






M——variate numer
L——seq_len(序列长度)
T——seq_pred(预测长度)
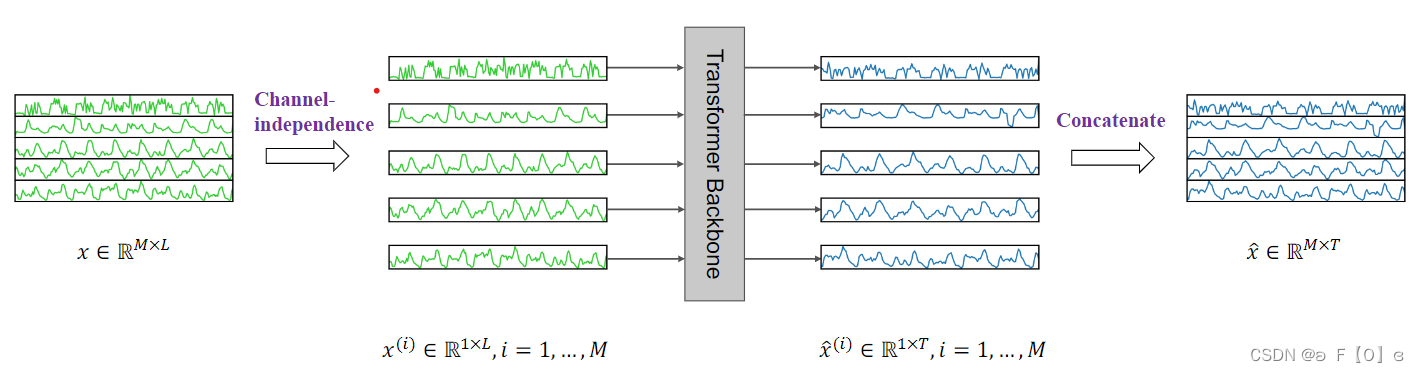
Channel Independence
- 不同Channel的数据有不同的规律,如果直接mix后投射到一个空间上会不太好学。会需要更多的数据来学习组合关系。
- 如果一个channel的数据有噪声,也容易影响所有channel,分开则没有这样的影响。
- Channel Independence的模型没有那么容易过拟合。因为每个维度的信息是有限的,所以没有那么容易拟合。
Patching
对于每一个单变量序列(已经通过转换从[L,M]->[M,L]),将长为L序列切成N块,每块长度P(图1)。每一个时间段视为一个 token(这不同于很多 Transformer-based 模型将每一个时间点视为一个token)。过程有点类似一维的cnn,也可以设置stride长度来决定patch块与patch块之间是否重合。每个Patch块,就相当于transformer的一个输入。
通过这种方式,序列长度从L变成了N,可以大大缩减计算量和显存占用。另外一个要提到的点是Position Embedding,论文用的是learnable的PE,用nn.init.uniform_(W_pos, -0.02, 0.02)来初始化。
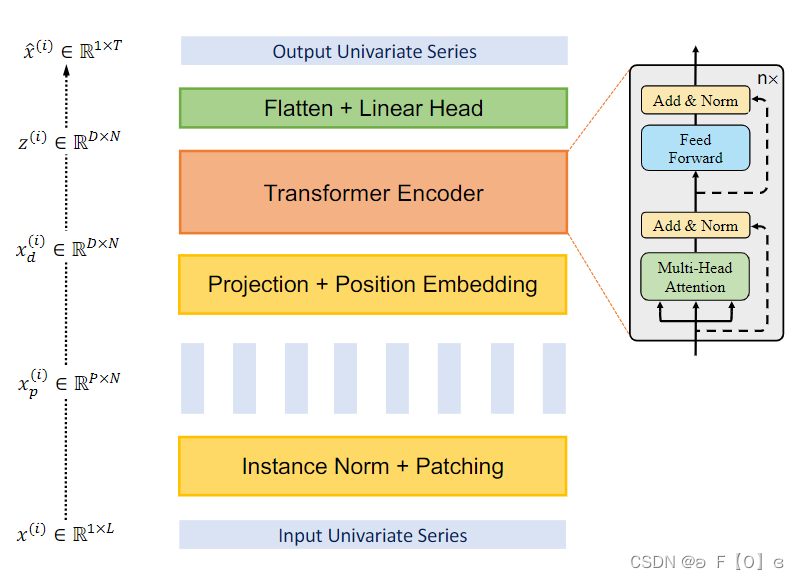
图1 Patching 过程, 将长为L序列切成N块,每块长度P

















 1785
1785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









