







本章主要是学习《大规模语言模型——从理论到实战》第八章内容的一个总结。
8.3 大语言模型评估方法
在大语言模型评估体系和数据集合构建的基础上,评估方法需要解决如何评估大模型的问题, 包括:
- 采用哪些评测指标。
- 如何进行评估等问题。
8.3.1 评估指标
本节分别针对分类任务、回归任务、 语言模型、文本生成等不同任务所使用的评测指标,以及大语言模型评测指标体系进行介绍。
1. 分类任务评估指标
分类任务(Classification)是将输入样本分为不同的类别或标签的机器学习任务。
分类任务通常采用精确度(Precision)、召回率(Recall)、准确率(Accuracy)、PR 曲线等指标,利用测试语料,根据系统预测结果与真实结果之间的对比,计算各类指标对算法性能进行评估。
方法举例:使用混淆矩阵(Confusion Matrix)对预测结果和真实结果之间的对比情况进行表示。如图8.9 所示:
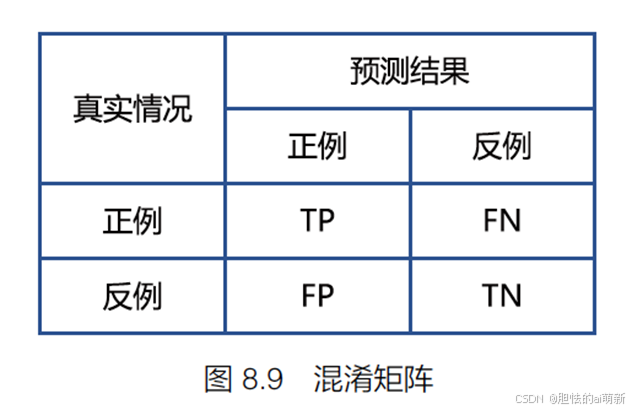
其中,TP(True Positive,真阳性)表示被模型预测为正的正样本;FP(False Positive,假阳性)表示被模型预测为正的负样本;FN(False Negative,假阴性)表示被模型预测为负的正样本;TN(True Negative,真阴性)表示被模型预测为负的负样本。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。
根据混淆矩阵,常见的分类任务评估指标定义如下:
- 准确率(Accuracy):表示分类正确的样本占全部样本的比例。具体计算公式如下:
![]()
- 精确度(Precision,P):表示分类预测是正例的结果中,确实是正例的比例。精确度也称查准率、准确率,具体计算公式如下:
![]()
- 召回率(Recall,R):表示所有正例的样本中,被正确找出的比例。召回率也称查全率,具体计算公式如下:
![]()
- F1 值(F1-Score):是精确度和召回率的调和均值。具体计算公式如下:
![]()
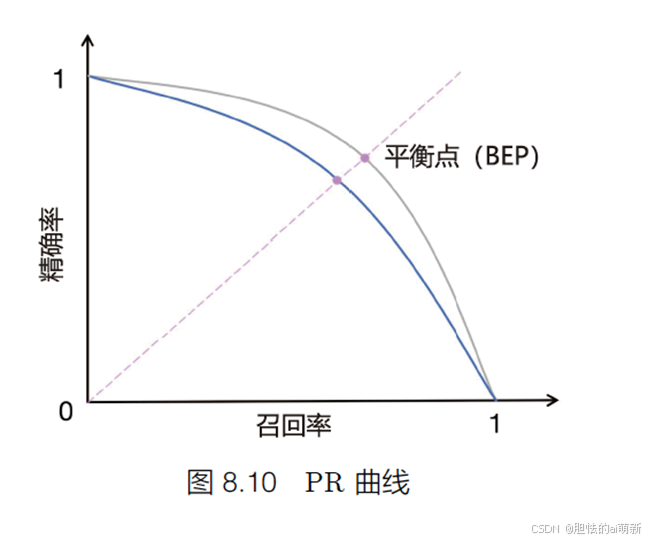
- PR 曲线(PR Curve):PR 曲线的横坐标为召回率 R,纵坐标为精确度 P,绘制步骤如下:
(1) 将预测结果按照预测为正类概率值排序;
(2) 将概率阈值由 1 开始逐渐降低,逐个将样本作为正例进行预测,并计算出当前的 P,R 值;
(3) 以精确度 P 为纵坐标,召回率 R 为横坐标绘制点,将所有点连成曲线后构成 PR 曲线。
如图8.10所示。平衡点(Break-Even Point,BPE) 为精确度等于召回率时的取值,值越大代表效果越优。
2. 回归任务评估指标
回归任务(Regression)是根据输入样本预测一个连续的数值的机器学习任务。
回归任务的评估指标主要目标是衡量模型预测数值与真实值之间的差距,主要评估指标定义如下:
- 平均绝对误差(Mean Absolute Error,MAE)表示真实值与预测值之间绝对误差损失的预期 值。具体计算公式如下:
![]()
- 平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)表示真实值与预测值之间相 对误差的预期值,即绝对误差和真值的百分比。具体计算公式如下:
![]()
- 均方误差(Mean Squared Error,MSE)表示真实值与预测值之间平方误差的期望。具体计算 公式如下:
![]()
- 均方误差根(Root Mean Squared Error,RMSE)表示真实值与预测值之间平方误差期望的平方根。具体计算公式如下:
![]()
- 均方误差对数(Mean Squared Log Error,MSLE)表示对应真实值与预测值之间平方对数差 的预期,MSLE 对于较小的差异给予更高的权重。具体计算公式如下:
![]()
- 中位绝对误差(Median Absolute Error,MedAE)表示真实值与预测值之间绝对差值的中值。 具体计算公式如下:
![]()
3. 语言模型评估指标
语言模型最直接的测评方法就是使用模型计算测试集的概率,或者利用交叉熵(Cross-entropy) 和困惑度(Perplexity)等派生测度。
法一:计算测试集的概率
- 对于一个平滑过的
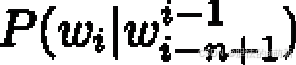 n 元语言模型,可以用下列公式计算句子P(s) 的概率:
n 元语言模型,可以用下列公式计算句子P(s) 的概率:
![]()
- 对于由句子(s1, s2, . . . , sn) 组成的测试集 T,可以通过计算 T 中所有句子概率的乘积来得到整个测试集的概率:
![]()
法二:交叉熵
交叉熵测度则利用预测和压缩的关系进行计算。对于n 元语言模型![]() ,文本s 的概率为P(s),在文本 s 上,n 元语言模型
,文本s 的概率为P(s),在文本 s 上,n 元语言模型![]() 的交叉熵为:
的交叉熵为:
![]()
其中,Ws 为文本 s 的长度,该公式可以解释为:利用压缩算法对s 中的Ws 个词进行编码,每一个编码所需要的平均比特位数。
法三:困惑度
困惑度的计算可以视为模型分配给测试集中每一个词汇的概率的几何平均值的倒数,它和交叉熵的关系为:
![]()
交叉熵和困惑度越小,语言模型性能就越好。不同的文本类型其合理的指标范围是不同的,对于英文来说,n 元语言模型的困惑度约在 50 到 1000 之间,相应的,交叉熵在 6 到 10 之间。
4. 文本生成评估指标
自然语言处理领域常见的文本生成任务包括机器翻译、摘要生成等。由于语言的多样性和丰 富性,需要按照不同任务分别构造自动评估指标和方法。
Ⅰ. 机器翻译任务:
在机器翻译任务中, 通常使用 BLEU(Bilingual Evaluation Understudy)[用于评估模型生成 的翻译句子和参考翻译句子之间差异的指标。一般用 C 表示机器翻译的译文,另外还需要提供m个参考的翻译 S1, S2, ..., Sm。
BLEU 核心思想就是衡量机器翻译产生的译文和参考翻译之间的匹配程度,机器翻译越接近专业人工翻译质量就越高。BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。
BLEU 基本原理是统计机器产生的译文中的词汇有多少个出现在参考译文中,从某种意义上说是一种精确度的衡量。BLEU 的整体计算公式如下:
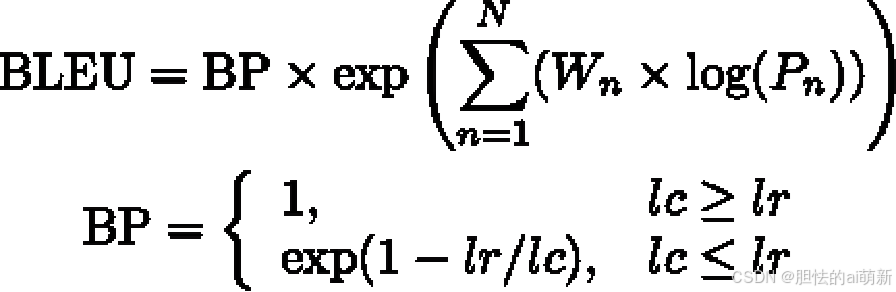
其中,Pn 表示n-gram 翻译精确率;Wn 表示n-gram 翻译精确率的权重(一般设为均匀权重,即 Wn = 1/N) ;BP 是惩罚因子,如果机器翻译的长度小于最短的参考翻译,则BP 小于1;lc 为机器翻译长度,lr 为最短的参考翻译长度。
给定机器翻译译文C,m 个参考翻译S1, S2, · · · , Sm,Pn 一般采用修正n-gram 精确率,计算公式如下:
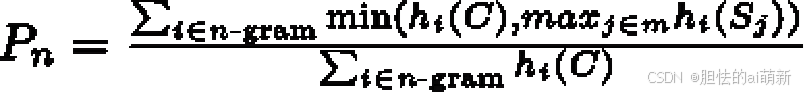
其中,i 表示 C 中第 i 个n-gram;hi(C) 表示n-gram i 在C 中出现的次数;hi(Sj) 表示n-grami 在参考译文Sj 中出现的次数。
Ⅱ. 文本摘要任务
文本摘要采用 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评估方法,该方法也称为面向召回率的要点评估,是文本摘要中最常用的自动评价指标之一。
ROUGE 与机器 翻译的评价指标 BLEU 的类似,能根据机器生成的候选摘要和标准摘要(参考答案)之间词级别 的匹配来自动为候选摘要评分。ROUGE 包含一系列变种:有ROUGE-N,ROUGE-L等。
ROUGE-N:
ROUGE-N是应用最广泛的,它统计了 n-gram 词组的召回率,通过比较标准摘要和候选摘要来计算 n-gram 的结果。通过比较标准摘要和候选摘要来计算n-gram 的结果。给定标准摘要集合S = {Y1, Y2, · · · , YM} 及候选摘要ˆY ,则ROUGE-N 的计算公式如下:
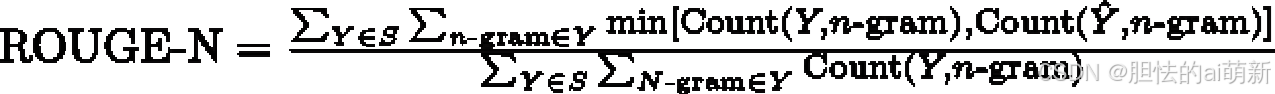
其中n-gram 是Y 中所有出现过的长度为n 的词组,Count(Y, n-gram) 是Y 中n-gram 词组出现的次数。
举例:下面以两段摘要文本为例给出ROUGE 分数的计算过程:候选摘要ˆ Y = {a dog is in the garden},标准摘要Y = {there is a dog in the garden}。可以按照公式(8.18)计算ROUGE-1 和ROUGE-2的分数为:
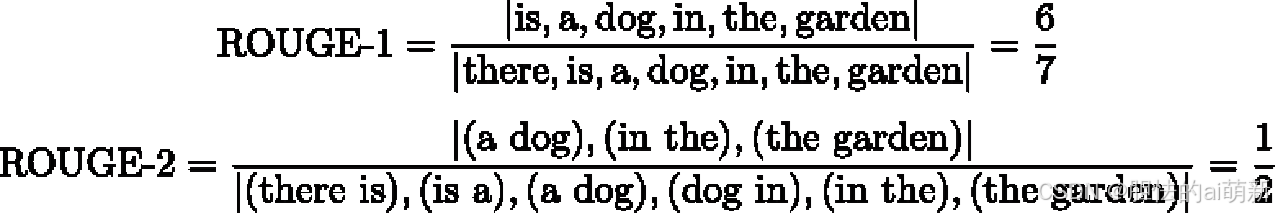
注意:ROUGE 体现的是标准摘要中有多少 n-gram 出现在候选摘要中,而 BLEU 体现了候选翻译中有多少 n-gram 出现在标准翻译中。
ROUGE-L:
ROUGE-L,它不再使用 n-gram 的匹配,而改为计算标准摘要与候选摘要之间的最长公共子序列,从而支持非连续的匹配情况,因此无需预定义 n-gram 的长度超参数。ROUGE-L 的计算公式如下:
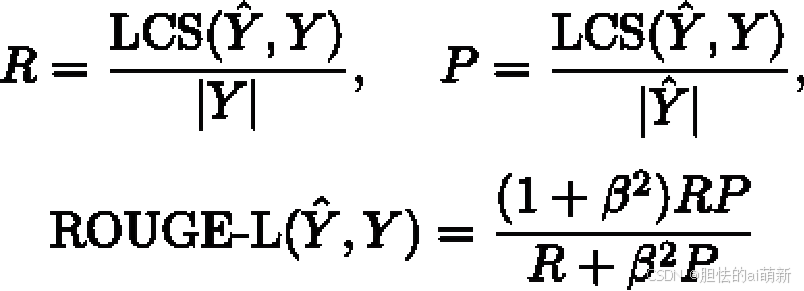
其中, ˆY 表示模型输出的候选摘要,Y 表示标准摘要。| Y | 和| ˆY | 分别表示摘要Y 和ˆ Y 的长度,LCS( ˆY , Y ) 是 ˆY 与Y 的最长公共子序列长度,R 和P 分别为召回率和精确率,ROUGE-L 是两者的加权调和平均数,β 是召回率的权重。在一般情况下,β 会取很大的数值,因此ROUGE-L会更加关注召回率。
举例:还是以上面的两段文本为例,可以计算其 ROUGE-L 如下:
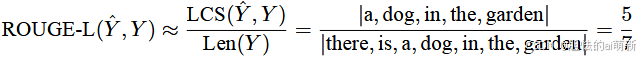
5. 大语言模型评估指标体系
为更全面地评估大语言模型所生成的文本质量,需要从三方面开展评估,包括:语言层面、语义 层面和知识层面。
语言层面
语言层面是评估大语言模型所生成文本的基础指标,要求生成的文本必须符合人类通常语言习 惯。这意味着生成的文本必须具有正确的词法、语法和篇章结构。具体而言:
Ⅰ. 词法正确性
评估生成文本中单词的拼写、使用和形态变化是否正确。确保单词的拼写准确 无误,不含有拼写错误。同时,评估单词的使用是否恰当,包括单词的含义、词性和用法等 方面,以确保单词在上下文中被正确应用。此外,还需要关注单词的形态变化是否符合语法 规则,包括时态、数和派生等方面。
Ⅱ. 语法正确性
评估生成文本的句子结构和语法规则的正确应用。确保句子的构造完整,各个 语法成分之间的关系符合语法规则。包括主谓关系、动宾关系、定状补关系等方面的准确应 用。此外,还需要评估动词的时态是否正确使用,包括时态的一致性和选择是否符合语境。
Ⅲ. 篇章正确性
评估生成文本的整体结构是否合理。确保文本段落之间的连贯性,包括使用恰 当的主题句、过渡句和连接词等,使得文本的信息流畅自然。同时,需要评估文本整体结构 的合理性,包括标题、段落、章节等结构的使用是否恰当,以及文本整体框架是否清晰明了。
语义层面
语义层面的评估主要关注文本的语义准确性、逻辑连贯性和风格一致性。要求生成的文本不出 现语义错误或误导性描述,并且具有清晰的逻辑结构,能够按照一定的顺序和方式组织思想并呈现出来。具体而言:
Ⅰ. 语义准确性
评估文本是否传达了准确的语义信息。包括词语的确切含义和用法是否正确,以 及句子表达的意思是否与作者的意图相符。确保文本中使用的术语、概念和描述准确无误, 能够准确传达信息给读者。
Ⅱ. 逻辑连贯性
评估文本的逻辑结构是否连贯一致。句子之间应该有明确的逻辑关系,能够形 成有条理的论述,文本中的论证、推理、归纳、演绎等逻辑关系正确。句子的顺序应符合常 规的时间、空间或因果关系,以便用户能够理解句子之间的联系。
Ⅲ. 风格一致性
评估文本在整体风格上是否保持一致。包括词汇选择、句子结构、表达方式等方 面。文本应该在整体上保持一种风格或口吻。例如,正式文档应使用正式的语言和术语,而 故事性的文本可以使用生动的描写和故事情节。
知识层面
知识层面的评估主要关注知识准确性、知识丰富性和知识一致性。要求生成文本所涉及到的知 识准确无误、丰富全面,并且保持一致性,确保生成文本的可信度。具体而言:
Ⅰ. 知识准确性
评估生成文本中所呈现的知识是否准确无误。这涉及到事实陈述、概念解释、历 史事件等方面。生成的文本应基于准确的知识和可靠的信息源,避免错误、虚假或误导性的 陈述。确保所提供的知识准确无误。
Ⅱ. 知识丰富性
评估生成文本所包含的知识是否丰富多样。生成的文本应能够提供充分的信息, 涵盖相关领域的不同方面。这可以通过提供具体的例子、详细的解释和相关的背景知识来实 现。确保生成文本在知识上具有广度和深度,能够满足读者的需求。
Ⅲ. 知识一致性
评估生成的文本中知识的一致性。这包括确保文本中不出现相互矛盾的知识陈 述,避免在不同部分或句子中提供相互冲突的信息。生成的文本应该在整体上保持一致,使 读者能够得到一致的知识体系。
8.3.2 评估方法
评估方法的目标是解决如何对大语言模型生成结果进行评估的问题。
- 自动评估(Automatic Evaluation):可以通过比较正确答案或参考答案与系统生成结果来直接计算得出,例如准确率、召回率等。
- 人工评估(Human Evaluation):并不是直接 可以计算的,而需要通过人工评估来得出,例如文章的流畅性、逻 辑性、观点表达等方面的评估则需要人工阅读并进行分项打分。
- 大语言模型评估:利用能力较强的语言模型(如 GPT-4),构建合适的指令来评估系统结果。这种评估方法 可以大幅度减少人工评估所需的时间和人力成本具有更高的效率。
- 对比评估(Comparative Evaluation):对比不同系统之间或者系统不同版本的差别,针对系统之间的不同进行量化。
1. 人工评估
人工评估是一种广泛应用于评估模型生成结果质量和准确性的方法,它通过人类参与来对生成结果进行综合评估。
优点:
- 与自动化评估方法相比,人工评估更接近实际应用场景,并且可以提供更全面和准确的反馈。
- 人工评估中,评估者可以对大语言模型生成结果整体质量进行评分,也可以根据评估体系从语言层面、语义层面以及知识层面等不同方面进行细粒度评分。
- 人工评估还可以对不同系统之间的优劣进行对比评分,从而为模型的改进提供有力支持。
缺点:
- 由于人的主观性和认知差异,评估结果可能存在一定程度的主观性。
- 人工评估需要大量的时间、精力和资源,因此成本较高,而且评价的周期长,不能及时得到有效的反馈。
- 评估者的数量和质量也会对评估结果产生影响。
人工评估是一种常用于评估自然语言处理系统性能的方法。通常涉及五个层面:评估人员类型、评估指标度量、是否给定参考和上下文、绝对还是相对测评以及评估者是否提供解释。
Ⅰ. 评估人员类型
评测人员种类是指评测任务由哪些人来完成。常见的评测人员包括领域专家、众包工作者和 最终使用者。领域专家对于特定领域的任务具有专业知识和经验,可以提供高质量的评测结果。众包工作者通常是通过在线平台招募的大量非专业人员,可以快速地完成大规模的评测任务。最终使用者是指系统的最终用户,他们的反馈可以帮助开发者了解系统在实际使用中的表现情况。
Ⅱ. 评估指标度量
评估指标度量是指根据评估指标所设计的具体度量方法。常用的评估度量包括李克特量表 (Likert Scale),它为生成结果提供不同的标准,分为几个不同等级,可以用于评估系统的语言流畅度、语法准确性、结果的完整性等方面。
Ⅲ. 是否给定参考和上下文
是否给定参考和上下文是指提供与输入相关的上下文或输出的参考,这有助于评估语言流畅度、语法以外的性质,比如结果的完整性和正确性。对于非专业人员来说很难仅从输出结果判断流畅性以外的其他性能,因此提供参考和上下文可以帮助评估人员更好地理解和评估系统性能。
Ⅳ. 绝对还是相对测评
绝对还是相对测评是指将系统输出与参考答案进行比较,还是与其他系统对比。绝对测评是指将系统输出与单一参考答案进行比较,可以评估系统的各维度的能力。相对测评是指同时对多个系统输出进行比较,可以评估不同系统之间的性能差异。
Ⅴ. 评估者是否提供解释
评估者是否提供解释是指是否要求评估人员为自己的决策提供必要的说明。提供决策的解释 说明有助于开发者了解评测过程中的决策依据和评估结果的可靠性,从而更好地优化系统性能。但是缺点是极大地增加了评估人员的时间花费。
对于每个数据,通常会有多个不同人员进行评估,因此需要一定的方法整合最终评分。
Ⅵ. 整合最终评分的方法:
- 平均主观得分
最简单的最终评分整合方法是平均主观得分(Mean Opinion Score, MOS),即将所有评估人员的分数进行平均:
![]()
其中,N 为评估者人数,Si 为第 i 个评估者给出的得分。
- 中位数法
中位数法:将所有分数按大小排列,取中间的分数作为综合分数。中位数可以避免极端值对综合分数的影响,因 此在数据分布不均匀时比平均值更有用;
- 最佳分数法
最佳分数法:选择多个分数中的最高得分作为综合分数。这种方法可以在评估中强调最佳性能,并且在只需要比较最佳结果时非常有用;
- 多数表决法
多数表决法:将多个分数中出现次数最多的分数作为综合分数。这种方法适用于分类任务,其中每个分数代表一个类别。
由于数据由多个不同评估者进行标注,因此不同评估者之间的评估的一致性也是需要关注的因素。评估者间一致性 (Inter-Annotator Agreement,IAA)是评估不同评估者之间达成一致的程度的度量标准。一些常用的 IAA 度量标准包括一致性百分比(Percent Agreement)、Cohen’s Kappa、Fleiss’ Kappa 等。这些度量标准计算不同评估者之间的一致性得分,并将其转换为 0 到 1 之间的值。得分越高,表示评估者之间的一致性越好。
- 一致性百分比
一致性百分比(Percent Agreement)用以判定所有评估人员一致同意的程度。使用 X 表示待 评估的文本,|X| 表示文本的数量,ai 表示所有评估人员对 xi 的评估结果的一致性,当所有评估人员评估结果一致时,ai = 1,否则等于 0。一致性百分比可以形式化表示为:
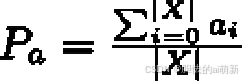
- Cohen’s Kappa
Cohen’s Kappa是一种用于度量两个评估者之间一致性的统计量。Cohen’s Kappa 的值在-1 到 1 之间,其中 1 表示完全一致,0 表示随机一致,而-1 表示完全不一致。通常情况 Cohen’s Kappa 的值在 0 到 1 之间。具体来说,Cohen’s Kappa 计算公式为:
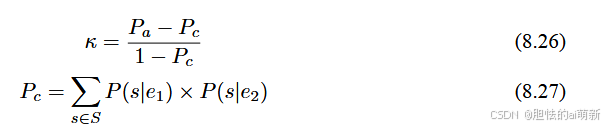
其中,e1 和 e2 表示两个评估人员,S 表示对数据集 X 的评分集合,P (s|ei) 表示评估人员 i 给出分数 s 的频率估计。一般来说,Kappa 值在 0.6 以上被认为一致性较好,而在 0.4 以下则 被认为一致性较差。
- Fleiss’ Kappa
Fleiss’ Kappa是一种用于度量三个或以上评价者之间一致性的统计量,它是 Cohen’s Kappa 的 扩展版本。与 Cohen’s Kappa 只能用于两个评价者之间的一致性度量不同,Fleiss’ Kappa 可以用于多个评价者之间的一致性度量。Fleiss’ Kappa 的值也在-1 到 1 之间,其中 1 表示完全一致,0 表示随机一致,而-1 表示完全不一致。
具体来说,Fleiss’ Kappa 计算与公式 8.26 相同,但是其 Pa 和 Pc 的计算则需要扩展为三个以上评估者的情况。使用 X 表示待评估的文 本,|X| 表示文本总数,n 表示评估者数量,k 表示评价类别数。文本使用 i = 1, ...|X| 进行 编号,打分类别使用 j = 1, ..., k 进行编号,则 nij 表示有多少标注者对第 i 个文本给出了第 j 类评价。Pa 和 Pe 可以形式化的表示为:
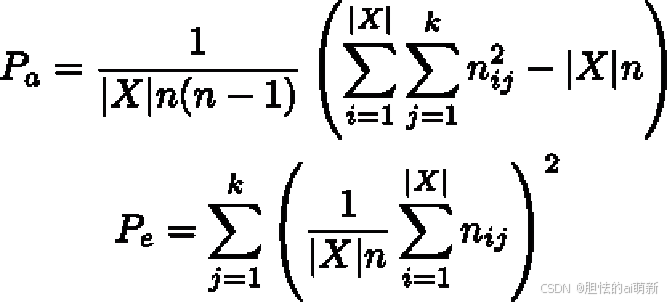
一般来说,与Cohen’s Kappa 一样,Cohen’s Kappa 值在0.6 以上被认为一致性较好,而在0.4 以下则被认为一致性较差。需要注意的是,Fleiss’ Kappa 在评估者数量较少时可能不太稳定,因此在使用之前需要仔细考虑评估者数量的影响。
2. 大语言模型评估
传统的基于参考文本的度量指标,如 BLEU 和 ROUGE,与人工评估之间的相关性不足、对于需要创造性和多样性的任务,也无法提供有效的参考文本。为了解决上述问题,最近的一些研究提出可以采用大型语言模型进行自然语言生成任务的进行评价。而且这种方法还可以可以应用于缺乏参考文本的任务。使用大语言模型进行结果评估过程如图8.11所示:
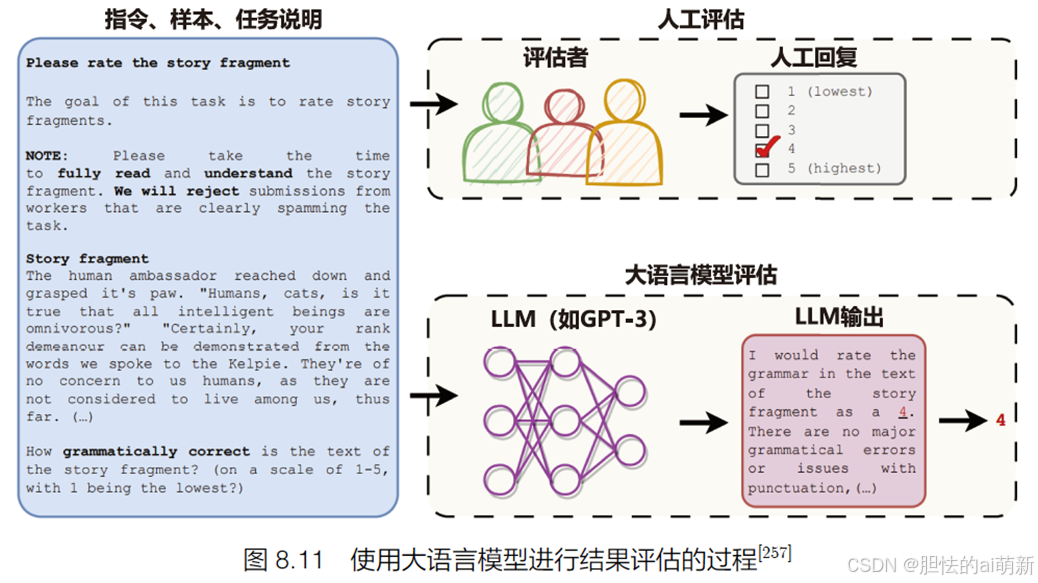
使用大语言模型进行评估的过程比较简单,例如针对文本质量判断问题,将任务说明、待评估样本以及对大语言模型的指令,该指令要求大语言模型采用 5 级李克特量表法,对给定的待评估样本质量进行评估。给定这些输入,大语言模型将通过生成一些输出句子来回答问题。通过解析输出句子以获取评分。不同的任务使用不同的任务说明集合,并且每个任务使用不同的问题来评估样本的质量。
3. 对比评估
对比评估的目标是比较不同系统、方法或算法在特定任务上是否存在显著差异。
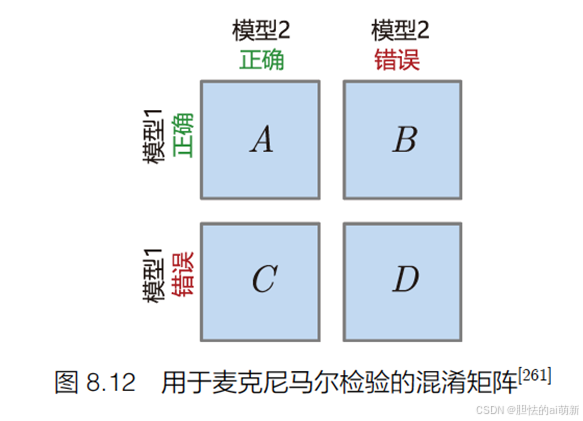
麦克尼马尔检验(McNemar Test)是由 Quinn McNemar 于1947年提出的一种用于成对比较的非参数统计检验, 可以应用于比较两个机器学习分类器的性能。麦克马纳检验也被称为“被试内卡方检验”(withinsubjects chi-squared test),它基于 2 × 2 混淆矩阵(Confusion Matrix),有时也称为 2 × 2 列联表 (Contingency Table),用于比较两个模型之间的预测结果。
给定如图8.12 所示的用于麦克尼马尔检验的混淆矩阵,可以得到模型1 的准确率为A+B / A+B+C+D,模型2 的准确率为A+C / A+B+C+D。这个矩阵中最重要的数字是B 和C,反映了两个模型之间的差异。
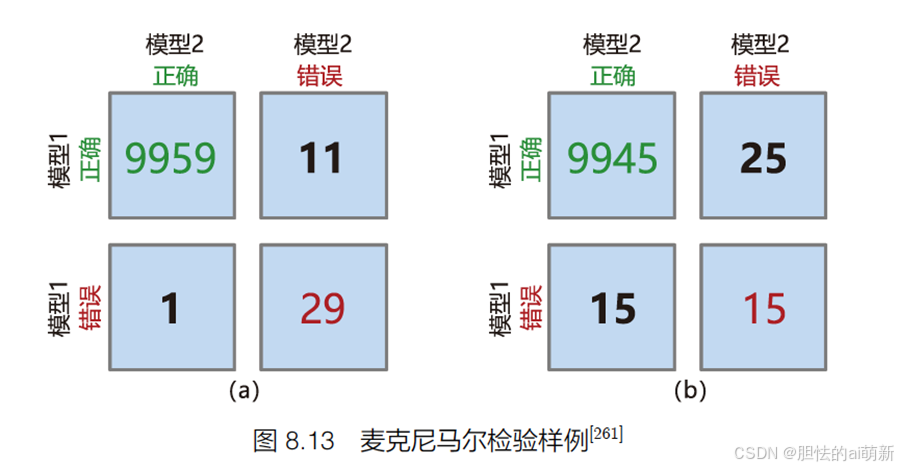
样例:
根据图8.13(a) 和8.13(b),可以计算得到模型1 和模型2 在两种情况下的准确率分别为99.7% 和99.6%。但是根据图8.13(a),可以看到模型1 回答正确且模型2回答错误的数量为11,但是反过来模型2 回答正确但模型1 回答错误的数量仅为1。在图8.13(b)中,这两个数字变成了25 和15。显然,图8.13(b) 中的模型1 与模型2 之间的差异更大,图8.13(a) 中的模型1 与模型2 之间的差异则没有这么明显。
为了量化表示上述情况,麦克尼马尔检验中提出的零假设是概率p(B) 与p(C) 相等,即两个模型都没有表现得比另一个好。麦克尼马尔检验的统计量(“卡方值”)具体计算公式如下:
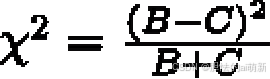
设定显著性水平阈值(例如α = 0.05)之后,可以计算得到p−value(p 值)。如果零假设为真,则p 值是观察这个经验(或更大的)卡方值的概率。如果p 值小于预先设置的显著性水平阈值,可以拒绝两个模型性能相等的零假设。换句话说,如果p 值小于显著性水平阈值,可以认为两个模型的性能不同。
在上述公式的基础上,还有一个连续性修正版本,这也是目前更常用的变体:
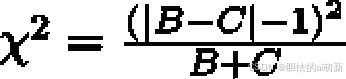
当B 和C 的值大于50 时,麦克尼马尔检验可以相对准确地近似计算p 值,如果B 和C 的值相对较小(B + C < 25),则建议使用以下二项式检验公式计算p 值:
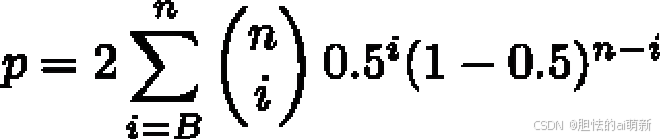
其中n = B + C,因子2 用于计算双侧p 值(Two-sided p-value)。

















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









