






Llama 3 近期重磅发布,发布了 8B 和 70B 参数量的模型,XTuner 团队对 Llama 3 微调进行了光速支持!!!同时开源社区中涌现了 Llama3-XTuner-CN 手把手教大家使用 XTuner 微调 Llama 3 模型。
XTuner:
http://github.com/InternLM/XTuner
(文明点击阅读原文可直达)
Llama3-XTuner-CN:
https://github.com/SmartFlowAI/Llama3-XTuner-CN/
Llama 3 概览
首先我们来回顾一下 Llama 3 亮点概览~
- 首次出现 8B 模型,且 8B 模型与 70B模型全系列使用 GQA (Group Query Attention)。
- 最大模型达到 400B 规模大小,未来几个月内发布!
- 分词器由 SentencePiece 换为了 Tiktoken,与 GPT4 保持一致。
- 相比于 Llama2 的 32000 词表大小,Llama3 的词表大小来到了惊人的 128256。
- 数据方面上,Llama3 使用了约 15T token 用于模型的训练。
- 开源模型大小为 8B 和 70B 两种,每种规模均有开源基座模型和 instruct 模型。
- Llama3 8B Instruct 模型在数学与代码能力方面数倍于 Llama2 7B chat 模型。
2*A100 即可全量微调
8K 上下文 Llama3 8B
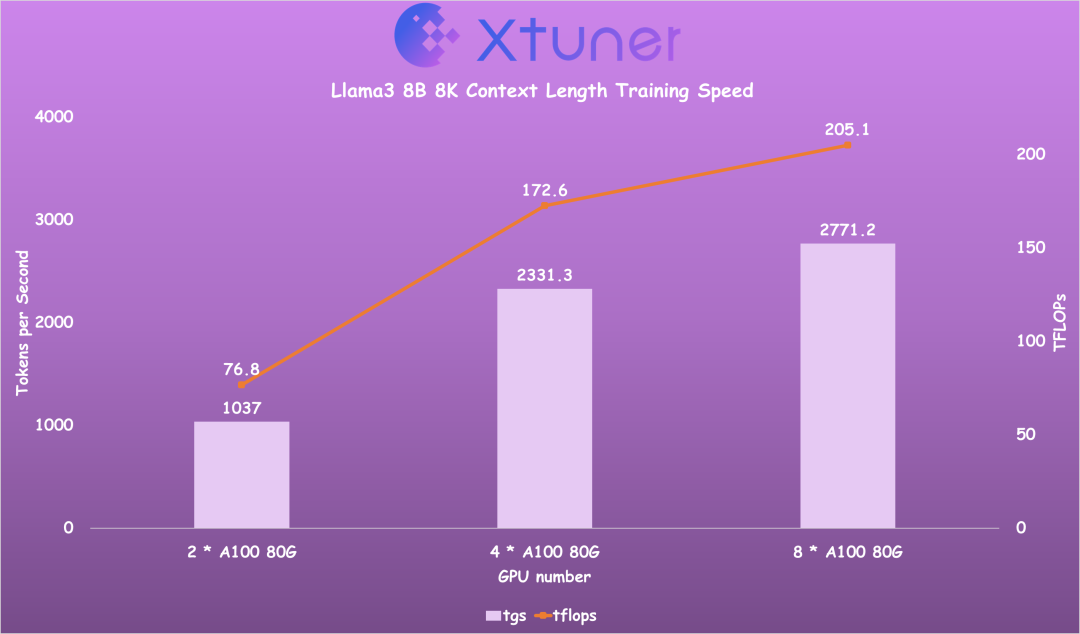
在正式实战之前我们先看一下 XTuner 团队对 Llama 3 8B 的性能测试结果,XTuner 团队在 Llama 3 发布之后光速进行了支持并进行了测速,以下使用不同数量 GPU 全量微调 Llama3 8B 时的训练效率,仅需 2 * A100 80G 即可全量微调 8k 上下文 Llama3 8B。
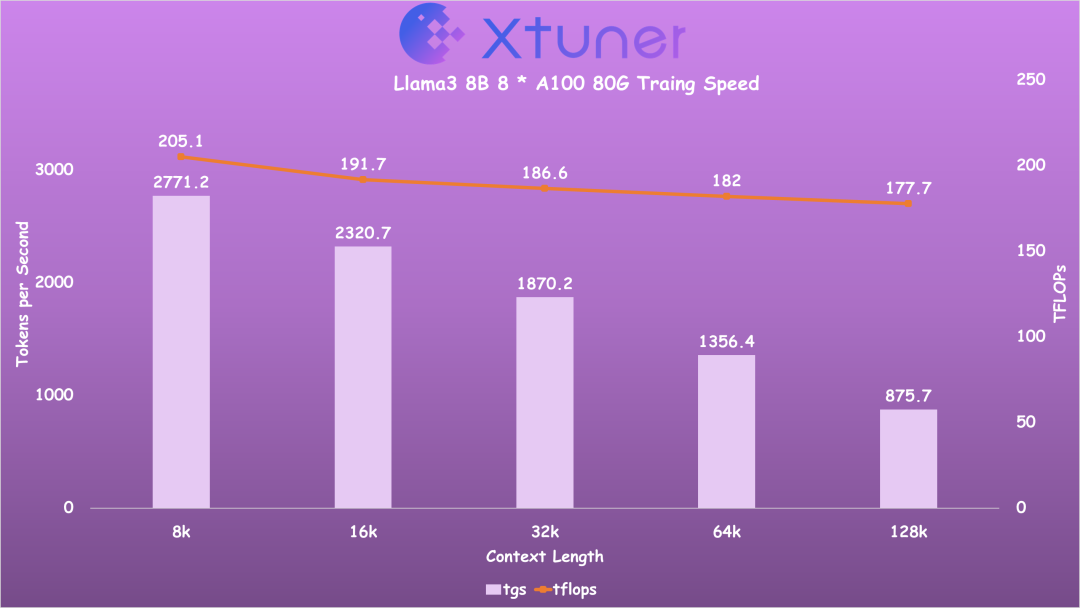
使用 8 * A100 80G 全量微调不同上下文长度的 Llama3 8B 时的训练效率。
实践教程
Web Demo 部署
本小节将带大家手把手在 InternStudio 部署 Llama3 Web Demo。

环境配置
conda create -n llama3 python=3.10conda activate llama3conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
conda install gitgit-lfs install
下载 Llama3 模型
首先通过 OpenXLab 下载 Llama-3-8B-Instruct 这个模型。
mkdir -p ~/modelcd ~/modelgit clone https://code.openxlab.org.cn/MrCat/Llama-3-8B-Instruct.git Meta-Llama-3-8B-Instruct
或者软链接 InternStudio 中的模型。
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct \ ~/model/Meta-Llama-3-8B-Instruct
安装 XTuner
cd ~git clone -b v0.1.18 https://github.com/InternLM/XTunercd XTunerpip install -e .
运行 web_demo.py
**
**
streamlit run ~/Llama3-XTuner-CN/tools/internstudio_web_demo.py \ /root/model/Llama-3-8B-Instruct
通过此命令我们就成功本地运行 Llama3 的 Web Demo 了可以愉快的和它对话了,此时问“你是”,模型的自我认识是 Llama。
XTuner 微调 Llama 3 个人小助手认知
在本节我们尝试让 Llama3 有"它是SmartFlowAI打造的人工智能助手"的自我认知,最终效果图如下所示:

自我认知训练数据集准备
首先我们通过以下脚本制作自我认知的数据集。
cd ~/Llama3-XTuner-CNpython tools/gdata.py
数据生成脚本 gdata.py 如下所示,实现了产生 2000 条自我认知的数据的功能,在正式环境中我们需要对各种数据进行配比,为了社区同学们能够快速上手,本例子就采用了过拟合的方式。
import json
# 输入你的名字或者机构name = 'SmartFlowAI'# 重复次数n = 2000
data = [ { "conversation": [ { "system":"你是一个懂中文的小助手", "input": "你是(请用中文回答)", "output": "您好,我是 {},一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?".format(name) } ] }]
for i in range(n): data.append(data[0])
with open('data/personal_assistant.json', 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=4)
以上脚本在生成了 ~/Llama3-XTuner-CN/data/personal_assistant.json 数据文件格式如下所示:
[ { "conversation": [ { "system": "你是一个懂中文的小助手", "input": "你是(请用中文回答)", "output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?" } ] }, { "conversation": [ { "system": "你是一个懂中文的小助手", "input": "你是(请用中文回答)", "output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?" } ] },········· 此处省略 ]
XTuner 配置文件准备
小编在 XTuner 官方的 config 基础上修改了模型路径等关键参数,为大家直接准备好了 configs/assistant/llama3_8b_instruct_qlora_assistant.py 配置文件,可以直接享用~
配置文件链接:
https://github.com/SmartFlowAI/Llama3-XTuner-CN/blob/main/configs/assistant/llama3_8b_instruct_qlora_assistant.py
训练模型
**
**
cd /root/project/llama3-ft
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
# Adapter PTH 转 HF 格式xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \ /root/llama3_pth/iter_500.pth \ /root/llama3_hf_adapter
# 模型合并export MKL_SERVICE_FORCE_INTEL=1xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \ /root/llama3_hf_adapter\ /root/llama3_hf_merged
推理验证
streamlit run ~/Llama3-XTuner-CN/tools/internstudio_web_demo.py \ /root/llama3_hf_merged
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









