIMAL(10, 2)
);
-- 插入数据
INSERT INTO t_sales_info (customer_id, order_date, `year`, product_id, product_price)
VALUES
('A', '2023-06-01', '2023', '1', 36.0),
('A', '2023-09-01', '2023', '2', 48.0),
('B', '2023-09-07', '2023', '2', 48.0),
('C', '2023-10-10', '2023', '3', 23.0),
('A', '2023-11-11', '2023', '3', 23.0),
('C', '2023-12-11', '2023', '3', 23.0),
('A', '2024-01-01', '2024', '2', 48.0),
('B', '2024-02-02', '2024', '2', 48.0),
('C', '2024-02-04', '2024', '1', 36.0),
('C', '2024-02-11', '2024', '1', 36.0),
('B', '2024-03-16', '2024', '3', 23.0),
('B', '2024-04-01', '2024', '3', 23.0),
('A', '2024-04-14', '2024', '3', 23.0),
('C', '2024-04-21', '2024', '3', 23.0),
('B', '2024-05-07', '2024', '3', 23.0);
#检测一下数据
select * from t_sales_info;
2.常用聚合函数
- 平均数:avg()
- 计数:count()
- 最大值:max()
- 最小值:min()
- 标准差:stddev()
- 求和:sum()
-
3.常用窗口函数
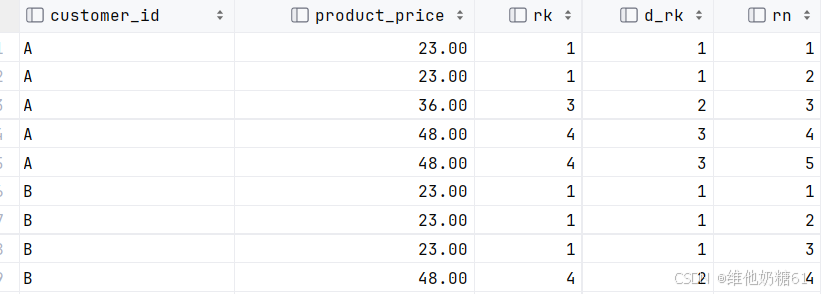
- CUME_DIST():函数会计算当前行及之前所有行的数量占该分区总行数的比例
- RANK() :会跳过重复值
DENSE_RANK() :不会跳过重复值序号
ROW_NUMBER() :不包含重复值, 相同名次按顺序排列; 排名值是将当前行之前的行数加1
SELECT customer_id, product_price
, RANK() OVER(PARTITION BY customer_id ORDER BY product_price) AS rk
, DENSE_RANK() OVER(PARTITION BY customer_id ORDER BY product_price) AS d_rk
, ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY product_price) AS r_n
FROM t_sales_info ;
4.分区表,分桶表,内部表,外部表
(1)分区表(Partitioned Table)
定义:按某一列或多列的值将数据划分为多个分区,每个分区存储在不同的目录中。
优点:
查询优化:查询时只扫描相关分区,减少数据读取量。
管理方便:可单独对某个分区进行备份、删除等操作。
适用场景:适合有明显时间、地域等划分特征的数据,如按日期、地区分区。
CREATE TABLE sales (
id INT,
date STRING,
amount DOUBLE
) PARTITIONED BY (date);
(2)分桶表(Bucketed Table)
定义:根据某列的哈希值将数据分散到固定数量的桶中,每个桶存储为一个文件。
优点:
数据均匀分布:哈希算法确保数据均匀分布,避免倾斜。
优化连接和聚合:相同列分桶的表在连接和聚合时效率更高。
适用场景:适合需要频繁连接或聚合操作的场景,如用户ID、订单ID等。
主要区别
划分方式:分区表按列值划分,分桶表按哈希值划分。
存储结构:分区表每个分区一个目录,分桶表每个桶一个文件。
适用场景:分区表适合有明显划分特征的数据,分桶表适合需要高效连接和聚合的场景。
CREATE TABLE user_orders (
user_id INT,
order_id INT,
order_date STRING
) CLUSTERED BY (user_id) INTO 10 BUCKETS;
(3)内部表(Managed Table)
定义:内部表由 Hive 完全管理,包括数据的存储和元数据的管理。
数据存储:数据存储在 Hive 的默认路径(通常是 HDFS 上的 /user/hive/warehouse)。
生命周期:创建表时,Hive 会自动管理数据的存储位置。
删除表时,数据和元数据都会被删除。
适用场景:适合临时数据或不需要长期保留的数据。
CREATE TABLE managed_table (
id INT,
name STRING
);
(4)外部表(External Table)
定义:外部表的数据存储位置由用户指定,Hive 只管理元数据。
数据存储:数据存储在用户指定的路径(如 HDFS 上的自定义目录)。
生命周期:
创建表时,需要指定数据的位置。
删除表时,只删除元数据,数据不会被删除。
适用场景:适合需要长期保留的数据,或者数据由其他系统(如 Spark、Flink)生成和管理。
CREATE EXTERNAL TABLE external_table (
id INT,
name STRING
)
LOCATION '/path/to/external/data';
5.多表关联查询
(1)内连接:inner join...on
定义:只返回两个表中 匹配的记录。
行为:
如果左表的某条记录在右表中没有匹配,则该记录不会出现在结果中。
如果右表的某条记录在左表中没有匹配,则该记录也不会出现在结果中。
适用场景:当只需要查询两个表中完全匹配的数据时使用。
SELECT
o.order_id,
o.order_amount,
c.customer_name
FROM
orders o
INNER JOIN
customers c
ON
o.customer_id = c.customer_id;(2)左连接:left jion ...on
定义:返回 左表的所有记录,以及右表中 匹配的记录。如果右表中没有匹配的记录,则返回 NULL。
行为:
左表的每一条记录都会出现在结果中。
如果右表中没有匹配的记录,则右表的字段值为 NULL。
适用场景:当需要查询左表的所有记录,即使右表中没有匹配的数据时使用。
- 右连接:right join...on
定义:返回 右表的所有记录,以及左表中 匹配的记录。如果左表中没有匹配的记录,则返回 NULL。
行为:
右表的每一条记录都会出现在结果中。
如果左表中没有匹配的记录,则左表的字段值为 NULL。
适用场景:当需要查询右表的所有记录,即使左表中没有匹配的数据时使用。
- 全连接:full join...on
定义:返回左表和右表的所有记录。如果某一边没有匹配的记录,则返回 NULL。
行为:
左表和右表的所有记录都会出现在结果中。
如果某一边没有匹配的记录,则对应字段为 NULL。

















 2338
2338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









