






iText2KG
一种由 LLM 驱动的零样本方法,使用大型语言模型构建增量知识图谱(KG)
iText2KG 是一个 Python 包,通过利用大型语言模型从文本文档中提取实体和关系,逐步构建具有已解析实体和关系的一致知识图谱。
它具有零样本能力,无需专门的训练即可跨各个领域提取知识。
它包含四个模块:文档提炼器、增量实体提取器、增量关系提取器和图形集成器与可视化。
-
文档提取器:此模块将原始文档重新表述为预定义的语义块,并由指导 LLM 提取特定信息的模式引导。
-
增量实体提取器:此模块识别并解析语义块内的唯一语义实体,确保实体之间的清晰度和区别。
-
增量关系提取器:此组件处理已解析的实体以检测语义上唯一的关系,解决语义重复的挑战。
-
Neo4j图形集成器:最后一个模块以图形格式可视化关系和实体,利用 Neo4j 进行有效表示。
对于我们的 iText2KG 它包含了两大特点
-
增量构建:
iText2KG允许增量构建KG,这意味着它可以在新数据可用时不断更新和扩展图,而无需进行大量重新处理。 -
零样本学习:该框架利用
LLM的零样本功能,使其无需预定义集或外部本体即可运行。这种灵活性使其能够适应各种KG构建场景,而无需进行大量训练或微调。
一 、设置模型
在运行 iText2KG 之前,我们先设置好大模型,我这里选择的是 OpenAi 的模型以及 HuggingFace 的 bge-large-zh embedding 模型。这么选择也是考虑到构建 KG 的准确度。
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "*****"
openai_api_key = os.environ["OPENAI_API_KEY"]
openai_llm_model = llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
messages = [
(
"system",
"You are a helpful assistant that translates English to French. Translate the user sentence.",
),
("human", "I love programming."),
]
ai_msg=openai_llm_model.invoke(messages)
开始部署我们的 Embedding 模型:
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
openai_embeddings_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
text = "This is a test document."
query_result = openai_embeddings_model.embed_query(text)
query_result[:3]
doc_result = openai_embeddings_model.embed_documents([text])
二 、使用 iText2KG 构建 KG
我们这里的场景是,给出一篇简历,使用知识图谱将在线职位描述与生成的简历联系起来。
设定目标是评估候选人是否适合这份工作。
我们可以为 iText2KG 的每个模块使用不同的 LLM 或嵌入模型。但是,重要的是确保节点和关系嵌入的维度在各个模型之间保持一致。
如果嵌入维度不同,余弦相似度可能难以准确测量向量距离以进行进一步匹配。
我们的简历放到根目录,加载简历:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(f"./CV_Emily_Davis.pdf")
pages = loader.load_and_split()
初始化 DocumentDistiller 引入 llm :
from itext2kg.documents_distiller import DocumentsDisiller, CV
document_distiller = DocumentsDisiller(llm_model = openai_llm_model)
信息提炼:
IE_query = '''
# DIRECTIVES :
- Act like an experienced information extractor.
- You have a chunk of a CV.
- If you do not find the right information, keep its place empty.
'''
# 使用定义好的查询和输出数据结构提炼文档。
distilled_cv = document_distiller.distill(documents=[page.page_content.replace("{", '[').replace("}", "]") for page in pages], IE_query=IE_query, output_data_structure=CV)
将提炼后的文档格式化为语义部分。
semantic_blocks_cv = [f"{key} - {value}".replace("{", "[").replace("}", "]") for key, value in distilled_cv.items() if value !=[] and value != "" and value != None]
我们可以自定义输出数据结构,我们这里定义了4种,工作经历模型,岗位,技能,证书。
from pydantic import BaseModel, Field
from typing import List, Optional
class JobResponsibility(BaseModel):
description: str = Field(..., description="A specific responsibility in the job role")
class JobQualification(BaseModel):
skill: str = Field(..., description="A required or preferred skill for the job")
class JobCertification(BaseModel):
certification: str = Field(..., description="Required or preferred certifications for the job")
class JobOffer(BaseModel):
job_offer_title: str = Field(..., description="The job title")
company: str = Field(..., description="The name of the company offering the job")
location: str = Field(..., description="The job location (can specify if remote/hybrid)")
job_type: str = Field(..., description="Type of job (e.g., full-time, part-time, contract)")
responsibilities: List[JobResponsibility] = Field(..., description="List of key responsibilities")
qualifications: List[JobQualification] = Field(..., description="List of required or preferred qualifications")
certifications: Optional[List[JobCertification]] = Field(None, description="Required or preferred certifications")
benefits: Optional[List[str]] = Field(None, description="List of job benefits")
experience_required: str = Field(..., description="Required years of experience")
salary_range: Optional[str] = Field(None, description="Salary range for the position")
apply_url: Optional[str] = Field(None, description="URL to apply for the job")
定义一个招聘工作需求的描述:
job_offer = """
About the Job Offer
THE FICTITIOUS COMPANY
FICTITIOUS COMPANY is a high-end French fashion brand known for its graphic and poetic style, driven by the values of authenticity and transparency upheld by its creator Simon Porte Jacquemus.
Your Role
Craft visual stories that captivate, inform, and inspire. Transform concepts and ideas into visual representations. As a member of the studio, in collaboration with the designers and under the direction of the Creative Designer, you should be able to take written or spoken ideas and convert them into designs that resonate. You need to have a deep understanding of the brand image and DNA, being able to find the style and layout suited to each project.
Your Missions
Translate creative direction into high-quality silhouettes using Photoshop
Work on a wide range of projects to visualize and develop graphic designs that meet each brief
Work independently as well as in collaboration with the studio team to meet deadlines, potentially handling five or more projects simultaneously
Develop color schemes and renderings in Photoshop, categorized by themes, subjects, etc.
Your Profile
Bachelor’s degree (Bac+3/5) in Graphic Design or Art
3 years of experience in similar roles within a luxury brand's studio
Proficiency in Adobe Suite, including Illustrator, InDesign, Photoshop
Excellent communication and presentation skills
Strong organizational and time management skills to meet deadlines in a fast-paced environment
Good understanding of the design process
Freelance cont
继续使用上面方法做信息提炼:
IE_query = '''
# DIRECTIVES :
- Act like an experienced information extractor.
- You have a chunk of a job offer description.
- If you do not find the right information, keep its place empty.
'''
distilled_Job_Offer = document_distiller.distill(documents=[job_offer], IE_query=IE_query, output_data_structure=JobOffer)
print(distilled_Job_Offer)
semantic_blocks_job_offer = [f"{key} - {value}".replace("{", "[").replace("}", "]") for key, value in distilled_Job_Offer.items() if value !=[] and value != "" and value != None]
到这里准备工作完成,简历和工作需求都已经提炼完毕,然后正式开始构建 graph,我们将简历的所有语义块作为一个块传递给了 LLM。
也将工作需求作为另一个语义块传递,也可以在构建图时将语义块分开。
我们需要注意每个块中包含多少信息,然后好将它与其他块连接起来,我们在这里做的就是一次性传递所有语义块。
from itext2kg import iText2KG
itext2kg = iText2KG(llm_model = openai_llm_model, embeddings_model = openai_embeddings_model)
global_ent, global_rel = itext2kg.build_graph(sections=[semantic_blocks_cv], ent_threshold=0.6, rel_threshold=0.6)
global_ent_, global_rel_ = itext2kg.build_graph(sections=[semantic_blocks_job_offer], existing_global_entities = global_ent, existing_global_relationships = global_rel, ent_threshold=0.6, rel_threshold=0.6)
iText2KG 构建 KG 的过程我们看到有很多参数,下面分贝是对每个参数的表示做一些解释:
-
llm_model:用于从文本中提取实体和关系的语言模型实例。 -
embeddings_model:用于创建提取实体的向量表示的嵌入模型实例。 -
sleep_time (int):遇到速率限制或错误时等待的时间(以秒为单位)(仅适用于OpenAI)。默认为 5 秒。
iText2KG 的 build_graph 参数:
-
sections(List[str]):字符串(语义块)列表,其中每个字符串代表文档的一部分,将从中提取实体和关系。 -
existing_global_entities(List[dict], optional):与新提取的实体进行匹配的现有全局实体列表。每个实体都表示为一个字典。 -
existing_global_relationships (List[dict], optional):与新提取的关系匹配的现有全局关系列表。每个关系都表示为一个字典。 -
ent_threshold (float, optional):实体匹配的阈值,用于合并不同部分的实体。默认值为 0.7。 -
rel_threshold (float, optional):关系匹配的阈值,用于合并不同部分的关系。默认值为 0.7。


从图中结果看到我们构建过程中的实体,和关联关系。
最后使用 GraphIntegrator 对构建的知识图谱进行可视化。
使用指定的凭据访问图形数据库 Neo4j,并对生成的图形进行可视化,以提供从文档中提取的关系和实体的视觉表示。
from itext2kg.graph_integration import GraphIntegrator
URI = "bolt://3.216.93.32:7687"
USERNAME = "neo4j"
PASSWORD = "selection-cosal-cubes"
new_graph = {}
new_graph["nodes"] = global_ent_
new_graph["relationships"] = global_rel_
GraphIntegrator(uri=URI, username=USERNAME, password=PASSWORD).visualize_graph(json_graph=new_graph)
打开我们的 Neo4j 图形数据库:
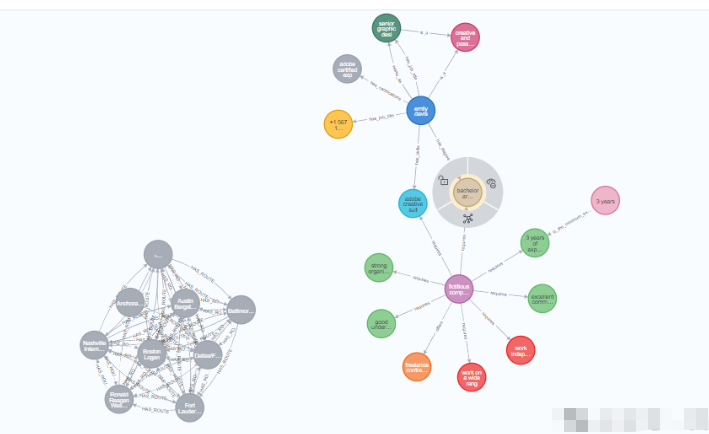
可以看到简历和工作需求的匹配关系连接。这样子我们可以灵活的运用 iText2KG 框架做图形关系和实体的增量。
三、总结
本文介绍了使用大型语言模型 ( LLM ) 构建增量知识图谱 ( KG ) 的 iText2KG 框架。一个强大的 KG 构建框架,该框架利用了 LLM 的优势,解决了该领域的重大挑战,并提出了一种模块化方法,可增强不同领域的灵活性和适用性。
-
增强的架构一致性:
iText2KG方法在各种文档类型中实现了高架构一致性,优于由于依赖预定义结构而经常难以保持一致性的传统方法。 -
实体和关系提取的高精度:该框架有效地缓解了与语义重复和未解决实体相关的问题,这些问题在传统方法中普遍存在。这导致更准确和可靠的
KG。 -
减少后处理需求:传统方法通常需要大量的后处理来解决歧义和冗余。
iText2KG通过采用结构化结构来最大限度地减少这种需求。
四、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









