






算法中,dfs,bfs是常见的考点,虽然效率不高,但简单有效。其中数的排列问题也是十分常见,堆循环也能解决,但dfs更加便捷,剪枝,回溯也能提高算法效率(虽然只提高那么一点,该超时还是会超时)
一.排列类型
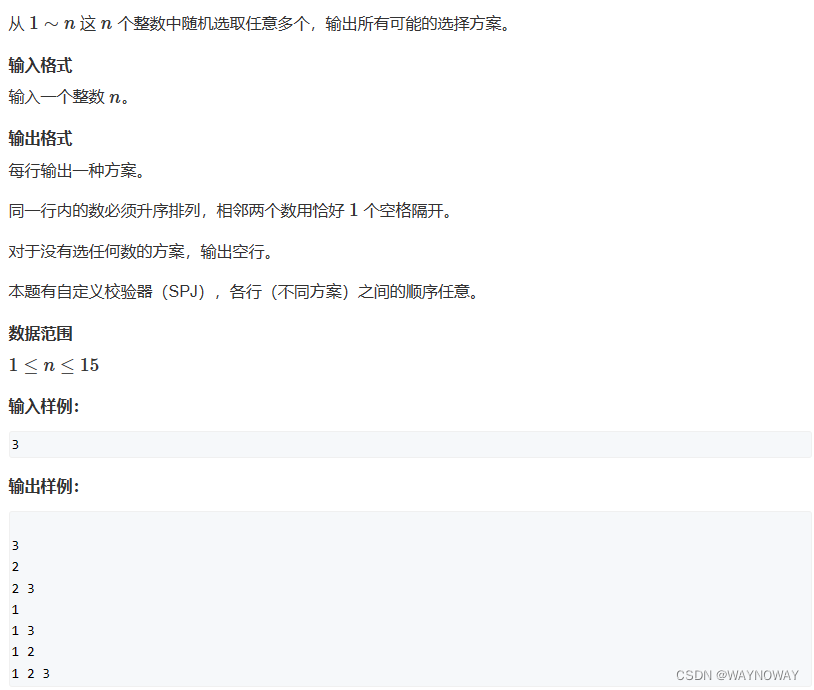
1.递归实现指数型枚举
#include <iostream>
#include <vector>
using namespace std;
int n;
int book[25];//标记数组,选择为1,否则为2
int arr[25];
void dfs(int index)
{
if(index > n){
for(int i=1;i<=n;i++){
if(book[i]==1){
cout<<i<<" ";
}
}
puts("");
return;
}
book[index] = 1;//选择index
dfs(index+1);
book[index] = 0;//回溯
book[index] = 2;//不选择
dfs(index+1);
book[index] = 0;
}
int main() {
cin>>n;
dfs(1);//dfs对1~n进行排列
return 0;
}
使用深度优先搜索(DFS)枚举给定范围内数的所有可能状态,并输出了所有可能的组合。具体来说,它是对于给定的 n 个数,每个数有两种状态(即选择和未选择),输出了所有可能的状态组合。在 dfs 函数中,它尝试将每个数标记为 1 或 2,然后递归遍历到下一个数。最后输出了所有可能的状态组合。对于每个数,它都有两种状态(1 或 2),通过递归的方式遍历了所有可能的情况。
2.递归实现组合型枚举

#include <iostream>
#include <vector>
using namespace std;
int n,m;
bool book[25];
vector<int> arr;//存储排列好的组合
void dfs(int index)
{
if((int)arr.size() == m){
for(auto i:arr){
cout<<i<<" ";
}
puts("");
return;
}
for(int i=index;i<=n;i++){//保证升序排列
arr.push_back(i);
dfs(i+1);
arr.pop_back();//回溯,清理容器,模拟下一种情况
}
}
int main() {
cin>>n>>m;
dfs(1);
return 0;
}
在 dfs 函数中,从当前的索引位置开始,依次选取数字并递归地探索下一个数字,直到达到了组合的长度上限为止。在达到组合长度后,它输出了当前的组合。完成对从 1 到 n中选取长度为 m的所有可能组合进行探索和输出
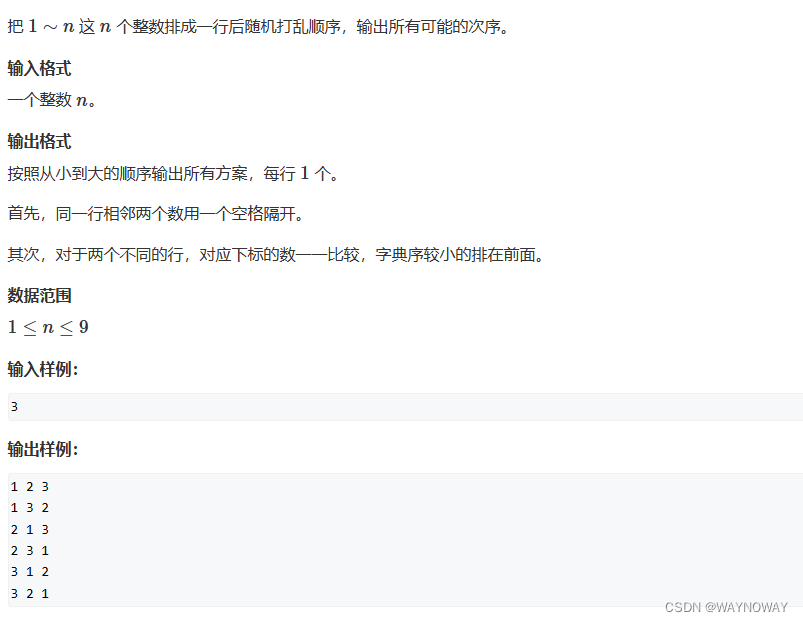
3.递归实现排列型枚举
#include <iostream>
#include <vector>
using namespace std;
int n;
bool book[25];//标记数组
vector<int> arr;//存储排序组合
void dfs()
{
if((int)arr.size() == n){
for(auto i:arr){
cout<<i<<" ";
}
puts("");
return;
}
for(int i=1;i<=n;i++){
if(!book[i]){//保证不会重复参与排序,即一个数只出现一次
book[i] = true;
arr.push_back(i);
dfs();
book[i] = false;//回溯
arr.pop_back();
}
}
}
int main() {
cin>>n;
dfs();
return 0;
}
数组 book 用来标记数字是否被使用过,另外使用了一个 vector<int> arr 用来存储当前生成的排列。具体来说,在 dfs 函数中,它尝试遍历所有可能的情况,从 1 到 n的数字中选取未被使用过的数字。对于每个数字,它标记为已使用(book[i] = true),将其加入当前排列 arr 中,然后递归探索下一个位置。当排列长度达到 n时,输出当前排列并返回。之后,它回溯到上一步,将刚才使用过的数字标记为未使用,继续探索其他可能的排列
二.例题
1.日期统计

#include<bits/stdc++.h>
using namespace std;
int b[]={0,31,28,31,30,31,30,31,31,30,31,30,31};
vector<int> arr;
bool book[50];
int a_f[110];
int x=1;
int a[50];
int date,mon,day;
set<int>q;//用来排重
void dfs(int index)
{
if( arr.size() == 4 ){
date = arr[0]*1000+arr[1]*100+arr[2]*10+arr[3];
mon = arr[0]*10+arr[1];
day = arr[2]*10+arr[3];
if(mon > 0 && mon <= 12 && day > 0 && day <= b[mon]){//判定
q.insert(date);//符合条件加入集合,排除重复日期
}
return;
}
for(int i=index;i<=40;i++){
arr.push_back(a[i]);
dfs(i+1);
arr.pop_back();
}
}
int main()
{
for(int i=1;i<=100;i++)//年份已固定,只用从后40位枚举
{
cin>>a_f[i];
}
for(int i=61;i<=100;i++){
a[x++] = a_f[i];//只读取数组40位,从出现2023的3的后一个数读入数组
}
dfs(1);
cout<<q.size()<<endl;//集合元素数量即符合的日期个数
return 0;
}
最开始是在数据结构课上学的搜索,不过当时只是涉及二叉树的遍历,对于排列问题遇到了也都是堆循环,直到准备蓝桥杯的时候才开始突击dfs,bfs这些,不过从结果来看,突击的结果好像不咋样...

















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









