






什么是大模型
随着chatGPT爆火到现在的deepseek,大家都在是AI时代要来了,AI相关的内容里面最核心的就是大模型了,那么我们肯定需要先来了解一下什么是大模型(LLM)?
有的人觉得大模型就是谷歌啊百度啊什么的升级版搜索引擎!
有的人觉得大模型是一个无所不知的小老师!
有的人觉得大模型回答的很空泛生成的东西还不如自己写的一点用都没有!
微软对应LLM的定义是以下这样的
大语言模型 (英文:Large Language Model,缩写LLM) 是高级的 AI 系统,它们利用通过机器学习技术对其进行训练的数据来理解并生成自然语言或类似于人类的文本。LLM 可以自动生成基于文本的内容,这些内容可以应用于各行各业的大量用例,从而改进全球组织的效率和成本节省。
其实有点拗口对吧,我来用大白话来解说一下,LLM就相当于“小孩”,用各种的资料去培养他,然后他从不会说话到你问他内容他能根据你教他的东西去猜测你想要的内容,然后输出一个答案给你(这个答案不一定靠谱,因为他自己的猜测嘛,也就是俗称的大预言幻觉)
那为什么又有什么8b,14b,32b,70b等等等的模型呢,又怎么区别呢?
其实就是你开始的时候教他的语料数据的大小决定的(就是你最开始教他的材料的多少),这样就可以理解了,你教的越多,他猜的越准,你教的少他就容易乱回答。
AI的本质
所以其实很多人对于什么ai要毁灭世界啊,什么会把90%的人的工作取代掉啊什么的无端猜忌其实就不攻自破了(ai或者LLM本质上是基于概率的输出,根据用户输入,连续预测输出,连智能都不一定算的上)反正博主是持乐观态度,真要毁灭人类还要很久,现在的数据量和计算能力是不足以支撑ai去达到那种程度的
什么是提示词
相信关注ai的人都知道提示词
那么什么是提示词?提示词(Prompt)是用户输入给AI系统的指令或信息,用于引导AI生成特定的输出或执行特定的任务
比如一个简单的问题 ,一段详细的指令 ,一个复杂的任务描述,这些都可以称为提示词
通过提示词可以让ai输出的结果更符合我们的要求
提示词的基本结构
上下文(背景设定):为AI提供背景信息,帮助它更准确地理解和执行任务
明确任务:为AI明确表达所需要完成的任务,比如“你的任务是从论文中提取出关键的信息”
执行步骤(可选):为AI提供明确的执行步骤或思维链 输出格式
注意事项: 通过调试执行发现AI可能出现的问题,动态添加在提示词的最后
大模型的幻觉
有很多人的截图发出来说什么ai具有自我思考能力了,有很多骇人听闻的传闻传出来,博主的猜测其实就是大模型幻觉导致的
那么什么是大模型幻觉呢?
什么是AI幻觉?AI模型生成的内容看似合理,但实际上是错误或虚假的现象(为了回答你问题而回答,根本不管对错,或者把别的信息套用到你问的东西上,比如你给的内容是西红柿10块,你问他玉米几块?但是你的数据里没有玉米多少钱,他就会回答你说玉米10块,把西红柿的价格套到了玉米上)
简单来说,就是AI“编造”了一些看似可信但实际上不存在或不准确的信息,这通常发生在AI试图回答超出其训练数据范围的问题时, 它会根据已有的模式和知识生成一个看似合理的答案,但 实际上这个答案并没有真实的依据
如何尽量避免ai幻觉
1.用模型微调,用于垂直领域的应用(比如专用于数据变动不大,但是对精细化要求较高的场景,专门微调一个对这个行业/领域有极高准确率的模型)
2.使用了RAG策略的AI知识库
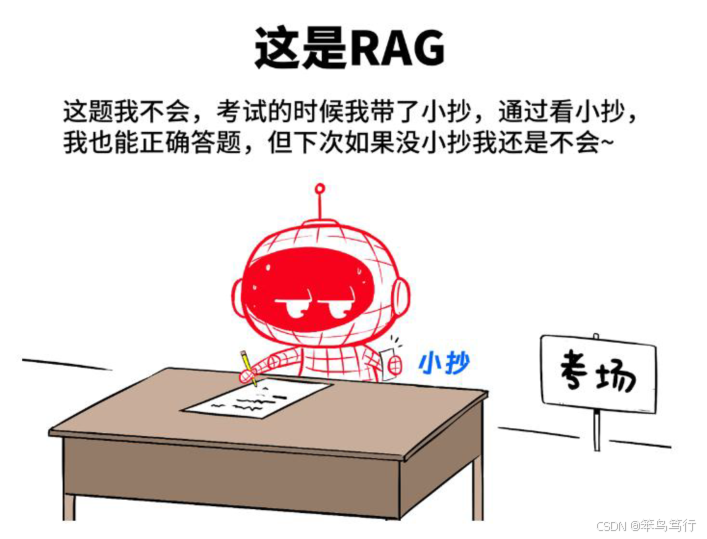
什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索技术和生成模型的自然语言处理框架。它通过从外部知识库中检索相关信息,并将这些信息输入到生成模型中,从而生成更准确、更符合语境的文本。
使用了RAG策略的向量知识库,相当于一个在考试的孩子,手上拿着对应知识的小抄,时刻会通过小炒去修改他的输出结果,通过这种方式去减少幻觉
3.使用提示词
其实下面的方法配置智能体的时候也会使用提示词,使用提示词工程,去约束ai,分配给他人设和任务要求,让他以更符合我们要求的方式去输出内容
4.使用智能体(AI agent)
使用 AI 实现业务流程的自动化和执行,智能体可以独立规划、适应新信息和执行任务,使其能够处理复杂的动态环境、决策和自主行动。他们可以从反馈中学习,调整策略,并在最少的人工监督下运营。
相当于你预先告诉了他这个流程是怎么操作的,也给他配置了对应的知识库,然后让他就按照你配置的流程和使用你给他的内容去自主回答,你还会告诉他对应步骤应该注意什么,这种做法就极大的提高了他的可信度,将不可控的随意回答控制在了你给的流程里,后面发现什么步骤应该添加什么对应的要求就可以直接给他加上,将流程可控!(我这里还是推荐之前我讲过的煎蛋智能体平台,这个简单易上手,不像dify需要对于代码知识要求那么高,但是能力差不多,确实是好用)
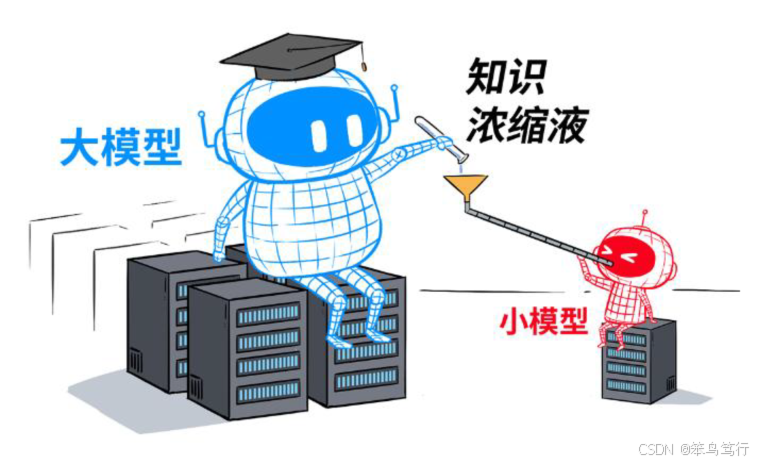
5.模型蒸馏
什么是模型蒸馏?
“模型蒸馏”就是把大模型学到的本领,用“浓缩”的方式教给小模型的过程,在保证一定精度的同时,大幅降低运算成本和硬件要求。
我暂时了解到减少幻觉的大体分为这5种,如果有补充的可以在评论区告诉我,我会去修订,因为我也还在努力学习中
在可见的未来里AI肯定会占据一席之地,让我们一起学习,共勉
祝愿大家万事皆成



















 4566
4566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











