






目录
大模型如果用bfloat16需要特别大的显存,所以都在用INT4、INT8做量化,效果不错
量化学习
为什么量化

对Llama13B模型来说,不同算子加载需要的显存不同
中间是TensorCore,左右两边是显存,加载过程中模型要频繁地将weight和激活值从显存加载到TensorCore,计算完后,又将结果放回到显存中
在大模型推理中,制约推理速度的关键因素是显存带宽,量化数据可以减小数据交换所用的时间
对称量化

INT8是-128~127,为了方便,丢掉-128
为了最大程度的保留精度,要尽可能把-127~127占满
首先找到绝对值最大的数:2.11,将它映射到最大的整数127,从而得到了一个缩放比例:2.11/127,从而其他数都按照这个比例缩放,然后取整

反量化时也按照缩放比例进行缩放
但是,这种量化方法并没有占满左边的整数,因此引入非对称量化
非对称量化

不映射到-128~127了,改成0~255
缩放比例为:
我们还需要计算一个 ,它的作用是对缩放取整后的变量进行平移,从而保证每个变量都在0~255之间
,它的作用是对缩放取整后的变量进行平移,从而保证每个变量都在0~255之间
再经过一个clamp操作 ,确保缩放平移后的变量都在0~255之间
,确保缩放平移后的变量都在0~255之间
反量化过程则为量化值减去zero_point乘上scale
量化后的数据计算

对Xf和Wf进行对称量化

对Xf和Wf进行非对称量化
量化异常值

这种情况下,即使使用非对称量化,仍然有很大一部分整数被浪费,同时,很多值被量化为同一整数
有很多工作可以解决这些问题,例如:用直方图描述数据分布、逐步舍弃一些异常值、计算量化前和量化后数据的均方误差或KL散度,找到合适的取值范围、单独对异常值进行量化、对channel量化、对group量化等
神经网络量化

训练后动态量化(pytorch)


在pytorch中,使用quantize_dynamic方法,输入模型、需要量化的层、量化类型就可以量化了
可以看到torch.qint8中,量化使用的参数是和量化后数值存放在一起的,方便随时进行反量化
为什么qint8中的值不是整数?因为输出的是qint8反量化后的值,要打印整数值需要用torch.int)repr函数
存在的问题:(1)每一次推理每一层都要对输入统计量化参数,耗时(2)每一层计算完都转化为fp32,存入显存,占用显存带宽
训练后静态量化(pytorch)
(1)动态量化之所以只量化参数,不量化输入,是因为输入总是会变的。针对这个问题的解决方法是:用有代表性的输入数据跑一遍整个网络,认为这些输入就代表了真实推理时的输入,通过统计得到每层大概的量化参数
(2)动态量化每次计算完都要转成fp32,解决方法是:这一层的输出是下一层的输入。下一层还是要量化,不如在这一层直接量化好再传给下一层


左边在量化输入,右边在量化权重(放在train之后)
(1)定义一个QuantStub量化占位符和一个DeQuantStub反量化占位符,并在forward部分调用
(2)为模型设置一个适合在x86架构下运行的量化配置,prepare生成带量化的模型
(3)用有代表性的数据对模型各层激活值的量化参数进行校准,这里直接前向传播就行
(4)convert转换成int8的量化模型
量化感知训练
对训练好的模型,无论怎么量化,总是会有误差。减少误差不正是神经网络擅长的吗?是否有一种通过模型训练的办法来减少误差?
在网络训练过程中,模拟量化,让模型在训练过程中就能调整参数,让它更适合量化,提高量化后模型的精度


prepare函数变成了prepare_qat,QAT就是Quantization-aware-training
大模型量化

黄色的是传统量化方法,蓝色的8bit是hf transformers中默认的LLM.int8()方法,绿色的是float
16
为什么参数量到一定量级后,传统方法失效?这是由Emergent Features引起的。Emergent Features是指在一些层的模型输出的特征里,有些特征突然变大,是其他特征的几十倍

对大模型而言,它有很多Emergent Features,这些大的特征代表大模型在学习过程中学到的重要特征。可以看到,因为这些特别大的异常值,导致其他某些特征量化+反量化后的值变为同一个了
LLM.int8()将这些Emergent Features单独处理,再汇总结果

对于矩阵乘法,可以把行和列拆出来分别运算,再加起来

在LLM.int8()中,取大于6的为异常值,发现异常列的占比不到0.1%

对输入按行进行量化,对权重按列进行量化,对Emergent Features用fp16计算
使用LLM.int8()对精度几乎没有影响,但模型推理速度会变慢20%左右
transformers调用

QLoRA
上面讲的量化方法都是线性的
对于神经网络,一般参数值都是符合均值为零的正态分布的,也就是零附近的参数会很多,但是极大极小值很少。如果我们均匀分配本来就不多的量化后的整数值,就有点浪费,我们能不能在原始浮点型数值密集的地方多分配一些量化后的整数值,密度小的地方少分配点,这样就能减小量化带来的误差
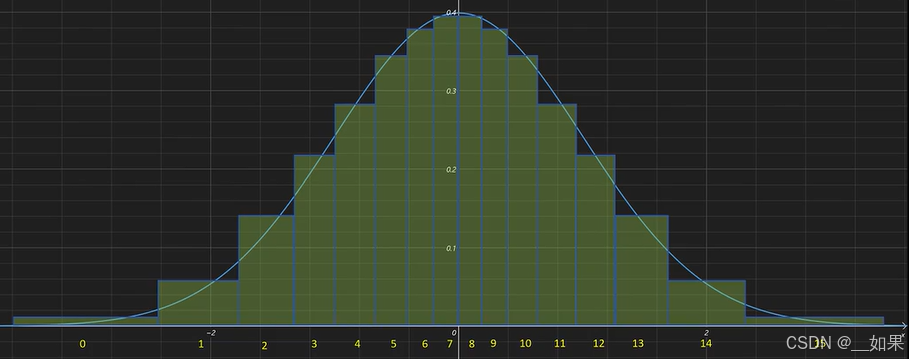
基于这样的思想,我们把一个正态分布,根据累积概率密度分为16个区域(4bit量化后有16个整数)
如何量化呢?
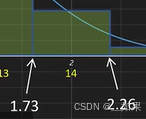
比如对于区域14,我们可以求出区域的起始点和终点对应x值,如果x在1.73~2.26之间,则量化为14,对于反量化,则取区域的平均值(1.73+2.26)/2=1.995
但这样就有两个问题:
(1)对于正态分布两侧的区间,求不出均值,无法反量化
解决方案:截断,QLoRA中对两边都各自舍弃了累积概率密度0.0322917
(2)0无法被反量化为0
解决方案:0单独分配一个区间,剩下15个区间,正区间8个负区间7个,得到所有的x后除以它们最大的绝对值,归一化,得到下面这张表,这就是NF4(NormalFloat4)
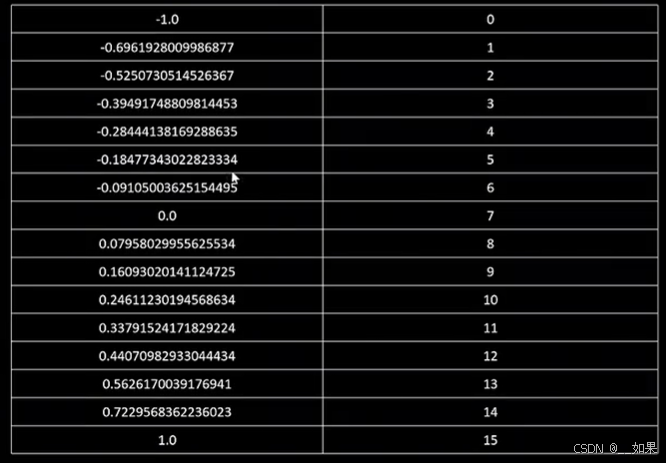
NF4并不是用来计算的,而是专门对符合正态分布的数据进行量化用的,计算时要反量化成浮点型
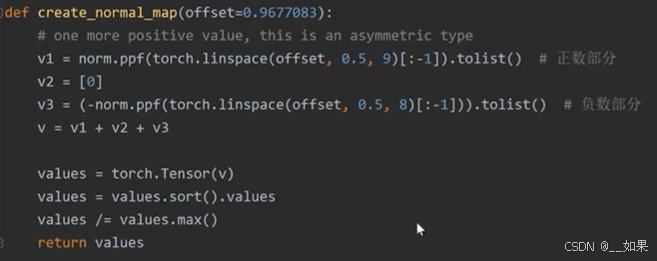
offset是截断的累积概率密度,0.5是因为x=0时的累积概率为0.5
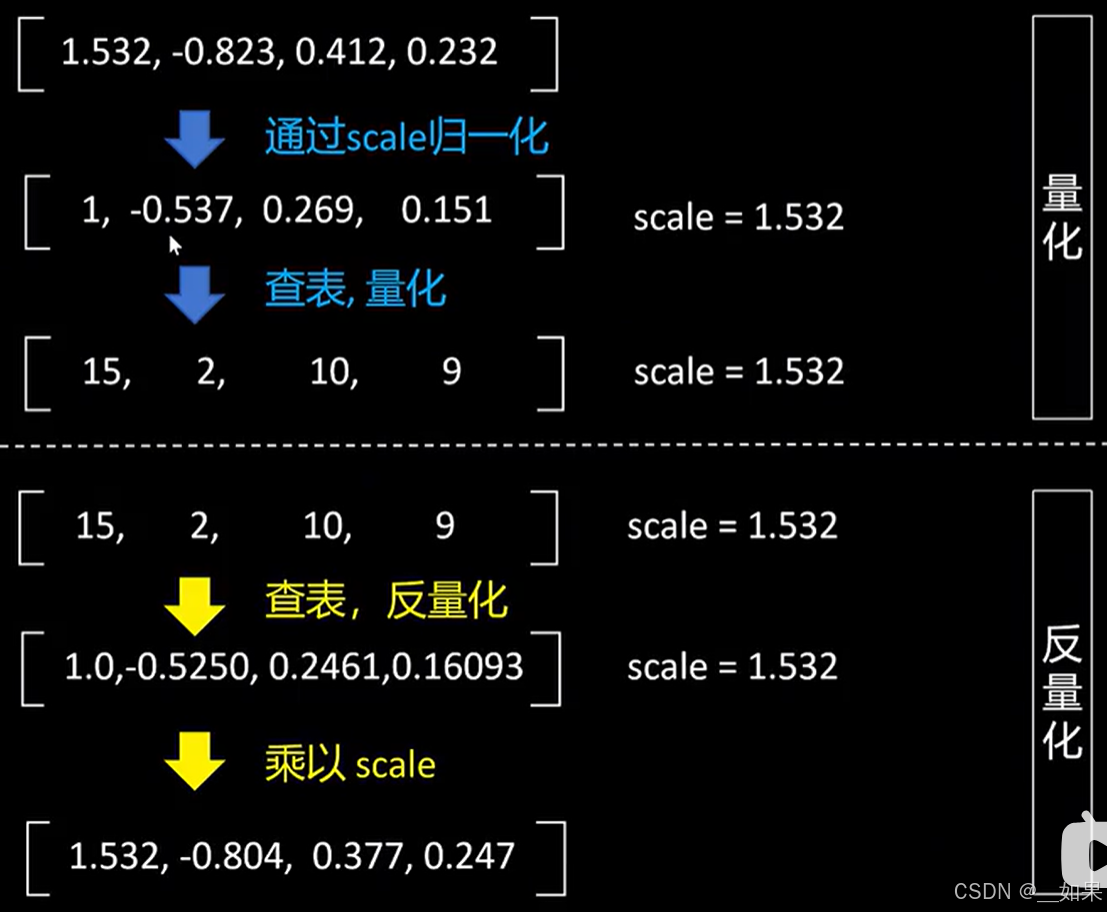
分块量化
QLoRA里每64个值作为一个块进行NF4 4-bit 量化,64x4bit=256bit,但是由于我们要存储的scale是32bit的浮点数,这造成了32/256=12.5%的额外显存占用

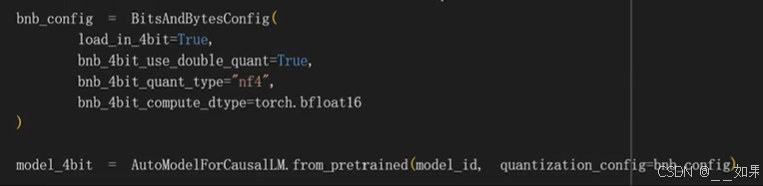
因此这里的参数为4bit量化、双重量化、量化类型NF4、计算类型bf16
Transformers

使用bitsanbytes库
在transformers源码中的modeling_utils文件中有一个replace_with_bnb_linear方法用于替换算子
以Llama为例,MLP有三个线性层,Attn有四个线性层


大部分的算子都是线性层

替换掉的是线性层和1D卷积
大模型量化部署

GPTQ
GPTQ 对某个 block(分块量化) 内的所有参数逐个量化,每个参数量化后,需要适当调整这个block 内其他未量化的参数,以弥补量化造成的精度损失。所以GPTQ 量化需要准备校准数据集

Hessian矩阵会用于后面逐层量化过程中的损失和补偿计算
AWQ
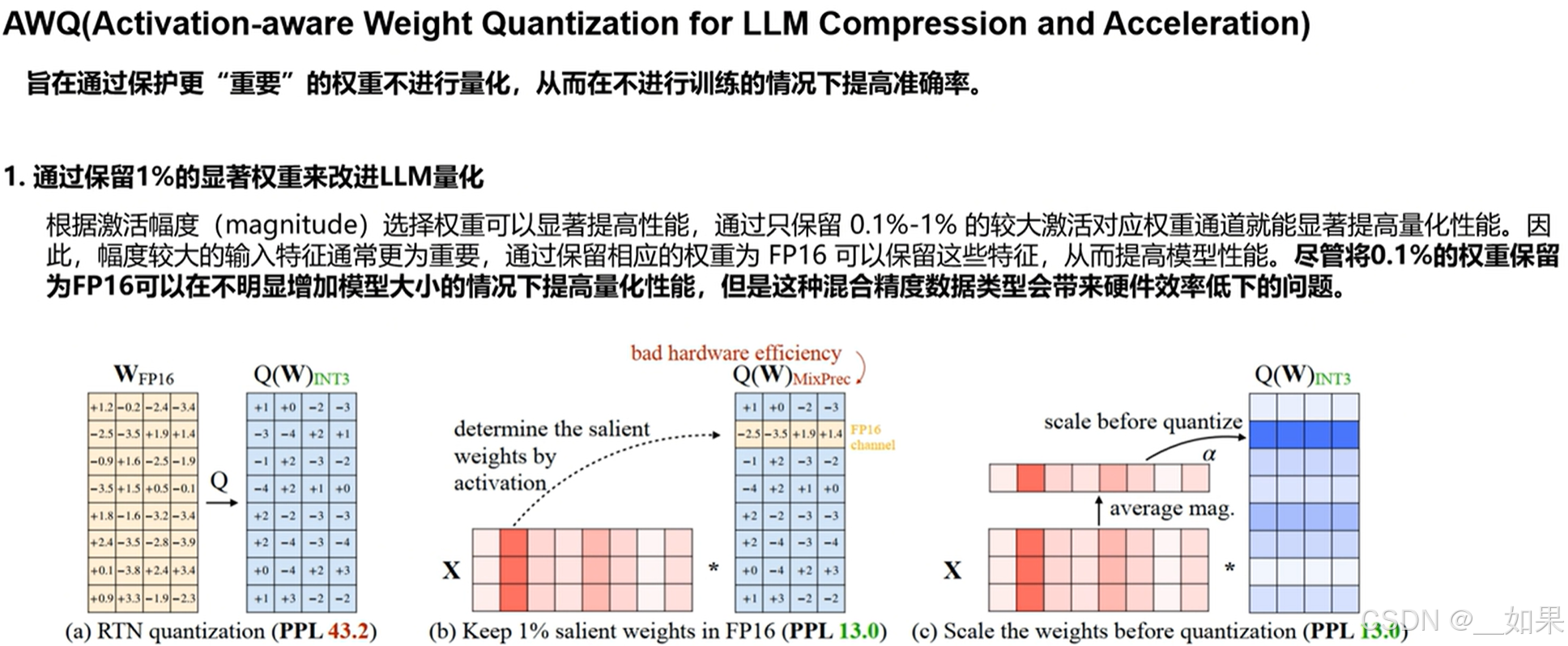
和LLM.int8()不同的是:LLM.int8()是分离出离群值,而AWQ是找出显著权重
论文对比了3种选择方法:基于激活act分布、基于权重W分布、随机。
实验结果显示:基于激活act分布的方法最好,相当于较大激活幅度对应的权重更重要。
AWQ思路是对关键权重先乘一个方法系数再量化进行一个保护。首先,识别关键权重的方法是分析Activation分布,个人理解:通过校验数据集找到没被激活抑制的权重所在位置,这些位置(也就是激活值大的位置)对于最终输出的影响更大 所以是显著权重。

论文通过最小化layer量化前后的差值来在搜索空间寻找最优的 scaling(网格搜索)
不同于 GPTQ 方法计算线性层使用matrix-vectOr(MV)乘法,AWO方法使用matrix-matix(MM)乘法,MV 只能在慢的 cuda 内核上执行,而MM可以在A100和H100上的16倍更快的张量核上执行
与Flash Attention结合起来,得到一个既被量化又更快速的模型
transformers:
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = 'mistralai/Mistral-7B-Instruct-v0.2'
quant_path = 'mistral-instruct-v0.2-awq'
quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM" }
# Load model
model = AutoAWQForCausalLM.from_pretrained(
model_path, **{"low_cpu_mem_usage": True, "use_cache": False}
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
print(f'Model is quantized and saved at "{quant_path}"')运行:
python examples/llm_engine_example.py --model TheBloke/Llama-2-7b-Chat-AWQ --quantization awq大模型:
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="TheBloke/Llama-2-7b-Chat-AWQ", quantization="AWQ")
# Generate texts from the prompts. The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")Llama.cpp

Llama.cpp gguf量化级别:不同量化变体其实就是采用了不同的量化方案来处理 attention.wv、attention.wo 和 feed forward.w2 张量

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









