






 本文介绍了如何为可视化课程知识问答系统收集高质量数据,包括从山软智库获取课程资料、利用OCR技术处理PDF、进行文本预处理和向量化,以及使用Faiss向量数据库进行检索和RAG增强。重点讨论了如何通过GPT2模型生成答案和创建Prompt模板,以构建一个完整的知识问答系统。
本文介绍了如何为可视化课程知识问答系统收集高质量数据,包括从山软智库获取课程资料、利用OCR技术处理PDF、进行文本预处理和向量化,以及使用Faiss向量数据库进行检索和RAG增强。重点讨论了如何通过GPT2模型生成答案和创建Prompt模板,以构建一个完整的知识问答系统。
第一周:数据获取
对于可视化课程知识问答系统来说, 获取高质量的课程知识数据是非常重要的任务.
考虑到本项目面向的人群主要是山东大学软件学院的学生/老师, 我们需要采集高质量的课程知识资料. 校内维护的高质量课程复习资料可以从山软智库公开平台进行采集, 公开平台也可以获取到课程参考书目和百科资料. 对于获取到的多种资料, 需要进行数据预处理才可以转化为可使用的纯文本.
①获取山软智库维护的公开课程资料.
山软智库提供了一系列公开课程资料,这些资料涵盖了不同学科,并采用了多级目录的结构化形式,方便学习和查阅。通过获取这些资料,学习者可以系统地掌握各学科的知识。
这些课程资料通常以PDF格式提供,包含详细的课程内容和知识结构,帮助学习者更好地理解和应用所学知识。多级目录的设计使得资料的层次分明,查找和导航变得更加便捷。
下例图为山软智库的课程资料PDF(分学科含多级目录的结构化知识).

②通过参考教材获取资料.课程参考教材和参考书目内含大量结构化的知识.
课程参考教材和书目中包含大量结构化的知识,这些知识以清晰、系统的方式呈现,便于学习者查阅和理解。例如,教材中常常包括概念解释、理论背景、实践案例以及习题和解答,通过这种结构化的方式,学习者可以全面掌握理论知识并将其应用于实践中。
③通过百科内容获取资料. 高质量百科词条含对名词的多维解释和双向链接知识关联.
百科词条不仅提供了对名词和概念的详细解释,还通过双向链接的形式,关联了相关知识,使得学习者能够全面理解并探索相关主题。
百科内容的优势在于其丰富的知识层次和全面的解释。每个词条通常由专家或资深编辑撰写,内容经过多次审核,确保信息的准确性和可靠性。高质量的百科词条包括了概念的定义、历史背景、应用实例、最新研究进展等多维度的信息,为学习者提供了一个全面的知识视角。
此外,百科内容中的双向链接设计,使得学习者能够方便地跳转到相关词条,进行更深入的探索和学习。这种知识关联的方式,有助于构建一个完整的知识网络,使学习者在理解某一特定概念时,可以同时了解到与之相关的其他概念,从而形成系统的知识体系。
考虑前两种知识都是PDF形式, 需要通过OCR识别并提取为纯文字内容
在处理数据分析或文档处理时,PDF文档中的内容往往需要转换为纯文字形式以便于后续操作。为了实现这一目标,可以使用OCR技术。OCR技术能够自动识别PDF文档中的文字,并将其转换为可编辑的纯文字内容。

使用RapidOCR对获取到的PDF进行处理, 获取纯文字信息
RapidOCR是一款由RapidAI研发的高效OCR工具
使用RapidOCR提供的方法对PDF文件进行识别,得到初始数据
import os
from pdf2image import convert_from_path
from rapidocr_onnxruntime import RapidOCR
def pdf_to_images(pdf_path, output_folder='output_images'):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
images = convert_from_path(pdf_path)
image_paths = []
for i, image in enumerate(images):
image_path = os.path.join(output_folder, f'page_{i + 1}.png')
image.save(image_path, 'PNG')
image_paths.append(image_path)
return image_paths
def recognize_text(image_paths):
ocr = RapidOCR()
results = []
for image_path in image_paths:
result = ocr(image_path)
results.append(result)
return results
def main():
pdf_path = 'ComputerNetwork.pdf'
image_paths = pdf_to_images(pdf_path)
ocr_results = recognize_text(image_paths)
for i, result in enumerate(ocr_results):
print(f'Page {i + 1} OCR Results:')
for line in result:
print(line)
print('\n')
if __name__ == "__main__":
main()
获取到的数据需要进行清洗才能正常使用
我们考虑直接使用大参数模型(如Qwen-72B)对文本进行清洗,详见其他成员博客。
获取纯文字信息后, 需要考虑对其进行文本划分和向量化.
在处理PDF文档时,获取纯文字信息只是第一步。为了进一步分析和处理文本数据,需要对其进行文本划分和向量化。
文本划分计划通过Jieba/HanLP等实现.
import jieba
def segment_text(text):
# 使用Jieba进行分词
words = jieba.lcut(text)
return words
# 示例使用
segmented_text = segment_text(extracted_text)
print(segmented_text)
向量化计划通过Faiss向量数据库实现.
具体路线流程如下图:
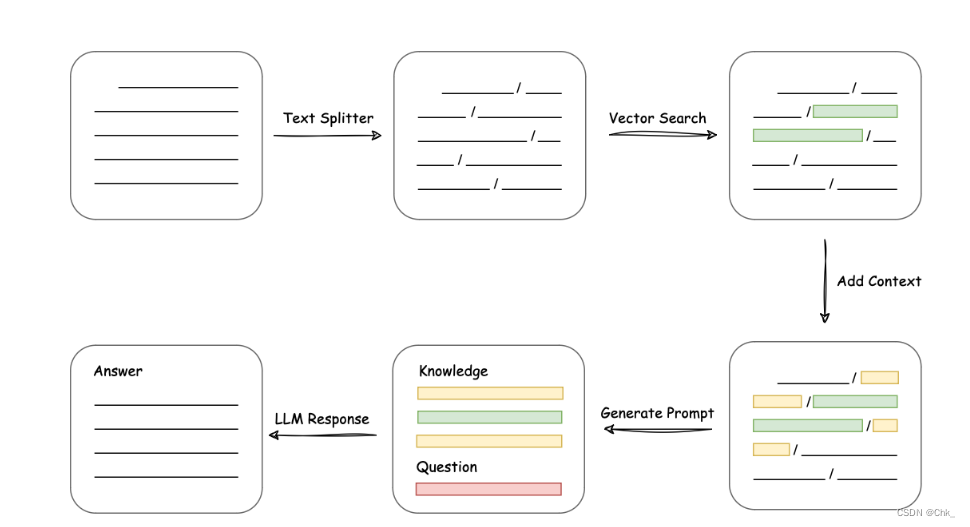
第三周-第四周:文本向量化及向量库搜索研究
Faiss向量数据库搭建初览
参考:向量数据库-Faiss详解 - 知乎 (zhihu.com)
向量数据库Faiss是Facebook AI研究院开发的一种高效的相似性搜索和聚类的库。它能够快速处理大规模数据,并且支持在高维空间中进行相似性搜索。
安装faiss向量数据库:
conda create -n faiss
conda activate faiss
#pip install faiss-cpu
#GPU版本
#pip install faiss-gpu
conda install -c conda-forge faiss-cpu导入faiss向量数据库
import numpy as np
import faiss随机数据作为向量数据库
d = 128 # dimension
nb = 10000 # database size
np.random.seed(1234) # make reproducible
xb = np.random.random((nb, d)).astype('float32')创建索引
-
索引是Faiss进行高效搜索的关键。
- 选用暴力检索的方法FlatL2
- L2代表构建的index采用的相似度度量方法为L2范数,即欧氏距离
index = faiss.IndexFlatL2(d) # build the index
print(index.is_trained)将数据添加到索引中
index.add(xb) # add vectors to the index
print(index.ntotal)检索TopK相似query
- 此时向量数据库已经准备好可以进行搜索了。
- 生成5个查询向量,并且我们希望找到每个查询向量的最近的4个向量
nq = 5 # number of query vectors
k = 4 # we want 4 similar vectors
Xq = np.random.random((nq, d)).astype('float32')
D, I = index.search(Xq, k) # sanity check
print('Xq is:\n',Xq)
print('result is')
print(I)
print(D)Faiss向量数据库搭建进阶
Faiss向量数据库搭建基于一些基本算法:k-means 聚类、PCA、PQ 编码 / 解码
k-means聚类
k-means聚类是一种常用的无监督学习算法,用于将数据分为k个簇。
k-means聚类能够通过迭代优化最小化簇内的总平方误差,从而找到数据的自然分组。
Faiss 提供了一个高效的 k-means 实现。可以对给定的二维张量中的一组向量进行快速聚类。
对于给定的二维张量中的一组向量进行聚类的方法如下:
ncentroids = 1024
niter = 20
verbose = True
d = x.shape [1]
kmeans = faiss.Kmeans (d, ncentroids, niter=niter, verbose=verbose)
kmeans.train (x)将数据分为1024个簇,迭代20次,输出详细的统计信息。
结果中心点存储在.kmeans.centroids 中。
目标函数的值(在 k-means 情况下为总平方误差)随迭代次数的变化存储在变量中,并且更详细的统计信息存储在.kmeans.objkmeans.iteration_stats 中。
要在 GPU 上运行,在 Kmeans 构造函数中添加选项。这将使用机器上所有可用的GPU.gpu=True
PCA主成分分析
PCA主成分分析能够有效地降低数据的维度,同时保留数据中尽可能多的原始信息。
高维数据通常包含大量的冗余和噪声,直接处理可能会导致计算复杂度过高以及过拟合问题。
通过PCA,我们可以将Embedding后得到的高维数据投影到一个较低维度的子空间中,这个子空间由数据方差最大的方向(即主成分)构成,从而简化数据结构并突出主要特征。
以下代码示例使用Faiss库中自带的PCAMatrix方法将 40D 向量降维到 10D。
# random training data
mt = np.random.rand(1000, 40).astype('float32')
mat = faiss.PCAMatrix (40, 10)
mat.train(mt)
assert mat.is_trained
tr = mat.apply(mt)
# print this to show that the magnitude of tr's columns is decreasing
print (tr ** 2).sum(0)量化器
量化器对象继承自,该对象提供三种常用方法(参见 impl/Quantizer.h):Quantizer
- 训练:在向量矩阵上训练量化器
- compute_codes 和:编码器和解码器。编码器通常是有损的,并返回每个输入向量的代码矩阵。decode uint8.
- get_DistanceComputer 是返回对象的方法。DistanceComputer 量化器对象的状态是训练的结果。 字段指示量化器生成的每个代码的字节数。Quantizercode_size .
量化器类型
支持的量化器类型有:
ScalarQuantizer:分别在线性范围内量化每个向量分量。
ProductQuantizer:对子向量执行向量量化
AdditiveQuantizer:将向量编码为码书条目的总和,详细信息请参见 Addtive Quantizers。 可以以多种方式训练加法量化器,因此有子类ResidualQuantizer ,LocalSearchQuantizer, ProductAdditiveQuantizer.
(每个量化器都是前一个量化器的超集。)
第五周-第六周:可视化问答系统的向量数据库搭建
可视化问答系统的向量化是非常重要的一环.
可视化问答系统数据库的向量化主要考虑将数据预处理部分得到的纯txt文件通过faiss向量库标准化为向量以便后续进行RAG增强检索.
Faiss向量化的基本步骤:
- 文本向量化:将查询文本转换为向量形式,以便与存储在Faiss数据库中的向量进行比较。
- 相似度搜索:在Faiss数据库中搜索与查询向量最相似的向量。
- 返回结果:根据搜索结果返回对应的文档或信息。
文本嵌入
首先需要使用Embedding模型将文本转化为嵌入向量, 才能在后续将这些向量存储到向量库中.
为什么使用Embedding模型对文本数据进行处理?
- Embedding将高维度、非结构化的文本转换为固定维度的向量表示,从而便于计算和分析。
- Embedding模型通过在大规模语料库上进行训练,能够捕捉词汇和句子之间的语义关系,使得相似含义的文本在向量空间中距离更近。这种向量化表示不仅简化了文本处理的复杂性,还能显著提高后续任务(如文本分类、聚类和搜索)的效率和准确性。
代码示例 (使用sentence-transformer库)
使用Embedding模型:all-MiniLM-L6-v2
该模型基于微软的 MiniLM 架构, 是一种轻量级、低延迟的语言模型,专门设计用于高效的文本嵌入生成。
all-MiniLM-L6-v2 是一个双塔模型,包含 6 层 Transformer 网络,能够将句子或文本片段编码为固定大小的高维向量(嵌入向量)。
这些向量保留了文本的语义信息,使得相似含义的句子在向量空间中距离更近。该模型在大规模多语料库上进行了预训练,具备较强的跨领域和跨语言的适应能力。
all-MiniLM-L6-v2 的参数量较少,因此在计算资源有限的环境中也能高效运行。它在嵌入质量和计算速度之间提供了良好的权衡,非常适合需要快速生成高质量文本嵌入的应用场景,如语义搜索、文本聚类和文本分类等。通过使用 all-MiniLM-L6-v2,开发者可以在保持高精度的同时,实现高效的文本处理和相似性计算。
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
def read_text_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
return [line.strip() for line in lines if line.strip()]
def text_to_vectors(texts, model_name='all-MiniLM-L6-v2'):
model = SentenceTransformer(model_name)
vectors = model.encode(texts, show_progress_bar=True)
return vectors
def build_faiss_index(vectors, index_path='faiss_index'):
d = vectors.shape[1]
index = faiss.IndexFlatL2(d)
index.add(vectors)
faiss.write_index(index, index_path)
def search_faiss_index(query_vector, index_path='faiss_index', top_k=5):
index = faiss.read_index(index_path)
distances, indices = index.search(query_vector, top_k)
return distances, indices
def main():
txt_file_path = 'ComputerNetwork.txt'
texts = read_text_file(txt_file_path)
vectors = text_to_vectors(texts)
build_faiss_index(vectors)
query_text = "查询文本"
query_vector = text_to_vectors([query_text])
distances, indices = search_faiss_index(query_vector)
print("查询结果:")
for i, index in enumerate(indices[0]):
print(f"文本: {texts[index]}, 距离: {distances[0][i]}")
if __name__ == "__main__":
main()
文本嵌入后,考虑对嵌入的向量归入Faiss库
归入Faiss向量库
创建L2距离的Faiss索引
dimension = embedding_out_dim # 经过Embedding后的向量维度
index = faiss.IndexFlatL2(dimension) # 使用L2距离的平面索引
使用Faiss索引查找5个最近邻向量
query_vector = vector
k = 5 # 查找前5个最近邻
distances, indices = index.search(query_vector, k)
print("最近邻索引:", indices)
print("最近邻距离:", distances)
第七周-第八周:可视化问答系统搭载RAG增强检索
想要实现完整的RAG系统,基座技术是前几周实现的Faiss向量库和文本向量嵌入。
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 加载预训练的GPT模型和tokenizer
gpt_tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
gpt_model = GPT2LMHeadModel.from_pretrained('gpt2')
def generate_answer(retrieved_docs, query):
context = " ".join(retrieved_docs) + " " + query
inputs = gpt_tokenizer.encode(context, return_tensors='pt', truncation=True, padding=True)
outputs = gpt_model.generate(inputs, max_length=200, num_return_sequences=1)
answer = gpt_tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer
# 生成回答
answer = generate_answer(retrieved_docs, query)
print("Generated Answer:", answer)
根据查询从Faiss数据库中索引相关知识
def retrieve(query, k=5):
query_embedding = embed_text(query)
distances, indices = index.search(query_embedding, k)
retrieved_documents = [documents[idx] for idx in indices[0]]
return retrieved_documents
# 示例查询
query = "Example query text..."
retrieved_docs = retrieve(query)
print("Retrieved Documents:", retrieved_docs)
制作Prompt模板
def create_prompt_template(retrieved_docs, query):
context = "\n".join([f"Document {i+1}:\n{doc}" for i, doc in enumerate(retrieved_docs)])
prompt = f"Context:\n{context}\n\nQuery: {query}\n\nAnswer:"
return prompt
# 创建Prompt Template
prompt_template = create_prompt_template(retrieved_docs, query)
print("Prompt Template:\n", prompt_template)
将知识嵌入模型Prompt中
检索到的文档内容:
- Document 1: "Paris is the capital and most populous city of France."
- Document 2: "France, officially the French Republic, is a country primarily located in Western Europe."
- Document 3: "The capital city of France is Paris, which is known for its art, fashion, and culture."
模型Prompt模板:
You should answer the Query by these contexts
Context:通过用户输入在向量库中检索到的相关文档
Query:用户输入
Answer:模型回复
最终提交给模型的回复:
You should answer the Query by these contexts
Context:
Document 1:
Paris is the capital and most populous city of France.
Document 2:
France, officially the French Republic, is a country primarily located in Western Europe.
Document 3:
The capital city of France is Paris, which is known for its art, fashion, and culture.Query: What is the capital of France?
Answer:
模型回答


















 7076
7076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









