







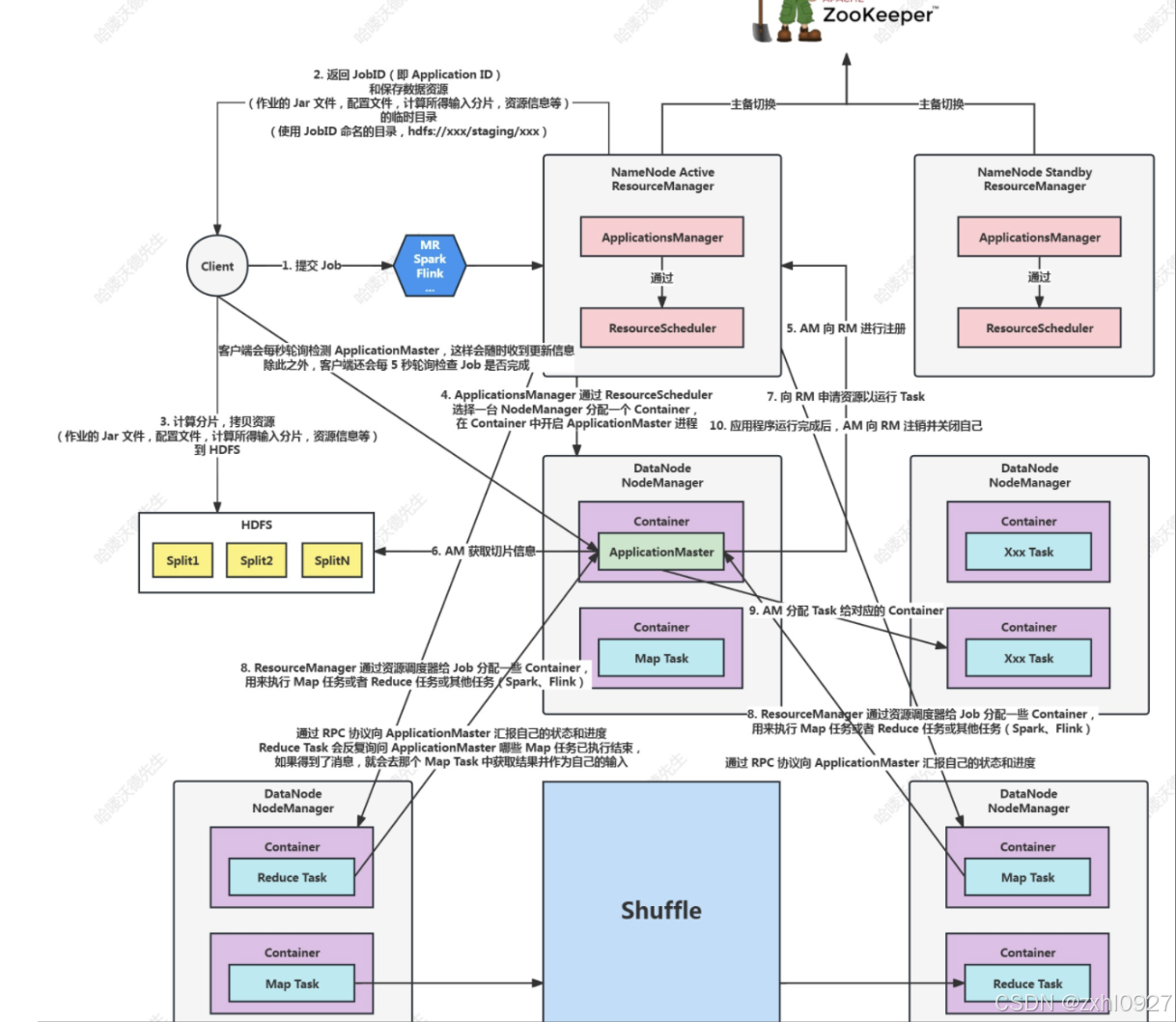
1.排序
1.快速排序
左右指针法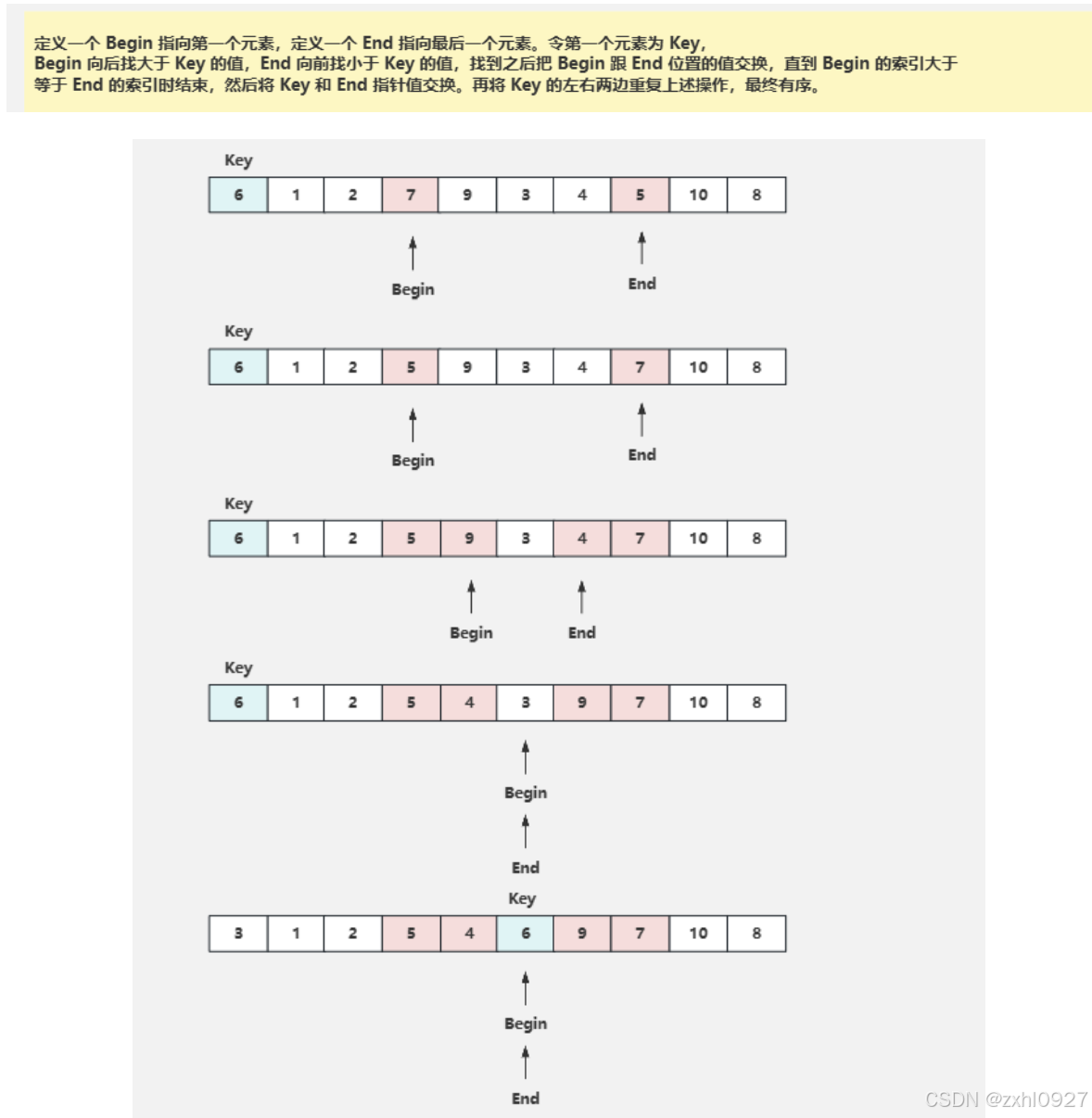
挖坑法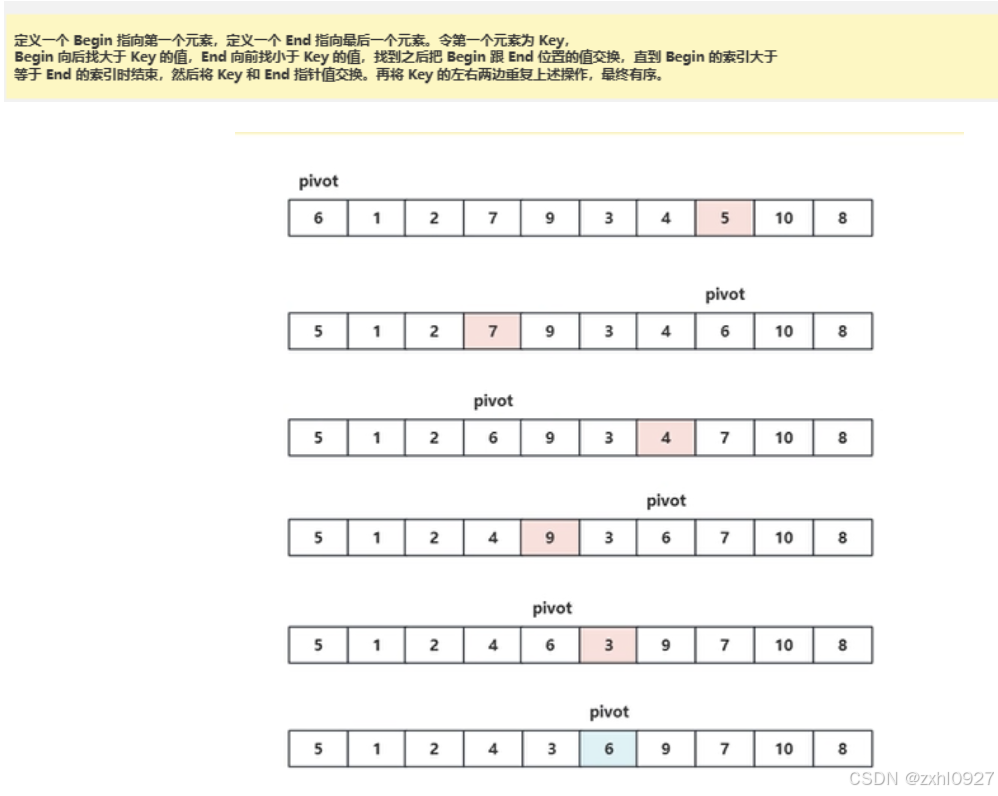
左右俩边各找一个基准,如此反复,最终有序
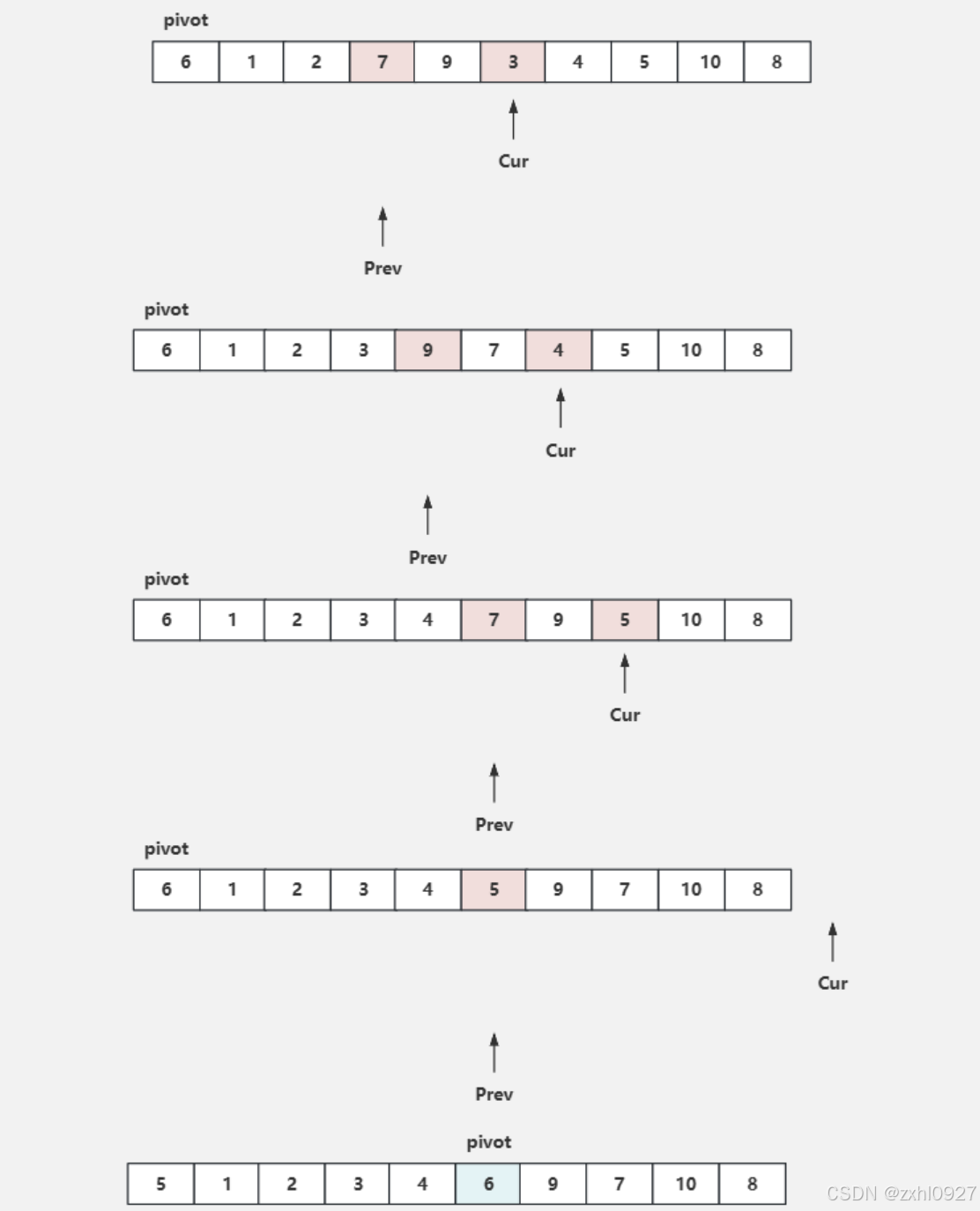
前后指针

2.归并排序
二分再合并
2.MapReduce计算流程
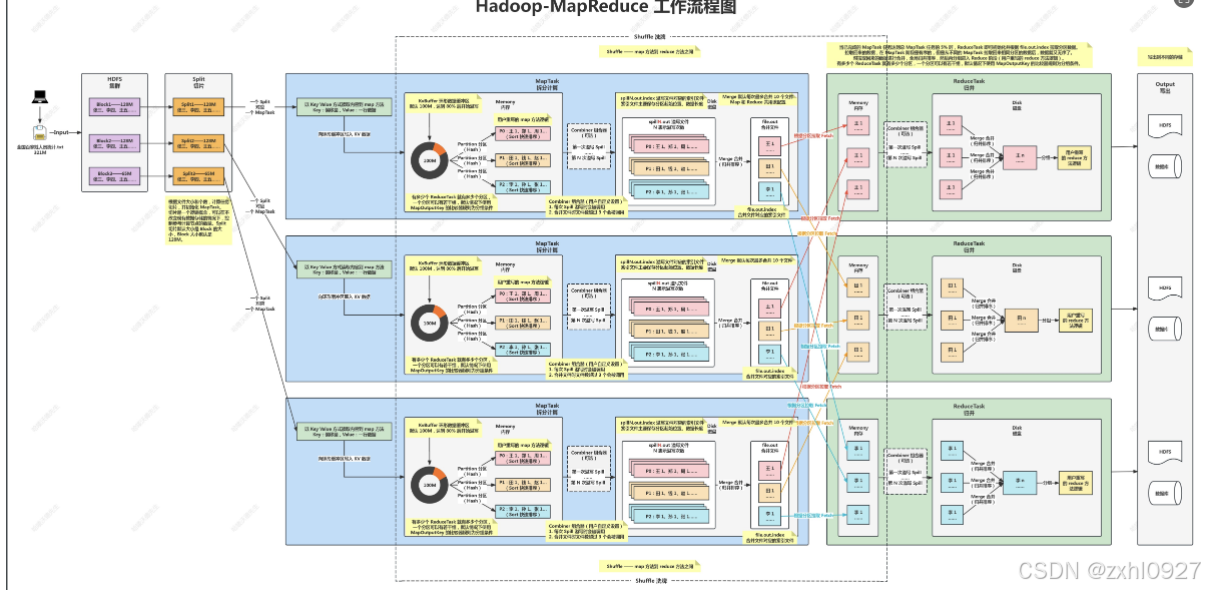
1)原始数据File
2)数据块Block
3)切片Split
4)MapTask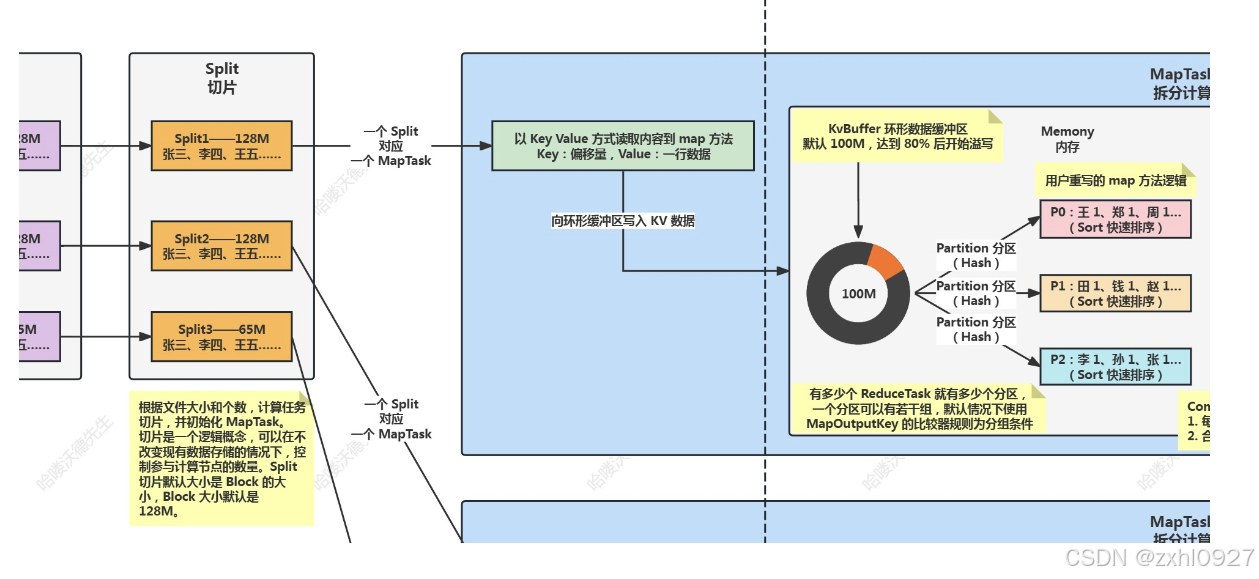
5).读入环形数据缓冲区(内存)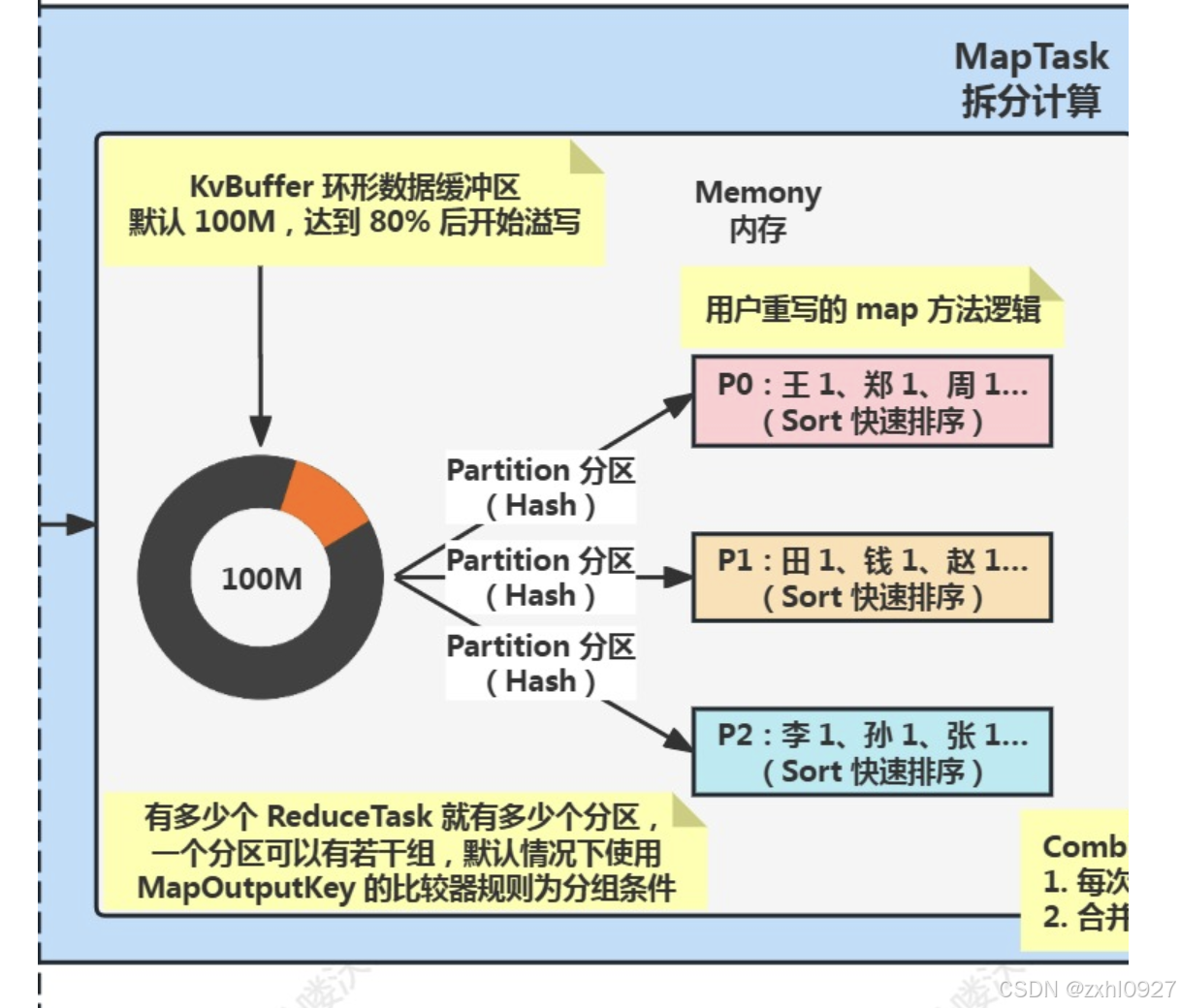
6).分区&排序(内存)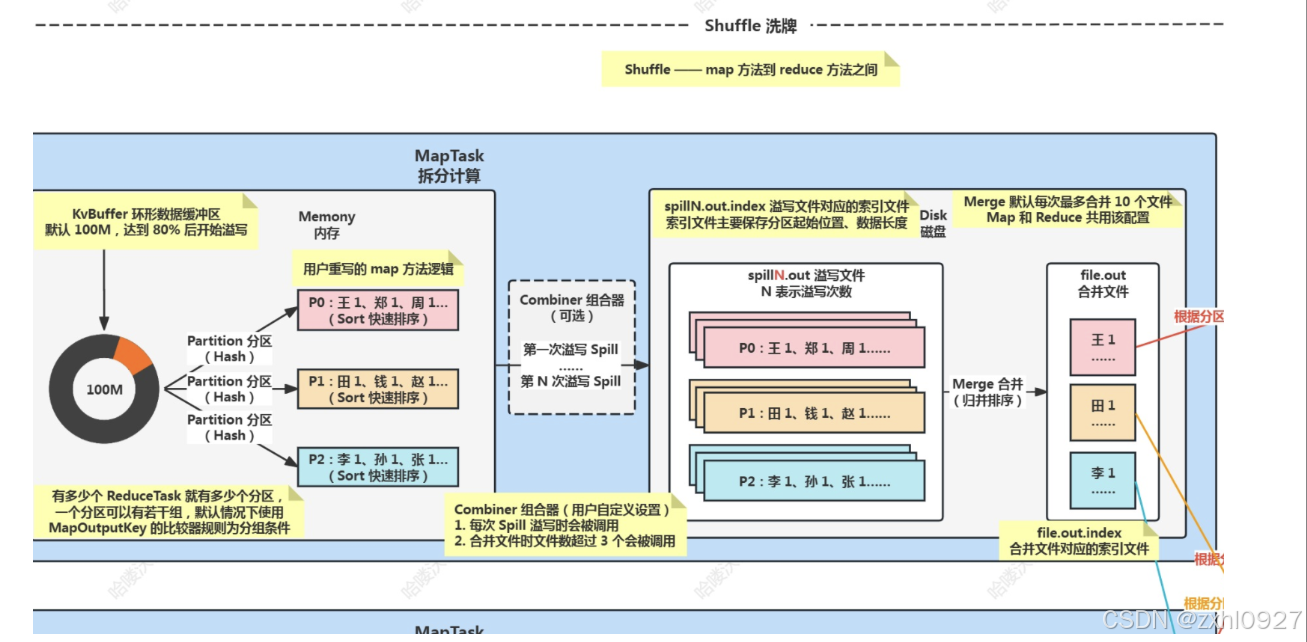
7)溢写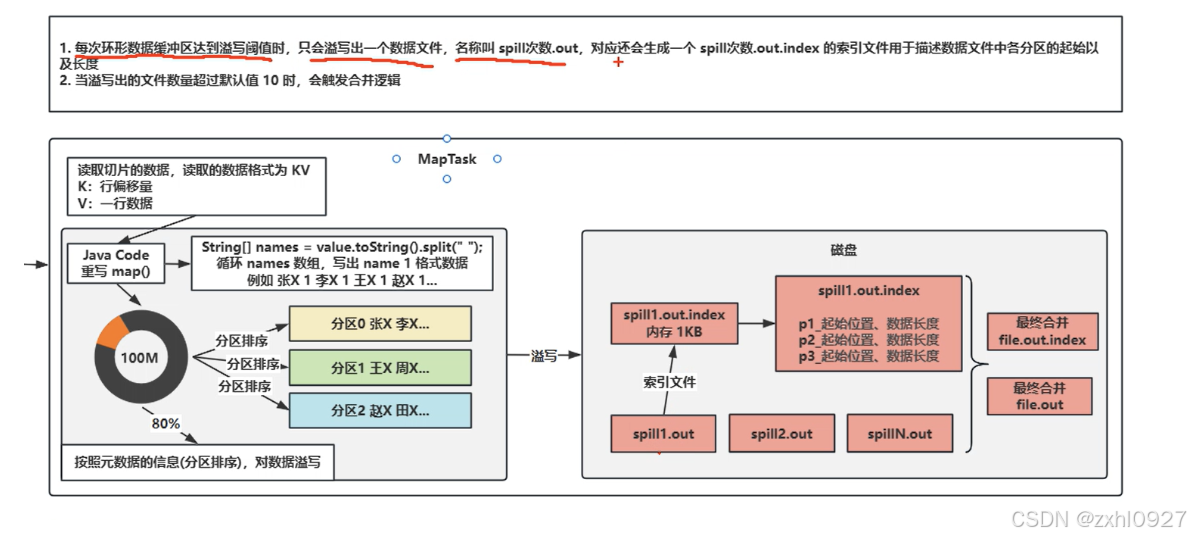
8)合并
9)组合器(可选)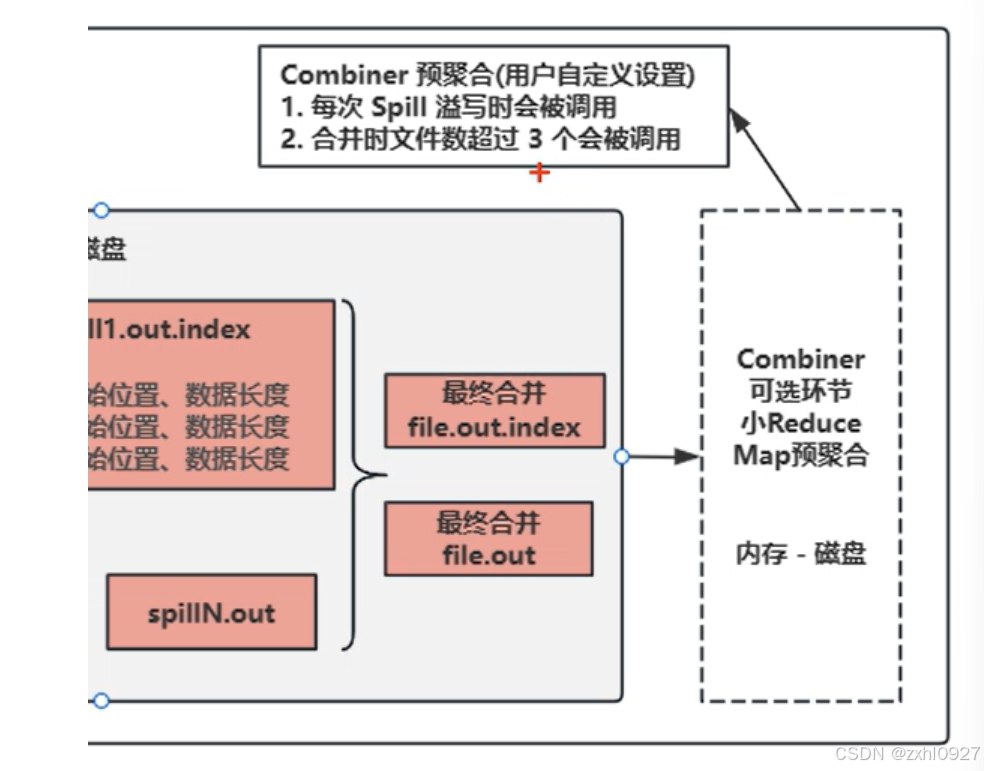
10)写出ReduceTask
合并;次数(网络io,磁盘io)优化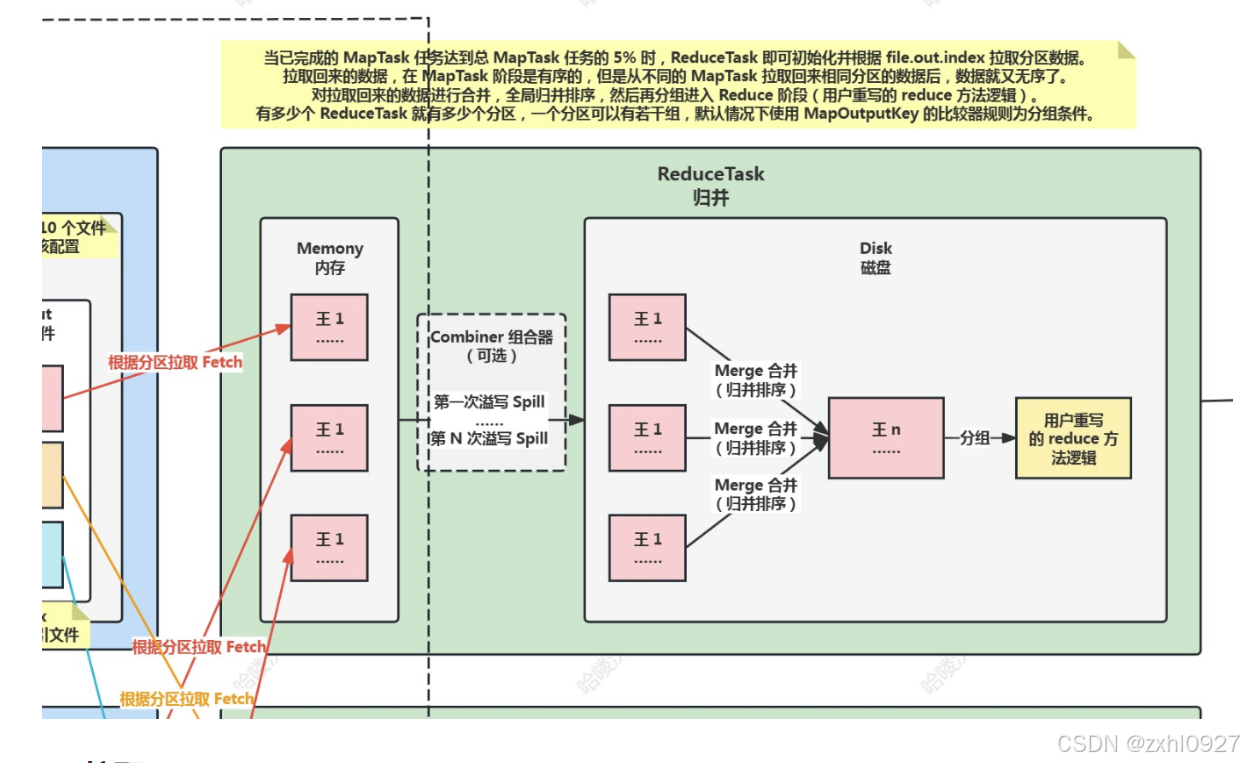
11)拉取
12)合并
13)分组归并
14)写出
3.Shuffle
4.YARN资源(内存.CPU)管理框架
hadoop1.0版本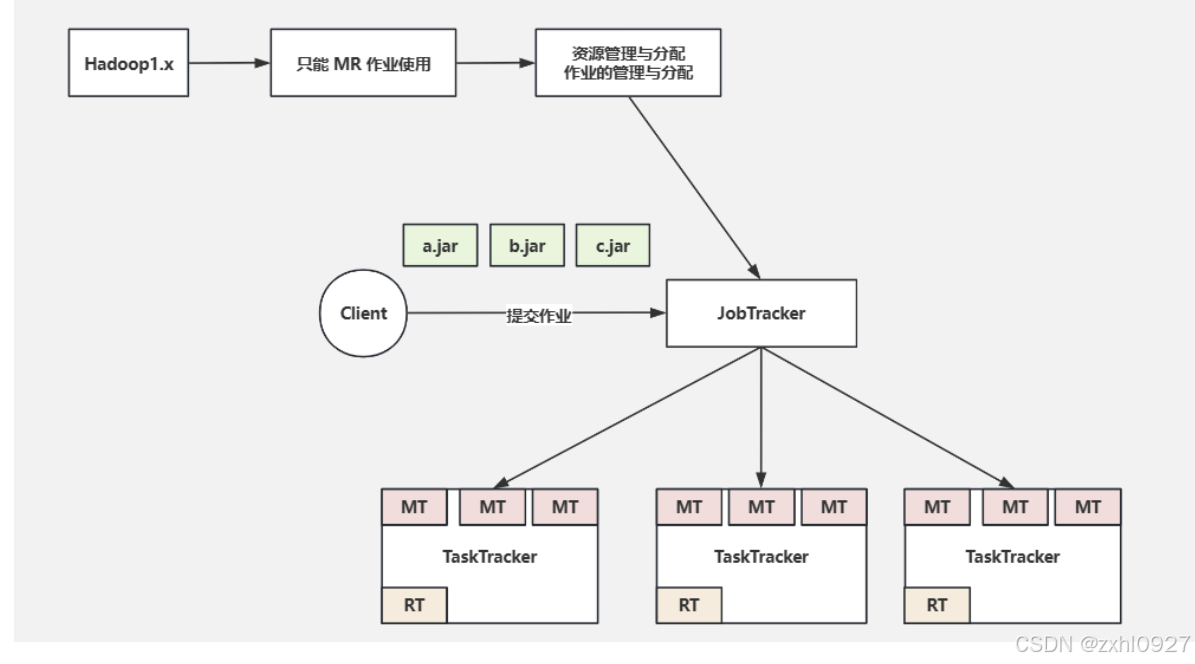
hadoop2.0版本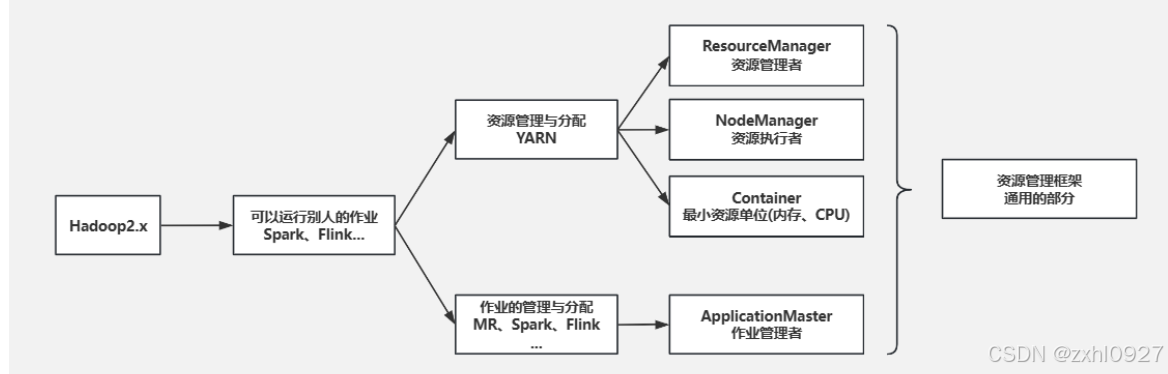
5.数据压缩(数据大小的优化)--使用CPU
应用的地方:(1)MapTask写出(2)ReduceTask写出
1)
计算密集型(少用压缩):要进行大量的计算,消耗CPU资源
io密集型 :CPU消耗很少,任务的大部分都在等待io操作完成(因为io的速度远远低于CPU和内存的速度)
2)压缩比较
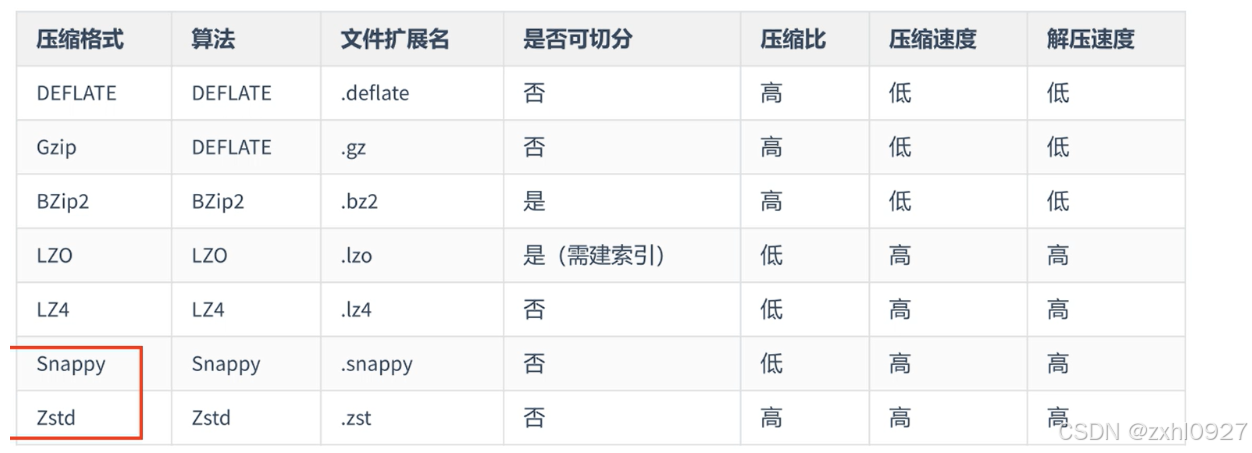
MapTask写出 推荐使用Snappy,Zstd(速度和效率)
ReduceTask写出的数据需要考虑是否是下一个作业的入口数据:
a:如果是,不推荐使用不可切分压缩算法,推荐使用BZips.
b:如果计算过的结果无需进行再次计算,就是归档存储,且后续在计算的可能性也比较小,推荐使用高比例压缩算法Gzip.BZip2,节省存储空间。
6.MR优化
1).小文件优化:
a.尽量不要上传;b.使用FileInputFormat读取数据的时候实现类CombineFileInputFormat读取数据,在读取数据的时候进行合并
2).数据倾斜:
产生的原因:
四种解决方案:
1)不使用默认的Hash分区算法,采用自定义分区
memory :内存 vcore :CPU
3).推测执行
4).MapReduce执行流程
Map(修改时不要超过yarn上限):
a 临时文件:
b.分片:调整分片大小
c.资源
d.环形缓冲区&溢写
e.合并
f.输出
组合器:
压缩: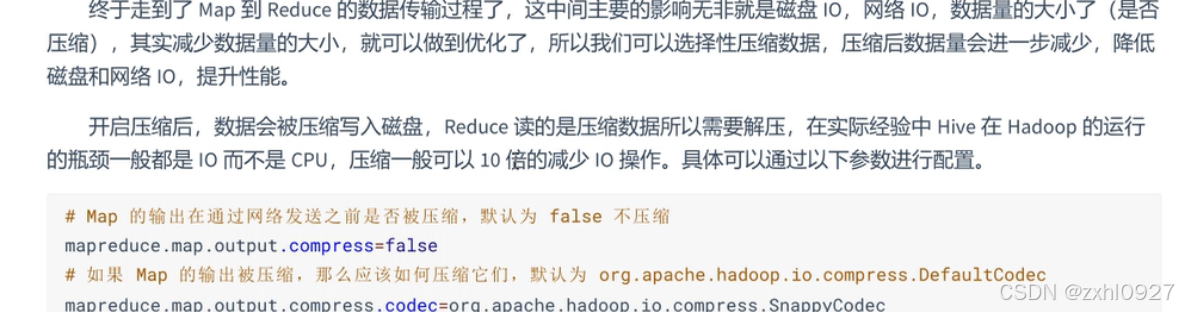
响应线程
g.容错
Reduce:(修改时不要超过yarn上限)
a.资源
b.拉取
c.缓冲区&溢写
d.合并
e.读缓存



















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









