






Kylin从入门到精通
1.特点
标准 SQL 接口,支持超大数据集,亚秒级响应,可伸缩性和高吞吐率,BI(商务智能) 及可视化工具集成
2 核心
1)数据仓库
2)OLAP
MOLAP(多维 OLAP)–不支持事务。MOLAP 是基于多维分析的 OLAP 系统,一般对存储有优化,进行部分**预计算,**查询性能最高,但查询灵活性有限制。MOLAP 将 OLAP 分析所用到的多维数据物理上存储为多维数组的形式,形成“立方体”的结构。Kylin 就属于 MOLAP 系统。
ROLAP(关系 OLAP)。ROLAP 是更偏向传统关系型的 OLAP 系统,ROLAP 又分为两类:一类是 MPP 数据库,另一类是 **SQL 引擎。**MPP 数据库是完整的数据库,一般需要把数据导入到库中进行 OLAP 分析,入库时对数据分布进行优化,进而获得后期查询性能的提升,提供灵活的即席查询能力,但无法支持超大数据量的查询。SQL 引擎只提供SQL 执行能力,不负责具体的数据存储。
HOLAP(混合 OLAP)–支持事务:把 MOLAP 和 ROLAP 两种结构的优点结合起来。例如 HTAP(HTAP = OLTP + OLAP),典型代表 PingCAP 的 TiDB;再或者 HSAP(Hybrid Serving/Analytical Processing),典型代表 Alibaba 的 Hologres。
3)BI(商务智能)
用现代数据仓库技术、在线分析技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。
4)维度和度量
5)事实表和维度表
6)Cube,Cuboid和Cube Segment
Cube(或 Data Cube),即数据立方体,是一种常用于数据分析与索引的技术;它可以对原始数据建立多维度索引。通过 Cube 对数据进行分析,可以大大加快数据的查询效率。
Cuboid 在 Kylin 中特指在某一种维度组合下所计算的数据。
多个Cuboid为一个Cube
Cube Segment 是指针对源数据中的某一个片段,计算出来的 Cube 数据。通常数据仓库中的数据数量会随着时间的增长而增长,而 Cube Segment 也是按时间顺序来构建的。
3.工作原理
Kylin 的核心思想就是 Cube 预计算,理论基础是空间换时间,把高复杂度的聚合运算、多表联结等操作转换成对预计算结果的查询。
4.技术架构
下面红色字体
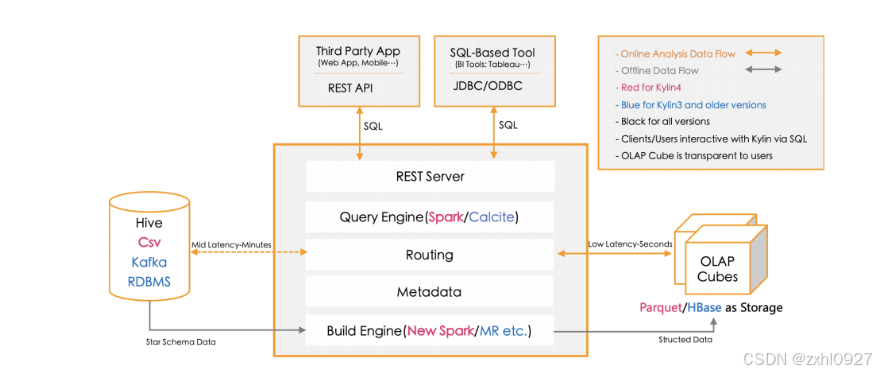
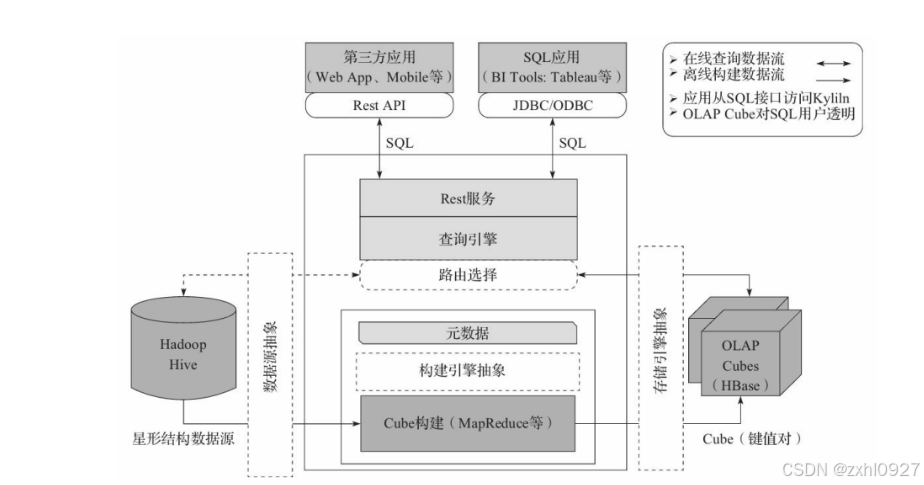
5.增量构建
不以日为单位创建新的 Segment, 而是以 N 天为单位创建新的 Segment
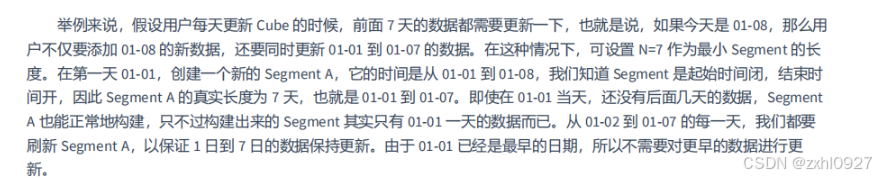
由此可以看到,在任意一天内,我们只需要同时照顾两个 Segment,第一个 Segment 主要以刷新近期数据为主,第二个 Segment 则兼顾了加入新数据与刷新近期数据。这个过程中可能存在少量的多余计算,但是每天多余计算的数据量不会超过 N 天的数据量。这对于 Kylin 整体的计算量来说是可以接受的。根据业务场景的不同,N 可能是 7 天,也有可能是 30天,我们可以适度地把最小的 Segment 设置成比 N 稍微大一点的数字。
6.工具集成
1).JDBC
a.Statement(不支持占位符)-----有谓词下压
b.PreparedStatement(支持占位符)
2).Restful API
a.Query API–查询
b.Cube API–构建
3).Zeppelin
一个让交互式数据分析变得可行的基于网页的 Notebook。基于 Web 的笔记本,支持以 SQL、Scala、Python、R 等语言进行数据驱动的、交互式的数据分析和协作文档。
7.构建优化
1)Cube planner

2)Cuboid 剪枝优化
a.聚合组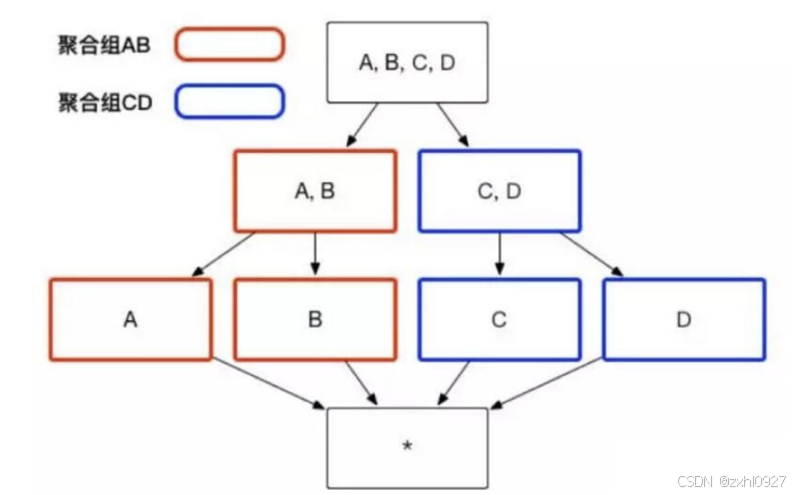
b.联合维度
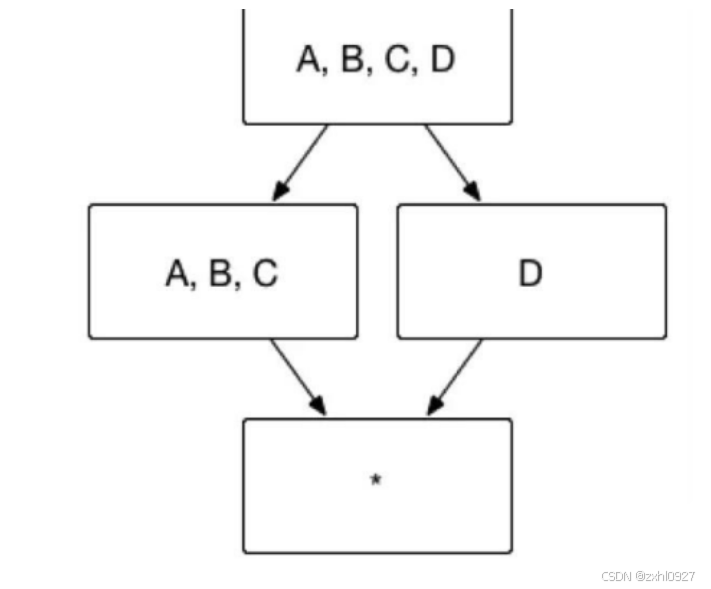
c**.** 层级维度:层级维度表示带层级的 Dimension。如果维度之间有层级关系,如:年 -> 月 -> 日,要求子级的父级必须存在。
d.强制维度 :所有的查询请求中都存在 GROUP BY 这个维度,那么这个维度就被称为强制维度,只有包含此维度的 Cuboid 会被生成。
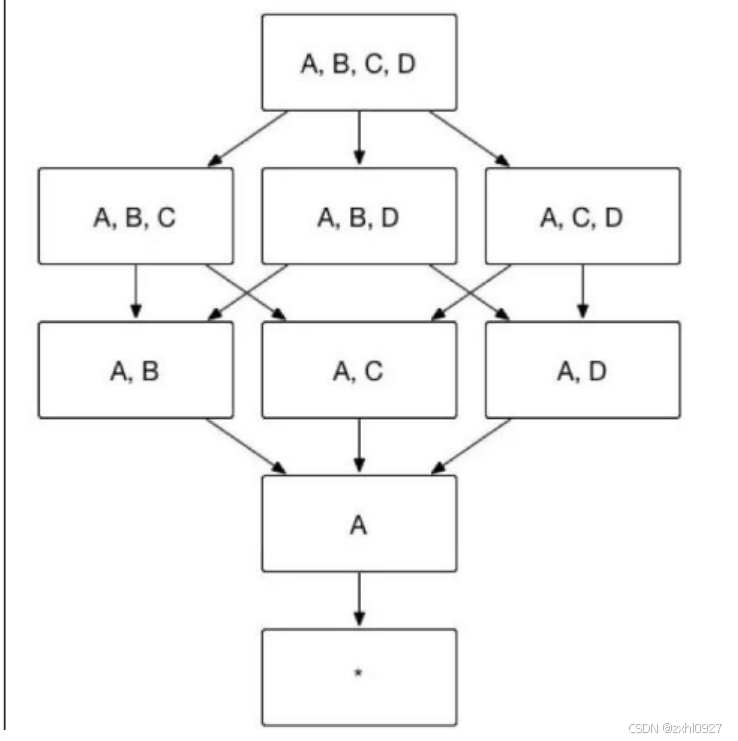
e.衍生维度:在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实就是使用事实表上相应的外键)来替代它们。
Kylin 会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。只有维度表才可以创建衍生维度,事实表无法创建。
3)Rowkey 优化
a.Rowkey 顺序调整

parquet(列式存储)
b. 维度编码调整
c.按照维度分片
4)Spark 优化
a.使用适当的 Spark 资源和配置来构建 Cube
b.自动设置 Spark 配置
c.根据实际情况手动设置 Spark 配置
5)全局字典优化(实现精确计数)
基于 Spark 的全局字典: Kylin 使用预计算技术来加速大数据分析,在 Cube 的增量构建过程中,为了避免由于对不同时间段分别构造字典而导致最终去重结果出现错误,一个 Cube 中的所有 Segments 都将使用同一个字典,即全局字典。
Kylin 4.0 构建全局字典的方式是基于 Spark 进行分布式的编码处理,减小了单机节点的压力,构建字典数量能够突破整型最大数量的限制。

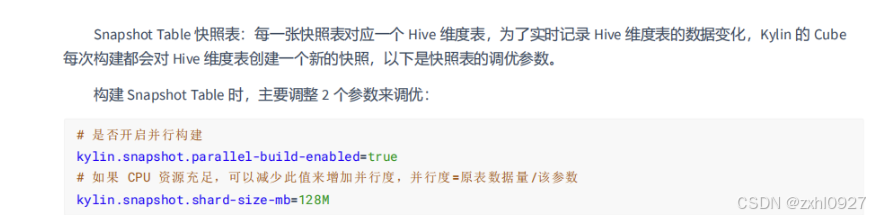
6)快照表优化
8.查询优化
1)使用排序列快速读取 Parquet 文件
2)使用 Shard By 列裁剪 Parquet 文件
3)减少小的或不均匀的 Parquet 文件
4)Spark 优化
a.将多个小文件读取到同一个分区
b.使用堆外内存
c.为每个查询设置不同的配置


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









