






目录
选取所有节点
以两个斜杠(//)开头的xpath规则会选取所有符合要求的节点.如果使用'//*',那么会选取整个HTML文档中所有的节点,其中星号(*)表示所有的节点.当然,'//'后面还可以跟更多的规则,如,要选取所有的<li>节点,可以使用'//li'
准备一个demo.html文件
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8">
<title>XPATH演示</title>
</head>
<body>
<div>
<ul>
<li class="item1"><a href="https://geekori.com">geekori.com</a></li>
<li class="item2"><a href="https://www.jd.com">京东商城</a></li>
<li class="item3"><a href="https://www.taobao.com">淘宝</a></li>
<li class="item4"><a href="https://www.google.com">谷歌</a></li>
<li class="item5"><a href="https://www.microsoft.com">微软</a></li>
</ul>
</div>
</body>
</html>选取所有节点的代码
from lxml import etree
parser=etree.HTMLParser()
html=etree.parse('demo.html',parser)
nodes=html.xpath('//*')
print('共',len(nodes),'个节点')
print(nodes)
# 输出所有节点的节点名
for i in range(0,len(nodes)):
print(nodes[i].tag,end=' ')
# 按层次输出节点,indent是缩进
def printNodeTree(node,indent):
print(indent+node.tag)
indent+=' '
children=node.getchildren()
if len(children)>0:
for i in range(0,len(children)):
# 递归调用
printNodeTree(children[i],indent)
print()
# 按层次输出节点对的节点,nodes[0]是根节点(html节点)
printNodeTree(nodes[0],'')
# 选取demo.html文件中所有的<a>节点
nodes=html.xpath('//a')
print()
print('共',len(nodes),'个<a>节点')
print(nodes)
# 输出所有<a>节点的文本
for i in range(0,len(nodes)):
print(nodes[i].text,end=' ')选取子节点
在选取子节点时,通常会将'/'和'//'规则放在一起使用,只用一个斜杠(/)表示选取当前节点下的直接子节点.例如,选取<li>节点下的<a>节点,可以使用'//li/a',也可以使用'//ul/a',由于<a>节点并不是<ul>的直接子节点,所以必须使用两个斜杠(//)才可以找到子孙节点<a>,而使用'//ul/a'是无法找打<a>节点的
from lxml import etree
parser=etree.HTMLParser()
html=etree.parse('demo.html',parser)
# 成功选取<a>节点
nodes=html.xpath('//li/a')
print('共',len(nodes),'个<a>节点')
print(nodes)
for i in range(0,len(nodes)):
print(nodes[i].text,end=' ')
print()
# 成功选取a节点
nodes=html.xpath('//ul//a')
print('共',len(nodes),'个<a>节点')
print(nodes)
for i in range(0,len(nodes)):
print(nodes[i].text,end=' ')
print()
# 无法选取<a>节点,因为<a>不是<ul>的直接子节点
nodes=html.xpath('//ul/a')
print('共',len(nodes),'个<a>节点')
print(nodes)选取父节点
如果知道子节点,想得到父节点,可使用'..',例如'//a[@class='class1']/..'可以得到class属性为class1的<a>节点的父节点.得到父节点还可以使用'parent::*',例:'//a[@class="class1"]/parent::*'
from lxml import etree
parser=etree.HTMLParser()
html=etree.parse('demo.html',parser)
#选取href属性值为https://www.jd.com的<a>节点的父节点,并输出父节点的class属性值
result=html.xpath('//a[@href="https://www.jd.com"]/../@class')
print('class属性=',result)
#选取href属性值为https://www.jd.com的<a>节点的父节点,并输出父节点的class属性值
result=html.xpath('//a[@href="https://www.jd.com"]/parent::*/@class')
print('class属性=',result)属性匹配与获取
使用xpath根据<a>节点的href属性过滤特定的<a>节点,并输出<a>节点的文本和url
本例使用contains函数判断属性值是否包含www.
contains函数第一个参数值是待匹配的值,如@href表示href属性,text()函数表示节点的文本
第二个参数值表示被包含的字符串,如本例的www
from lxml import etree
parser=etree.HTMLParser()
html=etree.parse('demo.html',parser)
#选取href属性值为https://geekori.com的<a>节点
nodes=html.xpath('//a[@href="https://geekori.com"]')
print('共',len(nodes),'个节点')
for i in range(0,len(nodes)):
print(nodes[i].text)
#选取所有href属性值包含www的<a>节点
nodes=html.xpath('//a[contains(@href,"www")]')
print('共',len(nodes),'个节点')
for i in range(0,len(nodes)):
print(nodes[i].text)
#选取所有href属性值包含www的<a>节点的href属性值,urls是href属性值的列表
urls=html.xpath('//a[contains(@href,"www")]/@href')
for i in range(0,len(urls)):
print(urls[i])多属性匹配
and表示与,or表示或
from lxml import etree
parser=etree.HTMLParser()
html=etree.parse('demo.html',parser)
# 选取herf属性值为https://www.jd.com或者https://www.microsoft.com的<a>节点
aList=html.xpath('//a[@href="https://www.jd.com" or @href="https://www.microsoft.com"]')
for a in aList:
print(a.text,a.get('href'))
# 匹配<li class="item5" value="1234"><a href="https://www.microsoft.com">微软</a></li>
# 选取href属性值包含www,并且父节点中value属性值等于1234的<a>节点
print('----------------')
aList=html.xpath('//a[contains(@href,"www") and ../@value="1234"]')
for a in aList:
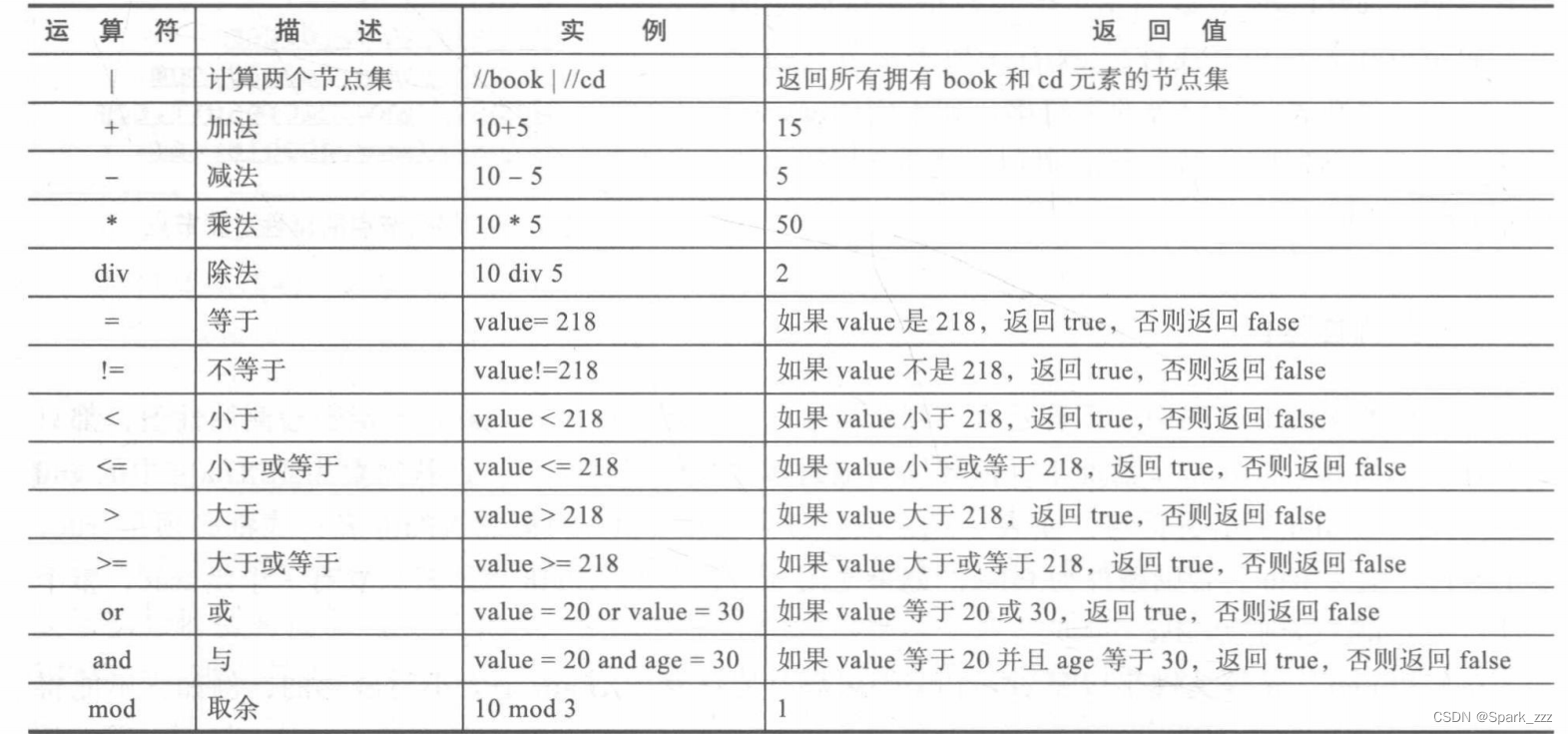
print(a.text,a.get('href'))除了and和or,xpath还有其他运算符


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









