






C++(进阶) 第8章unordered_map和unordered_set的使⽤
文章目录
前言
unordered其实就是哈希,但是c+之前map和set取名没有弄好不像java里面一样的叫tree_map,tree_set,hash_map,hash_set
其实他们就是同一个 东西只是名字不一样
unordered->无序的,它和map和set功能是一样的但是底层实现不一样,中序遍历也并不是有序的
提示:以下是本篇文章正文内容,下面案例可供参考
一、unordered_set
1.文档
先来看看文档
https://legacy.cplusplus.com/reference/unordered_set/

感兴趣的可以看看文档,set和unordered_set他们的功能其实基本都是一模一样,百分之90功能是一样的,不同的就是底层一个是红黑树,一个是哈希表
2.unordered_set 和set的区别
这里可以看到下面一个遍历是有序的一个是无序的

从性能上看set底层是搜索树也就说set查找是log n,unordered_ set 的时间复杂度就是O(1)了
是什么概念呢假设find一个10亿个的数据
o log n ->需要30次
o(1)->只需要3-5次左右即可找到
然后其实unordered_map和map其实基本都是一样
二、什么是哈希什么是哈希表
1.哈希
哈希其实就是一种映射关系,哈希也叫散列
哈希就是一种值和存储位置的映射关系,可能是1对多,也有可能是1对1
准确的来说哈希是一种思想
大概可以这么玩
1.直接地址法
假设有:
1,2,3,4,5,6这里可以开一个数组
只需要开6个数组就可以进行一一对应
这里只需要用下标直接去访问就行了
所以这里的时间复杂度是o(1)
但是假如说
现在是:1,2,3,4,5,6,10000
难道这里直接创建一个10000大小的数组去映射这个7个数组吗?
这里显然是浪费了大量的空间
所以说哈希适合数据比较集中的数据
这里可以发现值和存储位置是一一对应的
2.除留余数法
hashi = key % N(这里N是表的大小)
上面%的值在表上就一定会找到一个映射的值
假如还是上面的例子

10000 % 10 也就是0,也就是说这里10000的映射就在0那个位置
但是这里有就会有一个新的问题,这里已经不是一一对应了这里的10和10000是在同一个位置
ok那么这里就会出现一个新的问题了。这里该怎么样用下标去访问呢?这里就会有一个冲突的问题
这个就是叫哈希碰撞/哈希冲突----不同的值可以会映射到相同的位置
怎么解决哈希冲突
1.闭散列——开放定址法
这里会按照规则去找其他空的位置,这里又会有俩种方式
a->线性探测---- 当前位置+1,+2, +3…… 本质是+i
b->二次探测----当前位置+1的二次方+2的二次方+3的二次方…
举个例子:
假如这里10已经映射到了0哪里了,然后继续20,但是这里20也是0,这时候就会往后面挪


然后继续插入剩下的数,直到10000来了,就继续在20的后面

假如这里在插入一个17,但这里7的位置已经给占了,后面的也给占了这里就只能这样了

这里并不会出现找不到的位置,这里会有一个负载因子的东西来控制,这个后面在介绍
那这里该怎么查找呢?
还是上面的例子假如现在我要查找


这里查找了以后就会发现16不在这,这里是35,那么这里就接着往后找直到找到为止
如果这里继续查找26,但是这里一直都是找不到的,只有遇到空才能确定找不到
但是这里又会遇到一个问题,假如这里先删除66在查找16这里就会直接遇到空也就是删除会影响查找,但又没办法直接遍历这个表,那样就没有意义

这里的解决方案是每个位置给一个状态标记

√就是有
-就是空
x就可以是删除以后的
就比如这样

2.开散列——哈希桶
哈希桶其实就是从原来的数组变成了指针数组

3.代码实现
1.基本框架
#define _CRT_SECURE_NO_WARNINGS
#include<bits/stdc++.h>
using namespace std;
enum State
{
EXIST,
EMPTY,
DELETE
};
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
State _state = EMPTY;
};
template<class K,class V>
class HashTable
{
private:
vector<HashData<K,V>> _tables;
};
int main()
{
return 0;
}
2.Insert
下面是插入的基本框架
bool Insert(const pair<K, V>& kv)
{
//扩容
size_t HashIndex = kv.first % _tables.size();
while (_tables[HashIndex]._state == EXIST)
{
++HashIndex;
HashIndex = HashIndex % _tables.size();
}
_tables[HashIndex] = kv;
_tables[HashIndex]._state = EXIST;
}
一直插入值那么这个哈希表就一定会满,满了就要扩容,而已就算不满一个哈希表存的值越多哈希冲突的概率就越大,这个时候就会引入一个负载因子的概念

简单点就是数据的个数除以表的个数
所以在类成员里面还需要在加一个东西来纪录这个表里面存了多少个数据就像这样

size_t HashIndex = kv.first % _tables.size();
while (_tables[HashIndex]._state == EXIST)
{
++HashIndex;
HashIndex = HashIndex % _tables.size();
}
_tables[HashIndex]._kv = kv;
_tables[HashIndex]._state = EXIST;
++_n;
return 1;
}
但是这里扩容以后又会有新的问题,所以不能这样直接的扩容会出现很多问题

扩容就可以这样写
bool Insert(const pair<K, V>& kv)
{
//扩容
if (_n * 10 / _tables.size() >= 7)
{
HashTable<K, V> newHT;
newHT._tables.resize(_tables.size() * 2);
for (int i = 0; i < _tables.size(); i++)
{
if (_tables[i]._state == EXIST)
{
newHT.Insert(_tables[i]._kv);
}
}
_tables.swap(newHT._tables);
}
size_t HashIndex = kv.first % _tables.size();
while (_tables[HashIndex]._state == EXIST)
{
++HashIndex;
HashIndex = HashIndex % _tables.size();
}
_tables[HashIndex]._kv = kv;
_tables[HashIndex]._state = EXIST;
++_n;
return 1;
}
去冗余
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
{
return false;
}
//扩容
if (_n * 10 / _tables.size() >= 7)
{
HashTable<K, V> newHT;
newHT._tables.resize(_tables.size() * 2);
for (int i = 0; i < _tables.size(); i++)
{
if (_tables[i]._state == EXIST)
{
newHT.Insert(_tables[i]._kv);
}
}
_tables.swap(newHT._tables);
}
size_t HashIndex = kv.first % _tables.size();
while (_tables[HashIndex]._state == EXIST)
{
++HashIndex;
HashIndex = HashIndex % _tables.size();
}
_tables[HashIndex]._kv = kv;
_tables[HashIndex]._state = EXIST;
++_n;
return 1;
}
3.Find
HashData<K, V>* Find(const K& key)
{
size_t HashIndex = key % _tables.size();
while (_tables[HashIndex]._state != EMPTY)
{
if (_tables[HashIndex]._state == EXIST &&
_tables[HashIndex]._kv.first == key)
{
return &_tables[HashIndex];
}
++HashIndex;
HashIndex = HashIndex % _tables.size();
}
return nullptr;
}
4.Erase
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret == nullptr)
{
return false;
}
ret->_state = DELETE;
return true;
}
但是呢上面的代码是还有问题的
因为这里取%变成了字符,这里根本就取不了

关于这个问题已经可以看看大佬的解决方式
cnblogs.com/-clq/archive/2012/05/31/2528153.html
2.库里面的实现(重点)
上面的那些代码都是开放定址法
这里写的是哈希桶,库里面也是用这种方法
1.基本框架
用图片表达就是这样的
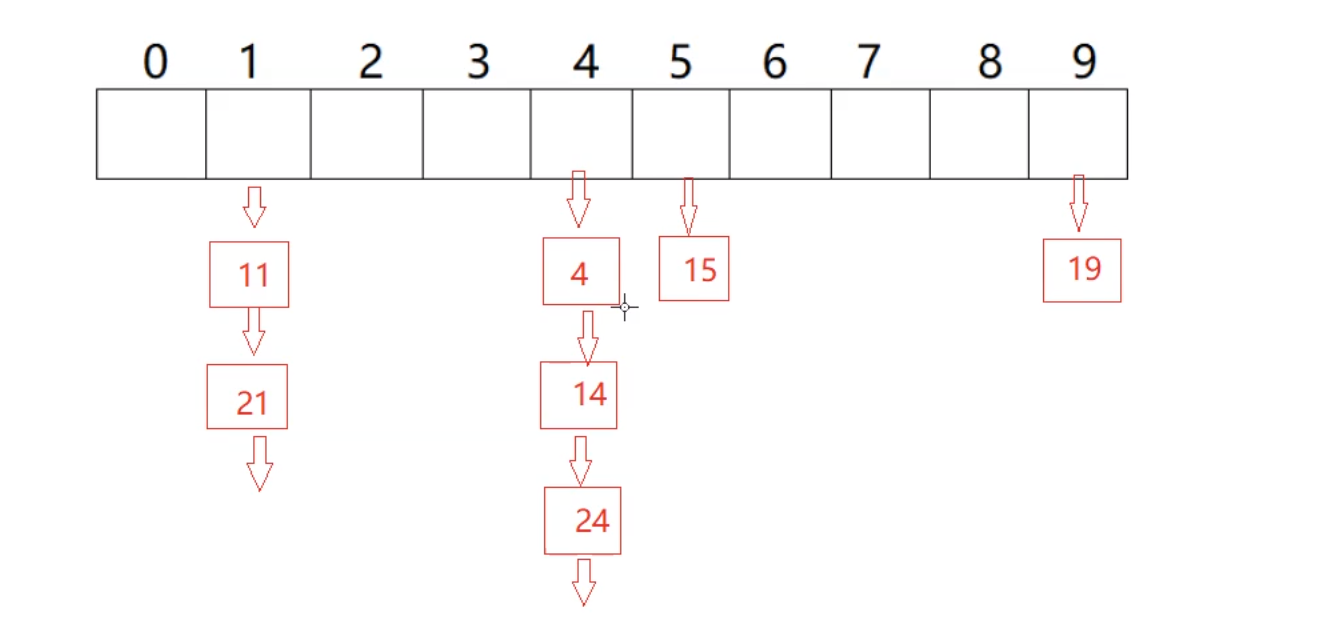
#define _CRT_SECURE_NO_WARNINGS
#include<bits/stdc++.h>
using namespace std;
template<class K,class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
};
template<class K,class V>
class HashTable
{
typedef HashNode<K, V> Node;
public:
HashTable()
{
_tables.resize(10, nullptr);
}
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
private:
vector<Node*> _tables;
size_t _n = 0;
};
2.Insert
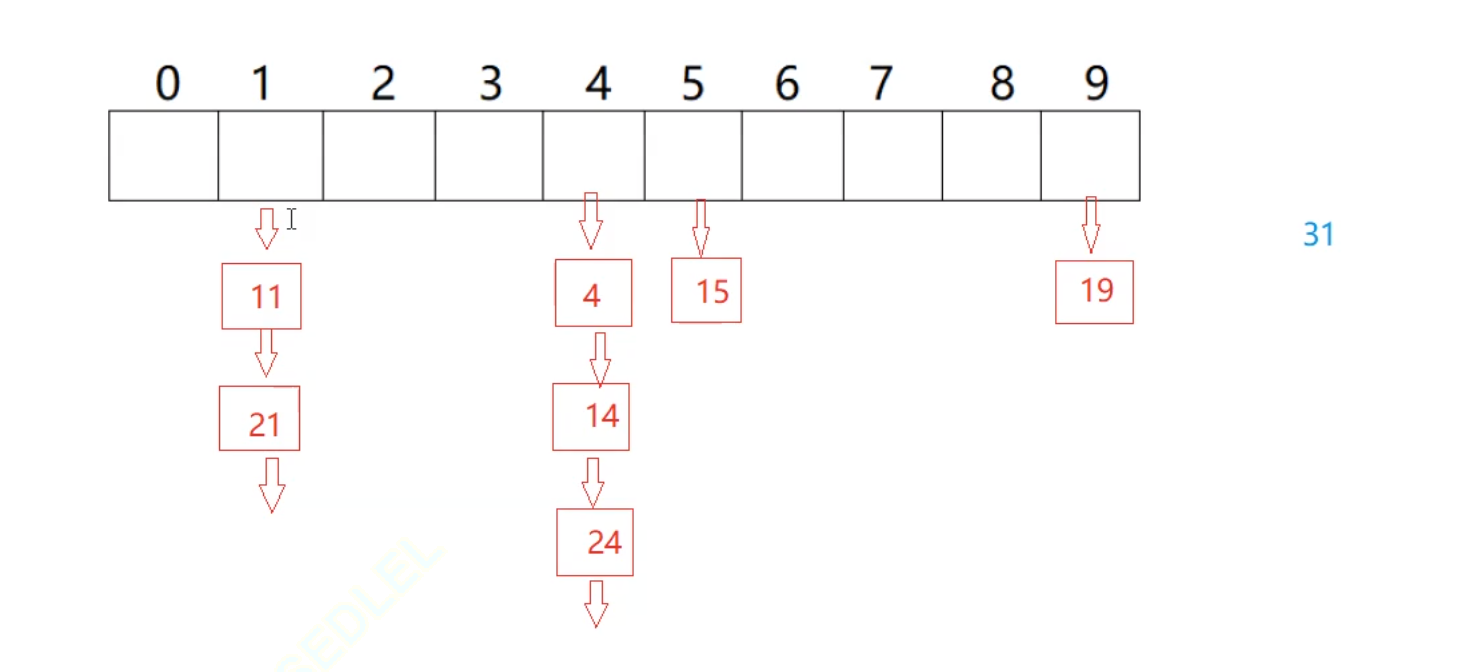
这里插入又要插入31,那么31会插入在21的下面,那么这里是走头插还是尾插呢?
但是实际上这里都可以因为这里是一个链表,所以这里我走头插,走尾插是还需要找到它的尾巴
这里的负载因子差不多 == 1左右 扩容
bool Insert(const pair<K,V>& kv)
{
size_t hashi = kv.first % _tables.size();
if (_n == _tables.size())
{
HashTable<K, V> newHT;
newHT._tables.resize(_tables.size() * 2);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
newHT.Insert(cur->_kv);
cur = cur->_next;
}
}
_tables.swap(newHT._tables);
}
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
}
3.哈希表
哈希表是一种数据结构
总结
未完……


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









