




 本文深入探讨Java并发编程,介绍JUC包中的ReentrantLock、原子类、线程池、Semaphore和CountDownLatch,并讨论它们的应用场景。此外,还讲解了线程安全的ArrayList、队列和哈希表,如CopyOnWriteArrayList、ArrayBlockingQueue和ConcurrentHashMap的使用。
本文深入探讨Java并发编程,介绍JUC包中的ReentrantLock、原子类、线程池、Semaphore和CountDownLatch,并讨论它们的应用场景。此外,还讲解了线程安全的ArrayList、队列和哈希表,如CopyOnWriteArrayList、ArrayBlockingQueue和ConcurrentHashMap的使用。
【大家好,我是爱干饭的猿,本文是多线程初级入门,主要介绍了JUC(java.util.concurrent) 的常见类、Callable 接口、线程安全的集合类。
后续会继续分享网络原理及其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【web】java多线程(常见锁策略+synchronized原理)》
🤞目录🤞
💖1. JUC(java.util.concurrent) 的常见类
1. 自己使用同步机制 (synchronized 或者 ReentrantLock)
2. Collections.synchronizedList(new ArrayList)
3. 如何把HashMap 变安全(Hashtable | ConcurrentHashMap )
🪐1. JUC(java.util.concurrent) 的常见类
1.1 ReentrantLock
上篇文章详细讲过,不过多赘述
可重入互斥锁. 和 synchronized 定位类似, 都是用来实现互斥效果, 保证线程安全
ReentrantLock 和 synchronized 的区别:
- synchronized 是一个关键字, 是 JVM 内部实现的(大概率是基于 C++ 实现). ReentrantLock 是标准
- 库的一个类, 在 JVM 外实现的(基于 Java 实现).
- synchronized 使用时不需要手动释放锁. ReentrantLock 使用时需要手动释放. 使用起来更灵活, 但是也容易遗漏 unlock.
- synchronized 在申请锁失败时, 会死等. ReentrantLock 可以通过 trylock 的方式等待一段时间就放弃.
- synchronized 是非公平锁, ReentrantLock 默认是非公平锁. 可以通过构造方法传入一个 true 开启公平锁模式
如何选择使用哪个锁?
- 锁竞争不激烈的时候, 使用 synchronized, 效率更高, 自动释放更方便.
- 锁竞争激烈的时候, 使用 ReentrantLock, 搭配 trylock 更灵活控制加锁的行为, 而不是死等.
- 如果需要使用公平锁, 使用 ReentrantLock
1.2 原子类
原子类内部用的是 CAS 实现,所以性能要比加锁实现 i++ 高很多。原子类有以下几个
- AtomicBoolean
- AtomicInteger
- AtomicIntegerArray
- AtomicLong
- AtomicReference
- AtomicStampedReference
import java.util.concurrent.atomic.AtomicInteger;
public class Main {
static int i = 0;
static AtomicInteger j = new AtomicInteger(0); // 原子类
public static void main(String[] args) {
// 不是原子的,想做到原子,就需要进行加锁操作
// 但加锁这个动作,其实成本是挺高的
i++;
i--;
// JVM 保证了这些操作是原子的,并且实现原子时,没有用到锁
// 整体来讲,性能能好些
// 内存其实通过 CAS + 多次尝试实现
// j = 0 CAS(j, 0, 1),成功了,原子操作成功;失败了,再次尝试 CAS(j, 1, 2)
j.getAndIncrement(); // 先取值,后加 1,视为是 j++
j.getAndDecrement(); // 先取值,后减 1,视为是 j--
j.incrementAndGet(); // ++j
j.getAndAdd(5); // d = j; j = j + 5
}
}1.3 线程池
上上篇文章详细讲过《线程池》
1.4 信号量Semaphore
信号量,用来表示 "可用资源的个数",本质上就是一个计数器
可以理解成可以被多个线程持有的锁
Semaphore 的 PV 操作中的加减计数器操作都是原子的, 可以在多线程环境下直接使用.
代码示例:
- 创建 Semaphore 示例, 初始化为 5, 表示有 5 个可用资源.
- acquire 方法表示申请资源(P操作), release 方法表示释放资源(V操作)
import java.util.Scanner;
import java.util.concurrent.Semaphore;
public class Main {
// permits: 许可
// 信号量:十字路口的红绿灯
// permits = 5 : 允许最多 5 个拿到许可证
// 一个线程取一个,可以有 5 个线程
// 一个线程就取 5 个,只有一个线程
// 许可只有数量的关系,并不要求,一定是 取的线程才能放回
static Semaphore semaphore = new Semaphore(5);
static class MyThread extends Thread {
@Override
public void run() {
Scanner scanner = new Scanner(System.in);
scanner.nextLine();
semaphore.release(); // 放回一个许可
}
}
public static void main(String[] args) throws InterruptedException {
MyThread t = new MyThread();
t.start();
semaphore.acquire();
semaphore.acquire();
semaphore.acquire();
semaphore.acquire();
semaphore.acquire();
semaphore.acquire(); // 阻塞
System.out.println("成功");
}
}1.5 CountDownLatch
同时等待 N 个任务执行结束
(类似于游戏技能CD,当CD走完时,才能使用或操作)
代码示例:
- 构造 CountDownLatch 实例, 初始化 3 表示有 3 个任务需要完成
- 每个任务执行完毕, 都调用 latch.countDown()
- 在 CountDownLatch 内部的计数器同时自减
- 主线程中使用 latch.await(); 阻塞等待所有任务执行完毕. 相当于计数器为 0 了
import java.util.concurrent.CountDownLatch;
public class Main {
// count: 计数器为 3 个,只有 3 个全部报到了,门闩才会打开
static CountDownLatch countDownLatch = new CountDownLatch(3);
static class MyThread extends Thread {
@Override
public void run() {
countDownLatch.countDown();
countDownLatch.countDown();
countDownLatch.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
MyThread t = new MyThread();
t.start();
countDownLatch.await();
System.out.println("门闩被打开了");
}
}应用场景:
多线程下载器:
线程1:下载0-100 countDownLatch.countDown();
线程2:下载101-200 countDownLatch.countDown);
线程n:下载.. countDownLatch.countDown();
主线程,等所有线程全部下载完成,代表整个文件下载完成了等在countDownLatch.await()一共n个
🪐2. Callable 接口
什么是 Callable 接口
- Callable 是一个 interface . 相当于把线程封装了一个 "返回值". 方便程序猿借助多线程的方式计算结果
- Callable 和 Runnable 相对, 都是描述一个 "任务"
- Callable 描述的是带有返回值的任务, Runnable 描述的是不带返回值的任务
- Callable 通常需要搭配 FutureTask 来使用. FutureTask 用来保存 Callable 的返回结果. 因为 Callable 往往是在另一个线程中执行的, 啥时候执行完并不确定
- FutureTask 就可以负责这个等待结果出来的工作
public class Main {
// 计算fib数的Callable的子类(封装了"返回值"的线程)
static class FibCalc implements Callable<Long>{
private final int n;
FibCalc(int n){
this.n = n;
}
private long fib (int n){
if(n == 0 || n == 1) return 1;
return fib(n-1) + fib(n-2);
}
@Override
public Long call() throws Exception {
return fib(n);
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService service = Executors.newSingleThreadExecutor();
FibCalc task = new FibCalc(40);
Future<Long> future = service.submit(task);
// 这一步实际上是在等任务计算完成,所以,时间可能需要很久
Long r = future.get();
System.out.println(r);
}
}🪐3. 线程安全的集合类
线程不安全: ArrayList、LinkedList、PriorityQueue、TreeMap、TreeSet、HashMap、HashSet、StrinaBuilder
线程安全: Vector、Stack、 HashTable、Dictionary、StringBuffer这几个类都是Java 设计失败的产品。 以后大家代码中不要出现这些类。
3.1 多线程环境使用 ArrayList
1. 自己使用同步机制 (synchronized 或者 ReentrantLock)
上一篇文章讲过,不在赘述
2. Collections.synchronizedList(new ArrayList)
synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List. synchronizedList 的关键操作上都带有 synchronized
3. 使用 CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器
优点: 在读多写少的场景下, 性能很高, 不需要加锁竞争
缺点: 1. 占用内存较多. 2. 新写的数据不能被第一时间读取到
- 拷贝当写的时候的一种顺序表(共享的数据,只要没有写操作,就是线程安全)
- cow t1、t2只是读数据,什么都不会发生,读的是同一份数据(共享)
- 当有一个线程要有写操作,比如t1,就会针对t1复制一份顺序表导致,t1和t2看到的不再是同一份数据
public class Main {
static CopyOnWriteArrayList<String> cow = new CopyOnWriteArrayList<>();
static class MyThread extends Thread{
@Override
public void run() {
System.out.println(cow.size()); // 只读操作
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(cow.size()); // 只读操作
}
}
public static void main(String[] args) throws InterruptedException {
cow.add("1");
cow.add("2");
cow.add("3");
MyThread t = new MyThread();
t.start();// 子线程休眠一秒
// 主线程
System.out.println(cow.size()); // 只读操作
TimeUnit.SECONDS.sleep(1);
cow.add("4"); // 由于进行了写的操作,所以,会为主线程复制一份元素
// 导致不是同一份数据了
System.out.println(cow.size()); // 只读操作
}
}3.2 多线程环境使用队列
1. ArrayBlockingQueue
基于数组实现的阻塞队列
2. LinkedBlockingQueue
基于链表实现的阻塞队列
3. PriorityBlockingQueue
基于堆实现的带优先级的阻塞队列
4. TransferQueue
最多只包含一个元素的阻塞队列
3.3 多线程环境使用哈希表
HashMap 本身不是线程安全的
1. HashMap原理

2. HashMap线程安全吗
3. 如何把HashMap 变安全(Hashtable | ConcurrentHashMap )
在多线程环境下使用哈希表可以使用:
- Hashtable
- ConcurrentHashMap
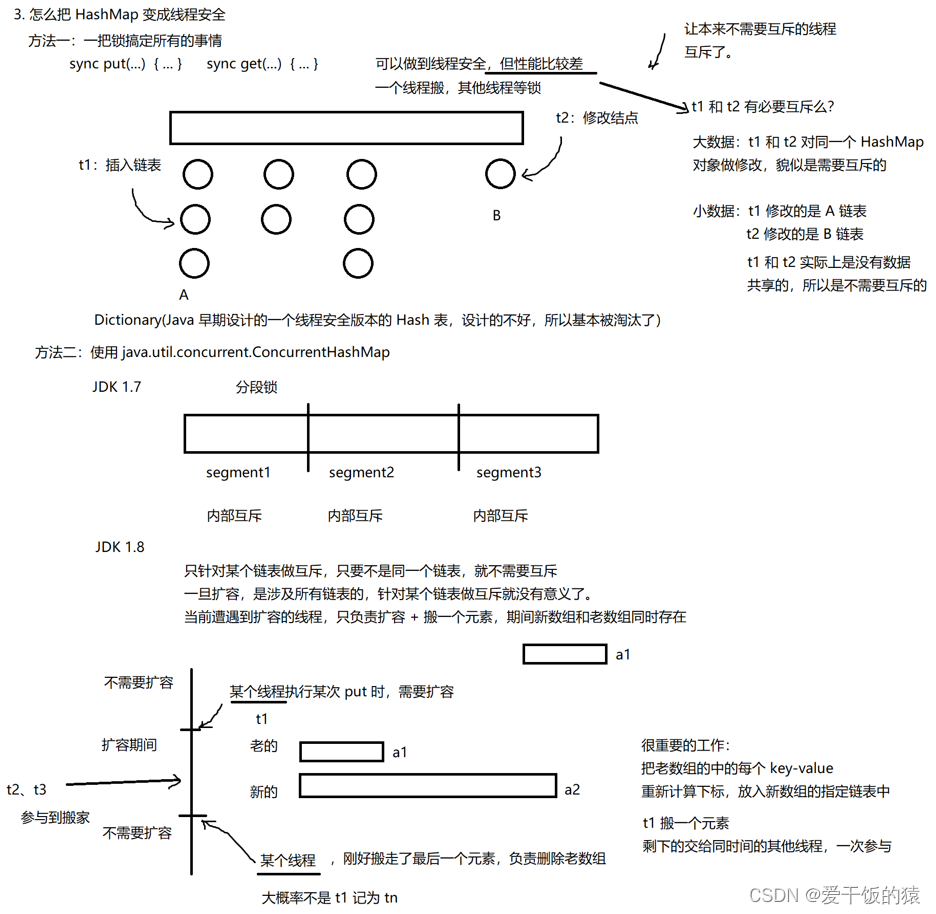
方法二:ConcurrentHashMap
- 读操作没有加锁(但是使用了 volatile 保证从内存读取结果), 只对写操作进行加锁. 加锁的方式仍然 是是用 synchronized, 但是不是锁整个对象, 而是 "锁桶" (用每个链表的头结点作为锁对象), 大大降 低了锁冲突的概率.
- 充分利用 CAS 特性. 比如 size 属性通过 CAS 来更新. 避免出现重量级锁的情况.
- 优化了扩容方式: 化整为零
- concurrent发现需要扩容的线程, 只需要创建一个新的数组, 同时只搬几个元素过去.
- 扩容期间, 新老数组同时存在.
- 后续每个来操作 ConcurrentHashMap 的线程, 都会参与搬家的过程. 每个操作负责搬运一小部分元素.
- 搬完最后一个元素再把老数组删掉.
- 这个期间, 插入只往新数组加.
- 这个期间, 查找需要同时查新数组和老数组
分享到此,感谢大家观看!!!
如果你喜欢这篇文章,请点赞加关注吧,或者如果你对文章有什么困惑,可以私信我。
🏓🏓🏓


















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











