






上文已经提到Langchain4j基本的对接模型应用、日志、流式响应等功能。
Java对接AI大模型(一)【Langchain4j】_java ai大模型-优快云博客
可细心的同学使用的时候应该发现啦,这个大模型他并没有任何记忆。例如你的第一句话是我叫张三。而下一句话请问他你是谁时,LLM似乎并没有记下来你的话。所以本文主要目的就是来介绍一下Langchai4j框架对接的大模型如何让他有记忆。
注意:若要跟着实现,务必阅读上文文章过后再接着学习。
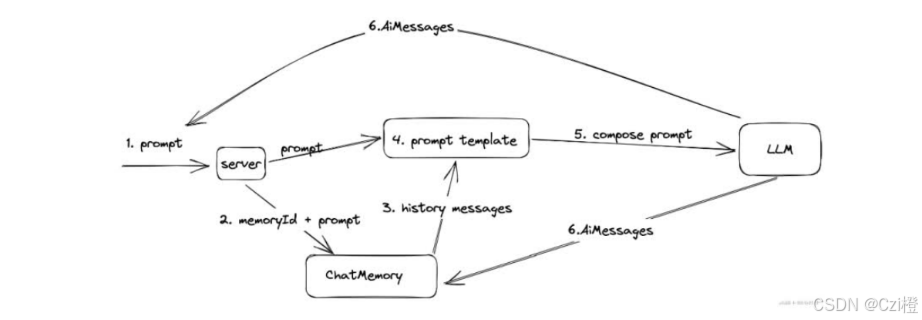
1. 内存记忆
在我们配置AiService时,我们可以配置一个chatMemory的属性
@Bean
public IChatStreamAssistant chatStreamAssistant(){
return AiServices.builder(IChatStreamAssistant.class)
.streamingChatLanguageModel(streamingChatLanguageModel())
.chatMemory(语言记忆)
.build();
}在Langchain4中提供了两个内存记忆。一种是按消息,另一种是按token.

- Message
- 属于对话结构的逻辑划分,直接影响模型对上下文的理解。例如,在API调用中需明确区分用户输入和助手回复的message,以保持对话连贯性。
- 指对话中的一条完整语义单元,通常包含角色(如用户或助手)和内容(如具体文本)
- Token
- 是模型处理文本的最小单位,通过分词算法(如BPE)将文本拆分为子词或字符。例如,英文单词"unhappy"可能被拆分为["un", "happy"]两个token,而中文词“你好”可能被拆为单个token或多个token,具体取决于分词方式。
- 是模型计算和内存管理的基础单位。模型的输入长度限制(如GPT-4的8k或32k上下文窗口)由token数量决定,而非message数量。例如,一条长message可能包含数百个token。
| 维度 | Message | Token |
| 本质 | 对话的语义单元 | 文本的处理单元 |
| 作用范围 | 对话结构管理 | 模型计算与资源消耗 |
| 限制因素 | 对话逻辑的复杂性 | 模型的最大上下文长度(如4k/8k tokens) |
| 典型应用 | 多轮对话的上下文维护 | 文本生成、成本核算、输入长度控制 |
1.1. MessageWindowChatMemory
我们先来查看按消息是如何配置内存记忆.Langchain4j为我们提供了一个MessageWindowChatMemory类用来构建消息的内存记忆的配置。
/**
* 消息窗口管理
* @return MessageWindowChatMemory
*/
@Bean
public MessageWindowChatMemory messageWindowChatMemory(){
return MessageWindowChatMemory.builder()
//内存记忆唯一标识id
.id("1")
//记忆最大消息条数
.maxMessages(3)
.build();
}我们需要配置他的最大消息条数,意义其实就是你输入了多少句话 * 2(大模型回复你的消息也算一条消息),便最多记忆配置的最大的多少句话.
例如(此时配置最大条数为三):
- 我是小明
- 我是谁 (回答 : 小明)
- 我是谁 (回答 : 未知)
1.2. TokenWindowChatMemory
/**
* token窗口管理
* @return TokenWindowChatMemory
*/
@Bean
public TokenWindowChatMemory tokenWindowChatMemory(){
return TokenWindowChatMemory.builder()
.maxTokens(1000, new OpenAiTokenizer())
.build();
}我们需要配置token的最大限制以及按何种token分词分析器。
我知道你可能还是对于token和message的区别不太理解。请看下面的例子
1.2.1. 场景设定
窗口限制:
- MessageWindowChatMemory:保留最近的 3 条消息。
- TokenWindowChatMemory:保留最近的 20 个令牌(假设每条消息的令牌数不同)。
1.2.2. 对话历史
- 用户消息 A:5 令牌 → 助手回复 A':3 令牌
- 用户消息 B:8 令牌 → 助手回复 B':4 令牌
- 用户消息 C:7 令牌 → 助手回复 C':2 令牌
- 用户新消息 D:10 令牌
1.3. 1. MessageWindowChatMemory 的行为
- 用户消息A → 当前消息数1(保留A)。
- 助手回复A' → 消息数2(保留A, A')。
- 用户消息B → 消息数3(保留A, A', B)。
- 助手回复B' → 消息数4 → 驱逐最旧的A → 保留A', B, B'。
- 用户消息C → 消息数4 → 驱逐最旧的A' → 保留B, B', C。
- 助手回复C' → 消息数4 → 驱逐最旧的B → 保留B', C, C'。
最终保留:B', C, C'(3条消息)。
关键点:每次新增消息时立即触发检查,超出则逐出最旧的一条
1.4. 2. TokenWindowChatMemory 的行为
- 用户消息A(5) → 总令牌5 ≤20 → 保留A。
- 助手回复A'(3) → 总令牌8 ≤20 → 保留A, A'。
- 用户消息B(8) → 总令牌16 ≤20 → 保留A, A', B。
- 助手回复B'(4) → 总令牌20 ≤20 → 保留A, A', B, B'。
- 用户消息C(7) → 总令牌27 >20 → 逐出最旧的A(5)→ 剩余22 → 仍超限 → 逐出A'(3)→ 剩余19 → 保留B, B', C。
- 助手回复C'(2) → 总令牌19+2=21 >20 → 逐出最旧的B(8)→ 剩余13 → 保留B', C, C'。
最终保留:B', C, C'(总令牌4+7+2=13)。
关键点:每条消息加入时立即触发令牌计算和驱逐
2. 磁盘记忆
上述的配置仅仅只满足了内存记忆,什么叫只满足内存记忆呢?就是你服务器已关闭,你说过的话大模型他老人家又忘啦。所以我们要是想我们说过的消息被记忆,还得配置持久化。
在Langchain4j当中,提供了持久化的接口ChatMemoryStore,我们去实现他即可。
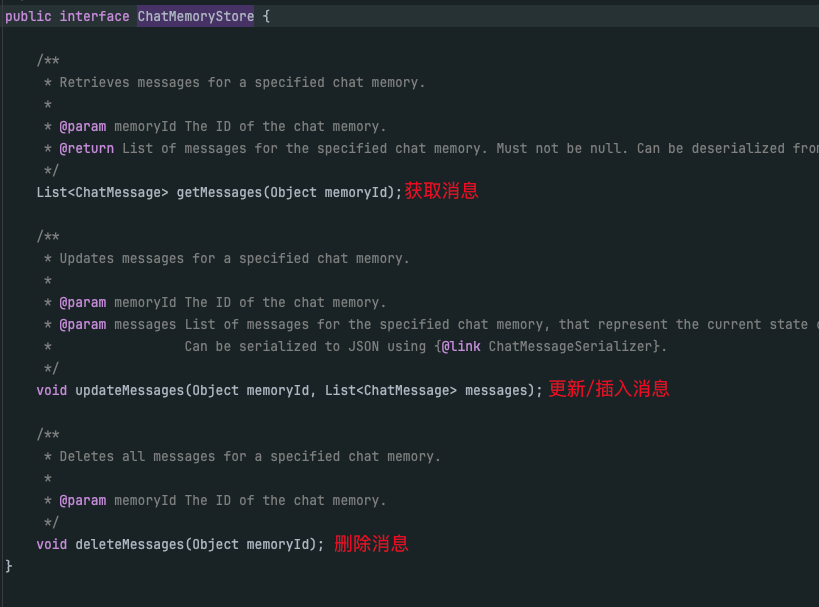
在此之前,我们还得需要学习一个持久化的数据库,MapDB,这是Langchain4j官方使用的数据库。
MapDB 是一个专为 Java 设计的嵌入式数据库引擎,提供高性能、轻量化的数据存储解决方案。以下是其核心特性与功能:
- 嵌入式数据库:直接运行在 JVM 中,无需独立服务器,适合集成到 Java 应用中13。
- 多存储模式:支持磁盘存储(持久化)和堆外内存存储(Off-Heap,类似 C 的 malloc/free)14。
- 数据结构丰富:提供并发的 Map、Set、List、Queue 等数据结构,兼容 Java 集合 API36。
| 特性 | 说明 |
| 高性能 | 优化后支持多核环境下的线性扩展,适合高并发场景34。 |
| 轻量级 | 核心 JAR 文件仅 160KB,无外部依赖5。 |
| 事务支持 | 提供 ACID 事务、MVCC(多版本并发控制),确保数据一致性37。 |
| 模块化设计 | 可配置缓存机制(减少反序列化开销)、异步写入引擎、压缩/加密等45。 |
| 易用性 | 通过 DBMaker 类简化配置,API 类似 Java 原生集合操作 |
2.1. mapDb的使用
引入mapDb数据库依赖
<dependency>
<groupId>org.mapdb</groupId>
<artifactId>mapdb</artifactId>
<version>3.0.10</version>
<exclusions>
<exclusion>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
</exclusion>
</exclusions>
</dependency>测试用例
public class MapDBExample {
public static void main(String[] args) {
//创建或打开一个
File dbFile = new File("mydb");
DB db = DBMaker.fileDB(dbFile)
.make();
HTreeMap<String, String> map = db.hashMap("myMap").
keySerializer(Serializer.STRING).
valueSerializer(Serializer.STRING).
createOrOpen();
map.put("key1", "value1");
map.put("key2", "value2");
//提交事务以确保数据被持久化到磁盘
db.commit();
//关闭数据库连接
db.close();
//重新打开数据库以检索数据
db = DBMaker.fileDB(dbFile).make();
map = db.hashMap("myMap").
keySerializer(Serializer.STRING).
valueSerializer(Serializer.STRING).
createOrOpen();
//从Map中检索数据
String value1 = map.get("key1");
String value2 = map.get("key2");
System.out.println("Value for key1: " + value1);
System.out.println("Value for key2: " + value2);
//关闭数据库连接
db.close();
}
}2.2. 具体使用
定义PersistentChatMemoryStore实现ChatMemoryStore接口
@Slf4j
public class PersistentChatMemoryStore implements ChatMemoryStore {
private final DB db = DBMaker.fileDB("memory.db")
.transactionEnable()
.make();
private Map<String,String> map = db.hashMap("messages", Serializer.STRING, Serializer.STRING).createOrOpen();
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String json = map.get((String) memoryId);
return messagesFromJson(json);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
String json = messagesToJson(messages);
log.info("updateMessages: {}", json);
map.put((String) memoryId, json);
db.commit();
}
@Override
public void deleteMessages(Object memoryId) {
map.remove((String) memoryId);
db.commit();
}
}
然后配置到chatMemory当中即可。
/**
* token窗口管理
* @return TokenWindowChatMemory
*/
@Bean
public TokenWindowChatMemory tokenWindowChatMemory(){
return TokenWindowChatMemory.builder()
.maxTokens(1000, new OpenAiTokenizer())
.chatMemoryStore(persistentChatMemoryStore())
.build();
}
/**
* 持久化存储
* @return ChatMemoryStore
*/
@Bean
public ChatMemoryStore persistentChatMemoryStore(){
return new PersistentChatMemoryStore();
}
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









