




目录
一、SVM
1.1 概述
支持向量机(Support Vector Machine,简称SVM)是一种经典的机器学习算法,它在解决小样本、非线性及高维模式识别等问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
是一种二分类模型,监督性学习。目的是找到集合边缘上的若干数据(支持向量)用这些点找出一个平面(决策面)使支持向量到该平面的距离最大。
1.2 四种分隔的情况
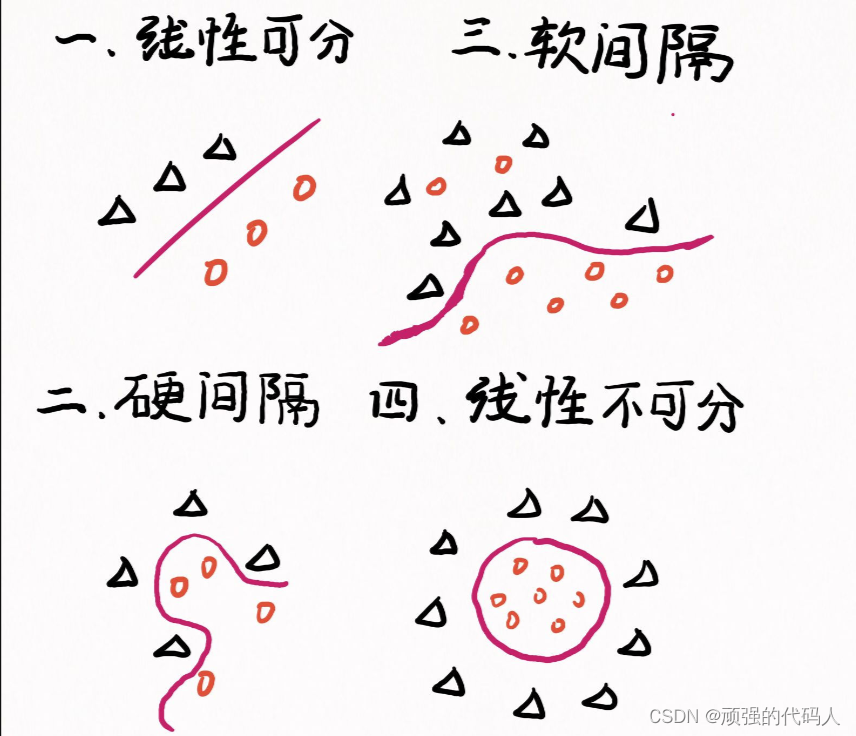
此外,我们将详细介绍一些线性可分的情况
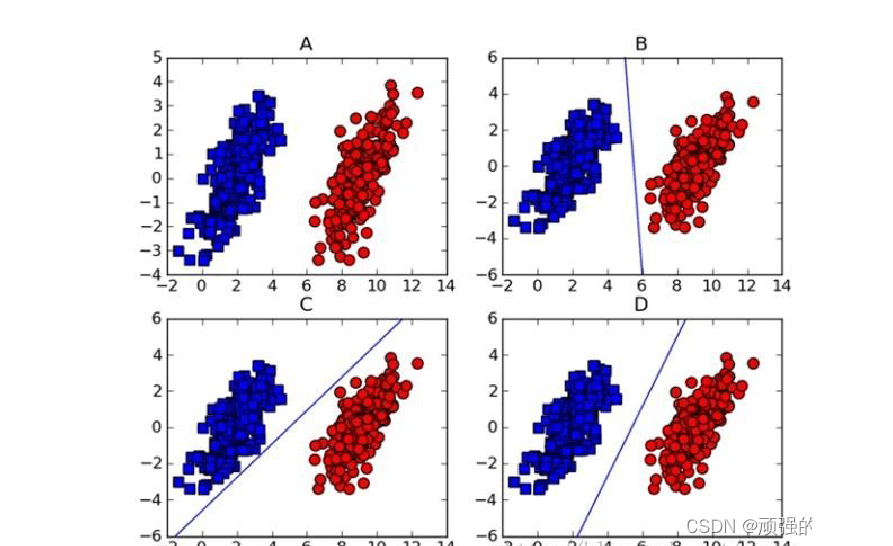
如上图所示,在图A中的两组数据已经分的足够开,因此很容易就可以画一条直线将两组数据点分开。
这种情况下,这组数据就被称为线性可分数据。
将数据集分开的直线称为分割超平面。当数据点都在二维平面上时,分割超平面只是一条直线。当数据集是三维时就是一个平面。如果数据集是N维的,那么就需要N-1维的某某对象对数据进行分割。该对象就被称为超平面也是分类的决策边界。
根据这种方法我们构造一个分类器,如果数据点离决策边界越远,那么其最后的预测结果也就越可信
点到分割线的距离称为间隔
而支持向量就是离分隔超平面最近的那些点。
1.3 最大间隔与分类
什么样的决策边界才是最好的呢?
首先我们引入
超平面方程:
对于线性可分的数据集来说,超平面有许多个,但几何间隔最大的分离超平面是唯一的。
① 两类样本分别分割在超平面的两侧
② 两侧距离超平面最近的样本点到超平面的距离被最大化
点
到直线
距离为
其中
支持向量(正、负)之差为
则最大间隔转化为求其最大值
即
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









