







 本文介绍了Hive如何使用from insert语法进行多表插入操作,以减少数据源扫描次数。同时,针对Hive中map数据类型在insert语句中的使用问题进行了探讨,提供了两种解决方法,并提到了lateral view和explode等语法的应用,帮助优化代码效率。
本文介绍了Hive如何使用from insert语法进行多表插入操作,以减少数据源扫描次数。同时,针对Hive中map数据类型在insert语句中的使用问题进行了探讨,提供了两种解决方法,并提到了lateral view和explode等语法的应用,帮助优化代码效率。
hive的多插语句可以只扫描一次数据源表,往多张目标表插入数据,减少对数据源表的扫描次数。
from table1
insert overwrite/into table2 select [cols,…] where cond2
insert overwrite/into table3 select [cols,…] where cond3
insert overwrite/into table4 select [cols,…] where cond4
…
;
测试数据:
drop table if exists default.test001;
create table if not exists default.test001(
s_name string,
s_course map<string, int>
) comment 'name_course'
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
drop table if exists default.test002;
create table if not exists default.test002(
s_course string,
c_cnt int
) comment 'course_count';
drop table if exists default.test003;
create table if not exists default.test003(
s_name string,
s_score decimal(4,2)
) comment 'average_score';
insert overwrite table default.test001
select '张三' as s_name, map('语文',90,'数学',80,'英语',86,'生物',71) as s_course
union all
select '李四', map('语文',88,'数学',95,'英语',76,'化学',67)
union all
select '王五', map('语文',69,'数学',99,'英语',78,'物理',84);
select * from default.test001;

map数据类型在 insert into table values() 这种语法中,如果写在values的括号里面,会报错,所以直接 insert into table select 的语法处理。
insert into table default.test001 values(‘张三’,map(‘语文’,90,‘数学’,80,‘英语’,86,‘生物’,71));
org.apache.hadoop.hive.ql.parse.SemanticException:Expression of type TOK_FUNCTION not supported in insert/values
写法1:
with t1 as
(select t.s_name,
t.s_course['语文'] as chinese,
t.s_course['数学'] as math,
t.s_course['英语'] as english,
t.s_course['生物'] as biology,
t.s_course['化学'] as chemisty,
t.s_course['物理'] as physic
from default.test001 t),
t2 as (
select t1.s_name, 'chinese' as course, t1.chinese as score from t1
union all
select t1.s_name, 'math' as course, t1.math as score from t1
union all
select t1.s_name, 'english' as course, t1.english as score from t1
union all
select t1.s_name, 'biology' as course, t1.biology as score from t1
union all
select t1.s_name, 'chemisty' as course, t1.chemisty as score from t1
union all
select t1.s_name, 'physic' as course, t1.physic as score from t1
)
from t2
insert overwrite table default.test002
select t2.course, count(1) as course_cnt
where t2.score is not null
group by t2.course
insert overwrite table default.test003
select t2.s_name, avg(t2.score) as avg_socre
where t2.score is not null
group by t2.s_name
;
是不是很熟悉?类似mysql的行列互换。
结果如下:
select * from default.test002;
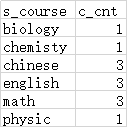
select * from default.test003;
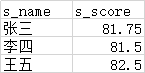
写法2:
with t2 as
(select t.s_name, course_t.course_name as course, course_t.course_score as score
from default.test001 t
lateral view explode(t.s_course) course_t as course_name, course_score
)
from t2
insert overwrite table default.test002
select t2.course, count(1) as course_cnt
group by t2.course
insert overwrite table default.test003
select t2.s_name, avg(t2.score) as avg_socre
group by t2.s_name
;
这是hive 的语法支持这些写法,可以减少代码的数量。
select * from default.test002;
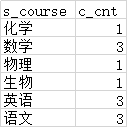
select * from default.test003;
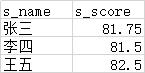
其中涉及到的hive 语法,可以到官网中查看相关的描述:
Language Manual
- from table insert table2 select [cols…] where cond2 …; 多插语句
- map 复合数据类型
- with as 临时表,用于在查询中出现多次的时候,简化代码
- lateral view
- explode
- insert overwrite 覆写数据

















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









