




利用本地大模型开发个人知识库是一个结合自然语言处理(NLP)、数据存储和检索的系统工程。以下是分步骤的实现思路和关键技术点,适用于隐私敏感或需要离线运行的场景:
1. 技术选型
1.1 本地大模型选择
轻量化模型:优先选择参数量适中、支持本地部署的模型:
- Llama 2(7B/13B参数,支持量化部署)
- Alpaca/Vicuna(基于LLaMA的微调版本)
- ChatGLM3-6B(中英双语,支持消费级GPU)
- Mistral-7B(高性能7B模型)
- Deepssek (华流最YYDS)
量化技术:使用GGUF/GPTQ量化降低显存占用(如llama.cpp或AutoGPTQ工具)
推理框架:
- Ollama(本地模型一键部署)
- llama.cpp(CPU/GPU混合推理)
- Text Generation WebUI(本地Web界面)
1.2 知识库架构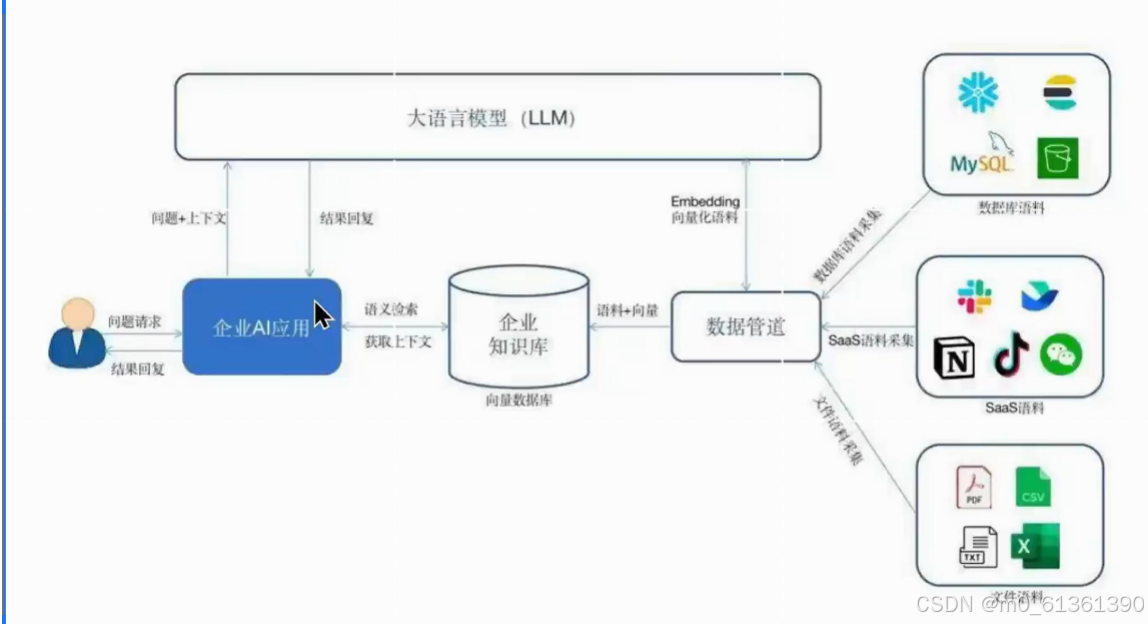
2. 知识库构建流程
2.1 数据采集与预处理
数据源:
- 本地文档(PDF/Word/Markdown/Text)
- 网页存档(单页/批量爬取)
- 笔记软件导出(Notion/Obsidian等)
- 结构化数据(CSV/Excel)
预处理工具链:
# 示例:使用Unstructured库处理多格式文档
from unstructured.partition.pdf import partition_pdf
elements = partition_pdf("doc.pdf", strategy="auto")
chunks = [elem.text for elem in elements if hasattr(elem, 'text')]
2.2 文本向量化
本地嵌入模型:
- BAAI/bge-small-zh-v1.5(中文小模型)
- sentence-transformers/all-MiniLM-L6-v2(英文轻量模型)
批量处理脚本:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
embeddings = model.encode(chunks, batch_size=32)
2.3 向量数据库选型
向量数据库(Vector Database),也叫矢量数据库,主要用来存储和处理向量数据。
图像、文本和音视频这种非结构化数据都可以通过某种变换或者嵌入学习转化为向量数据存储到向量数据库中,从而实现对图像、文本和音视频的相似性搜索和检索。传统数据库是基于精准匹配或者预定义标准的数据库是没法做AI这种海量还非结构化的数据查询搜索分析哦;
轻量级方案:
- FAISS(Facebook开源的CPU高效检索)
- Chroma(支持持久化存储的嵌入式数据库)
- Qdrant(支持本地部署的Rust高性能引擎)
持久化存储示例(Chroma):
import chromadb
client = chromadb.PersistentClient(path="/knowledge_db")
collection = client.create_collection("my_docs")
collection.add(
documents=chunks,
embeddings=embeddings.tolist(),
ids=[f"doc_{i}" for i in range(len(chunks))]
)
3. 检索增强生成(RAG)实现
3.1 混合检索策略
- 语义检索:基于向量相似度(余弦相似度)
- 关键词检索:BM25算法作为补充
- 混合评分:加权融合两种得分
3.2 本地RAG Pipeline
from langchain_community.vectorstores import Chroma
from langchain_community.llms import LlamaCpp
# 初始化本地大模型
llm = LlamaCpp(
model_path="mistral-7b-v0.1.Q4_K_M.gguf",
temperature=0.3,
n_gpu_layers=20
)
# 构建检索链
retriever = Chroma(persist_directory="/knowledge_db").as_retriever()
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# 执行查询
response = qa_chain.run("如何配置Llama2的量化参数?")
4. 工程化部署方案
4.1 硬件优化
- GPU加速:使用CUDA加速推理(NVIDIA 20系以上)
- CPU优化:
- 启用BLAS加速库(OpenBLAS/Intel MKL)
- 量化为4-bit/5-bit降低计算需求
4.2 交互接口
- 命令行工具:使用Typer库构建CLI
- 本地Web服务:FastAPI + Gradio前端
- 桌面应用:PyQt/Tauri框架打包
4.3 持续维护
- 增量更新:实现watchdog监控文件变动自动更新索引
- 版本管理:使用DVC跟踪知识库版本
- 日志审计:记录查询历史与知识溯源
5. 推荐工具栈
|
组件 |
推荐工具 |
|
文档解析 |
Unstructured, PyMuPDF |
|
文本切分 |
LangChain TextSplitter, spaCy |
|
向量模型 |
sentence-transformers, FastText |
|
向量数据库 |
Chroma, Qdrant |
|
本地LLM接口 |
llama-cpp-python, Ollama |
|
任务编排 |
LangChain, LlamaIndex |
6. 典型应用场景
- 学术研究:论文库快速问答
- 技术文档:代码库关联查询
- 个人记忆:日记/笔记语义检索
- 企业内网:私有化知识中枢
有了上面的基础知识铺垫后,接下来我们就最快捷的方式来举个例子吧
本次,基于本地部署的deepseek大模型来部署一个个人知识库
具体步骤:
第一步:
1 安装ollama: 地址:https://ollama.com/ (前面的文章有介绍安装步骤,比较简单,这里就不重复了)
第二步:
2 安装模型:
2.1安装一个deepseek-r1模型
确保1 安装成功后 在电脑cmd黑窗口中输入命令 :ollama run deepseek-r1:1.5b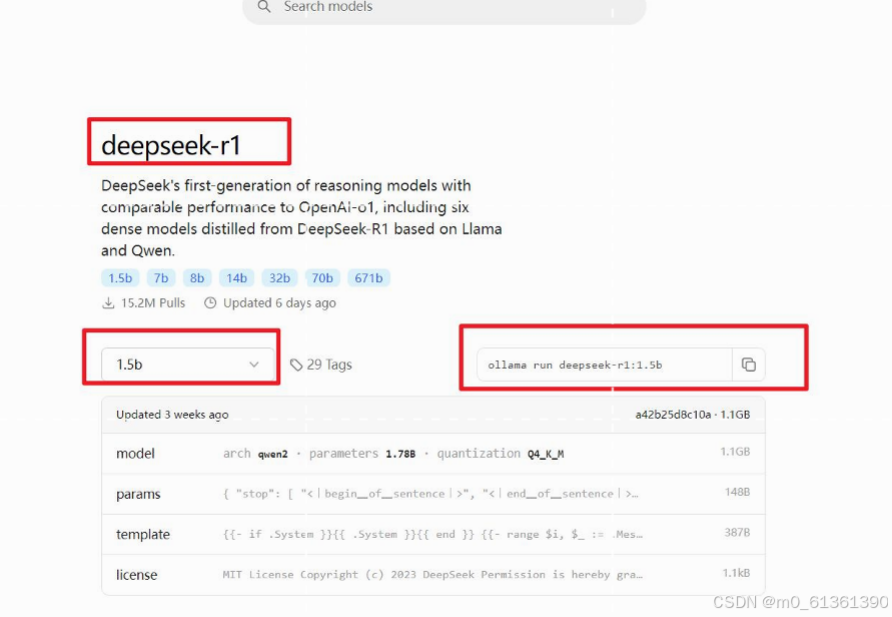
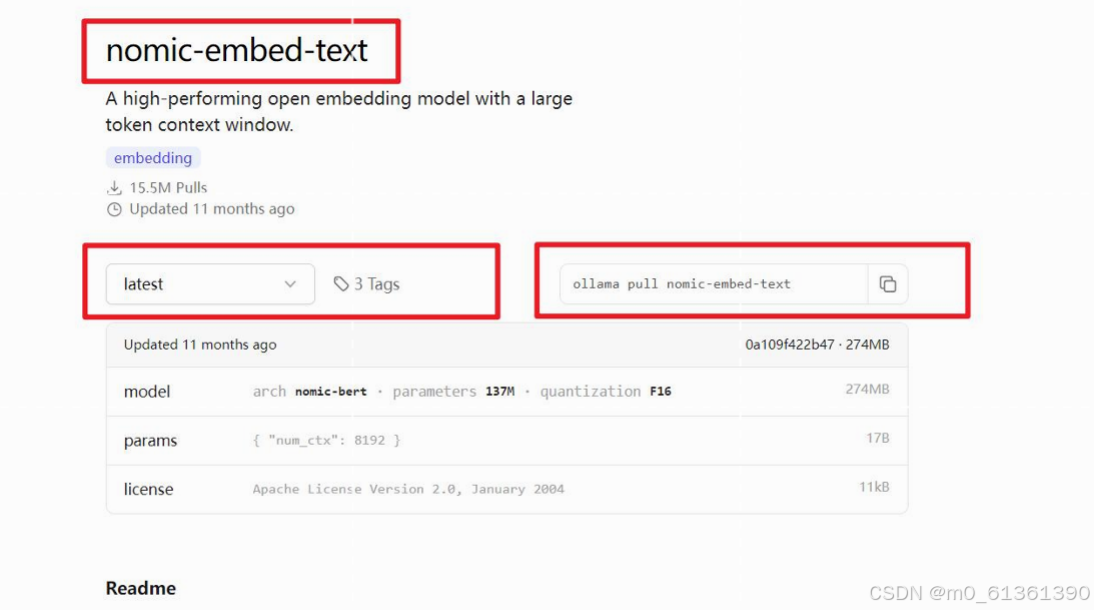
2.2 安装一个embedding解析模型
embedding"指的是将某种类型的输入数据(如文本、图像、声音等)转换成一个稠密的数值向量的过程,就是将输入的外部数据,向量化为Deepseek能识别的数据;
继续在cmd 的窗口中安装,输入命令: ollama pull nomic-embed-text
第三步:
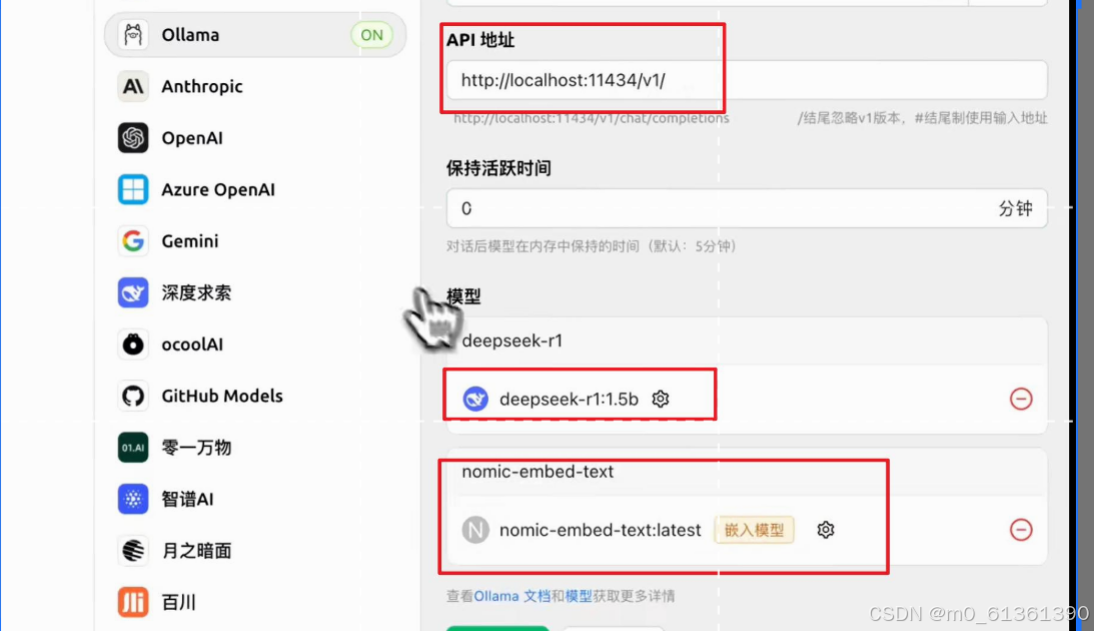
3.安装cherry Studio(可视化界面) 地址:https://www.cherry-ai.com/

3.1配置 确保本地本地的大模型都配置到cherry studio中了,配置方式见下图
3.2 将外部数据导入到模型中 (支持从多种数据)
点击知识库图标-->点击+号 -->创建一个知识库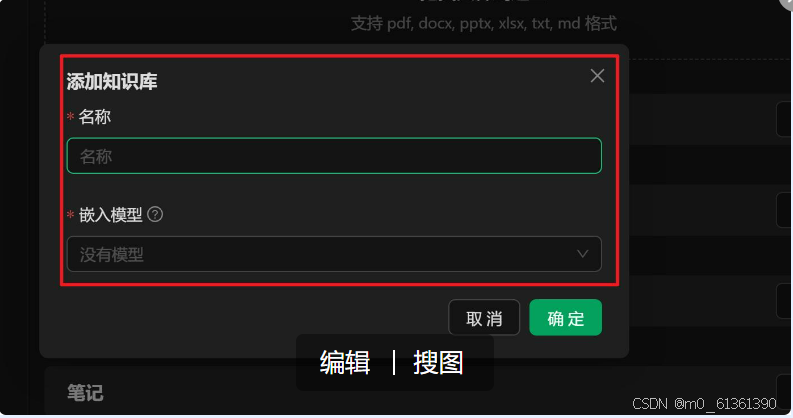
给知识库中增加自己想要的 本地搜索支持,下面是配置界面,支持网络和本地文件
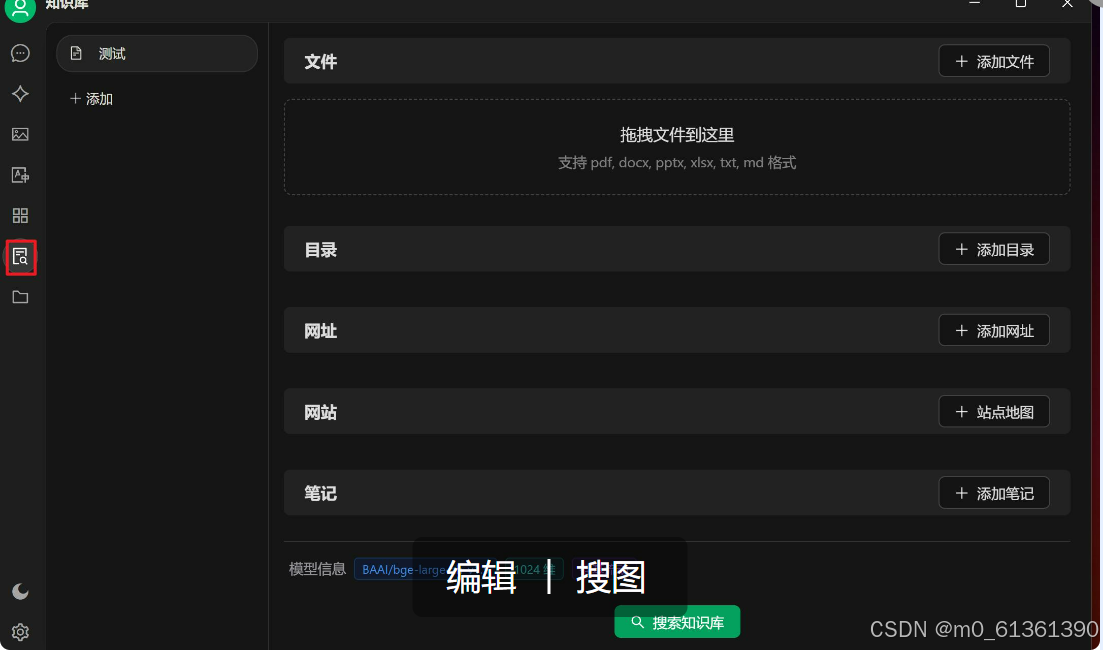 搜索的时候许需要勾选我们配置的知识库,这时候deepseek大模型搜索的就会从我们配置的知识库中去搜索啦;(搜索的时候记得勾选我们创建的知识库哦,操作如下图)
搜索的时候许需要勾选我们配置的知识库,这时候deepseek大模型搜索的就会从我们配置的知识库中去搜索啦;(搜索的时候记得勾选我们创建的知识库哦,操作如下图)
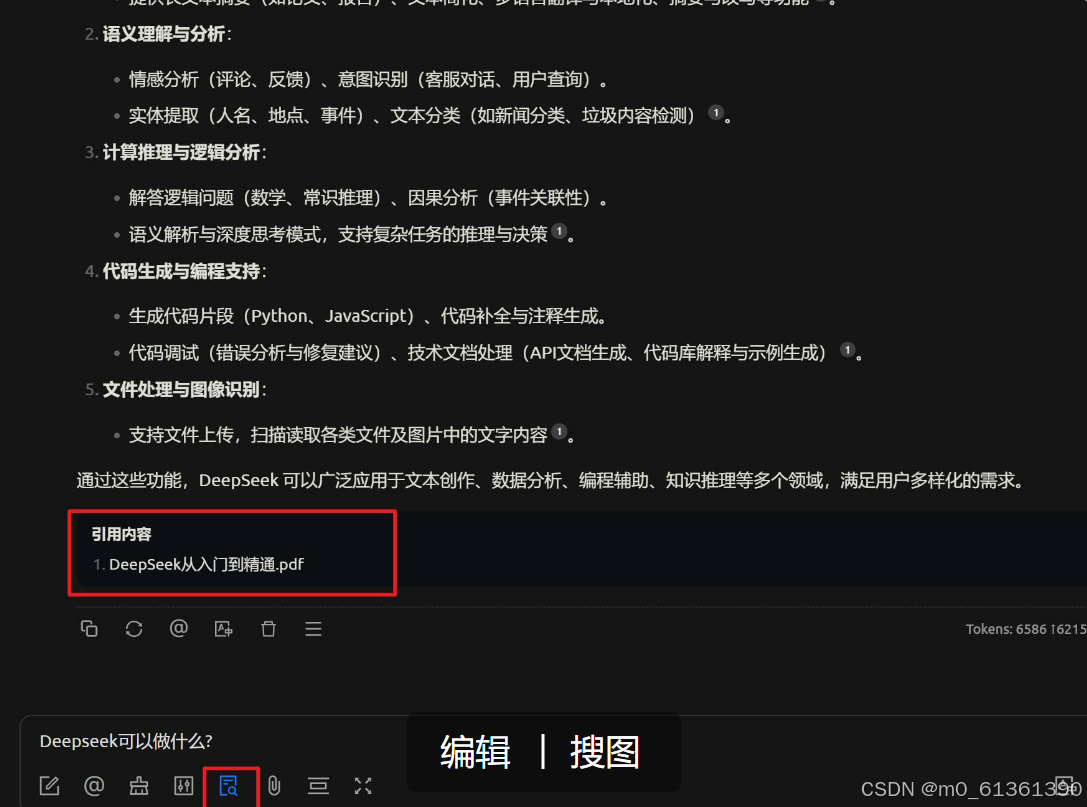
后面就可以愉快的使用啦;支持做很多行业检索,只要有相关的数据文件或者库就可以咯;快快行动起来吧
我是阳仔,每日分享使用的AI 使用技巧,喜欢的朋友欢迎点赞,收藏,转发,评论!!!!
如果还有什么想要看的欢迎留言讨论哦^_^


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









