






 本文介绍了Scala的基础知识,包括其作为Spark的首选语言、REPL解释器、基本数据类型、变量声明、输入/输出、控制结构、数据结构如数组、元组、列表、映射和集合,以及面向对象编程和函数式编程的基本概念。此外,还讲解了如何使用Scala进行文件操作、异常处理、循环控制以及对集合的遍历和操作,如映射、过滤和规约操作。
本文介绍了Scala的基础知识,包括其作为Spark的首选语言、REPL解释器、基本数据类型、变量声明、输入/输出、控制结构、数据结构如数组、元组、列表、映射和集合,以及面向对象编程和函数式编程的基本概念。此外,还讲解了如何使用Scala进行文件操作、异常处理、循环控制以及对集合的遍历和操作,如映射、过滤和规约操作。
- 目录
- 一,初识Scala
- 二,Scala基础知识
- 三,面向对象编程基础
- 四,函数式编程基础
-
一,初识Scala
- spark作为一个非常流行普及的分布式计算框架,支持Scala,Java,Python,R语言开发应用程序。spark本身就是Scala语言开发的,Scala语言自然就是我们学习Spark的首选语言。
- 1.Scala运行于JVM之上,兼容大多数Java程序。
- 2.Scala既是一门面向对象的编程语言也一门函数式的编程语言。
- 3.Scala解释器REPL(read,eval,print,loop的缩写)。
- 4.spark自带REPL解释器,spark配置好后,直接键入scala就可以进入scala解释器进行scala语言的学习,以下是spark的环境变量配置项。
- #SPARK
- export SPARK_HOME=/home/TG/software/spark/spark-3.1.3-bin-without-hadoop
- export PATH=${SPARK_HOME}/bin:$PATH
- export PATH=${SPARK_HOME}/sbin:$PATH
- 5.scala解释器中一次只能运行一行的运行Scala程序,要想依次运行多行程序得在本地编辑一个Scala文件。
- 源代码:
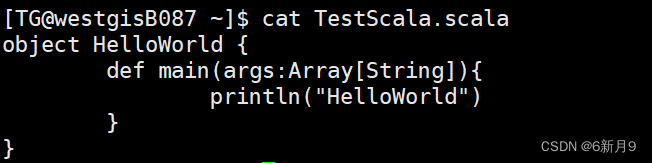
- 运行:
- 1)直接用Scala接源代码文件名

- 2)在REPL中:
- 先装载,:load接文件名
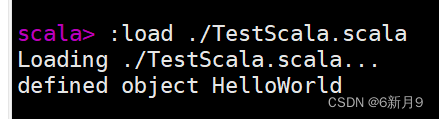
- 再用对象调用属性:

- 3)用scalac

- 注意scala -classpath . HelloWorld中的.与HelloWorld之间有空格
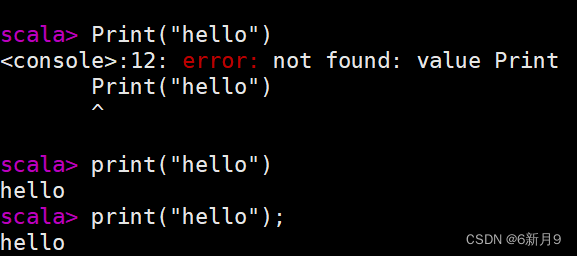
- 6.Scala语言大小写敏感,用;(英文的分号)作为语句的结束符且(;)可以省略。
-
二,Scala基础知识
- 1.九种基本数据类型+Unit类型
- Byte,Short,Int,Long,Char,String,Float,Double,Boolean(true,false两种取值),Unit作为没有返回值的的函数类型。
- 2.Scala只有val(不可变)和var(可变)两类型变量
- 变量声明:
- 1)val 变量名:数据类型 = 初始值
- 2)var 变量名:数据类型 = 初始值
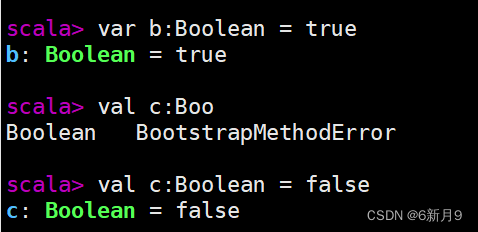
- 3.REPL自带类型推断机制,可以不用声明变量的类型,可以根据初始值来判断变量的类型

- 4.Scala操作符的优先级
- 算数运算符 >关系运算符>逻辑运算符>赋值运算符
- (!(逻辑非运算符)比算术运算符优先级高,建议尽量用括号去厘清操作符的优先级。
- 5.输入/输出
- 1)控制台输入
- import scala.io.StdIn._
- readInt(),readShort(),readLong(),readDouble(),readFloat(),readLine(),readBoolean()

- 2)控制台输出
- print()
- println()输出结束时默认加一个换行符
- printf()带格式化字符串输出
- Scala自带字符串插值机制,s/f,$用于插值,f支持带格式化参数
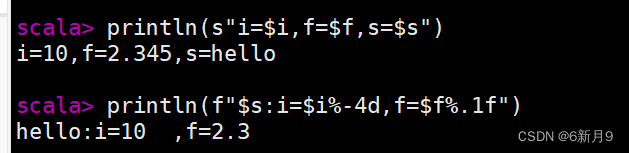
- 3)文本文件的创建和写入
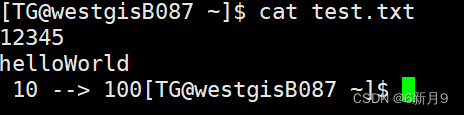
- import java.io.PrintWriter,用print和println方法向文本文件写入内容
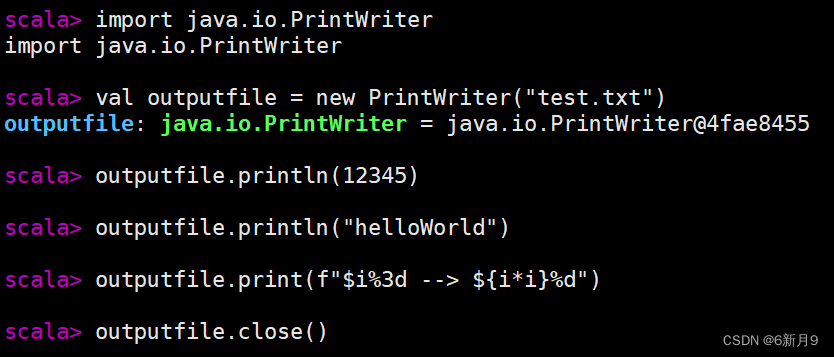
-
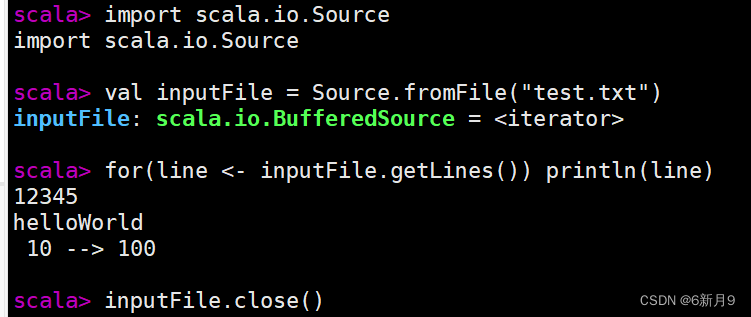
- 4)文件读取
- import scala.io.Source 用getLines方法返回一个包含所有行的迭代器
- 6.控制结构
- 1)if条件表达式
- Scala中if条件表达式会返回一个值,可以将这个值赋值给一个变量
-
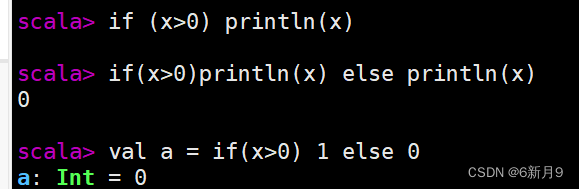
- 2) while循环
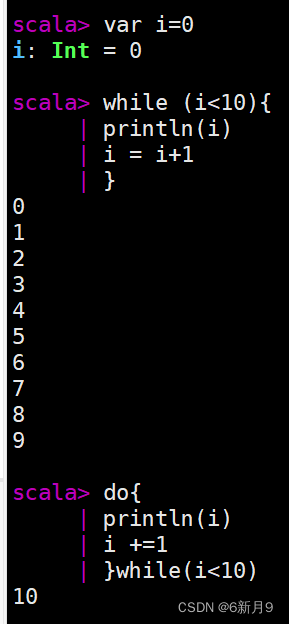
- 3)for循环表达式
- for循环每次执行的时候都可以产生一个值,然后将包含所有产生值的容器对象返作为for循环表达式的值返回。
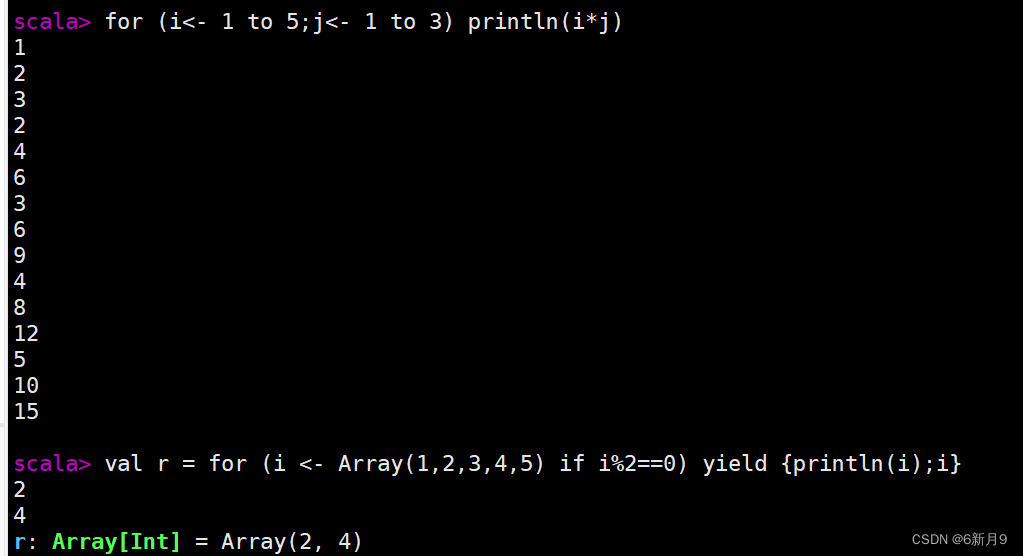
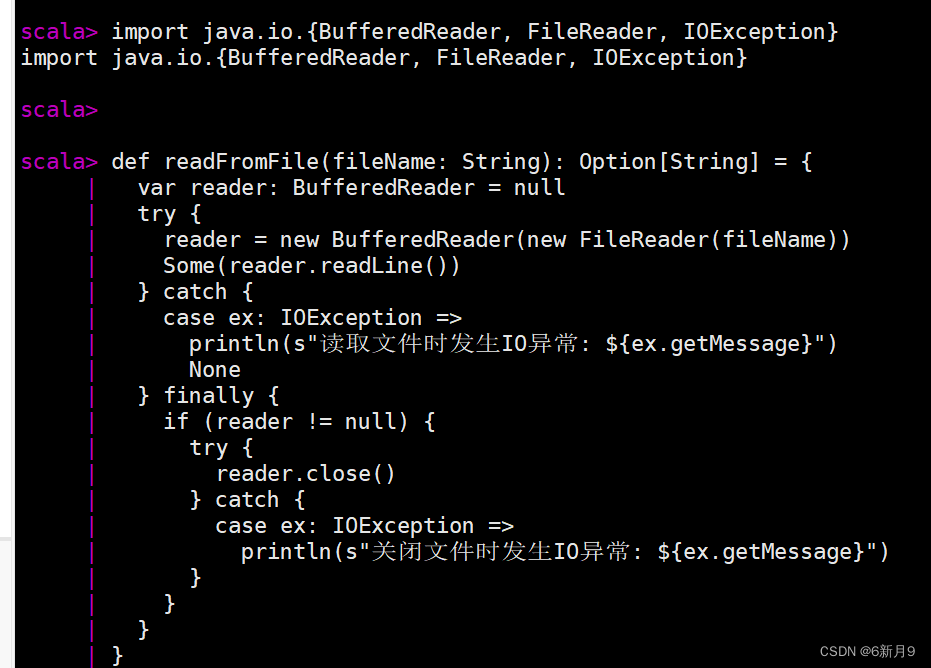
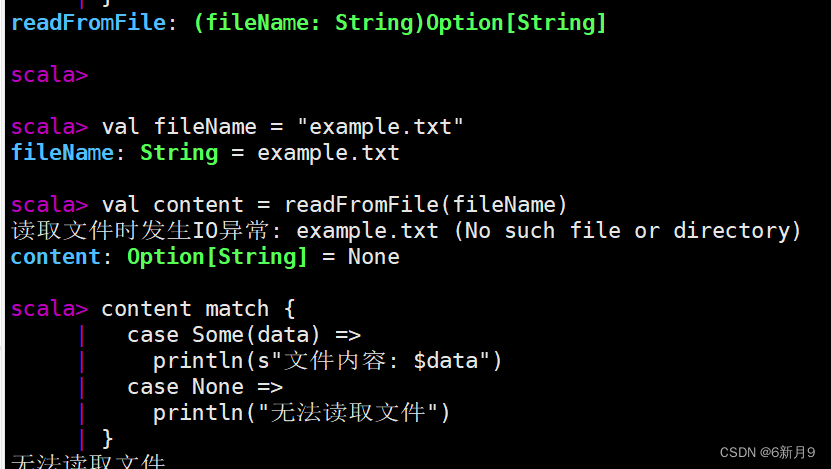
- 4)异常处理结构
- scala仅支持运行时异常,try{}catch{}finally{},finally{}语句块是可选的。finally语句块无论是否发生异常都会执行 。
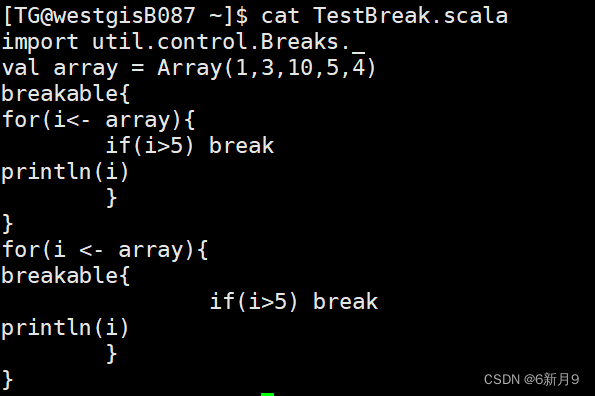
- 5)对循环的控制,Scala用breakable和break实现对循环的控制
- import util.control.Breaks._
- breakable{
- ...
- if(...)break
- ...
- }
- 即从break跳到breakable
- 7.数据结构
- scala编程中经常需要用到各种数据结构,比如数组(Array),元组(Tuple),列表(List),映射(Map),集合(Set)等。
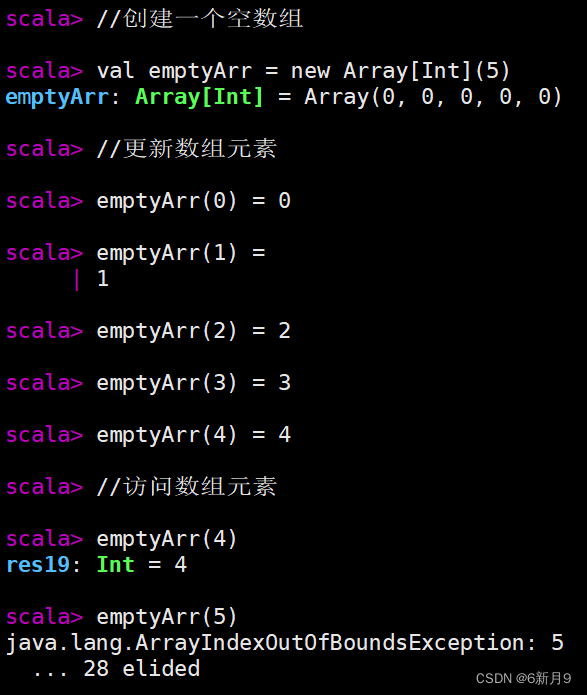
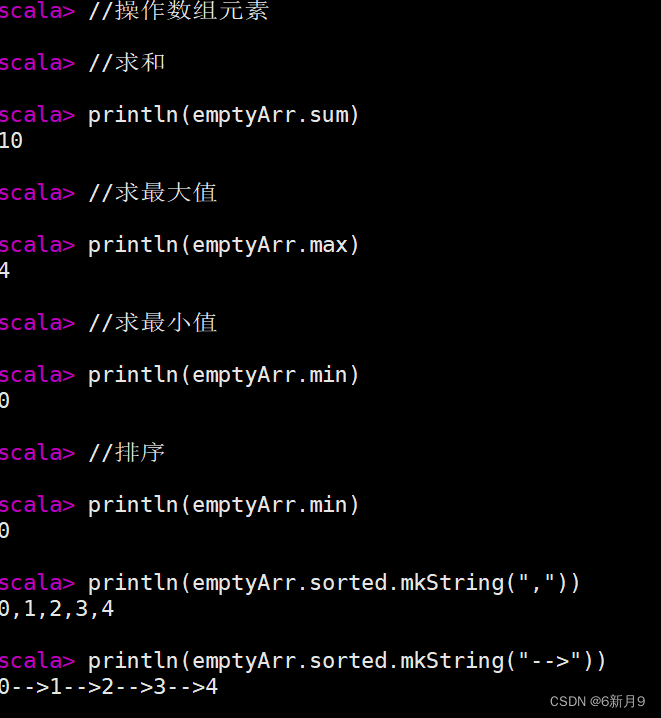
- 1)数组(Array)是一种可变的,可索引的,元素具有相同类型的数据集合,这是最常用的数据结构。
- 注意:1.Scala数组的索引是从零开始的,且最后一个元素的索引为数组长度n-1。
- 2.scala的数组使用圆括号来访问数组。
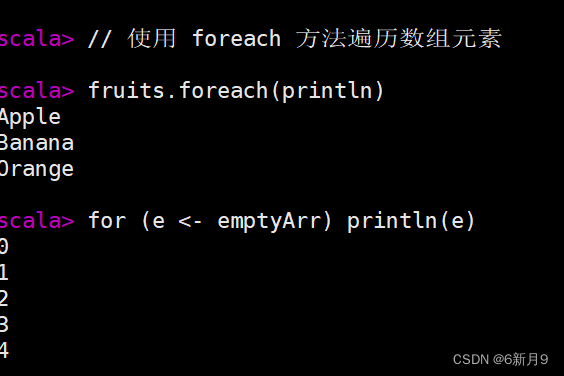
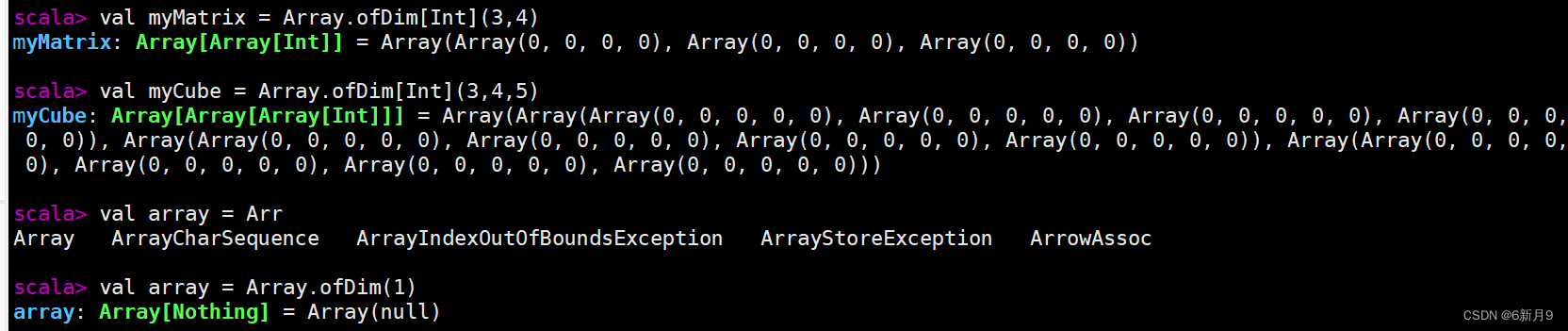
- 定义多维数组,通过ofDim方法定义多维数组
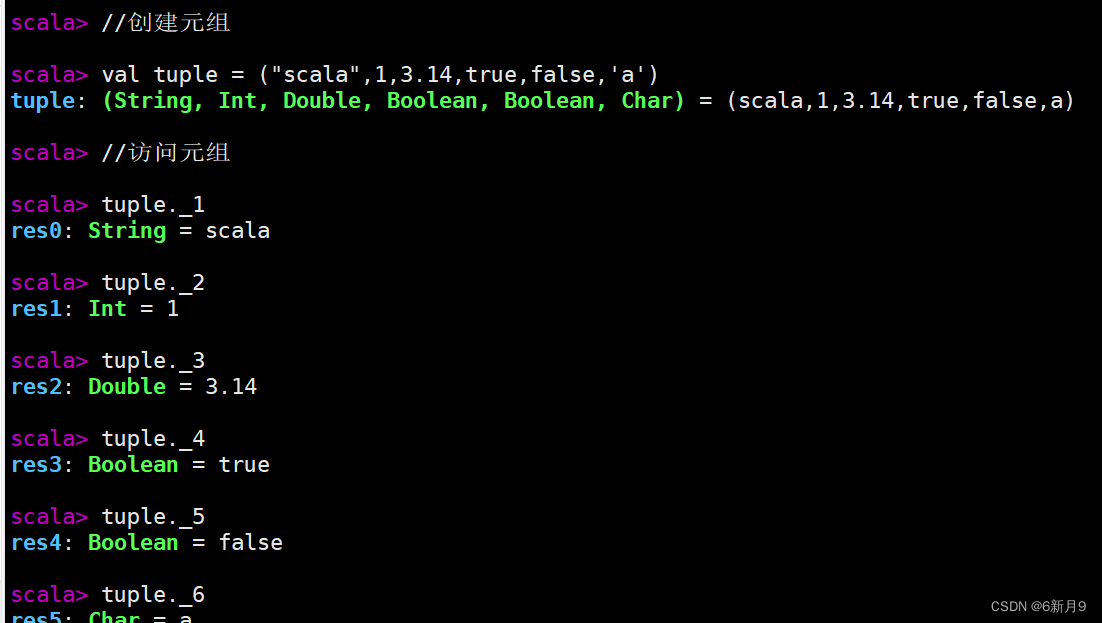
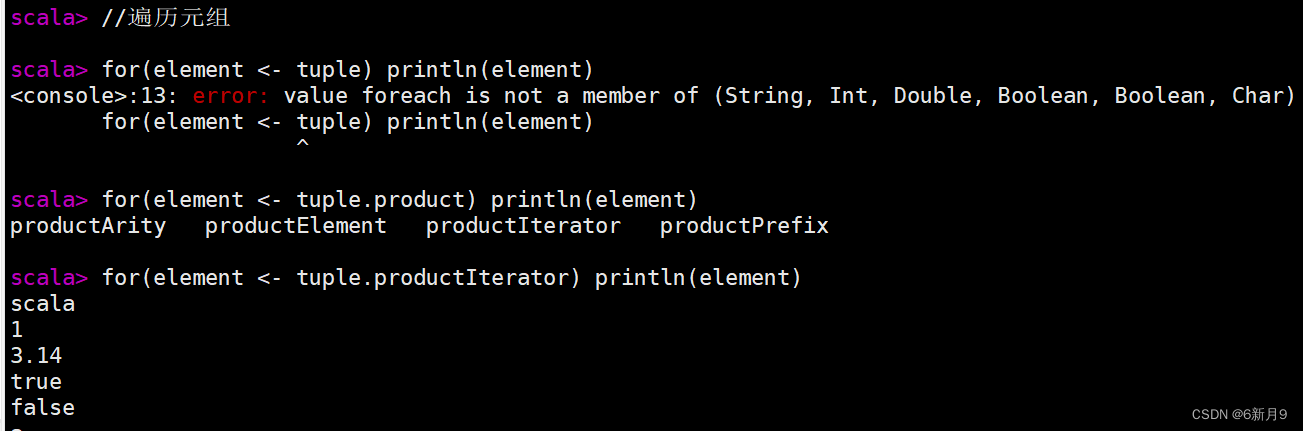
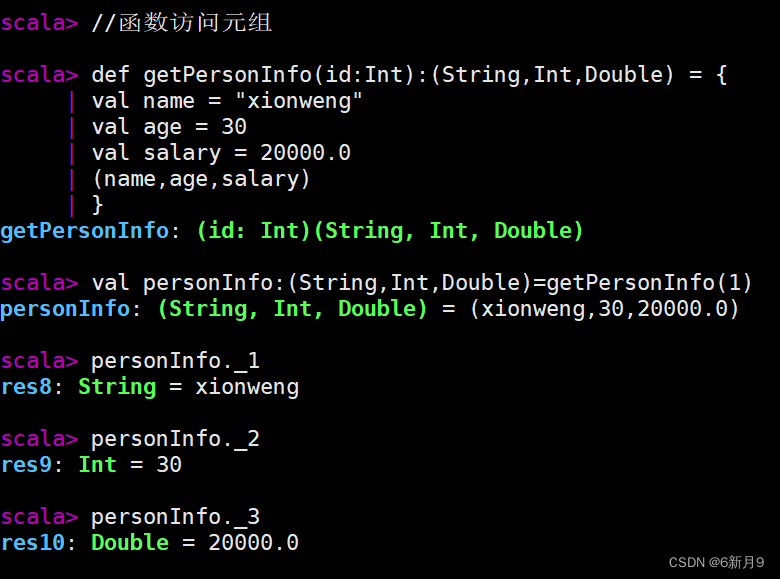
- 2)元组(Tuple)
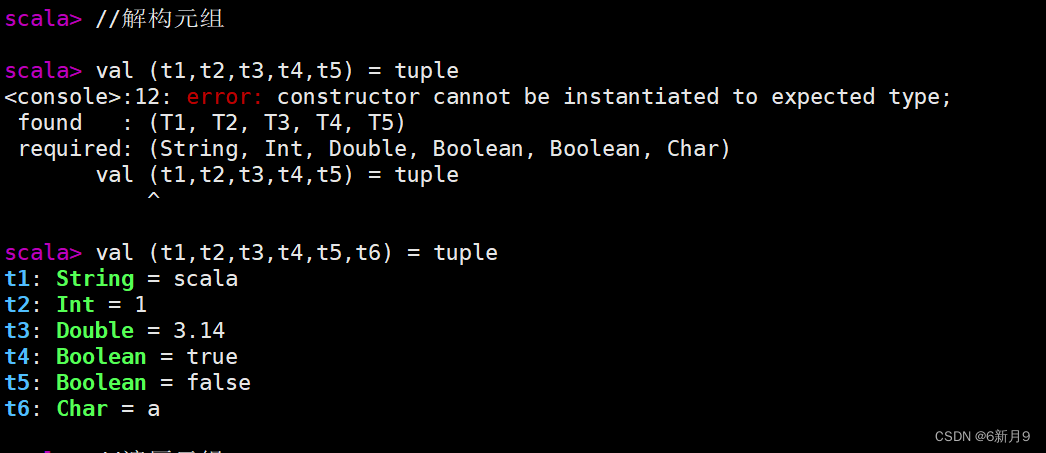
- 在Scala中,元组(Tuple)是一种用于存储固定数量的不同类型的元素的数据结构。元组可以包含从1个到22个元素,每个元素的类型可以不同。元组中的元素可以使用点号
.和索引访问。 - 注意:Tuple的索引从1开始,Array的索引从0开始,Tuple的元素可是不同类型,Array的元素只能同种类型。
-
-
- 3)列表(List)
- 在scala中,列表(List)是一种常用的容器类型,用于存储有序的元素序列。列表是不可变的,意味着它的内容在创建后不可更改。
- 注意:列表索引从零开始,列表元素可以重复,列表元素可以是不同数据类型。
- scala> //创建列表
- scala> val list = List("scala",0,3.14,true,false,'a')
- list: List[Any] = List(scala, 0, 3.14, true, false, a)
- scala> //访问列表元素
- scala> list(0)
- res0: Any = scala
- scala> list(5)
- res1: Any = a
- scala> //连接列表
- scala> val list1 = List(1,2,3)
- list1: List[Int] = List(1, 2, 3)
- scala> val list2 = List(4,5,6)
- list2: List[Int] = List(4, 5, 6)
- scala> val list3 = list1 ++ list2
- list3: List[Int] = List(1, 2, 3, 4, 5, 6)
- scala> //添加列表元素
- scala> val Numlist = List(1,2,3)
- Numlist: List[Int] = List(1, 2, 3)
- scala> val updatedlist = 0::Numlist
- updatedlist: List[Int] = List(0, 1, 2, 3)
- scala> val intlist = 1::2::3::Nil
- intlist: List[Int] = List(1, 2, 3)
- scala> //过滤元素
- scala> val numlist = List(1,2,3,4)
- numlist: List[Int] = List(1, 2, 3, 4)
- scala> val evenList = numlist.filter(_%2 == 0)
- evenList: List[Int] = List(2, 4)
- scala> //转换元素
- scala> val numlist = List(1,2,3,4,5)
- numlist: List[Int] = List(1, 2, 3, 4, 5)
- scala> val doubledList = numlist.map(_*2)
- doubledList: List[Int] = List(2, 4, 6, 8, 10)
- scala> //检查元素是否存在
- scala> val fruitsList = List("apple","banana","orange")
- fruitsList: List[String] = List(apple, banana, orange)
- scala> val hasApple:Boolean = fruitsList.contains("Apple")
- hasApple: Boolean = false
- scala> val hasapple:Boolean = fruitsList.contains("apple")
- hasapple: Boolean = true
- scala> //head和tail
- scala> fruitsList.head
- res2: String = apple
- scala> fruitsList.tail
- res3: List[String] = List(banana, orange)
- 注意:Nil为空列表对象,::向右结合,由于列表采用链表结构,因此,除了head和tail
- 以及其他的操作的时间复杂度为O(1),其他时间复杂度为O(n).
- 4)Range类
- // 使用 to 方法创建 Range
- val range1 = 1 to 5
- // 输出: Range(1, 2, 3, 4, 5)
- // 使用 until 方法创建 Range
- val range2 = 0 until 10 by 2
- // 输出: Range(0, 2, 4, 6, 8)
- // 使用 by 方法创建 Range
- val range3 = 10 to 1 by -1
- // 输出: Range(10, 9, 8, 7, 6, 5, 4, 3, 2, 1)
- // 检查 Range 是否为空
- val emptyRange = 1 to 0
- val nonEmptyRange = 1 to 5
- println(emptyRange.isEmpty) // 输出: true
- println(nonEmptyRange.isEmpty) // 输出: false
- // 检查 Range 是否包含特定值
- println(range1.contains(3)) // 输出: true
- println(range1.contains(6)) // 输出: false
- // 获取 Range 的长度
- println(range1.length) // 输出: 5
- // 遍历 Range 中的每个元素
- range2.foreach(println)
- // 输出:
- // 0
- // 2
- // 4
- // 6
- // 8
- // 对 Range 中的每个元素执行函数并返回新的 Range
- val doubledRange = range1.map(_ * 2)
- // 输出: Range(2, 4, 6, 8, 10)
- // 根据条件过滤 Range 中的元素并返回新的 Range
- val evenRange = range1.filter(_ % 2 == 0)
- // 输出: Range(2, 4)
- // 将 Range 转换为 List
- val rangeList = range1.toList
- // 输出: List(1, 2, 3, 4, 5)
- // 计算 Range 中所有元素的总和
- val sum = range1.sum
- // 输出: 15
- 5)集合(Set)
- scala的集合(Set)是不重复元素的容器,分为可变集合和不可变集合两种。
- scala> var myset = Set("hadoop","spark")
- myset: scala.collection.immutable.Set[String] = Set(hadoop, spark)
- scala> myset += "scala"
- scala> import scala.collection.mutable.Set
- import scala.collection.mutable.Set
- scala> val myMutableSet = Set("Database","BigData")
- myMutableSet: scala.collection.mutable.Set[String] = Set(BigData, Database)
- scala> myMutableSet+="Cloud"
- res12: myMutableSet.type = Set(BigData, Cloud, Database)
- scala> myset.foreach(println)
- hadoop
- spark
- scala
- 5)映射(Map)
- Scala 的 Map 是一种键值对(Key-Value)的集合,用于存储和操作键值对数据。Map 分为不可变的和可变的,默认是不可变的Map,可以通过创建新的 Map 来添加、更新或删除键值对。以下是 Scala Map 的详细介绍:
- 1. 创建 Map:
- - 使用 `->` 运算符创建键值对:
- val map1: Map[String, Int] = Map("apple" -> 1, "banana" -> 2, "orange" -> 3)
- - 使用元组列表创建 Map:
- val map2: Map[String, Int] = Map(("apple", 1), ("banana", 2), ("orange", 3))
- 2. 访问和操作 Map:
- - 通过键获取值:
- val value1 = map1("apple") // 获取键 "apple" 对应的值
- - 检查键是否存在:
- val containsKey = map1.contains("banana") // 检查是否包含键 "banana"
- - 获取所有键或值的集合:
- val keys = map1.keys // 获取所有键的集合
- val values = map1.values // 获取所有值的集合
- - 添加或更新键值对:
- val updatedMap = map1 + ("grape" -> 4) // 添加新的键值对
- val updatedMap2 = map1.updated("apple", 5) // 更新键 "apple" 对应的值
- - 删除键值对:
- val removedMap = map1 - "orange" // 删除键为 "orange" 的键值对
- 3. 遍历 Map:
- - 遍历所有键值对:
- map1.foreach { case (key, value) =>
- println(s"Key: $key, Value: $value")
- }
- - 遍历所有键:
- map1.keys.foreach { key =>
- println(s"Key: $key")
- }
- - 遍历所有值:
- map1.values.foreach { value =>
- println(s"Value: $value")
- }
- 4. Map 特性:
- - 键的唯一性:Map 中的键是唯一的,每个键只能对应一个值。
- - 无序性:Map 中的键值对没有固定的顺序。
- Scala 的 Map 提供了一种方便和高效的方式来存储和操作键值对数据。它适用于各种场景,例如配置信息、缓存数据、数据映射等。利用 Map 的丰富操作方法,可以高效地进行键值对的查找、更新和遍历操作。
- 6)迭代器(Iterator)
- Scala 的 Iterator 是一种用于遍历集合元素的抽象接口。Iterator 提供了一种惰性的方式来逐个访问集合中的元素,而不需要提前加载或生成整个集合。这种惰性求值的方式使得 Iterator 在处理大型集合时非常高效,并且占用的内存较少。下面是 Scala Iterator 的详细介绍:
- 1. 创建 Iterator:
- - 通过集合的 `iterator` 方法创建 Iterator:
- ```scala
- val list = List(1, 2, 3, 4, 5)
- val iterator = list.iterator
- ```
- - 通过调用 `fromIterator` 方法将集合转换为 Iterator:
- ```scala
- val iterator = Iterator.fromIterator(list.iterator)
- ```
- 2. Iterator 的操作方法:
- - `next()`:返回迭代器中的下一个元素,并将迭代器位置移动到下一个元素。
- - `hasNext()`:检查迭代器中是否还有下一个元素。
- - `foreach(function: A => Unit)`:对迭代器中的每个元素应用给定的函数。
- - `filter(predicate: A => Boolean)`:根据给定的条件谓词过滤迭代器中的元素。
- - `map[B](function: A => B)`:对迭代器中的每个元素应用给定的函数,并返回结果的新迭代器。
- - `toList`:将迭代器转换为一个 List。
- - `toSet`:将迭代器转换为一个 Set。
- 3. 遍历 Iterator:
- - 使用 `while` 循环遍历 Iterator:
- ```scala
- while (iterator.hasNext) {
- val element = iterator.next()
- // 处理元素
- }
- ```
- - 使用 `foreach` 方法遍历 Iterator:
- ```scala
- iterator.foreach { element =>
- // 处理元素
- }
- ```
- - 使用 `toList` 方法将 Iterator 转换为 List,并进行进一步的处理:
- ```scala
- val list = iterator.toList
- // 对 List 进行处理
- ```
- 4. Iterator 的特性:
- - 惰性求值:Iterator 采用惰性求值的方式,只在需要时才生成下一个元素,这样可以在处理大型集合时节省内存。
- - 只能单向遍历:Iterator 只能向前遍历集合,不支持反向遍历或跳跃遍历。
- - 只能遍历一次:Iterator 是一次性的,一旦遍历完成,就无法再次使用。
- Scala 的 Iterator 提供了一种高效和低内存消耗的方式来遍历集合元素。它适用于需要逐个访问集合元素并且不需要提前加载整个集合的场景。通过使用 Iterator 的操作方法和遍历方式,可以对集合元素进行过滤、映射和其他常见的操作。
- 当涉及到使用 Scala 的 Iterator 时,以下是一些常见的应用示例:
- 1. 过滤元素:
- ```scala
- val list = List(1, 2, 3, 4, 5)
- val evenNumbersIterator = list.iterator.filter(_ % 2 == 0)
- while (evenNumbersIterator.hasNext) {
- val element = evenNumbersIterator.next()
- println(element)
- }
- ```
- 在此示例中,我们使用 `filter` 方法创建了一个只包含偶数的迭代器,并通过遍历迭代器打印出所有偶数。
- 2. 转换元素:
- ```scala
- val list = List(1, 2, 3, 4, 5)
- val squaredNumbersIterator = list.iterator.map(n => n * n)
- squaredNumbersIterator.foreach { element =>
- println(element)
- }
- ```
- 在这个示例中,我们使用 `map` 方法创建了一个迭代器,其中每个元素都是原始列表中元素的平方。然后,我们使用 `foreach` 方法遍历迭代器并打印出平方后的数字。
- 3. 扁平化操作:
- ```scala
- val nestedList = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))
- val flattenedIterator = nestedList.iterator.flatten
- while (flattenedIterator.hasNext) {
- val element = flattenedIterator.next()
- println(element)
- }
- ```
- 在这个示例中,我们有一个嵌套列表,我们使用 `flatten` 方法将其扁平化为一个迭代器。然后,我们遍历迭代器并打印出扁平化后的元素。
- 4. 自定义迭代器:
- ```scala
- class CountingIterator(start: Int, end: Int) extends Iterator[Int] {
- private var current = start
- override def hasNext: Boolean = current <= end
- override def next(): Int = {
- val result = current
- current += 1
- result
- }
- }
- val countingIterator = new CountingIterator(1, 5)
- countingIterator.foreach(println)
- ```
- 在此示例中,我们自定义了一个 `CountingIterator` 类,它扩展了 `Iterator[Int]` 特质,并实现了 `hasNext` 和 `next` 方法。该迭代器用于生成从 `start` 到 `end` 范围内的连续整数。然后,我们创建一个实例并使用 `foreach` 方法遍历迭代器并打印出生成的数字。
- 这些示例展示了使用 Scala 的 Iterator 进行过滤、转换、扁平化等常见操作的应用场景。通过使用迭代器,我们可以逐个访问集合的元素,实现对数据的逐个处理,从而提供更高效的内存利用和懒加载的特性。
-
三,面向对象编程基础
- 当涉及到Scala的面向对象编程时,下面是更详细的讨论:
- 1. 类和对象:
- - 类是对象的模板,它定义了对象的属性和方法。可以使用`class`关键字定义类。
- - 对象是类的实例,通过使用`new`关键字和类的构造函数创建。对象可以调用类的方法和访问类的属性。
- ```scala
- class Person {
- var name: String = ""
- def sayHello(): Unit = {
- println(s"Hello, my name is $name.")
- }
- }
- val person = new Person()
- person.name = "John"
- person.sayHello// 输出: Hello, my name is John.
- ```
- 2. 属性和方法:
- - 类的属性用于存储对象的状态。可以使用`var`关键字定义可变属性,使用`val`关键字定义不可变属性。
- - 方法定义了对象的行为。方法可以读取和修改属性,也可以执行其他操作。
- ```scala
- class Circle {
- val radius: Double = 1.0
- def area(): Double = {
- Math.PI * radius * radius
- }
- }
- val circle = new Circle()
- println(circle.area()) // 输出: 3.141592653589793
- ```
- 3. 继承:
- - 继承允许创建一个类来扩展另一个类的属性和方法。使用`extends`关键字指定要继承的父类。
- - 子类可以继承父类的属性和方法,并且可以添加自己的新属性和方法。可以使用`override`关键字重写父类的方法。
- ```scala
- class Animal {
- def makeSound(): Unit = {
- println("The animal makes a sound.")
- }
- }
- class Dog extends Animal {
- override def makeSound(): Unit = {
- println("The dog barks.")
- }
- }
- val dog = new Dog()
- dog.makeSound() // 输出: The dog barks.
- ```
- 4. 多态:
- - 多态允许使用基类类型的引用来引用子类的对象,从而以统一的方式处理不同类型的对象。
- - 可以使用父类类型的变量引用子类对象,然后根据实际对象的类型调用相应的方法。
- ```scala
- class Shape {
- def area(): Double = 0.0
- }
- class Rectangle(width: Double, height: Double) extends Shape {
- override def area(): Double = width * height
- }
- class Circle(radius: Double) extends Shape {
- override def area(): Double = Math.PI * radius * radius
- }
- val shapes: Array[Shape] = Array(new Rectangle(2.0, 3.0), new Circle(1.0))
- for (shape <- shapes) {
- println(shape.area())
- }
- // 输出:
- // 6.0
- // 3.141592653589793
- ```
- 5. 封装:
- - 封装是将数据和方法组合在一个单元内,以防止对数据的直接访问。
- - 可以使用访问修饰符来限制对类的成员的访问权限。`private`修饰的成员只能在类内部访问,`protected`修饰的成员可以在类内部和子类中访问。
- ```scala
- class Person {
- private var age: Int = 0
- def getAge(): Int = age
- def setAge(newAge: Int): Unit = {
- if (newAge >= 0) {
- age = newAge
- }
- }
- }
- val person = new Person()
- person.setAge(25)
- println(person.getAge()) // 输出: 25
- person.age = -10 // 错误,age是私有的,无法直接访问
- ```
- 6. 抽象类和特质:
- - 抽象类是不能实例化的类,它可以包含抽象方法和非抽象方法。抽象方法没有实现,需要在子类中重写。
- - 特质是一组方法签名的集合,它可以由类实现。特质中的方法默认是抽象的,不需要使用`abstract`关键字。
- 可以使用with关键字混入多个特质,用extends继承一超类。
- ```scala
- abstract class Shape {
- def area(): Double // 抽象方法
- }
- class Circle(radius: Double) extends Shape {
- override def area(): Double = Math.PI * radius * radius
- }
- trait Drawable {
- def draw(): Unit // 抽象方法
- }
- class Square extends Drawable {
- override def draw(): Unit = {
- println("Drawing a square.")
- }
- }
- ```
- 8. 单例对象:
- 单例对象是一个类的实例,但只能存在一个实例。
- 单例对象常用于表示全局状态、共享资源或提供某些服务。
- 单例对象可以包含静态方法和字段,并且在整个应用程序中可以直接访问。
- ```scala
- object Config {
- val apiUrl: String = "https://example.com/api"
- def logLevel: String = "INFO"
- }
- println(Config.apiUrl) // 输出: https://example.com/api
- println(Config.logLevel) // 输出: INFO
- ```
- 这些是Scala面向对象编程的基础概念和语法。Scala还提供了更多高级特性和语法,如模式匹配、样例类、类型参数和隐式转换,使得面向对象编程更为强大和灵活。
-
四,函数式编程基础
- Scala是一门多范式编程语言,既支持面向对象编程(OOP)也支持函数式编程(FP)。函数式编程是一种编程范式,它将计算视为数学函数的求值,强调使用不可变数据和无副作用的函数来构建程序。以下是对Scala函数式编程的详细介绍:
-
不可变数据结构: 在函数式编程中,数据是不可变的,这意味着一旦数据被创建,就不能再被修改。Scala提供了许多不可变的数据结构,如
List、Set和Map等。不可变数据结构可以消除并发问题,使代码更易于理解和推理。 -
高阶函数: Scala支持高阶函数,即函数可以作为参数传递给其他函数,或者作为函数的返回值。高阶函数使得编写通用、灵活的代码变得更加容易。常见的高阶函数有
map、filter、fold等。 -
匿名函数: Scala允许使用匿名函数(也称为Lambda表达式),它们是没有名字的一种函数。匿名函数可以更简洁地定义功能,并通常用于高阶函数的参数传递。
-
不可变函数: 在函数式编程中,函数应该是无副作用的,即函数的执行不应该对除了函数返回值之外的任何内容产生影响。不可变函数更易于测试、推理和并行执行。
-
递归: 函数式编程通常使用递归而不是循环来解决问题。Scala支持尾递归优化,使递归函数能够在不产生栈溢出的情况下进行优化的尾递归调用。
-
模式匹配: 在函数式编程中,模式匹配是一种强大的工具,用于根据数据的结构匹配不同的模式,并执行相应的代码。Scala的
match表达式和case语句提供了强大的模式匹配功能。 -
柯里化: 柯里化是一种将多参数函数转换为一系列接受一个参数的函数的技术。Scala支持柯里化,这种技术可以让函数更加灵活和可组合。
-
不可变性检查: Scala编译器会在编译时检查不可变性,以确保在使用
val关键字声明的不可变变量被正确地处理。 - 函数式编程在Scala中具有非常广泛的应用,它提供了强大的工具和编程模式来编写简洁、高效、易于理解和维护的代码。尽管函数式编程可以在任何编程范式中应用,但Scala的函数式特性使其成为函数式编程的优秀选择。
-
五,Scala对容器的各种操作
- 1.遍历操作
- foreach用于对容器的遍历,foreach是一个完全无副作用的方法,它的返回值为Unit类型,它遍历容器的每个元素,并将接受的函数参数应用到每个元素上。
- //遍历操作
- //foreach()方法
- object Main{
- def main(args:Array[String]){
- val list = List(1,2,3)
- val f=(i:Int)=>println(i)
- list.foreach(f)
- val university = Map("XMU" -> "Xiamen University","THU" -> "Tsinghua University","PKU"->"Peking University")
- university.foreach(kv => println(kv._1+":"+kv._2))
- university.foreach{x=>x match {case (k,v) => println(k+":"+v)}}
- for((k,v) <- university)println(k+":"+v)
- }
- }
-
- 2.映射操作
- 映射是指通过对容器中的元素进行某些运算来生成一个新的容器。map和flatMap是常用的映射方法。
- //映射操作
- object Main{
- def main(args:Array[String]){
- val books = List("Hadoop","Hive","HDFS")
- books.map(s => s.toUpperCase).foreach(x=>println(x))
- books.map(s => s.length).foreach(x=>println(x))
- books.flatMap(s=>s.toList).foreach(x=>print(x))
- }
- }
- 3.过滤操作
- 过滤是指遍历一个容器,从中获得满足指定条件的元素,返回一个新的容器。常见的过滤操作有filter,filterNot,exists,find
- //过滤操作
- object Main{
- def main(args:Array[String]){
- val university = Map("XMU"->"Xiamen University","THU"->"Tsinghua University","PKU"->"Peking University","XMUT"->"Xiamen University of Technology")
- val xmus = university.filter(kv => kv._2.contains("Xiamen"))
- println(xmus)
- val l=List(1,2,3,4,5,6).filter(_%2==0)
- println(l)
- val xums0 = university.filterNot{kv=>kv._2.contains("Xiamen")}
- println(xums0)
- val t=List("Spark","Hadoop","Hbase")
- println(t.exists(_.startsWith("H")))
- t.find(_.startsWith("Hb")).foreach(x=>println(x))
- t.find(_.startsWith("Hp")).foreach(x=>println(x))
- }
- }
- 4.规约操作
- 规约操作是对容器的元素进行两两运算,将其规约为一个值。常见的规约操作有reduce,reduceLeft,reduceRight,fold,foldLeft,foldRight
- 5.拆分操作
- 拆分操作是把一个容器里的元素按一定的规则分割成多个子容器。常用的拆分操作有groupedBy,grouped,sliding

















02-13
 2924
2924
2924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









