






一些规定

预定义标识符不是关键字

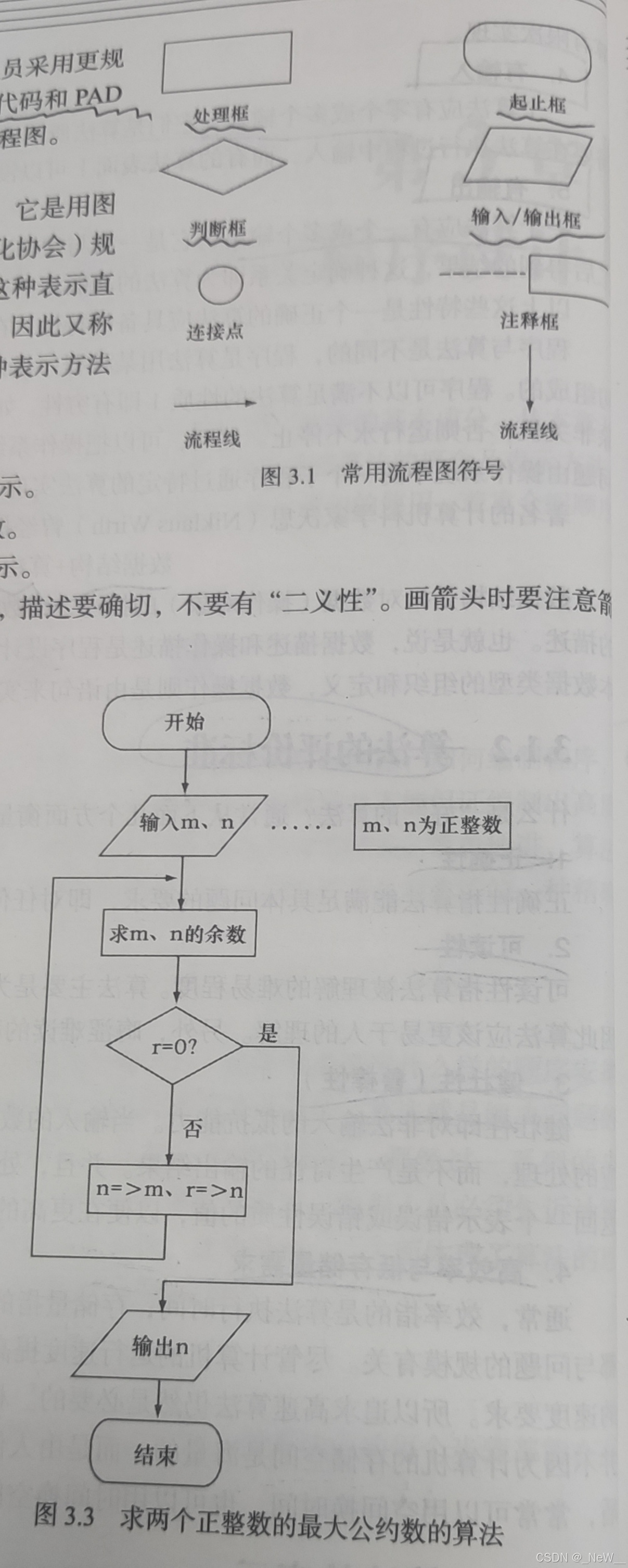
流程图
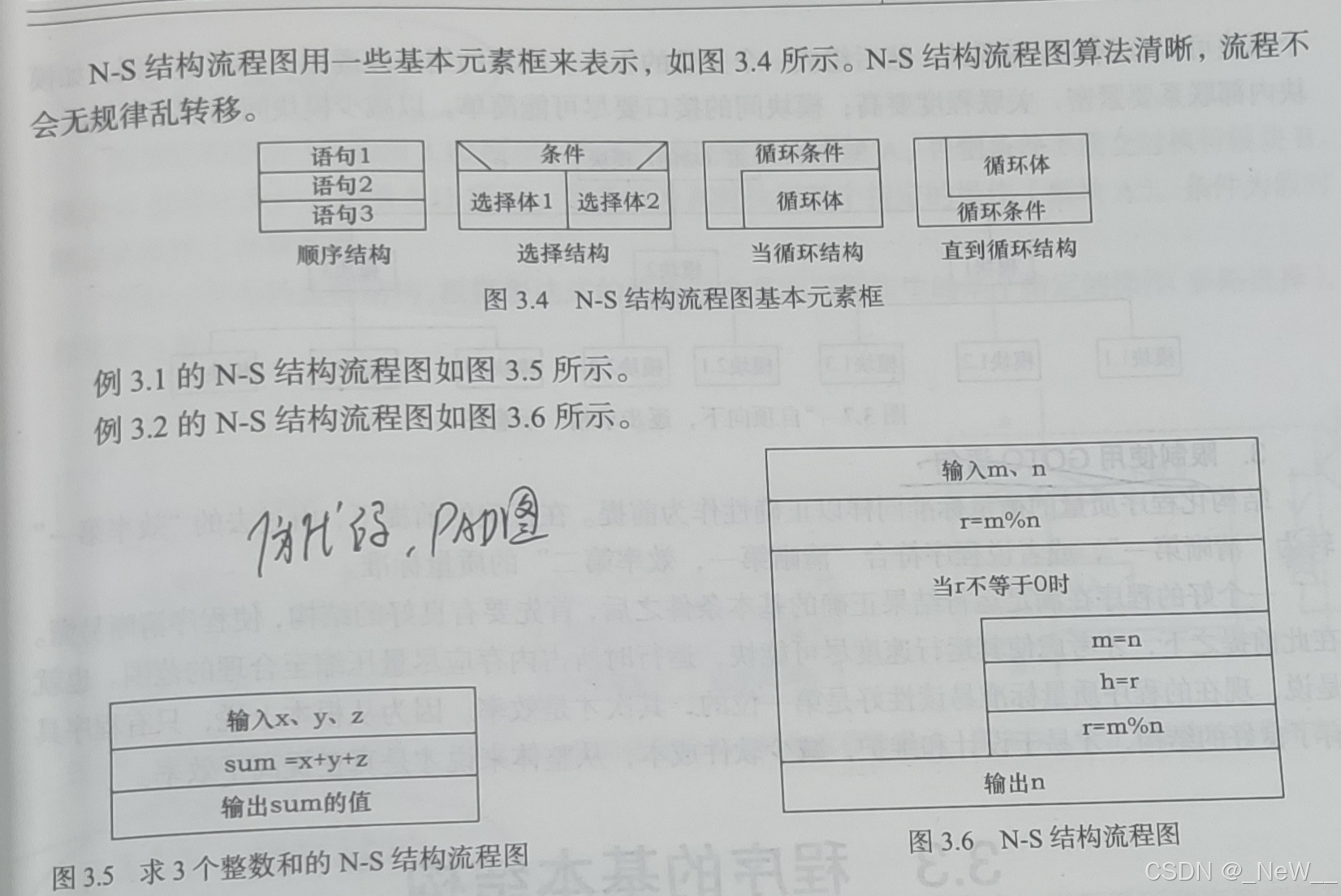
算法具有以下特性:有穷性,确定性,可行性,有输入,有输出
算法的评价标准:正确性,可读性,健壮性(鲁棒性),高效率与低存储量需求
算法的描述方法:流程图,结构图,伪代码,PAD图
结构化程序设计方法遵循的原则:自顶向下,模块化,限制使用GOTO语句




在c程序中,变量名代表存储器中的一个位置
b=(-1)&&(-1)得b的值为1,因为-1非0
b=(-1)&(-1)的b得值为-1
因为-1的补码全是1,两者且之后还全是1
数组的大小是固定的,所以数组元素的类型必须相同
当一个指针指向数组时,int a[10]; int *p=a;
文件打开失败,使用exit(1)


1.C语言的每条可执行语句最终都将被转换成二进制的机器指令。
2.结构化程序设计由3种基本结构组成(顺序结构、选择结构和循环结构),3种基本结构组成的算法可以完成任何复杂的任务。
3.用C语言实现的算法可以没有输入但必须有输出操作。
4.格式化输入函数scanf的返回值是输入的数据的个数。
5.x=1,y=2;printf("%d",x+y,x++,y++);
从右往左计算,最终打印的是x+y的值
6.- scanf("a=%d,b=%d",&a,&b) 中,格式控制字符串 "a=%d,b=%d" 规定了输入的格式。正确的输入是a=25,b=25
7.int m=0256,n=256;printf("%o %o\n",m,n);
结果为256 400
8.定义float x;unsigned y;合法的输入为scanf("%f%u",&x,&y)
9.程序调试是指对程序进行查错和排错
10.对c的源程序编译是指将C源程序翻译成目标程序
11.输出时制表符(\t)有8个空格
12.unsigned t=65535;
printf("%u,%o,%x,%d",t,t,t,t)
65535,177777,ffff,-1
65535的二进制数为16个1
在计算机中,数据以补码形式存储。当使用 %d 输出 unsigned int 类型的 65535 (二进制 1111111111111111 )时,系统将其补码形式的二进制数据按照有符号整数的规则去解析,最高位为 1 被视为负数,通过补码转换原码的规则得到原码 1000000000000001 ,进而得出十进制的 -1 并输出。所以最终看到的 -1 是解析后的十进制结果,不是补码本身。
13.scanf("%2d%*3d%2d", &a, &b);
%*3d表示会跳过三个数。例如输入1234567,得到的a=12,b=67
14.%的运算对象必须是整数型
15.Switch语句中,不是必须有default部分,才能构成完整的Switch语句。
16.若有说明static int a[3][4];则数组a中各元素可在程序编译阶段得到初值0
17.- “#define”:不是C语句,而是C语言中的预处理指令。用于在编译预处理阶段进行文本替换等操作,如“#define PI 3.14159”,就是将程序中后续出现的PI都替换为3.14159,它不遵循C语句以分号结尾的规则。
- “printf”:严格来说不是C语句,而是C标准库中的一个函数。但“printf”常出现在C语句中,如“printf("Hello, World!");”就是一个完整的C语句,这条语句调用了printf函数来实现输出功能。
18.
& : 0&0=0 0&1=0 1&0=0 1&1=1
| : 0|0=0 0|1=1 1|0=1 1|1=1(有1则为1)
^ : 0^0=0 0^1=1 1^0=1 1^1=0(相同为0,不同为1)
^ | &(与,或,异或)的优先级小于左移右移(有左移先计算左移,有~(非)运算,先计算非)
从低到高的排列顺序为:“|”、“^”、“&”、“<<”、“>>”、“~” 。

先将i取反,然后j右移3位,最后或
1.取反完11110100
2.右移完(原本是19,00010011)变为了00000010
3.或完 11110110
因为答案是八进制,所以三位三位看,后两位都为6
19.

(1)“编译预处理”命令是C语句的一种形式。(×)
- 解题步骤及理由:编译预处理命令是在正式编译之前由预处理器处理的指令,比如 #include 、 #define 等。C语句是组成C程序执行部分的语句,像 printf 语句、赋值语句等,它们在编译后生成可执行代码。编译预处理命令不属于C语句,所以答案为×。
(2)如果为调用库函数而用“#include”命令来包含相关的头文件,则用尖括号,以节省查找时间。(√)
- 解题步骤及理由:当使用 #include 包含头文件时,若使用尖括号 <> ,预处理器会直接到系统默认的头文件存放目录去查找头文件;若使用双引号 "" ,预处理器会先在源文件所在目录查找,若找不到再到系统默认目录查找。对于系统库函数的头文件,使用尖括号能避免在源文件目录不必要的查找,节省查找时间,所以答案为√。
(3)语句#define PI 3.1415926;定义了符号常量PI。(×)
- 解题步骤及理由:在宏定义 #define PI 3.1415926 中,不需要在末尾加分号。宏定义只是简单的文本替换,预处理器看到 PI 就会用 3.1415926 进行替换。加上分号后,替换时会把分号也包含进去,可能导致程序错误,所以答案为×。
(4)宏定义可以带有形参,程序中引用宏时,可以带有实参。在编译预处理时,实参与形参之间的数据是单向的值传递。(×)
- 解题步骤及理由:宏定义带有形参时,在编译预处理阶段是进行简单的文本替换。比如定义 #define MAX(a, b) ((a) > (b)? (a) : (b)) ,当使用 MAX(x, y) 调用时,是将 x 和 y 直接替换到宏定义的表达式中,并非像函数那样进行单向的值传递 。函数调用时实参和形参之间才是单向的值传递,所以答案为×。
(5)预处理命令是在程序运行时进行处理的,过多使用预处理命令会影响程序的运行速度。(×)
- 解题步骤及理由:预处理命令是在编译之前由预处理器进行处理的,不是在程序运行时处理。预处理阶段主要完成头文件包含、宏替换等操作,对程序运行速度并无直接影响。程序运行速度主要和编译后的代码执行效率等因素有关,所以答案为×。
编译时,编译系统不会为局部变量分配内存单元,而是在程序运行时,当局部变量所在函数被调用时,编译系统才根据需要临时分配内存。调用结束,内存空间释放
全局变量在函数编译阶段分配内存
20.
在 #define PI 3.1415926
PI是符号常量
#define PI 3.1415926; 写题时注意后边加的分号,这样是错误的
在宏定义中, PI 被定义为 3.1415926 ,在编译预处理时,只是将程序中出现的 PI 原封不动地替换为 3.1415926 ,这本质上就是一种字符串的替换。宏名 PI 相当于一个字符串,在预处理阶段被另一个字符串 3.1415926 所替代
21.关于预处理命令的描述
- A选项:预处理不仅包括宏替换和文件包含,还包括条件编译等操作,该选项描述不全面,所以A错误。
- B选项:预处理指令不是C语句,C语句以分号结尾,而预处理指令通常独占一行,不以分号结尾,所以B错误。
- C选项:在C源程序中,只要行首以“#”标识的控制行都是预处理命令,这是预处理命令的典型特征,所以C正确。
- D选项:预处理是在编译之前进行的独立步骤,不是编译程序扫描的一部分,它主要处理以“#”开头的命令,为后续编译做准备,所以D错误。
22.宏定义的范围
分析选项A:
- #ifdef 是条件编译指令,它的作用是判断某个宏是否已经被定义。如果该宏已定义,则执行 #ifdef 和 #endif 之间的代码。它并不是用于解除宏定义的
分析选项B:
- endif 是与 #ifdef 、 #ifndef 等条件编译指令配套使用的结束标志,用于结束条件编译块。它本身没有解除宏定义的功能
分析选项C:
- 在C语言中,并没有 #indefine 这样的指令,这是一个错误的写法
分析选项D:
- #undef 指令的作用就是取消前面定义的宏。当使用 #undef 指令后跟宏名时,就可以提前解除该宏定义的作用,使得在 #undef 之后,该宏不再起作用 。所以在C语言中,可用 #undef 来提前解除宏定义。
23.&&的优先级高于||
int x=-1;z=++x&&++x||++x;
z=1,x=1
int x=-1;z=++x||++x&&++x;
z=1,x=2
因为 || 的左边操作数为 0 ,所以需要计算 || 右边的表达式 ++x&&++x 。右边表达式值为1,最后0||1=1。
1.转义字符
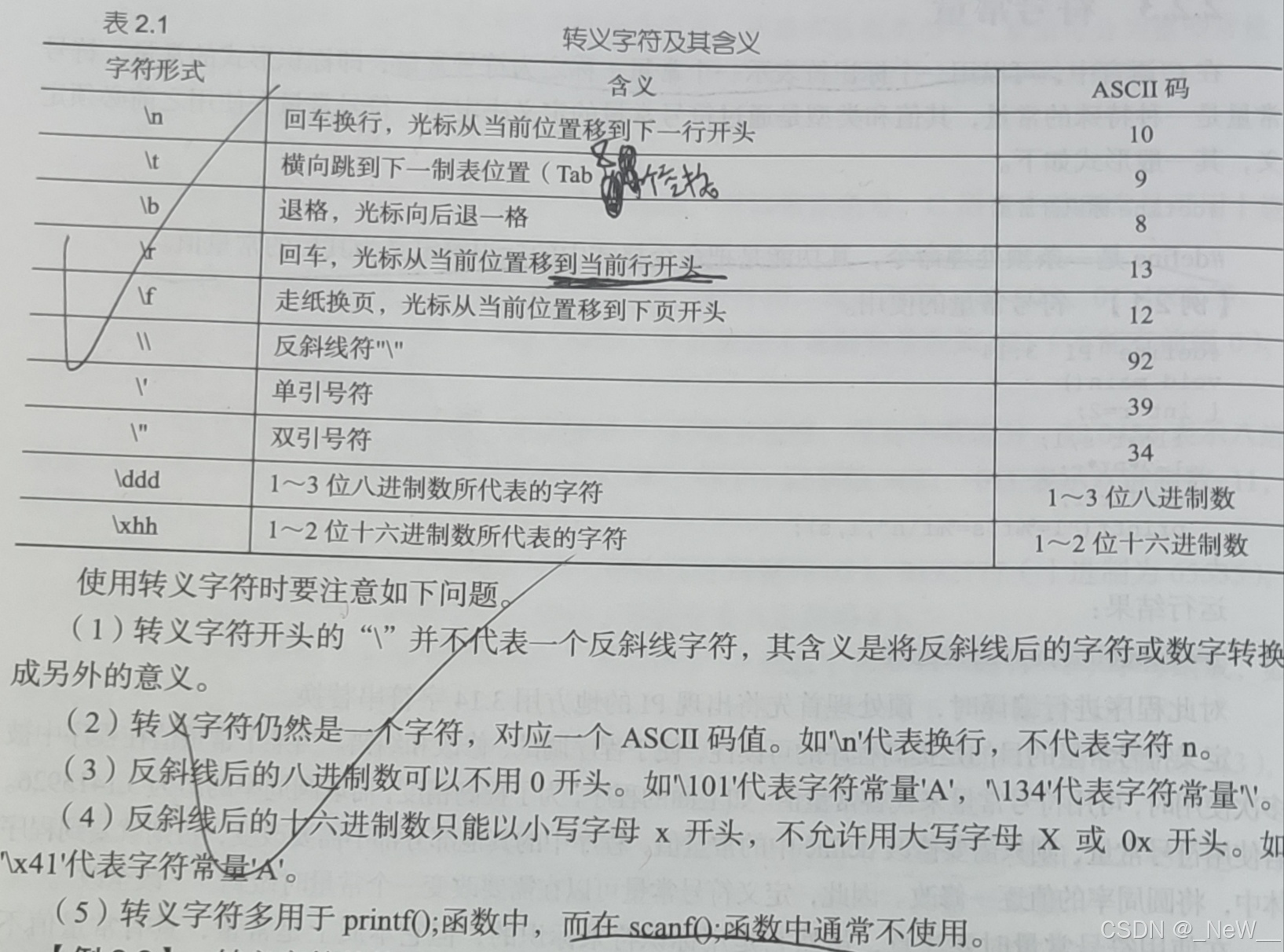
转义字符以"\",当转义字符后跟八进制数时,直接以 \ 开头加八进制数字,如" \101 ",表示字符'A'。而当转义字符后跟十进制数时,需要使用 \x 开头,后面跟十六进制数字来表示。例如," \x41" 也表示字符 'A' ,因为十六进制的 41 转换为十进制也是 65 ,对应ASCII码中的 'A' 。可在"\"后跟1-3位八进制数,也可在"\x"后跟1-2位十六进制数。
类型转换

2.float
单精度实型提供七位有效数字
比如float x=3.6;printf("%f",x); 结果为3.600000
3.整型常量和实型常量
整数常数以0开头的数是八进制数,以0x开头的数
长整型常量后加后缀L或l,无符号常量后加后缀U或u。
- A选项:“−012”是合法的整型常量,它是一个八进制整型常量的表示形式。以0开头表示八进制数,这里“−012”表示负的八进制数12 ,在C语言等编程语言中这种表示是允许的。
- B选项:“8E2”不是合法的整型常量。在C语言中,“E”或“e”用于表示指数形式,是实型常量的表示方式,用于科学计数法,如“1.2E3”表示1.2×10^{3} 。这里“8E2”不符合整型常量的表示规则,不能表示整型数。
- C选项:“123L”是合法的整型常量,“L”(或“l”)表示长整型,说明该整型常量是长整型数据类型,在需要表示较大范围整数时使用,这种表示在C语言等编程中是正确的。
- D选项:“0×35”(应该是“0x35” ,十六进制表示法中一般用小写x )是合法的整型常量,它是十六进制整型常量的表示形式,“0x”开头表示十六进制数,“35”是十六进制的数值,在编程中用于表示十六进制整数。
- A选项:“E3”是不合法的实型常量。在科学计数法表示实型常量时,“E”(或“e”)前面必须要有数字部分(可以是整数或小数),后面跟的是整数指数。这里“E3”前面没有数字部分,不符合实型常量科学计数法的表示规则。
- B选项:“.123”是合法的实型常量,它是小数形式的实型常量表示,省略了整数部分,等同于“0.123” ,在C语言等编程中这种表示是允许的。
- C选项:“6.2e4”是合法的实型常量,这是科学计数法的表示形式,表示6.2×10^{4} ,“6.2”是数字部分,“e4”表示以10为底的指数为4 ,符合实型常量科学计数法的表示规则。
- D选项:“5.”是合法的实型常量,它是小数形式的实型常量表示,省略了小数部分,等同于“5.0” ,在编程中这种表示实型数的方式是可行的。
4.printf("%x",-1);
理解 printf 函数中 %x 格式控制符的作用:
- %x 是 printf 函数中的格式控制符,用于以十六进制无符号整数形式输出数据 。这里“无符号”意味着在输出时不考虑符号位,将数据看作一个无符号数进行十六进制表示。
分析 -1 在计算机中的存储形式:
- 在计算机中,整数通常以补码形式存储。对于有符号整数, -1 的原码是 10000000 00000000 00000000 00000001 (假设是32位系统),其反码是 11111111 11111111 11111111 11111110 ,补码是在反码的基础上加1,即 11111111 11111111 11111111 11111111 。
将补码形式转换为十六进制表示:
- 按照每4位二进制数对应1位十六进制数的规则进行转换。 1111 对应十六进制的 f 。
- 那么 11111111 11111111 11111111 11111111 从右到左每4位一组,分别转换为十六进制就是 ffffffff 。但题目中 %x 格式控制符输出的是小写十六进制数,所以结果为 ffff 。因为 %x 不输出符号,将 -1 对应的补码看作无符号数进行十六进制表示。
- 有符号输出:
- 常见格式控制符是 %d ,用于输出有符号十进制整数。当输出负数时,会显示负号“-” ,正数正常显示数字,前面无“+”。例如 int num = -5; printf("%d", num); 会输出 -5 。
- 无符号输出:
- 像 %u 用于输出无符号十进制整数, %x (或 %X )用于输出无符号十六进制整数 , %o 用于输出无符号八进制整数。无符号输出不考虑数字原本的符号,将其看作无符号数输出。例如 unsigned int num = 5; printf("%u", num); , %u 会把 num 当作无符号数输出。对于 %x ,就像题目中 printf("%x", -1); ,它把 -1 的补码按无符号数转换为十六进制输出 。
5.一些例题


2.编写程序,接受从键盘上输入的两个字符(都在'0'~'9'和'A'~'F'范围内 ),代表一个十六制数,然后输出与它相等的十进制数。例如,输入3A,输出58。
6.goto语句
goto语句强制中断执行本语句后边的语句,跳转到语句标号标识的语句继续执行程序。
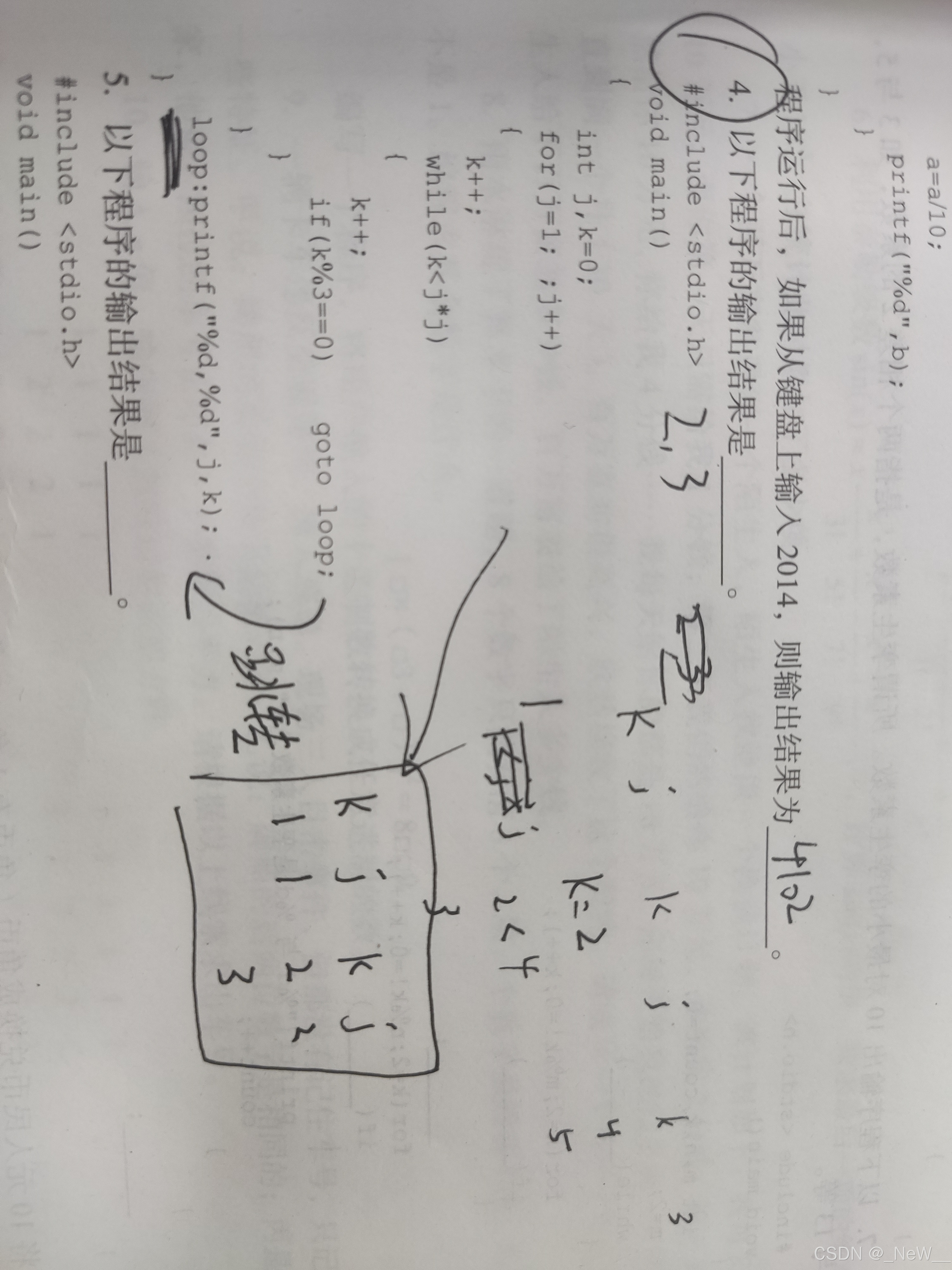
7.字符串
scanf("%s", s) 以 %s 格式说明符来读取字符串,它从输入流中读取字符,直到遇到空白字符或者到达输入缓冲区的末尾。它会把读取到的字符存储到指定的字符数组 s 中,并在末尾自动添加字符串结束符 \0 。
gets()
char str[100];
gets(str)
- 从标准输入读取字符,并将其存储到参数 str 所指向的字符数组中,直到遇到换行符或文件结束符。换行符不会被存储到字符数组中,而是会被替换为字符串结束符 \0 。
注意:strlen()是在string.h库函数中
strlen读到\0结束
char str[10]="Ch\nina";
strlen(str)的值为6
对于下面这种只能用sizeof()计算长度
sizeof在stdlib.h中
int a[]={1,2,3,4,5};
int len=sizeof(arr)/sizeof (int);
输出直接用printf("%s",str);但是只会输出到\0处
strcmp(str1,str2)
返回值等于0 str1=str2
返回值大于0 str1>str2
返回值小于0 str1<str2
- 对于 char x[] = "12345"; ,在C语言中,使用字符串常量初始化字符数组时,系统会自动在字符串末尾添加一个字符串结束标志 '\0' 。这里 "12345" 本身有5个字符,加上系统自动添加的 '\0' ,所以 x 数组的实际长度是6 。
- 对于 char y[] = {'1', '2', '3', '4', '5'}; ,这里是用字符常量逐个初始化字符数组,数组中只包含明确给出的5个字符,没有自动添加 '\0' ,所以 y 数组的长度是5。
字符数组与字符串
- 选项A:字符数组中不一定存放的是一个字符串。字符数组可以存放任意字符序列,只有当字符数组中存放的字符序列以 '\0' 结尾时,才能被看作是一个字符串。例如 char arr[] = {'a', 'b'}; ,它不是一个字符串,所以A错误。
- 选项B:不是所有的字符数组都可以被当作字符串处理。只有以 '\0' 结尾的字符数组才能按照字符串的方式进行处理,如 strlen 等字符串处理函数才能正确工作。像 char arr[] = {'a', 'b'}; 没有 '\0' 结尾,就不能当作字符串处理,所以B错误。
- 选项C:存放字符串的字符数组本质上还是数组,它具有数组的特性。所以可以像一般数组一样对数组中的单个元素进行操作,比如可以通过下标访问和修改单个字符,如 char str[] = "hello"; str[0] = 'H'; ,故C正确。
- 选项D:一个字符数组只有在以 '\0' 结尾时才能被认为是一个字符串。如果字符数组没有 '\0' 结尾,它只是一个普通的字符数组,不能等同于字符串,所以D错误。
函数中的变量名
分析选项A(extern):
- extern 关键字用于声明外部变量,它的作用是告诉编译器该变量在其他文件中定义,主要用于在多个文件间共享变量,而不是为了提高程序运行速度 。所以A选项不符合要求。
分析选项B(static):
- static 修饰的变量为静态变量。静态局部变量在程序运行期间只初始化一次,存储在静态存储区,它主要用于保留变量的值在函数调用之间不被销毁,以满足特定的编程需求,比如记录函数被调用的次数等,但它不是为了提高程序运行速度。静态全局变量用于限制变量的作用域在定义它的文件内,同样与提高运行速度无关。所以B选项不符合要求。
分析选项C(register):
- register 类型的变量称为寄存器变量。计算机的CPU访问寄存器比访问内存要快得多。当把自动变量或形参声明为 register 型时,编译器会尽可能将其存储在CPU的寄存器中,这样在程序运行过程中,对该变量的访问速度会加快,从而提高程序的运行速度 。所以C选项符合提高程序运行速度这一要求。
分析选项D(auto):
- auto 是自动变量的存储类型说明符,自动变量存储在栈区,其生命周期和作用域有特定的规则。但 auto 变量默认是在内存中存储,对其访问速度没有像 register 变量(若能存储在寄存器中)那样快,它不是专门为提高运行速度而设计的存储类型。
实参与形参
传值调用
当采用传值调用方式时,在函数调用时,系统会为形参分配新的存储单元,然后将实参的值复制到形参的存储单元中。实参和形参拥有各自独立的存储单元,对形参的修改不会影响到实参。
传址调用(指针传递等类似方式)
虽然在传址调用(如传递指针)时,实参(通常是指针变量或地址)和形参(也是指针类型)都指向同一块内存区域(比如传递一个指向变量的指针时,形参指针和实参指针指向同一个变量所在的内存地址),但实参和形参本身仍然是不同的存储单元,只是它们指向的目标内存单元是同一个。

汉诺塔问题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









