



我的配置步骤
SAM模型分割效果成效没有我想要的预期那么好,后期待完善,记录一下我的学习笔记
首先配置labelme+sam
目录
我的方法比较简单粗暴
操作来源这篇博客 labelme+sam在windows上使用指南-优快云博客
下列操作 均在已经存在虚拟环境的条件下操作 ,没有虚拟环境的先创建虚拟环境!我的虚拟环境是Anaconda
注意在创建虚拟环境的时候,建议python==3.8比较好,我最开始使用python==3.6,后续使用create AI-ploygon 就一直报错,重新搭建的虚拟环境
conda create labelme python=3.81.下载labelme环境配置
加载进入Releases · wkentaro/labelme · GitHub 科学上网快!
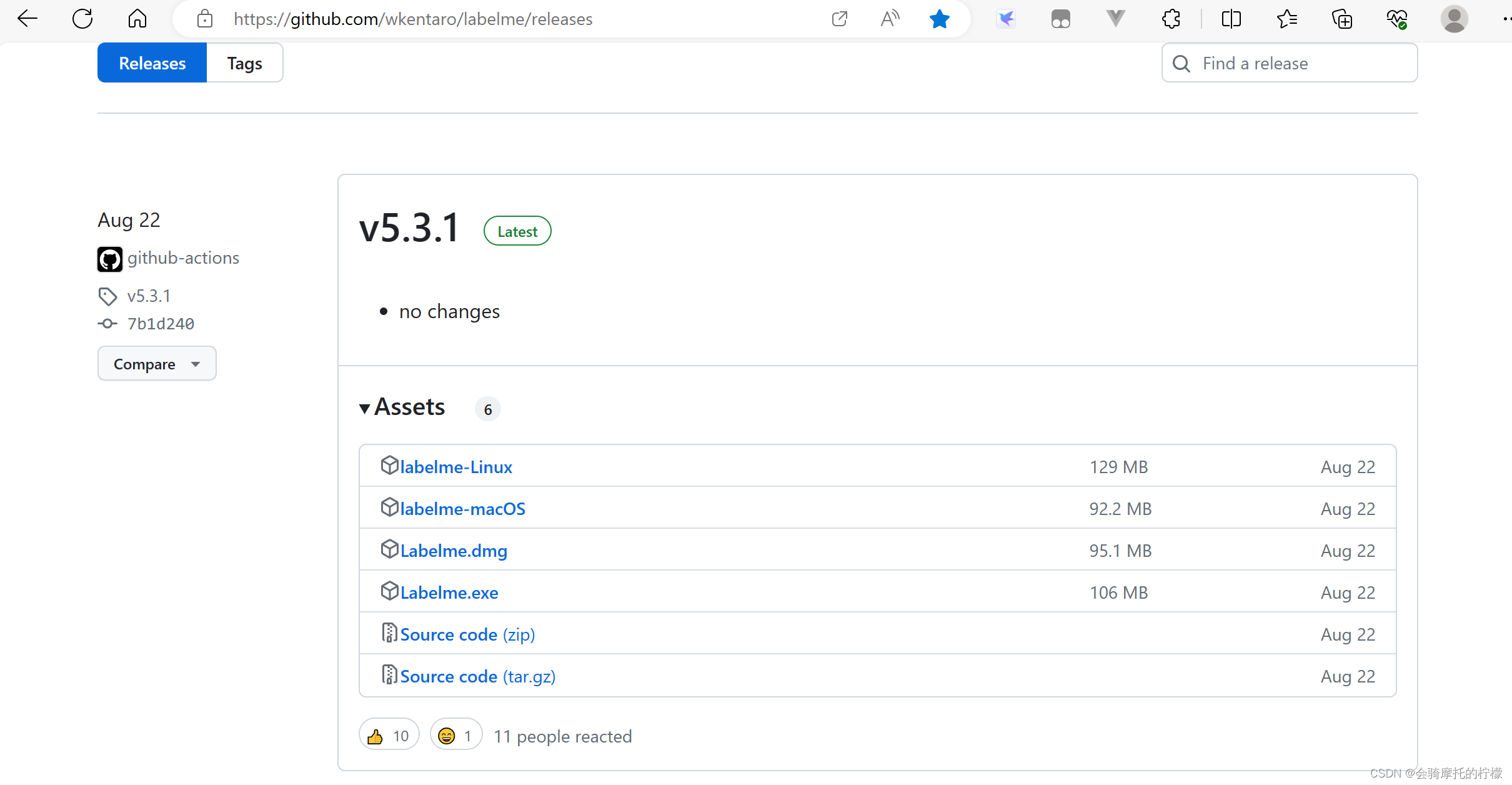
手动下载Source code.zip
然后手动解压安装包(因为我的虚拟环境 好像没有unzip使用unzip会报错)
激活虚拟环境进入安装包:我的虚拟环境设置在了 D:\AncondaEnv
conda activate D:\AncondaEnv
(D:\AncondaEnv) PS C:\Users\admin>cd labelme-5.3.1下载
pip install -e .下载完毕后,直接进入labelme
labelme下载无报错,就可以打开labelme开炫啦!
2.我走的弯路 -- 我遇到的问题
我在进行这一步之前,自己从清华镜像下 下载了 onnxruntime这个包,但是好像镜像里面只有1.10.1最新版本,但是labelme里的setup文件要求onnxruntime 1.14.1
所以我必须卸载这个版本,而且pip install onnxruntime对我没用,它会自动从清华镜像里下载,我尝试过删除镜像来源,还是不行!
pip install onnxruntime //无用所以我采用了简单粗暴的方式!!直接去onnxruntime · PyPI 下载.whl文件 然后安装
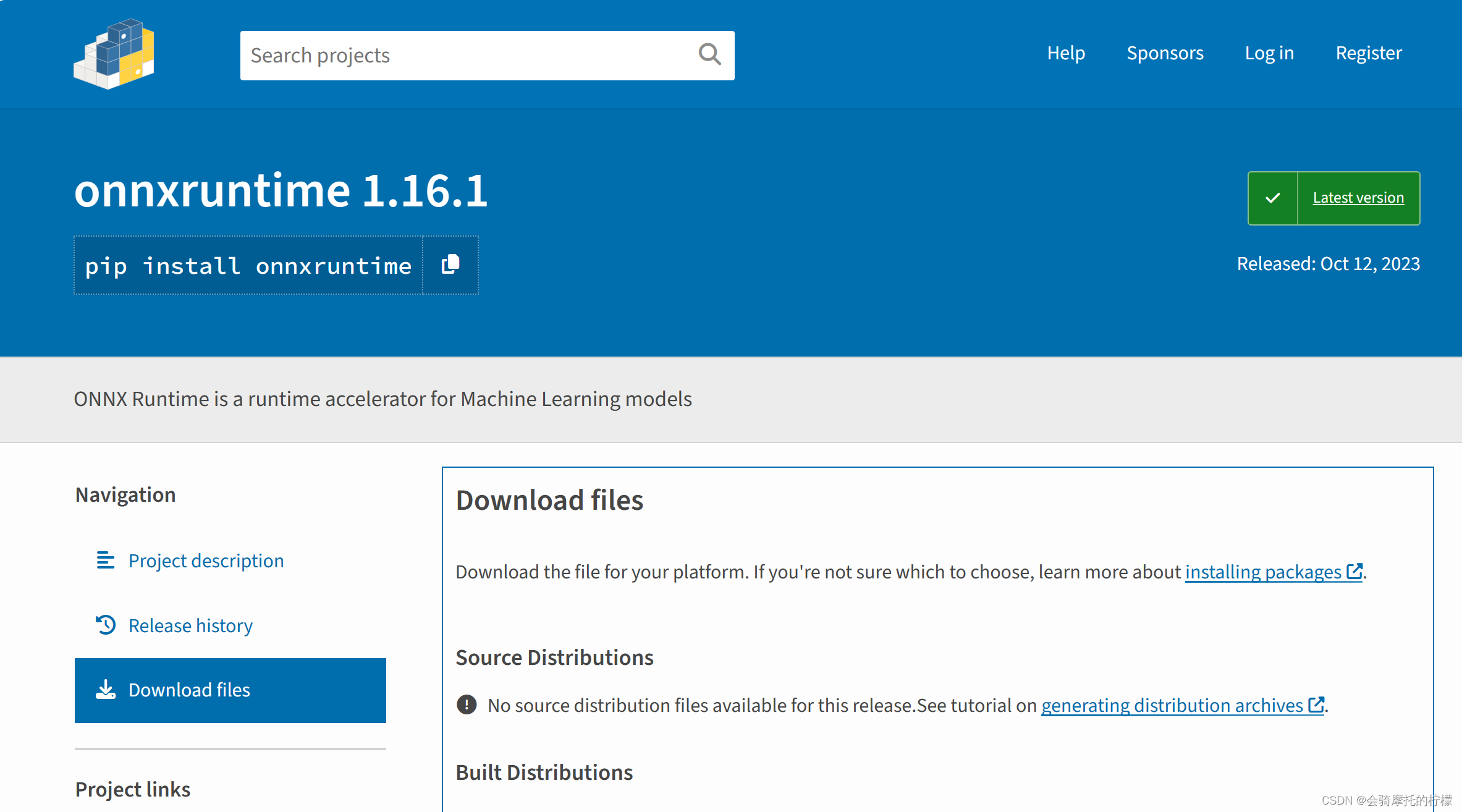
里面版本很多,下载前 先在自己的虚拟环境安装wheel
pip install wheel
然后查看自己的python版本支持的whl适配文件,输入:
pip debug --verbose得到自己的适配型号 ,下面是python3.8的适配型号
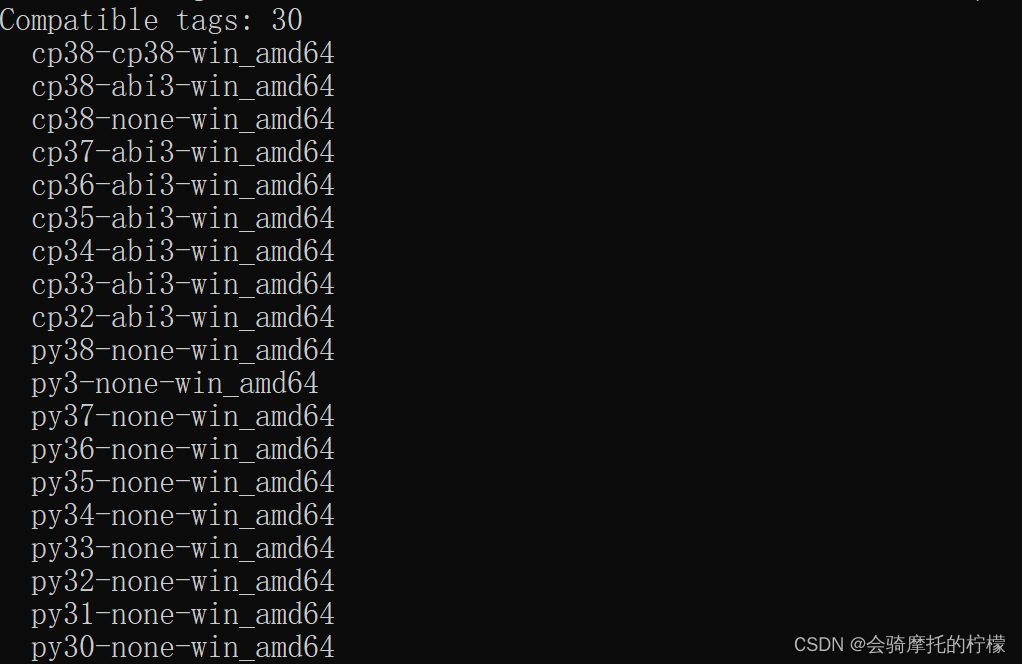
我安装3.6的还有一个原因是,3.6不支持cp38-cp38-win_amd64,它只有 cp36-cp36-win_amd64,而onnxruntime · PyPI 中onnxruntime1.16.1-cp38-cp38-win_amd64.whl

点击对应的.whl文件后下载即可,然后我将这个文件移动到 C:\Users\admin
然后直接进行下载,也可以进进入你.whl文件所在的位置然后再下载即可
pip install onnxruntime-1.16.1-cp38-cp38-win_amd64.whl下载后再去labelme-5.3.1 进行pip install -e .
以上就可以成功配置labelme,并使用AI 模型,但是我看配置SAM还有权重文件,以及这里面的AI标记我暂时还不会使用
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —
二编一下 —— 配置完上述的步骤后,就可以直接开炫了,不用再搞SAM的权重文件
想使用AI 分割的话,就直接选择 Create AI-Polygon 就可,控制面板的界面就如下
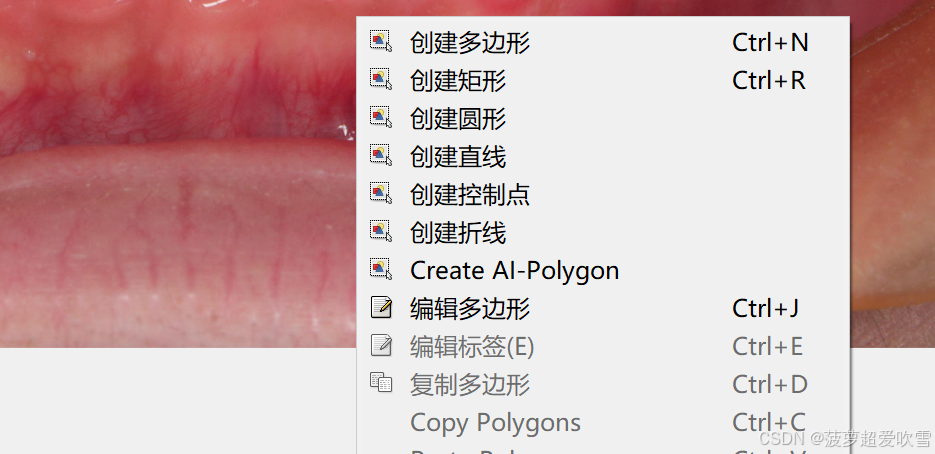
使用AI 分割的时候只需要点击你想单独分割出来的物体就可,如果效果不太好,可多点几下
谈谈使用感受:
就是在分割单个物体的时候效果还是不错的,但是如果是分割多个物体,我建议是直接一个一个的分,也可以实现,比如我现在是要分割连在一起的物体,AI识别阔能就没那么准确,就可以按个分割。

















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









