






目录
内部排序(每个 Reducer 内部进行排序):SORT BY(hash分区)
分区排序(多个Reduce):DISTRIBUTE BY (类似 MR 中的 自定义分区)
交互方式采用 SQL,元数据存储在 Derby 或 MySQL,数据存储在 HDFS,分析数据底层实现是 MapReduce,执行程序运行在 YARN 上。
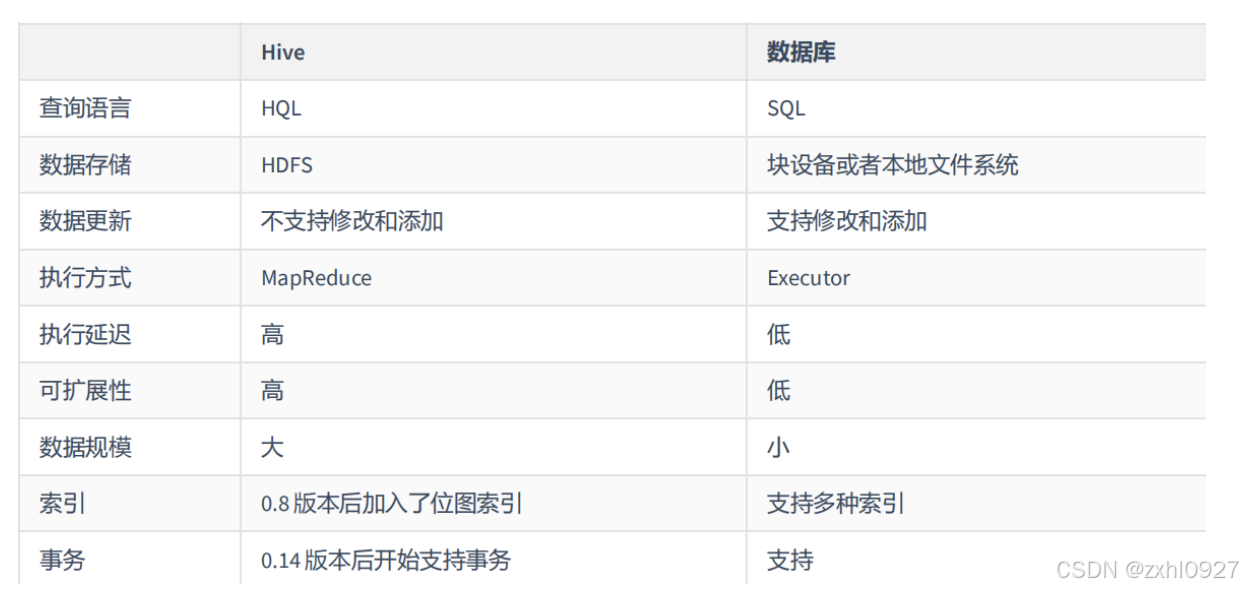
1.架构
1.Client
2.MetaStroe
3.Driver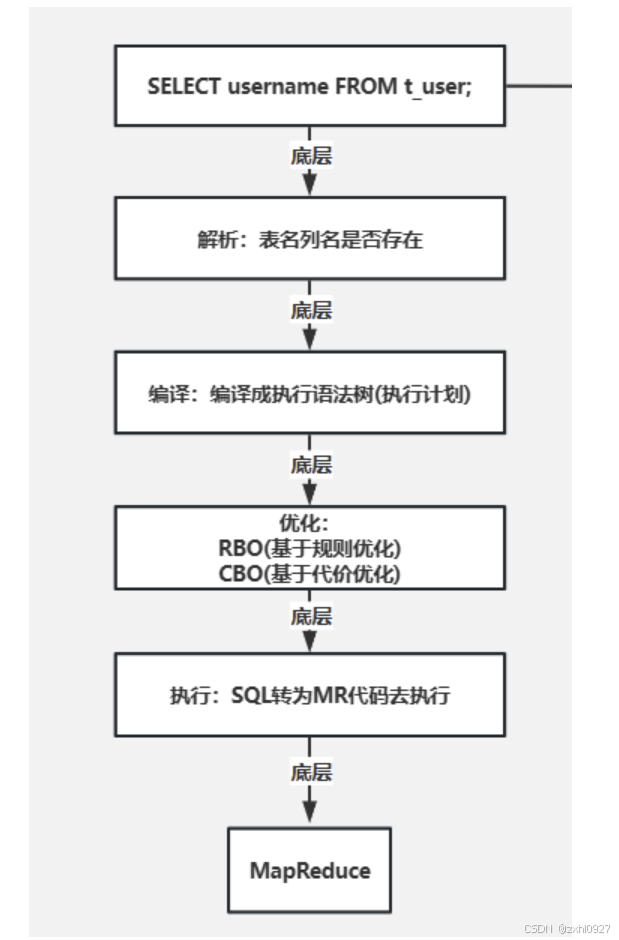
解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 ANTLR;对AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
编译器(Compiler):将 AST 编译生成逻辑执行计划。
优化器(Query Optimizer):对逻辑执行计划进行优化。
执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
大致流程如下:
Parser:将 HQL 语句解析成抽象语法树(AST:Abstract Syntax Tree);
Semantic Analyzer:将抽象语法树编译成查询块;
Logic Plan Generator:将查询块转换成逻辑查询计划;
Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划(RBO);
Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs);
Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划(CBO)。最后执行。
4.HDFS
2.工作原理
当创建表的时候,需要指定 HDFS 文件路径,表和其文件路径会保存到 MetaStore,从而建立表和数据的映射关系。当数据加载入表时,根据映射获取到对应的 HDFS 路径,将数据导入。
用户输入 SQL 后,Hive 会将其转换成 MapReduce 或者 Spark 任务,提交到 YARN 上执行,执行成功将返回结果。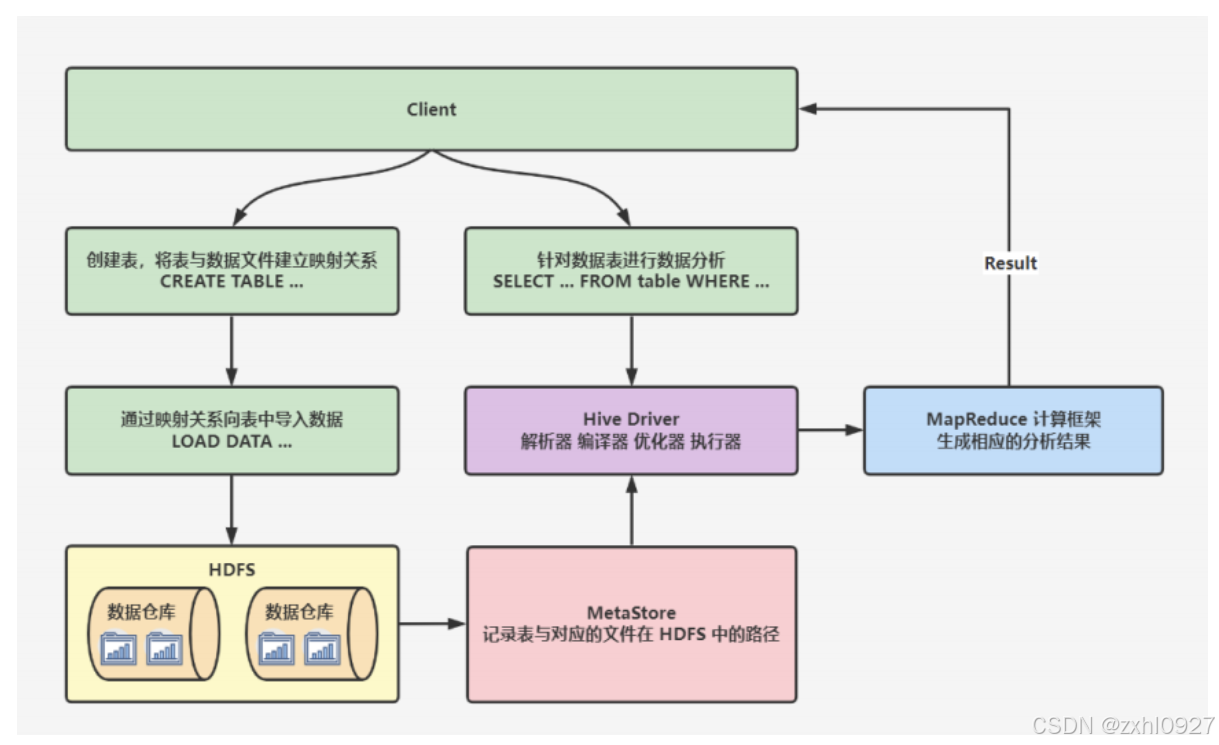
在搭建 Hive 数据仓库时,就会将 SQL 语句的常用指令操作,比如 SELECT、FROM、WHERE 以及函数等用 MapReduce写成模板,并且将这些 MapReduce 模板封装到 Hive 中。
那我们所需要做的,就是根据业务需求编写相应的 SQL 语句,Hive 会自动的到封装好的 MapReduce 模板中去进行匹配。匹配完后将运行 MapReduce 程序,生成相应的分析结果,然后反馈给我们。总之就是做离线数据分析时,Hive 要比直接使用MapReduce 开发效率更高。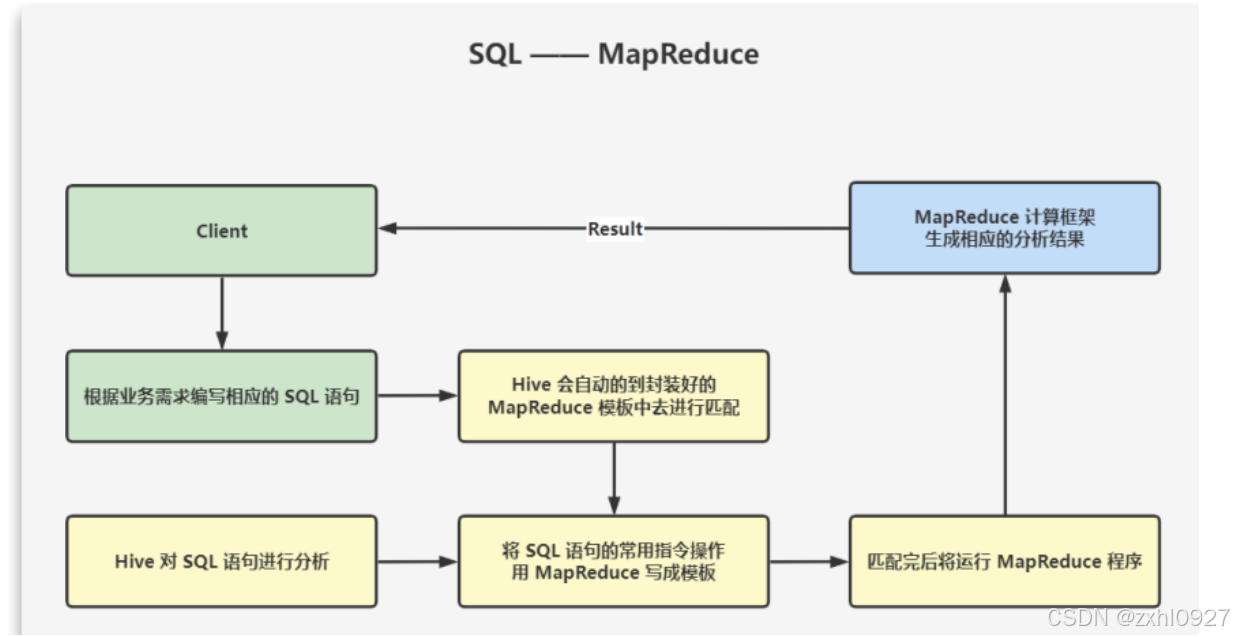
3.Hive 基础
1.内外部表
内部表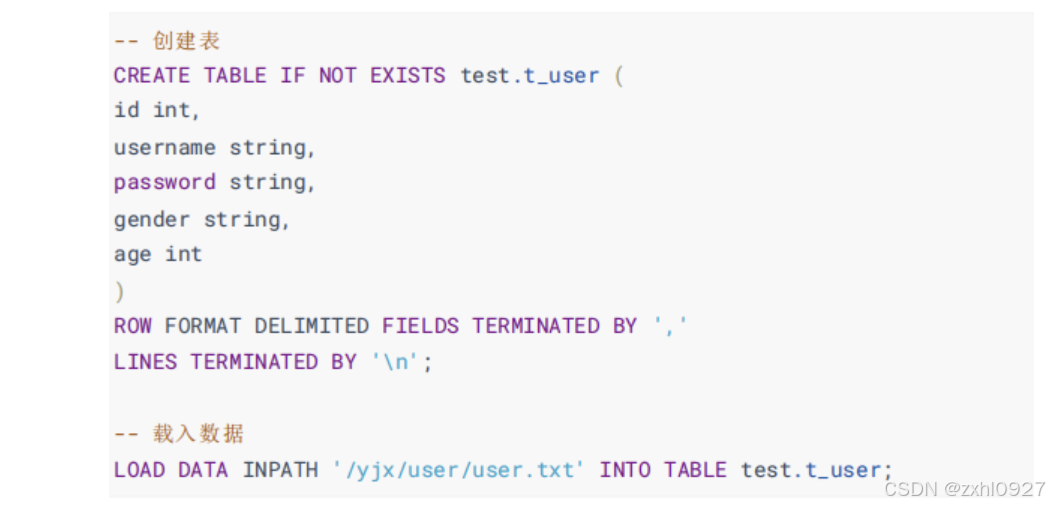
外部表
方案一:创建时指定数据位置(推荐) external
方案二:先建表再导入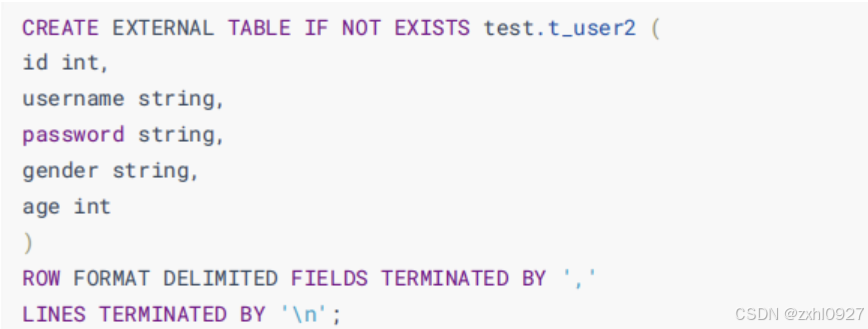
2.载入数据
加载本地数据:LOAD DATA LOCAL INPATH '/root/user.txt' INTO TABLE t_user;
加载 HDFS 数据:LOAD DATA INPATH '/yjx/user.txt' INTO TABLE t_user;
加载并覆盖已有数据:LOAD DATA INPATH '/yjx/user.txt' OVERWRITE INTO TABLE t_user;
加载并追加数据:LOAD DATA INPATH '/yjx/user.txt' INTO TABLE t_user;
通过查询插入数据:
3.导出数据
将查询结果导出到本地
将查询结果输出到HDFS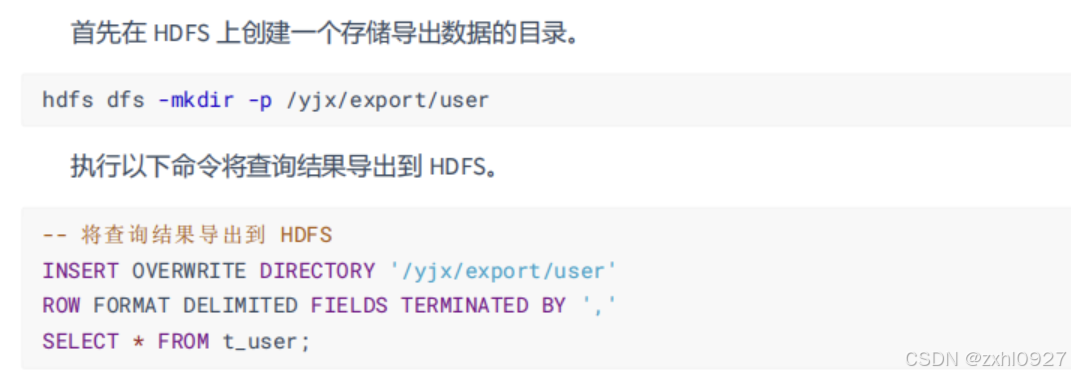
通过 HDFS 操作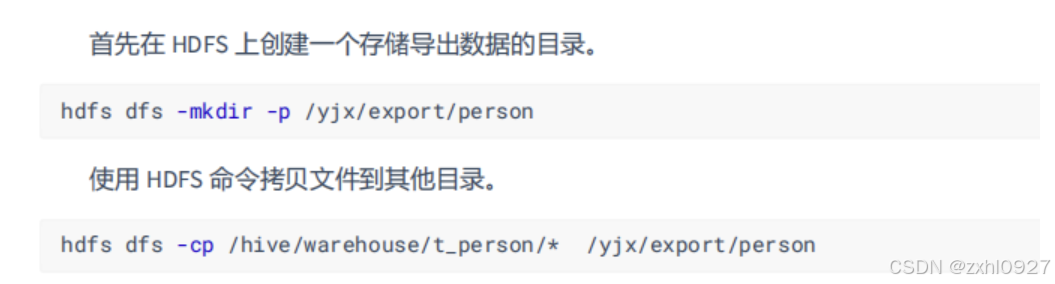
将元数据和数据同时导出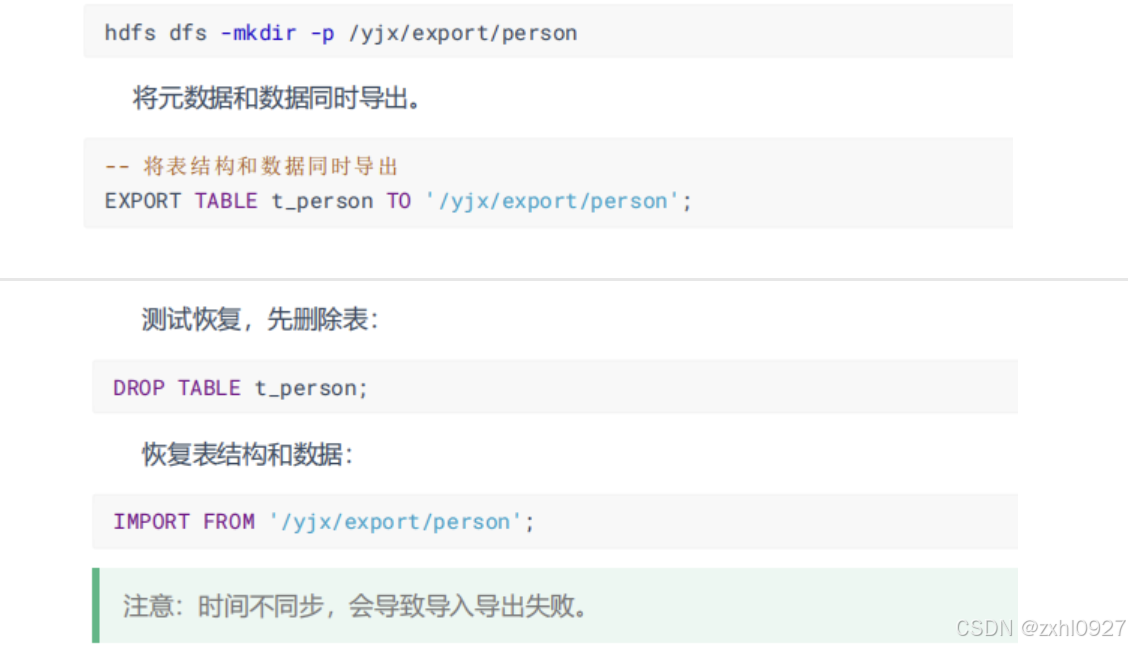
4.基本查询
内置运算符与函数
-- 查看系统自带函数:SHOW FUNCTIONS;
-- 显示某个函数的用法:DESC FUNCTION UPPER;
-- 详细显示某个函数的用法:DESC FUNCTION EXTENDED UPPER;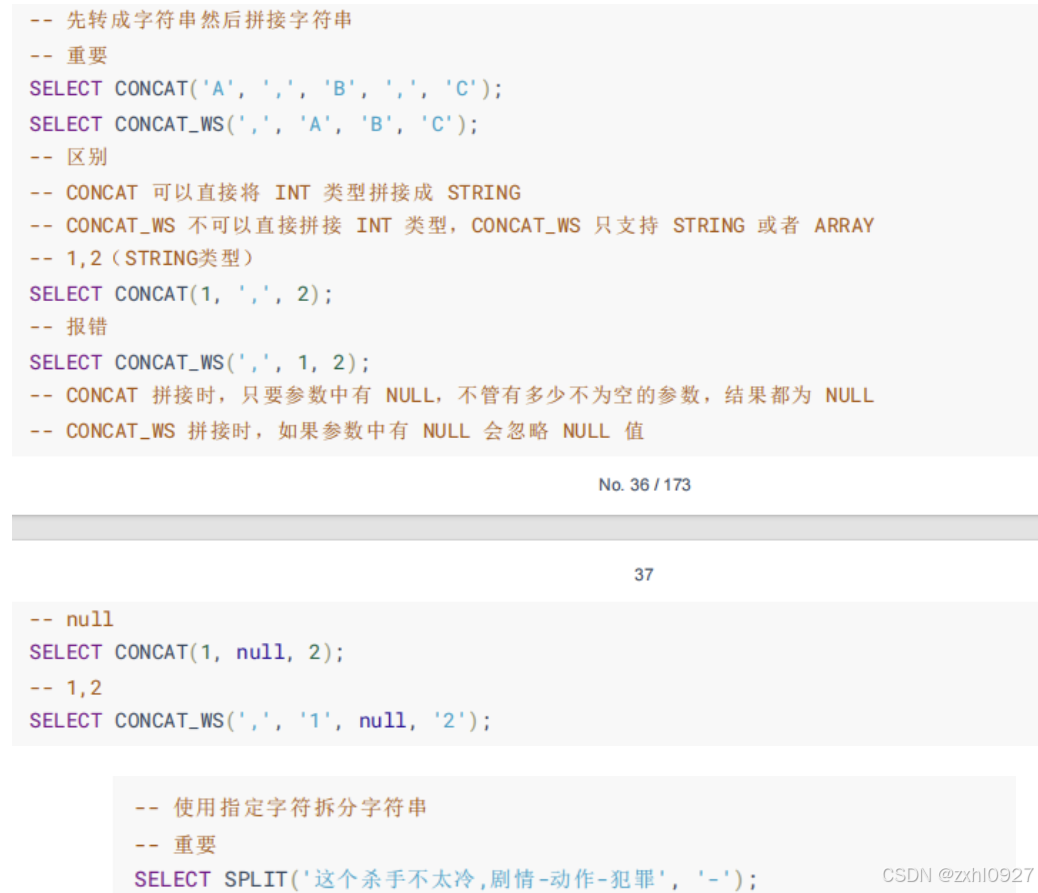
常用函数--正则
语法: REGEXP_EXTRACT(str, regexp[, idx])
返回值:String
说明:将字符串 str 按照 regexp 正则表达式的规则拆分,返回 idx 指定的字符
语法: REGEXP_REPLACE(str, regexp, rep)
返回值:String
说明:将字符串 str 中的符合 regexp 正则表达式的部分替换为 rep。
5.排序
全局排序(在一个 Reduce 中):ORDER BY
内部排序(每个 Reducer 内部进行排序):SORT BY(hash分区)
-- 查看 Reduce 的个数
SET mapred.reduce.tasks;
-- 设置 Reduce 的个数(不设置的话默认为-1,智能分区)
SET mapred.reduce.tasks=3;
-- 局部排序
SELECT * FROM emp SORT BY sal DESC;
分区排序(多个Reduce):DISTRIBUTE BY (类似 MR 中的 自定义分区)
进行分区,一般结合 SORT BY 使用(注意:DISTRIBUTE BY要在 SORT BY 之前)。
组合排序:CLUSTER BY
SELECT * FROM emp CLUSTER BY deptno;
6.复杂数据类型
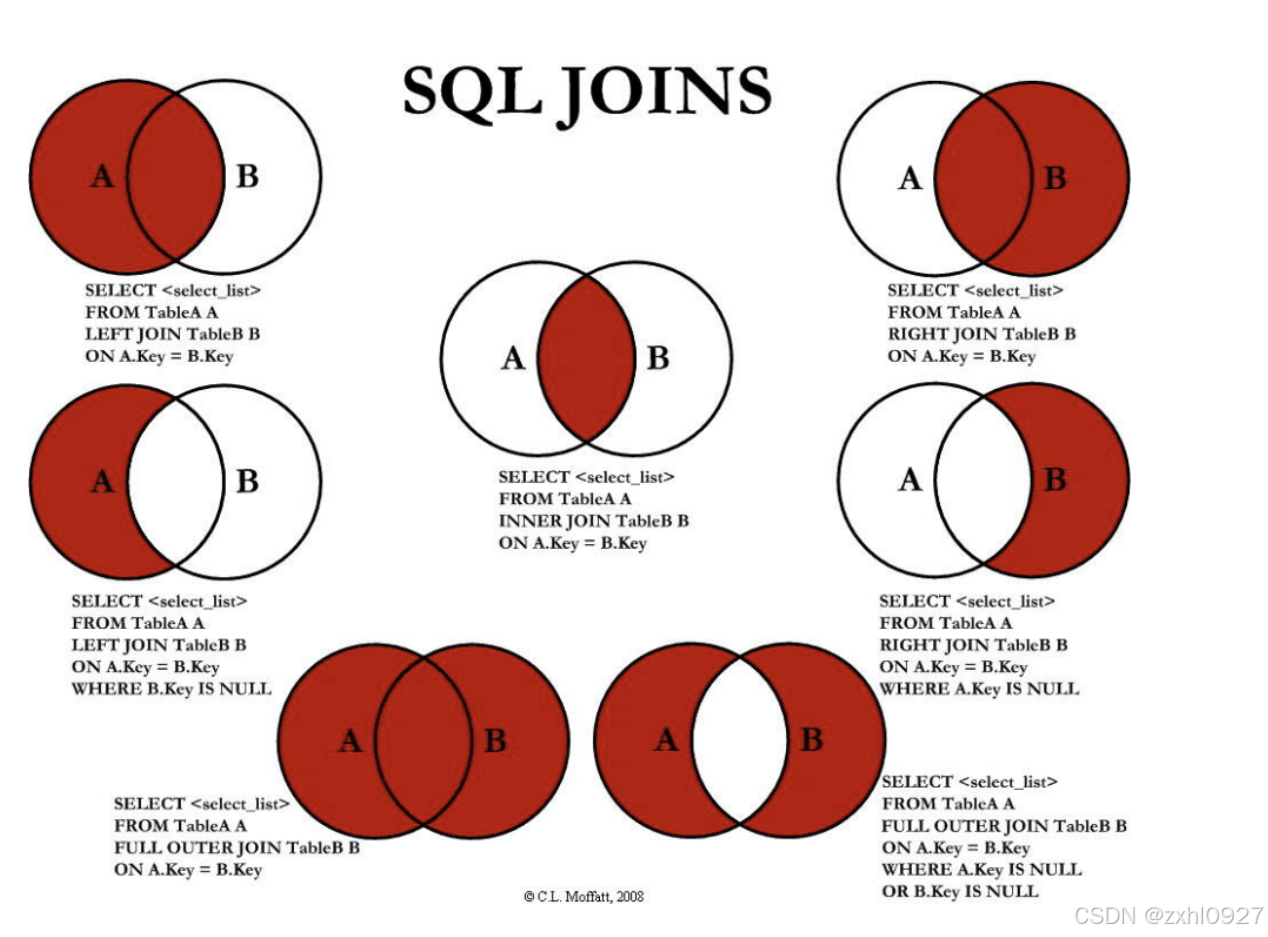
7.连接查询
4.Hive高级
1.分区/分桶
分区(目录)partitioned by
1.静态分区 (单分区 ,多分区)
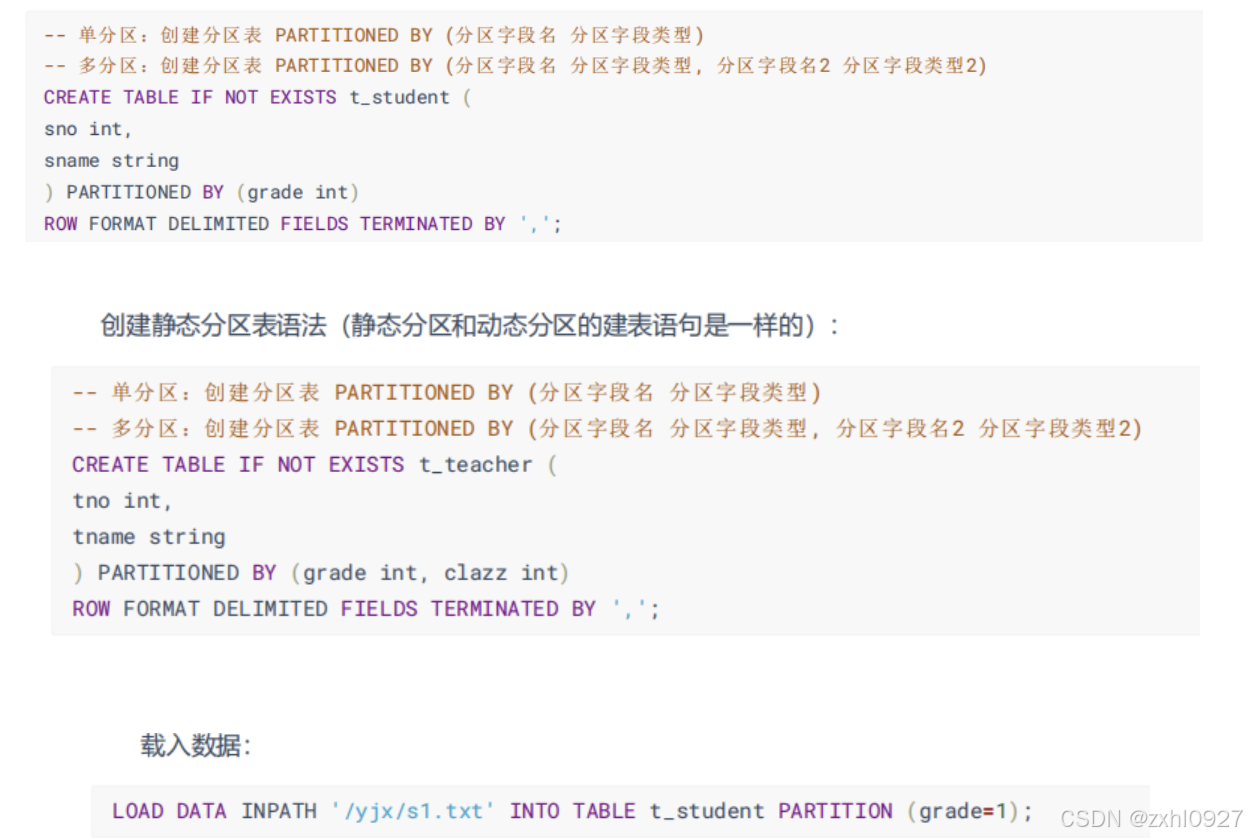
2.动态分区
然后载入数据
严格模式: Hive 通过参数 hive.mapred.mode 来设置是否开启严格模式。目前参数值有两个:strict(严格模式)和 nostrict(非严格模式,默认)。
分桶(数据)clustered BY
Hive 采用对列值哈希,然后除以桶的个数求余的方式决定该条记录要存放在哪个桶中。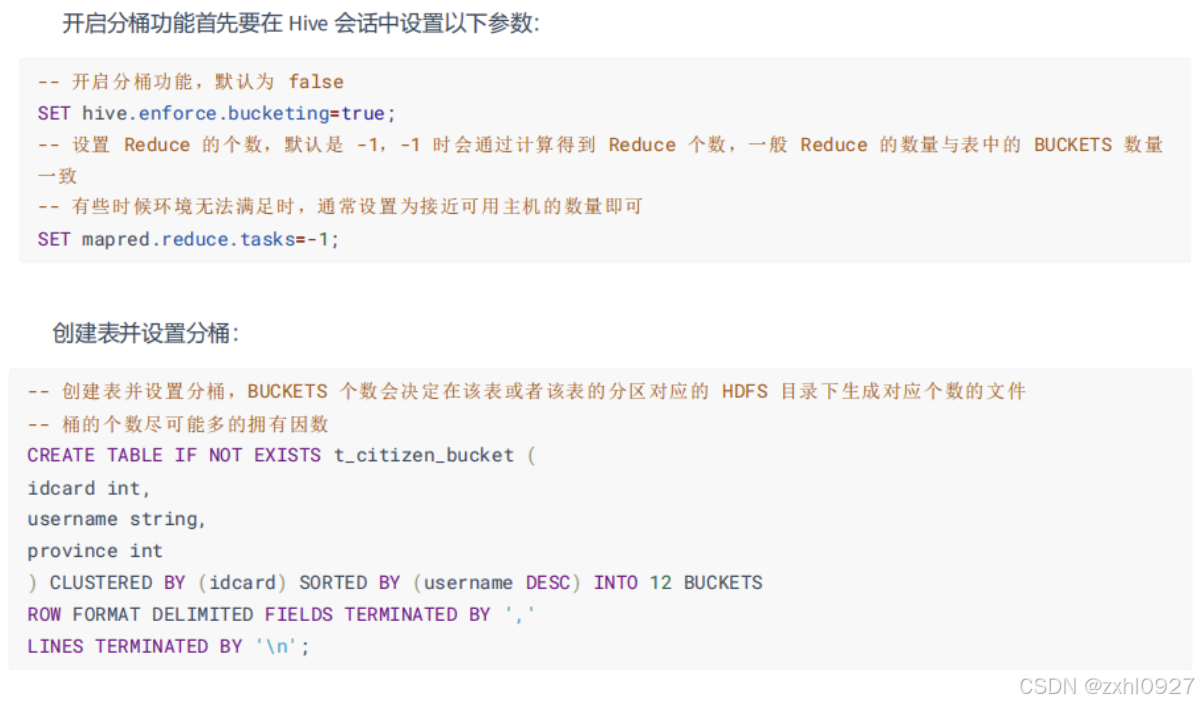
载入数据使用的是三方表载入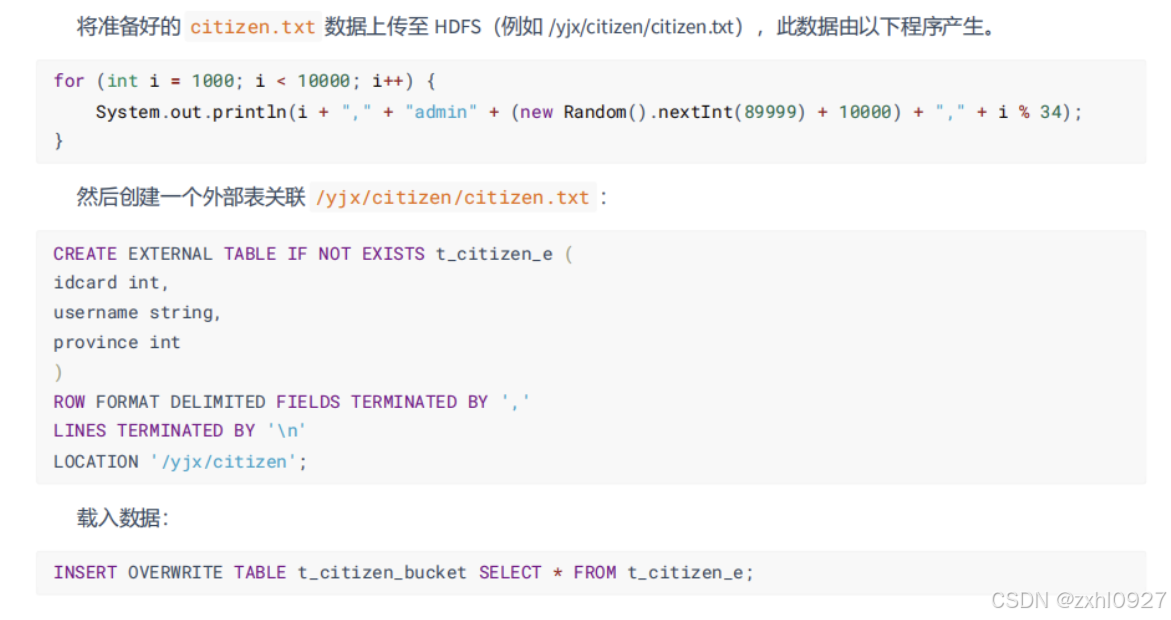
2.数据抽样
块抽样--
(不随机,速度快)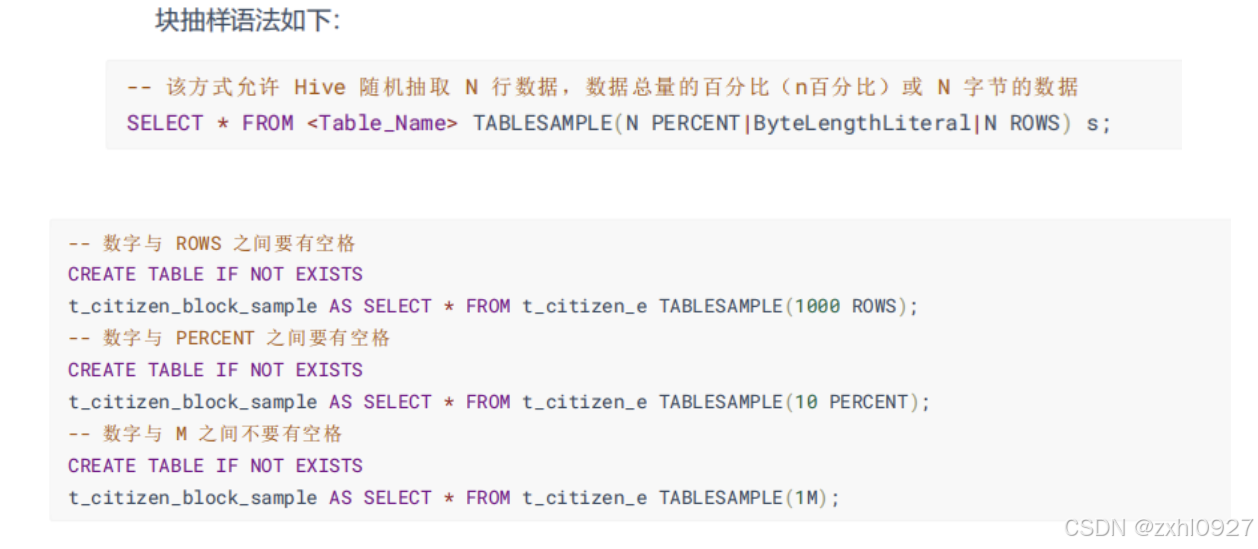
分桶抽样--
随机且速度最快(不走 MR)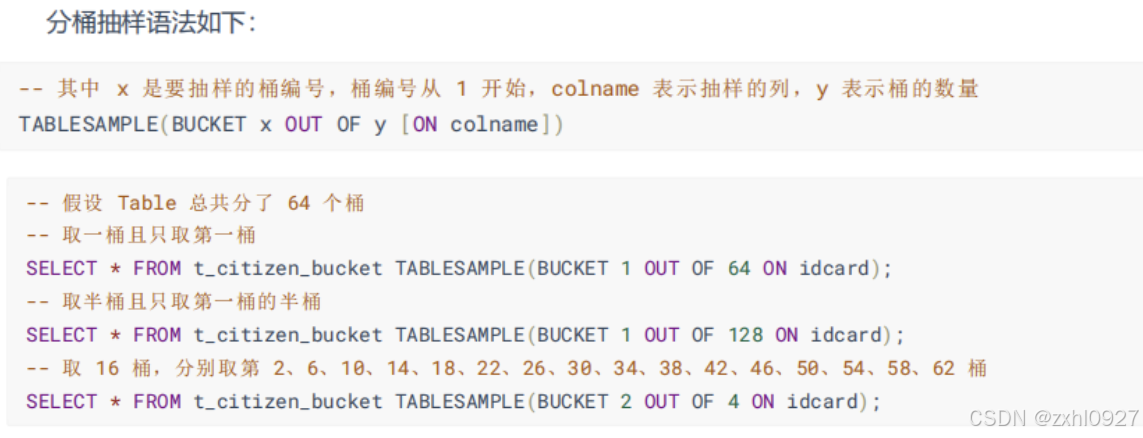
随机抽样(随机但速度慢)
3.事务(可以实现修改,删除)
产生的原因:底层是MapReduce所以不支持 UPDATE、DELETE 语法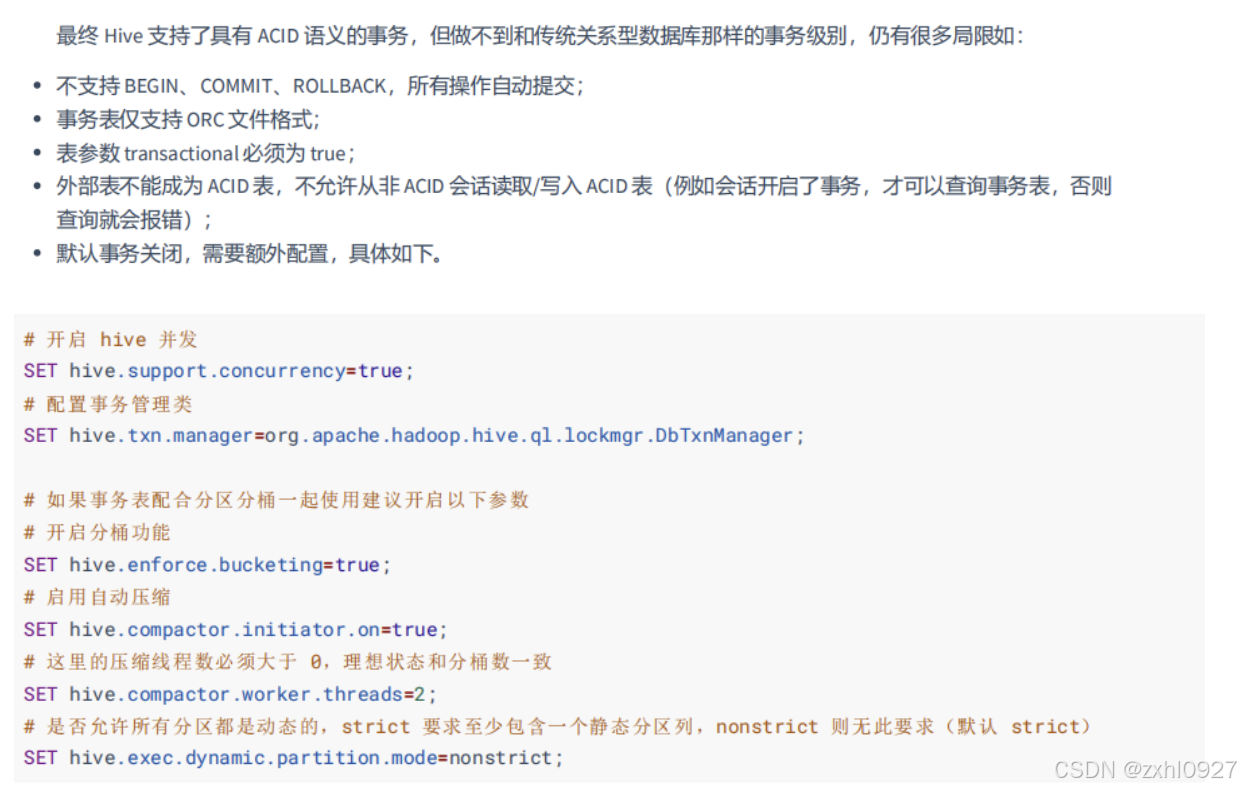
4.视图/物化视图
视图是一个虚拟的表,只保存定义,不实际存储数据
物化视图是真实存在的(但只能在事务表上创建)---materialized
刷新
1.增量刷新(使用了insert等时触发)
即只刷新原始源表中的变动会影响到的数据,增量刷新会减少重建步骤的执行时间。要执行增量刷新,物化视图的创建语句和更新源表的方式都须满足一定条件:
物化视图只使用了事务表;
如果物化视图中包含 GROUP BY,则该物化视图必须存储在 ACID 表中,因为它需要支持 MERGE 操作。对于由 Scan-Project-Filter-Join 组成的物化视图,不存在该限制。
2.定时刷新
可以通过 SET hive.materializedview.rewriting.time.window=10min; 设置定期刷新,默认为 0min。该参数也可以作为建表语句的一个属性,在建表时设置。
3.全量刷新
使用 UPDATE、INSERT 更新了源表数据,那么只能进行重建,即全量刷新(REBUILD)。
查询重写(里面的内容)
用户提交查询 Query,若该 Query 经过重写后可以命中已经存在的物化视图,则直接通过物化视图查询数据返回结果.
【假设我们要经常获取有关 1981 年之后按不同时期聘用的员工及其部门的信息,我们可以创建一个物化视图: 然后,查询提取有关 1982 年第一季度雇用的员工的信息(该查询会触发查询重写):】
5. 行转列,列转行
一行变多行(行转列)
多行变一行(列转行)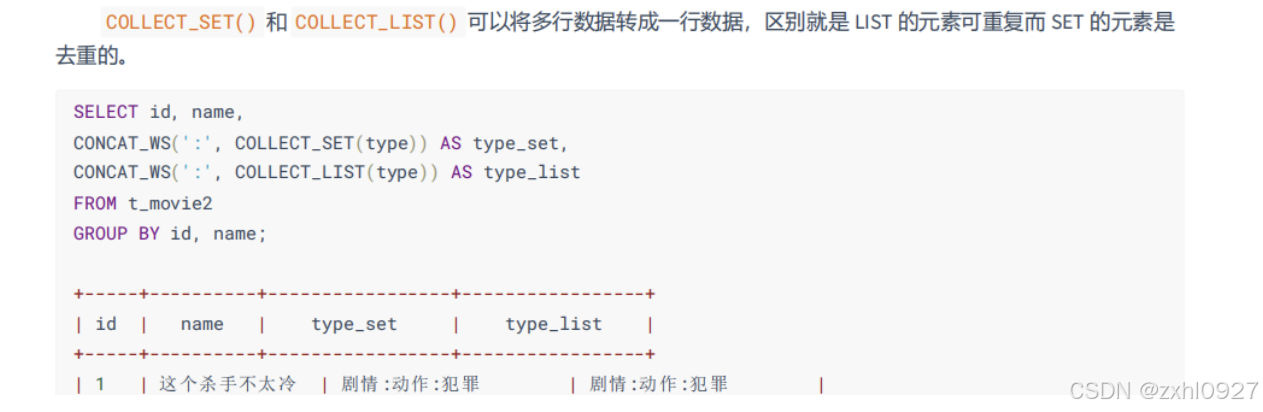
MySQL 实现方式: GROUP_CONCAT([DISTINCT] 要连接的字段 [ORDER BY 排序字段 ASC/DESC] [SEPARATOR‘分隔符’])
6.URL解析
侧视图 LATERAL VIEW 配合 PARSE_URL_TUPLE 函数可以实现 URL 字段的一列变多列。
7.JSON解析
一: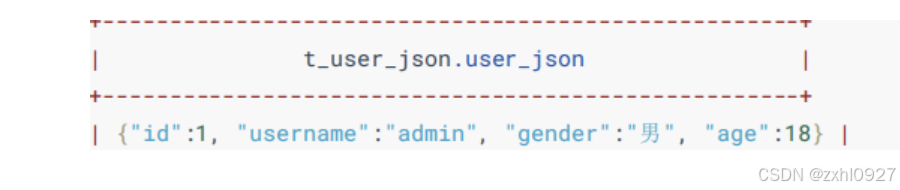
1)GET_JSON_OBJECT(JSON_TXT, PATH) :
2)
二: 创建 t_user_json2 表并使用 JsonSerDe 序列化器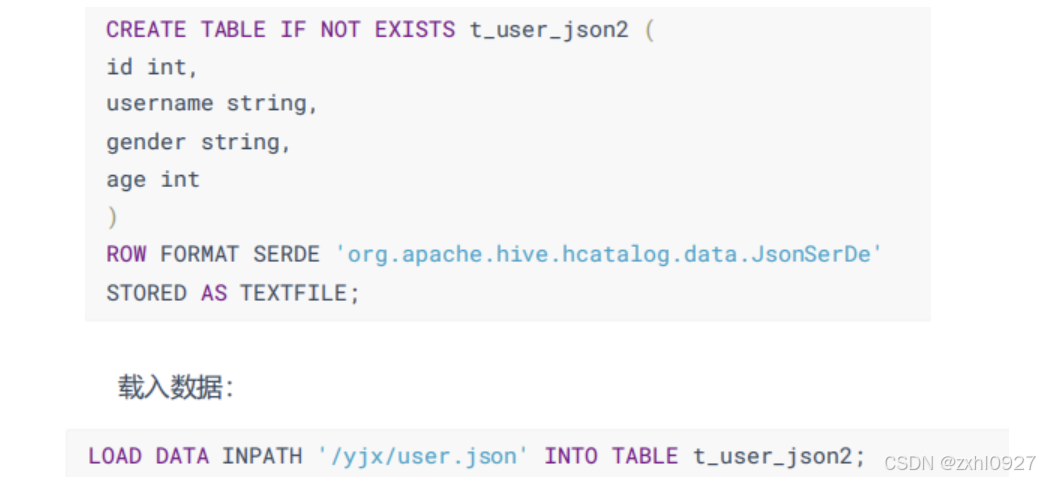
8.窗口函数
窗口函数的查询不会影响原有的查询,只是将查询结果拼接在原有查询出的每条记录后
XX函数() :聚合型窗口函数/分析型窗口函数/取值型窗口函数
分析型窗口函数:
OVER() :窗口函数
PARTITION BY :后跟分组的字段,划分的范围被称为窗口
ORDER BY :决定窗口范围内数据的排序方式
移动窗口 :
移动方向:
CURRENT ROW :当前行
PRECENDING :向当前行之前移动
FOLLOWING :向当前行之后移动
UNBOUNDED :起点或终点(一般结合 PRECEDING,FOLLOWING 使用)
UNBOUNDED PRECEDING :表示该窗口第一行(起点)
UNBOUNDED FOLLOWING :表示该窗口最后一行(终点)
移动范围: ROWS(物理上) 和 RANGE(逻辑上)
函数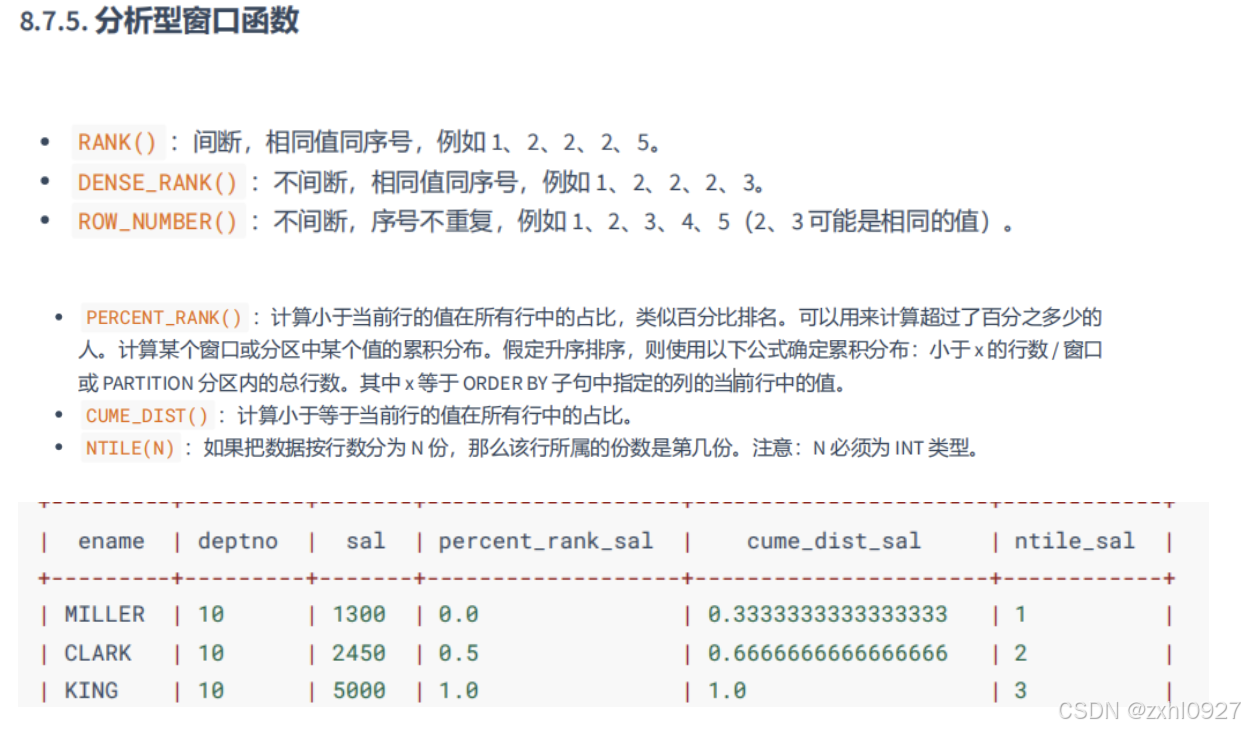

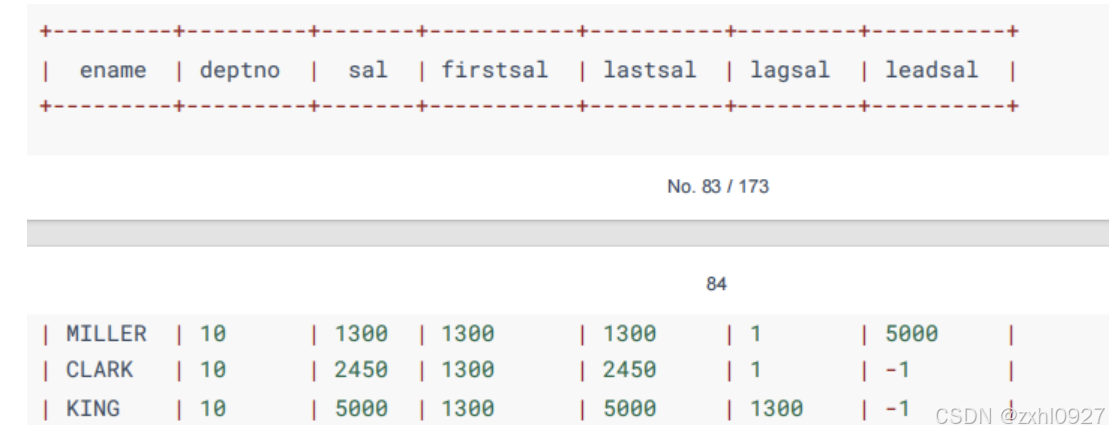

9.自定义函数
1.UDF:普通函数,一进一出,比如 UPPER, LOWER
是继承 GenericUDF 重写 initialize 方法、evaluate 方法getDisplayString 方法实现。
2.UDAF:聚合函数,多进一出,比如 COUNT/MAX/MIN
先继承 AbstractGenericUDAFResolver 类重写 getEvaluator 方法,然后使用静态内部类实现GenericUDAFEvaluator 接口。
3.UDTF:表生成函数,一进多出,比如 LATERAL VIEW EXPLODE()
继承GenericUDTF,然后重写父类的三个抽象方法,initialize 方法,process方法,close()方法,主要处理逻辑是在 process 中实现。
Hive自定义函数的流程包括以下几个步骤:
-
编写自定义函数:根据需求编写Java类,继承相应的Hive类(如
GenericUDF、GenericUDTF等),并实现必要的方法(如evaluate()、initialize()等)。 -
打包成jar包:将编写的Java代码打包成jar包,并上传到Hive所在的服务器。
-
在Hive中注册自定义函数:通过Hive的命令行窗口,将上传的jar包添加到Hive的classpath中,并创建临时函数与开发好的Java类关联。
-
使用自定义函数:在HiveQL中调用自定义函数,进行数据处理和分析。
自定义函数的作用主要包括:
-
扩展Hive的功能:Hive的内置函数可能无法满足所有业务需求,自定义函数可以扩展Hive的功能,满足特定的数据处理需求。
-
提高数据处理效率:通过编写高效的自定义函数,可以优化数据处理过程,提高数据处理的速度和效率。
-
灵活性:自定义函数可以根据具体业务需求进行定制,提供更高的灵活性和可配置性。
-
复用性:编写的自定义函数可以在多个项目中复用,减少重复开发工作。
*常用的关键字
explode () -- 展开 split()--切割
lateral view--侧视图 with--临时
stored as --存储格式 external table--外部表
row fromat delimited fields terminated by ','
lines terminated by '\n'
tblproperties---事务
union--合并俩个select表(去重)
union all--合并俩个select表(不去重)
group by ...having...
-- 创建分区表 CREATE TABLE partitioned_table(id INT, value STRING) partitioned BY (year INT, month INT, day INT);
-- 创建分桶表 CREATE TABLE bucketed_table(id INT, value STRING) clustered BY (id) INTO 32 BUCKETS;
将查询结果导出到本地:inserrt overwrite local directory XXX
将查询结果输出到 HDFS:insert overwrite directory XXX
通过 HDFS 操作:insert overwrite load directory XXX
将元数据和数据同时导出:export table XXX to XXX
10.压缩/存储
1)压缩
以 Hive 的压缩分两部分完成,一部分是 Hadoop 的压缩,一部分是 Hive 的。
2)存储
方式:OLTP (联机事务处理)和 OLAP(联机分析处理)
a.行式存储
Text File 易读 (load data)
Sequence File 和Java与语言绑定的
Map File 和Java语言绑定的且有序
Avro File 和编程语言无关的json格式(通用款)
b.列式存储
RC File
ORC File 支持事务 Hive一般用这个 (insert into)
Parquet File 不支持事务 Spark 一般用这个(insert into)(通用款)
11.优化
1.Explain执行优化
2.SQL优化
a.RBO优化:基于规则优化
1)谓词下推
在不影响结果的情况下,尽量将过滤条件提前执行。
2)列裁剪&常量替换
列裁剪(Column Pruning)表示扫描数据源的时候,只读取那些与查询相关的字段。
常量替换(Constant Folding)表示将表达式提前计算出结果,然后使用结果对表达式进行替换
b.CBO优化:基于代价优化
它需要计算所有可能执行计划的代价,并挑选出代价最小的执行计划。
然后统计表的相关信息才能使用 CBO 优化:
对于非分区表列的 Statics 信息存在 Hive 元数据表 TABLE_COL_STATS 中;
对于分区表列的 Statics 信息存在 Hive 元数据表 PART_COL_STATS 中。
c.JOIN 优化
a.小表 JOIN 大表的 Map Join:
每个 Mapper 从 Distributed Cache 读取 HashTableFiles 到内存中,顺序扫描大表,在
Map 阶段直接进行 Join,将数据传递给下一个 MapReduce 任务。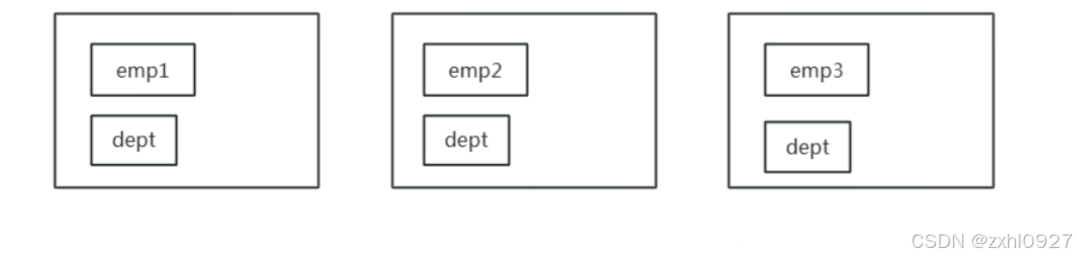
b.大表 JOIN 大表的 Reduce Join(俩大表在map中各自加盐,然后在reduce中join),Reduce Join 又分为以下两种:
1)Bucket Map Join(中型表和大表 JOIN):分桶(相同或者倍数)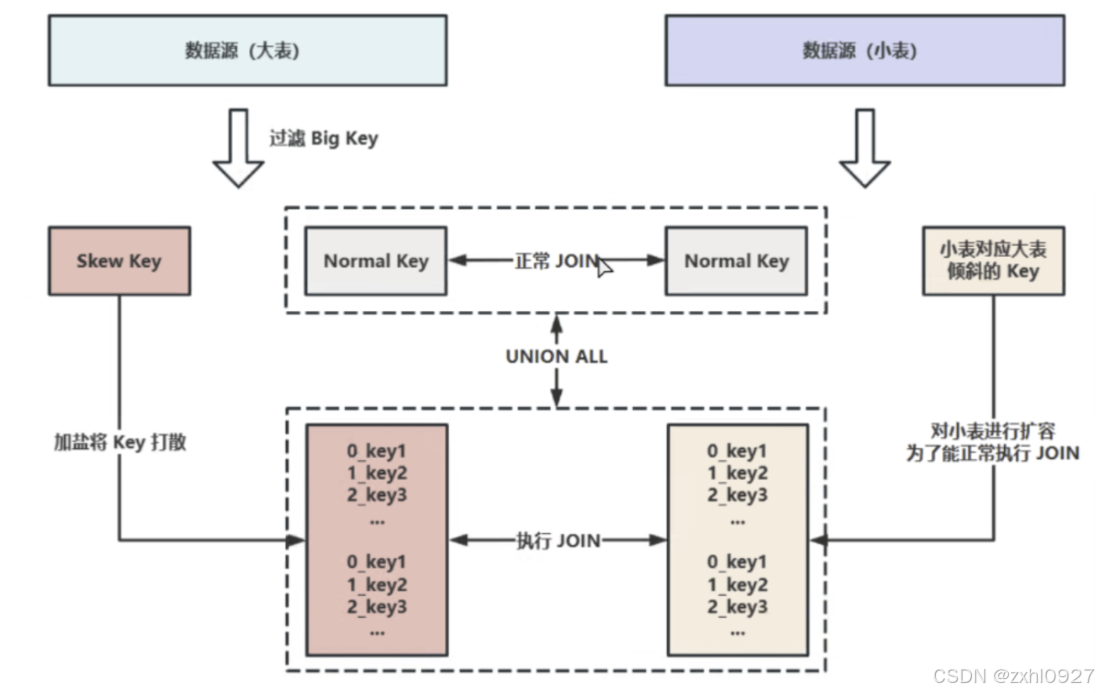
2)Sort Merge Bucket Join(大表和大表 JOIN):分桶(相同)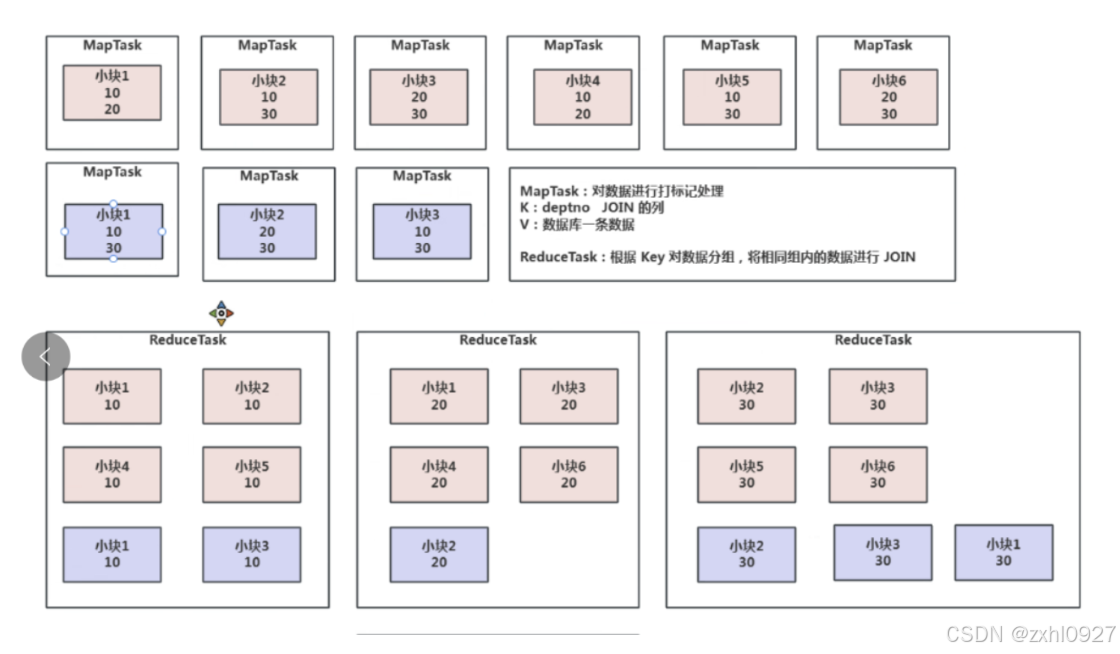
d.分区/分桶
3.数据倾斜
a.压缩引发的
在数据压缩的时候可以采用 BZip2 和 Zip 或 LZO 支持文件分割的压缩算法
b.单表数据导致
两阶段聚合(加盐局部聚合 + 去盐全局聚合)+ Map-Side 聚合(开启 Map 端聚合或自定义 Combiner)
c.JOIN数据倾斜优化
1)Map JOIN
2) 大小表 JOIN:采样倾斜 Key 并分拆 JOIN ( 原理) Skew Join(实战)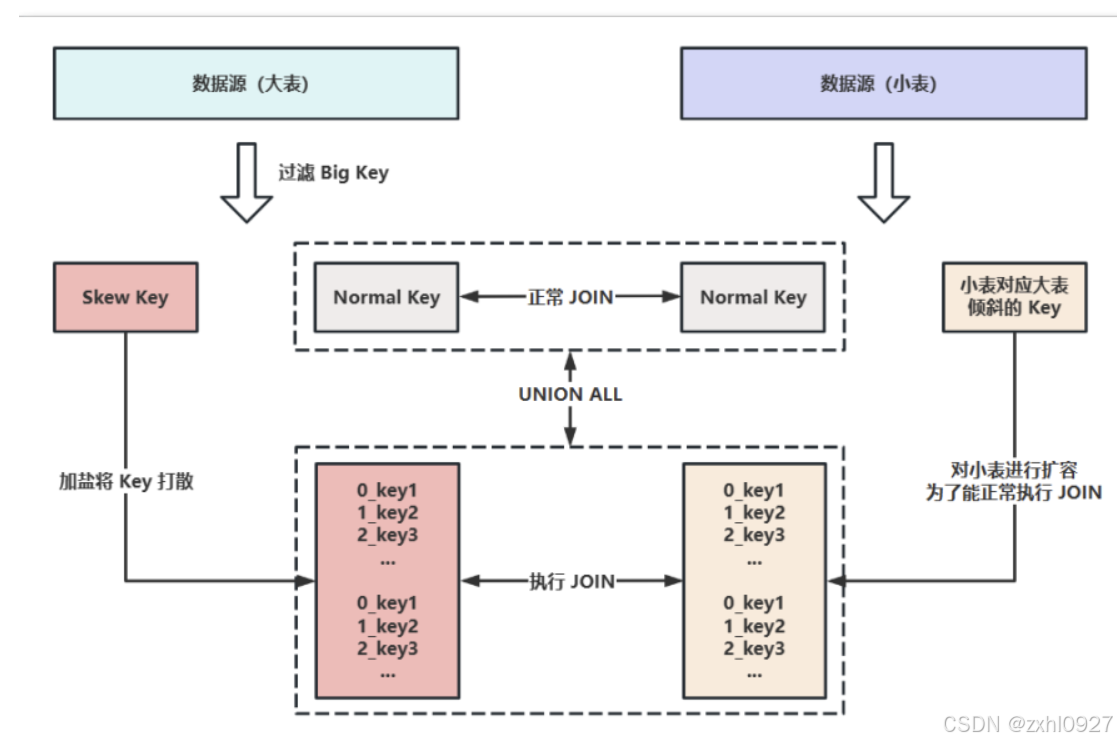
Skew Join(Hive自带的优化方案):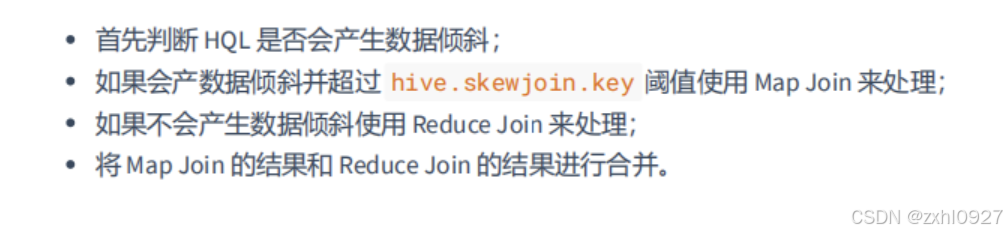
d.业务无关数据引发:先过滤再 JOIN
不需要null值时:- 使用 INNER JOIN,Hive 会自动过滤 NULL 值
-使用 LEFT JOIN 则会保留 NULL 值,添加个过滤条件。eg:WHERE deptno IS NOT NULL
需要null值时:
e. 无法消减中间结果的数据量引发的
f. 多维聚合计算数据膨胀引起的数据倾斜
SELECT A, B, C, COUNT(1) FROM T GROUP BY A, B, C WITH ROLLUP。
4.资源优化
a.向量化查询(CPU 寄存器上):多线程
b.存储优化
c.YARN优化:通过配置一些参数
d.并行执行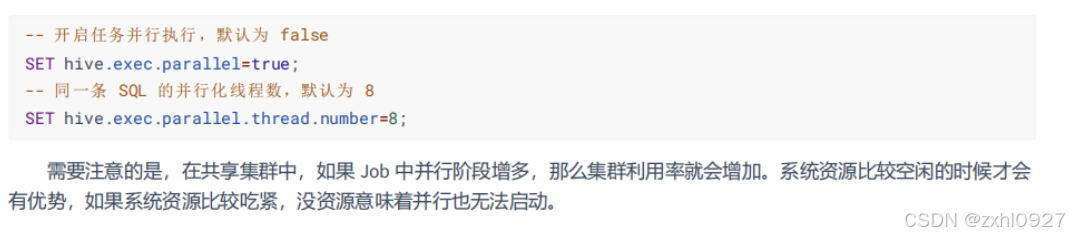
e.JVM重用---废弃了
5.聚合优化
a.GROUPBY优化
b.ORDERBY优化(属于全局排序)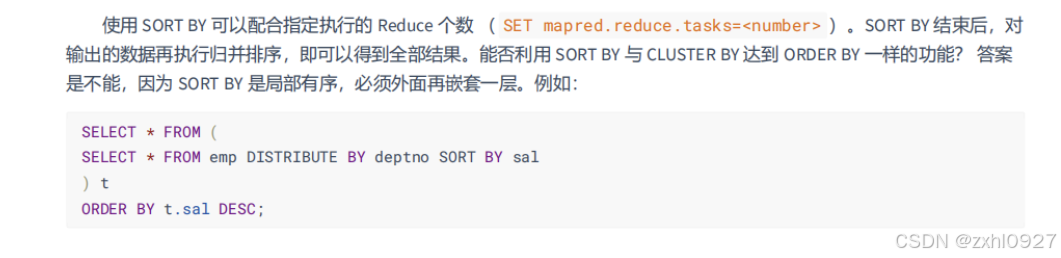
c.COUNT(DISTINCT)优化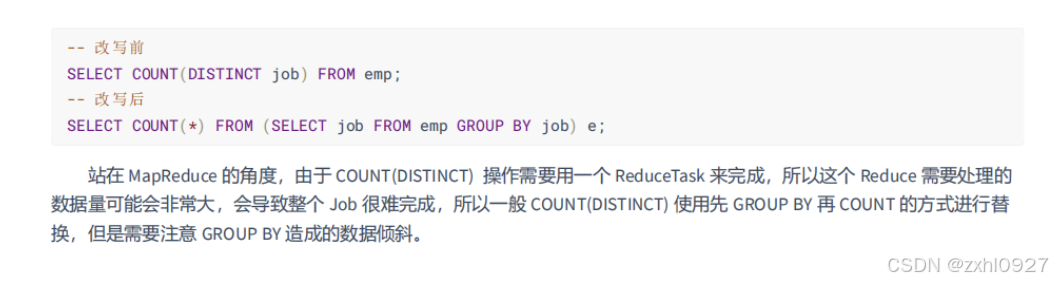
6.job优化
a.Map
使大数据量利用合适的 Map 数;使单个 Map 任务处理合适的数据量。
b.Reduce
使大数据量利用合适的 Reduce 数;使单个 Reduce 任务处理合适的数据量。
c.Shuffle
压缩中间数据,从而减少磁盘操作以及减少网络传输数据量
7.其他优化
a.Fetch模式
数据可以很快的返回,这其实涉及到 Fetch抓取的概念
b.多重模式
c.关联优化
当一个程序中有一些操作彼此之间有关联性的时候,是可以在一个 MapReduce 中完成的,但是 Hive 会不智能的选择使用两个 MapReduce 来完成这两个操作。
d.本地模式
(不用提交给Yarn,但是不能查看日志)
e.严格模式
为了禁止某些查询(这些查询可能会造成意想不到的坏结果)
f.推测执行




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









