







Mammal sleep data
msleep # 一个哺乳动物睡眠数据集计算方差(variation)
var(数据集名$列名)默认计算四分位数(quartile)
quantile 分位数
quantile(数据集名$列名)
Standard eviation
sd(数据集名$列名)Boxplot using ggplot
ggplot(msleep, aes(x=vore, y=sleep_total)) + geom_boxplot()这个会生成“msleep”数据集中不同饮食类别的总睡眠时间的箱线图
Histogram
ggplot(rolls_10, aes(n)) +
geom_histogram(bins = 6)这段代码会生成一个直方图,显示rolls_10数据框中n变量的分布情况,数据将根据值的不同被分配到6个不同的箱子中。
rbinom
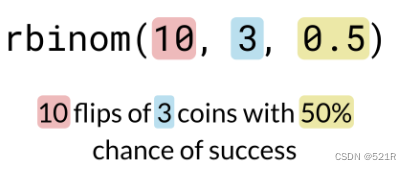
pbinom
pbinom(7, 10, 0.5, lower.tail = FALSE)在R语言中,pbinom函数用于计算二项分布的累积分布函数(CDF)。这个函数的参数包括:
-
第一个参数(在这个例子中是7)是成功次数的上界,即我们想要计算得到至多7次成功的概率。
-
第二个参数(在这个例子中是10)是试验次数,即二项实验重复的总次数。
-
第三个参数(在这个例子中是0.5)是每次试验成功的概率。
所以,pbinom(7, 10, 0.5)计算的是在10次试验中,每次试验成功的概率为0.5时,获得0到7次成功(包括0次和7次)的累积概率。
lower.tail = False表示的是7次以上成功的累积概率。即1-pbinom(7,10,0.5)
dbinom
dbinom(7, 10, 0.5)在R语言中,dbinom函数用于计算二项分布的概率质量函数(PMF)。这个函数的参数包括:
-
第一个参数(在这个例子中是7)是成功次数,即我们想要计算得到正好7次成功的概率。
-
第二个参数(在这个例子中是10)是试验次数,即二项实验重复的总次数。
-
第三个参数(在这个例子中是0.5)是每次试验成功的概率。
所以,dbinom(7, 10, 0.5)计算的是在10次试验中,每次试验成功的概率为0.5时,正好获得7次成功的概率。
runif
runif(1000, min = 0, max = 30)在R语言中,runif函数用于生成遵循均匀分布的随机数。此函数的参数包括:
-
第一个参数指定了要生成的随机数的数量,在这个例子中是1000个。
-
min和max参数指定了随机数生成的范围,在这个例子中,随机数将在0到30之间生成。
因此,runif(1000, min = 0, max = 30)的作用是生成1000个在0到30之间的均匀分布的随机数。
punif
punif(5, min = 1, max = 30, lower.tail = FALSE)在R语言中,punif函数用于计算均匀分布的累积分布函数(CDF)。此函数也允许计算其补(即在指定区间内随机变量大于某个值的概率),这通过设置lower.tail = FALSE参数来实现。
参数解释:
-
第一个参数(在这个例子中是5)是要计算其CDF的值。
-
min和max分别是均匀分布的最小值和最大值,在这个例子中分别是1和30。 -
lower.tail = FALSE表示我们感兴趣的是随机变量大于5的概率,而不是小于等于5的概率。
因此,punif(5, min = 1, max = 30, lower.tail = FALSE)计算的是在范围1到30的均匀分布中,随机变量取值大于5的概率。
dunif
dunif(1000, min = 0, max = 30)在R语言中,dunif函数用于计算均匀分布的概率密度函数(PDF)。这个函数的参数包括一个指定点,以及分布的最小值min和最大值max。
给定的命令dunif(1000, min = 0, max = 30)尝试计算点1000在一个从0到30范围内的均匀分布的概率密度。然而,考虑到均匀分布的性质,任何位于其定义域之外的点(即,在本例中,小于0或大于30的点)的概率密度都是0。因为在均匀分布的定义域外,没有任何概率密度(即,事件发生的可能性)。
因此,dunif(1000, min = 0, max = 30)的结果是0,因为1000不在分布的定义域[0, 30]内。
(r/p/d)unif 和 (r/p/d)binom的区别
unif(均匀分布)和binom(二项分布)在统计学和概率论中代表了两种完全不同类型的概率分布,它们在定义、性质和适用场景方面有显著的区别。
均匀分布(Uniform Distribution)
均匀分布可以是离散的也可以是连续的,其特点是在指定的区间内,任何一个事件发生的概率都是相同的。
-
连续均匀分布:定义在实数的某个区间上,比如[a, b],其中的每一个值发生的概率是相等的。它的概率密度函数(PDF)在定义区间内是常数,而在区间外为0。
-
离散均匀分布:定义在有限的、离散的值集上,比如抛一枚公平的六面骰子,得到任何一面的概率都是相等的,即1/6。
二项分布(Binomial Distribution)
二项分布是一种离散概率分布,它描述了在固定次数的独立实验中,每次实验成功的概率相同,成功的次数的概率分布。二项分布的典型例子包括抛硬币实验。
-
参数:二项分布有两个参数:n(实验次数)和p(单次实验成功的概率)。它的概率质量函数(PMF)给出了在n次实验中恰好得到k次成功的概率。
-
特点:二项分布关注的是“成功”的次数,而“成功”在每次实验中发生的概率是固定的。
区别
-
定义:
unif描述的是在某个范围内所有事件发生的概率相等;而binom描述的是在一定次数的独立实验中,每次实验成功的次数的分布。 -
参数:均匀分布的参数是其定义区间的上下界(对于连续型),或是可能结果的总数(对于离散型);二项分布的参数是实验次数n和每次实验成功的概率p。
-
离散性与连续性:均匀分布既可以是连续的也可以是离散的;二项分布是离散的。
-
适用场景:均匀分布通常用于模拟所有结果同等可能的情况,如抛骰子、随机抽取;二项分布用于模拟固定次数、成功概率固定的独立实验的成功次数,如抛硬币。
总结
unif和binom分别代表了不同类型的概率分布,它们在概率论和统计学中用于模拟和分析不同类型的随机过程和实验。选择使用哪种分布取决于研究的具体问题和实验的性质。
(r/p/d/q)norm
pnorm(154, mean = 161, sd = 7)
rnorm(154, mean = 161, sd = 7)
dnorm(154, mean = 161, sd = 7)
qnorm(0.95, mean = 161, sd = 7)在R语言中,pnorm函数用于计算正态分布的累积分布函数(CDF)。这个函数的参数包括:
-
第一个参数是你要计算其CDF的值,在这个例子中是154。
-
mean是分布的均值,在这个例子中是161。 -
sd是分布的标准差,在这个例子中是7。
因此,pnorm(154, mean = 161, sd = 7)计算的是在一个均值为161,标准差为7的正态分布中,随机变量小于或等于154的概率。(大于的话可以使用lower.tail=FALSE参数)
rnorm(154, mean = 161, sd = 7)计算的是生成154个服从均值为161,标准差为7的正态分布的随机数
dnorm(154, mean = 161, sd = 7)计算的是在均值为161,标准差为7的正态分布中,随机变量等于154的概率密度。
qnorm(0.95, mean = 161, sd = 7)计算的是在一个均值为161,标准差为7的正态分布中,累积概率等于0.95的分位数值。简单来说,这意味着找到一个数值,使得在该正态分布下,随机变量小于或等于这个数值的概率为95%。
(r/p/d/q)的含义
在R语言中处理概率分布函数时,函数名的首字母d、p、r、和q分别代表不同的含义:
-
d stands for density.
d开头的函数计算给定点的概率密度(对于连续分布)或概率质量(对于离散分布)。 -
p stands for probability.
p开头的函数计算累积分布函数(CDF),即随机变量小于或等于某个值的概率。 -
q stands for quantile.
q开头的函数计算分位数,即给定概率对应的随机变量的值。 -
r stands for random generation.
r开头的函数用于生成符合该分布的随机数。
replicate
replicate(1000, sample(die, 5, replace=TRUE)这段代码的含义是:
- `sample(die, 5, replace=TRUE)`:从`die`向量中随机抽取5个数字,抽取时允许重复(即一个数字可以被抽取多次),模拟掷骰子5次的结果。
- `replicate(1000, ...)`:重复上述抽取操作1000次,模拟掷骰子5次的操作一共进行1000轮。
这段代码的结果是一个矩阵,其中每一列代表一次模拟的结果,矩阵有5行(对应于每次模拟中的5次掷骰子),1000列(对应于进行的1000次模拟)。
这种模拟方法在统计学和概率论中非常有用,可用于估算各种事件的概率,比如“在掷骰子5次中至少得到一个6的概率是多少?”通过对模拟结果进行分析和计算,可以得到相应的概率估计。
dpois
dpois(5, lambda = 8)在R语言中,`dpois`函数用于计算泊松分布的概率质量函数(PMF)。这个函数的参数包括:
- 第一个参数是事件发生的次数,在这个例子中是5。
- `lambda`是平均发生率(即平均在一个给定的时间间隔或空间区域内事件发生的次数),在这个例子中是8。
因此,`dpois(5, lambda = 8)`计算的是在平均发生率为8的泊松分布中,恰好发生5次事件的概率。
简单来说,这意味着如果平均情况下某事件在给定的时间间隔内发生8次,那么这段时间内该事件恰好发生5次的概率是多少。
ppois
ppois(5, lambda = 8)在R语言中,`ppois`函数用于计算泊松分布的累积分布函数(CDF)。这个函数的参数包括:
- 第一个参数是事件发生的次数上界,在这个例子中是5。
- `lambda`是平均发生率(即平均在一个给定的时间间隔或空间区域内事件发生的次数),在这个例子中是8。
- 可以有第三个参数, lower.tail = FALSE, 则可以计算超过的概率
因此,`ppois(5, lambda = 8)`计算的是在平均发生率为8的泊松分布中,事件发生次数小于或等于5的累积概率。
简单来说,这意味着如果平均情况下某事件在给定的时间间隔内发生8次,那么这段时间内该事件发生次数不超过5次的概率是多少。
rpois
rpois(10, lambda = 8)`rpois(10, lambda = 8)`生成了一个随机数列,这些随机数根据泊松分布模拟了某事件发生的次数。
pexp
pexp(1, rate = 0.5)某服务的平均服务时间为2分钟,返回等待时间小于或等于1分钟的概率,根据指数分布的性质。
应用场景
指数分布在多种领域有应用,如:
- 描述无记忆性的等待时间,例如无线电元件的失效时间、顾客在银行排队等待的时间。
- 风险评估和可靠性工程中,估计产品或系统发生故障之前的预期寿命。
- 网络流量分析,评估数据包到达过程的特性。
通过使用`pexp`函数,可以基于已知的服务率或事件发生率来估计特定时间内事件发生的概率,从而在规划和管理中做出更为明智的决策。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









