






引言
起因
最近准备打算在docker上部署人工智能项目。大致的场景就是在矿区内部署一些个监控设备,监控一些特定的场景,主要是去识别一些危险区域,危险行为,设备异常之类。传统的人工智能项目多采用服务器直接部署,但是这样就一个不方便的地方,不能把人工智能算法的主动权交给客户。人工智能项目往往是使用特定模型,特定算法去针对一些特定场景去识别的。这就导致如果用户提出需求说想要更换算法模型或者,更换摄像头识别的设备,或者更换模型参数等,都需要程序员直接介入,首先必须要做的一步就是先把程序停止,然后再重启。
解决办法
那我们能不能直接把模型启停和参数设置以及更换设备的主动权交给客户来做呢?那就是我这次博客中想要带来的内容。使用docker部署人工智能项目可以大大的减轻程序员的工作量,同时满足客户频繁需要更换设备的需求!
docker守护进程配置
前提说明
在您看到这一章的时候,默认您已经了解了docker如何安装,docker的安装教程,在我前面的一篇文章中已经提到。当然这里也都默认使用linux-centos7进行部署安装。如果您使用的是ubuntu系统或者其他linux系统,建议您参考对应的docker安装教程。
什么是docker守护进程
那么什么是docker守护进程呢?Docker 守护进程(Docker Daemon)是 Docker 的核心组成部分,负责管理和执行 Docker 容器相关的操作。它通常以后台进程的形式运行,并且与 Docker 客户端(CLI)进行交互,处理来自客户端的请求。
Docker 守护进程的主要功能包括:
- 管理容器:它创建、启动、停止、删除容器,并确保容器的生命周期得到管理。
- 管理镜像:Docker 守护进程会从 Docker 仓库拉取镜像,或者构建新镜像,并确保它们能正确地存储和管理。
- 管理网络:它负责容器间的网络管理,包括创建和管理 Docker 网络,以支持容器之间的通信。
- 管理存储:它负责管理 Docker 容器使用的存储卷(volumes),确保数据持久化。
- 处理客户端请求:Docker 守护进程通过监听 Unix 套接字或 TCP/IP 套接字来接收来自客户端的命令。客户端通过 Docker CLI 或其他 API 发出请求,守护进程会解析请求并执行相应的操作。
由此我们不得不提出如何使用客户端连接docker守护进程,进行docker的直接操作了。
Docker 守护进程的远程访问:端口 2375 和 2376
Docker 守护进程(dockerd)默认情况下通过 Unix 套接字(/var/run/docker.sock)与 Docker 客户端通信。但是,如果希望远程管理 Docker 主机或服务器上的容器,可以通过 TCP 端口进行通信。通常,Docker 守护进程会监听以下两个端口:
- 2375 端口:用于未加密的 HTTP 通信。
- 2376 端口:用于加密的 HTTPS 通信。
端口 2375(不安全-不推荐)
-
默认情况下,端口 2375 是 Docker 守护进程的开放端口,它允许 Docker 客户端通过网络与 Docker 守护进程进行通信。但是,这个端口不加密通信,因此它不安全。
-
使用端口 2375 时,不会进行任何加密或身份验证,这使得它容易受到中间人攻击,因此不建议在生产环境中使用该端口。
启用 Docker 通过端口 2375 监听: 要允许 Docker 守护进程通过 2375 端口进行连接,你需要修改 Docker 配置文件或启动时指定相关参数。
建议大家直接跳过不使用这个端口操作docker守护进程,因为我之前试过,服务器容器产生安全漏洞,被人挖矿了。强烈推荐使用2376端口去操作docker守护进程。
端口 2376(安全-推荐)
-
端口 2376 是 Docker 的 HTTPS 安全通信端口,通常用于加密和验证连接。使用该端口时,Docker 会加密客户端和守护进程之间的通信,确保数据传输的安全性。
-
端口 2376 使用 SSL/TLS 协议进行加密,需要配置证书和密钥来进行身份验证。
启用 Docker 通过端口 2376 监听: 要让 Docker 守护进程通过端口 2376 进行加密通信,需要配置 SSL/TLS 证书:
配置步骤
1.编辑文件:vim /usr/lib/systemd/system/docker.service
修改前:
ExecStart=/usr/bin/dockerd -H f:// --containerd=/run/containerd/containerd.sock修改后(即去掉-H f://):
ExecStart=/usr/bin/dockerd --containerd=/run/containerd/containerd.sock2.创建 SSL 证书和密钥(server-cert.pem、server-key.pem 和 ca-cert.pem)。
如果你还没有证书,可以按照以下步骤生成它们:注意事项:这些证书文件一会儿会默认生成在您运行命令的当前目录,如果您不想保存在当前目录可以切换到一个专门存放这些证书文件的目录。防止证书文件被您意外删除--后续要用到。
- 创建CA证书(请依次执行,一行一行复制)
openssl genrsa -aes256 -out ca-key.pem 2048
openssl req -x509 -new -nodes -key ca-key.pem -sha256 -days 1024 -out ca.pem- 创建服务器证书(请依次执行,一行一行复制)
openssl genrsa -out server-key.pem 2048
openssl req -new -key server-key.pem -out server.csr
openssl x509 -req -in server.csr -CA ca.pem -CAkey ca-key.pem -CAcreateserial -out server-cert.pem -days 500 -sha256- 创建客户端证书(可选):
openssl genrsa -out key.pem 2048
openssl req -new -key key.pem -out client.csr
openssl x509 -req -in client.csr -CA ca.pem -CAkey ca-key.pem -CAcreateserial -out cert.pem 3.配置 Docker 守护进程: vim /etc/docker/daemon.json 配置文件,将生成的证书放置在 Docker 配置中指定的位置,如下所示: 修改deamon.json配置文件,加入如下配置(附送docker镜像加速地址-国内速度加快!):
其中tlscacert、tlscert、tlskey的配置文件改成步骤2中您在本地生成的证书文件所在目录。
{
"hosts": ["tcp://0.0.0.0:2376", "unix:///var/run/docker.sock"],
"tlscacert": "/hhk/ca.pem",
"tlscert": "/hhk/server-cert.pem",
"tlskey": "/hhk/server-key.pem",
"registry-mirrors": [
"http://hub.xdark.top",
"http://dockerpull.com",
"http://dockerproxy.cn/",
"https://registry.dockermirror.com/",
"https://docker.1panel.live/",
"https://hub.rat.dev/",
"https://dhub.kubesre.xyz/"
]
}4.重启docker守护进程,让上述这些配置生效。
systemctl daemon-reload
systemctl restart docker
systemctl enable dockerdocker使用服务器中的gpu配置
本地gpu以及CUDA驱动版本
很多人在纳闷自己的服务器上有nvidia GPU可是在docker内部却无法正常调用nvidia-gpu,这是一个令人头大的问题。如果您的机器上支持gpu。则使用nvidia-smi命令应该能够查看到本地的GPU信息以及支持的的最高版本的CUDA,如下图所示。我的是12.4版本。
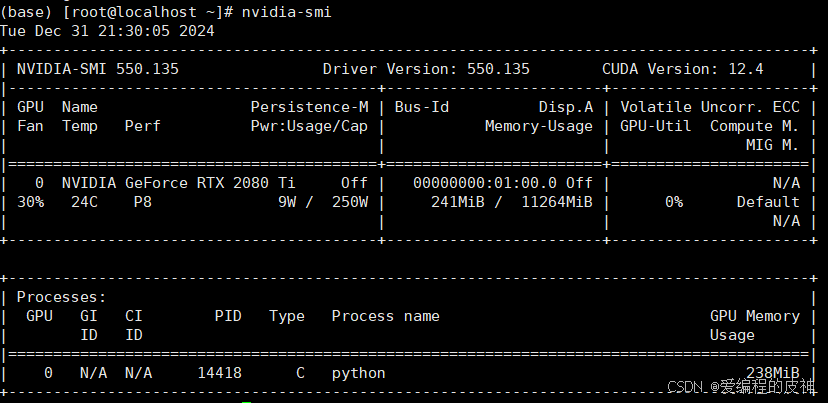
而且如果您已经安装了相关的CUDA驱动包,则可以使用如下命令nvcc -V进行查看您安装的CUDA的版本信息。
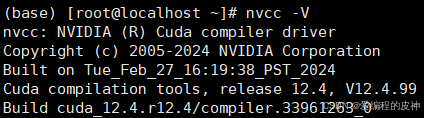
接下来您可以开始在docker中验证是否能够正常使用机器中自带的gpu了,默认肯定是不行的。下面我就如何在docker中验证是否启用gpu,以及如何进行人工智能算法部署进行介绍。
docker构建yolo镜像
我们以yolo为例开始讲解如何拉取yolo镜像,构建yolo镜像使用yolo完成一个AI项目的构建,在docker中启用GPU进行预测。
1.安装兼容版本的pytorch/pytorch镜像去构建。首先要先查看您本地的CUDA版本信息(nvcc -V)去查看。拉取对应版本的的pytorch镜像才可以。
官方地址:https://hub.docker.com/r/pytorch/pytorch/tags?name=11.1。国内用户可以使用科学上网工具进行访问哦!如果不行可以留下邮箱找我进行获取~。
而我这边的CUDA版本是12.4,进入官网直接搜12.4即可。
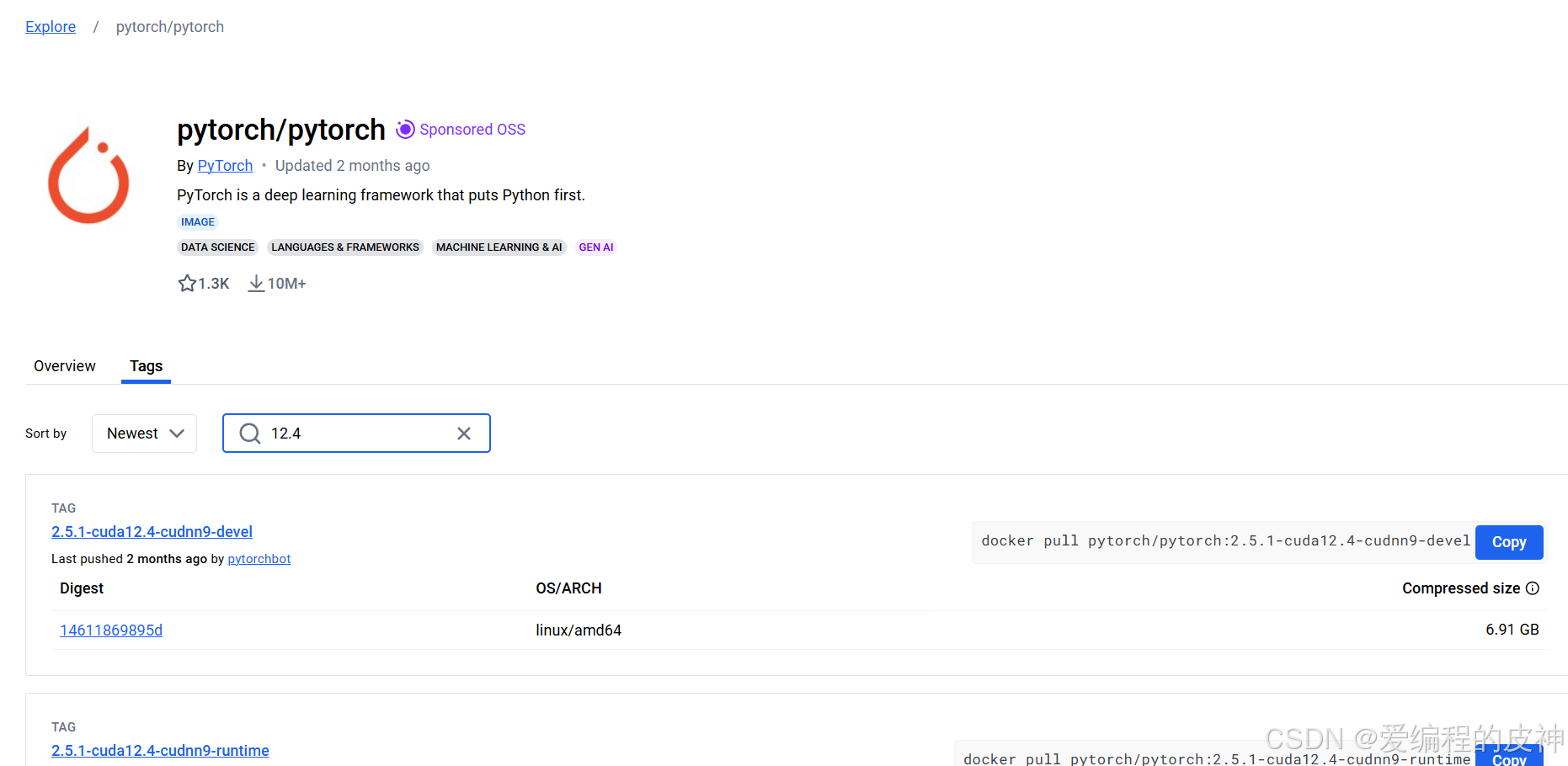
选用后缀-runtime的进行下载。我这里直接拉取最新的镜像。
docker pull pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime 然后就是漫长的拉取过程,如果大家拉的太慢的话,一定要给docker配置阿里云镜像仓库哦。还有就是设置镜像加速地址。前面已经介绍过了。下载下来大概有几个G。还是挺大的这个镜像。
下载完成之后可以使用docker images命令进行查看:

下载完毕之后大家需要使用上述pytorch镜像构建一个新的Dockerfile镜像。因为上面的pytorch只拥有了一些基础的pytorch环境并不具备,yolo的依赖环境。
Dockerfile大家自取。记得第一行改成您下载的镜像。
# 使用与CUDA 11.2兼容的PyTorch官方镜像作为基础镜像
# 使用nvidia-smi查看服务器CUDA 版本,然后参考PyTorch官方说明来选择合适的镜像,否则会出错!
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
# 所需要的包
RUN pip install scipy -i https://mirrors.aliyun.com/pypi/simple
RUN pip install numpy -i https://mirrors.aliyun.com/pypi/simple
RUN pip install matplotlib -i https://mirrors.aliyun.com/pypi/simple
RUN pip install tqdm -i https://mirrors.aliyun.com/pypi/simple
RUN pip install PyYAML -i https://mirrors.aliyun.com/pypi/simple
RUN pip install Pillow -i https://mirrors.aliyun.com/pypi/simple
RUN pip install opencv_python -i https://mirrors.aliyun.com/pypi/simple
RUN pip install tensorboard -i https://mirrors.aliyun.com/pypi/simple
RUN pip install h5py -i https://mirrors.aliyun.com/pypi/simple
RUN pip install Seaborn -i https://mirrors.aliyun.com/pypi/simple
RUN pip install ultralytics -i https://mirrors.aliyun.com/pypi/simple
RUN pip install yolo -i https://mirrors.aliyun.com/pypi/simple
#这个错误提示 ImportError: libGL.so.1: cannot open shared object file: No such file or #directory 通常是由于缺少 OpenGL 库,libGL.so.1 是 OpenGL 库的一个文件,它是 opencv-# # #python(cv2)库的依赖项。之后就支持导出tensorRT模型了。
# 上述构建了一个基础的镜像。此时还需要图像处理器。
RUN apt update
RUN apt install -y libgl1-mesa-glx
RUN apt install -y libglib2.0-0
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 再次导出。可以导出tensorRT模型了。又是一段时间的构建镜像和安装新的python依赖环境。上面构建完毕的镜像就拥有了必要的环境了。当然还要注意一般情况下构建之后的镜像在之后进入目标检测等相关任务的时候可能会发生报错,找不到机器上的图像处理器等,大家可以参考我上面的后面几行配置进行添加。最后是使用国内的清华源镜像对pip安装进行加速。
这样安装好后的镜像,除了拥有python的环境还具备了conda的环境,我搜了一下,官方的pytorch镜像是基于anaconda进行构建的。这样就省事多了。
如果后续使用avc1编码器进行视频编码,默认的opencv-python环境编码视频的时候经常报错。说找不到ffmpeg等h264编码错误。所以需要的可以不根据上面那个配置使用更完整的Dockerfile文件。
# 使用与CUDA 11.2兼容的PyTorch官方镜像作为基础镜像
# 使用nvidia-smi查看服务器CUDA 版本,然后参考PyTorch官方说明来选择合适的镜像,否则会出错!
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
# 所需要的包
RUN pip install scipy -i https://mirrors.aliyun.com/pypi/simple
RUN pip install numpy -i https://mirrors.aliyun.com/pypi/simple
RUN pip install matplotlib -i https://mirrors.aliyun.com/pypi/simple
RUN pip install tqdm -i https://mirrors.aliyun.com/pypi/simple
RUN pip install PyYAML -i https://mirrors.aliyun.com/pypi/simple
RUN pip install Pillow -i https://mirrors.aliyun.com/pypi/simple
RUN pip install opencv_python -i https://mirrors.aliyun.com/pypi/simple
RUN pip install tensorboard -i https://mirrors.aliyun.com/pypi/simple
RUN pip install h5py -i https://mirrors.aliyun.com/pypi/simple
RUN pip install Seaborn -i https://mirrors.aliyun.com/pypi/simple
RUN pip install ultralytics -i https://mirrors.aliyun.com/pypi/simple
RUN pip install yolo -i https://mirrors.aliyun.com/pypi/simple
#这个错误提示 ImportError: libGL.so.1: cannot open shared object file: No such file or #directory 通常是由于缺少 OpenGL 库,libGL.so.1 是 OpenGL 库的一个文件,它是 opencv-# # #python(cv2)库的依赖项。之后就支持导出tensorRT模型了。
# 上述构建了一个基础的镜像。此时还需要图像处理器。
RUN apt update
RUN apt install -y libgl1-mesa-glx
RUN apt install -y libglib2.0-0
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 再次导出。可以导出tensorRT模型了。
# 更完整的配置--卸载掉默认的opencv库,使用conda安装可以编码视频的opencv
RUN pip uninstall opencv-python opencv-contrib-python -y
RUN conda install -c conda-forge opencv -y经过上面的Dockerfile构建yolo镜像。
docker build -t yolo .构建完毕后查看镜像信息:docker images,如下图所示。
![]()
使用交互式命令从yolo镜像构建为容器
docker run -it --gpus all --ipc=host yolo /bin/bash - 创建并启动一个新的容器。
- 使用名为
yolo的镜像。 - 启用交互式终端(
-it),让用户可以直接操作容器。 - 允许容器访问宿主机的所有 GPU(
--gpus all),用于运行需要 GPU 加速的程序。 - 配置容器共享宿主机的 IPC 命名空间(
--ipc=host),提高共享内存使用效率。 - 启动后进入容器的 Bash Shell(
/bin/bash)。
应用场景
- 在容器中运行需要 GPU 加速的深度学习任务,例如训练或推理 YOLO 模型。
- 提供一个调试和交互式环境,以便在容器中配置和测试代码。
之后可以在出现的控制台中验证是否能够访问到本机的gpu。如下所示。
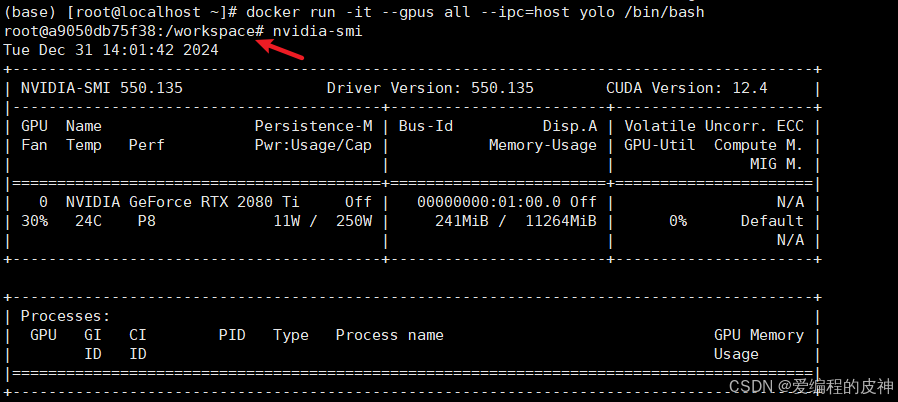
为什么在docker内无法查看gpu信息
解决办法
. NVIDIA Container Toolkit 未安装
-
问题:Docker 默认不支持直接访问 GPU,需要安装 NVIDIA Container Toolkit(以前叫 nvidia-docker2)。
-
安装 NVIDIA Container Toolkit:
# 安装nvidia-docker
sudo yum install -y nvidia-docker2 nvidia-container-runtime上述安装Nvidia-docker遇到报错:
[root@localhost docker]# yum install -y nvidia-docker2 nvidia-container-runtime
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* epel: repo.jing.rocks
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
No package nvidia-docker2 available.
No package nvidia-container-runtime available.
Error: Nothing to do
出现上面的原因。 需要下载这两个文件:nvidia-docker.repo 以及nvidia-container-runtime.repo。并配置到指定目录/etc/yum.repos.d/下。这是一个目录,在基于 YUM(Yellowdog Updater, Modified) 的 Linux 发行版(如 CentOS、RHEL、Fedora 等)中用于存放 YUM 软件仓库配置文件。这些配置文件定义了系统从哪些仓库(repository)中获取软件包以及如何更新这些软件包。
下载方式:通过网盘分享的文件:nvidia-docker
链接: https://pan.baidu.com/s/11CYYumoHirRer_mny1Ewgg?pwd=c87g 提取码: c87g
上述俩个为念下载之后上传至服务器的/etc/yum.repos.d/目录下面即可。
接下来我们重新安装:
# 安装nvidia-docker
sudo yum install -y nvidia-docker2 nvidia-container-runtime安装完成之后,我们查看一下daemon.json文件看看是否多了一个配置。cat /etc/docker/daemon.json。runtimes环境有了即可。
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"registry-mirrors": [
"http://hub.xdark.top",
"http://dockerpull.com",
"http://dockerproxy.cn/",
"https://registry.dockermirror.com/",
"https://docker.1panel.live/",
"https://hub.rat.dev/",
"https://dhub.kubesre.xyz/"
]
}重启docker守护进程:
systemctl daemon-reload
systemctl restart docker
systemctl enable docker使用gpu可访问模式启动yolo镜像操作。
docker run -it --gpus all --ipc=host yolo /bin/bash 重新输入nvidia-smi命令查看。即可发现如下:说明我们已经成功了!
总结
基于上述的整个环境配置我们即可拥有一套基于docker的人工智能项目部署方案。后期可以使用python或者java客户端等去操作docker守护进程。对部署的yolo项目进行启动,以及设备绑定。这样就可以把主动权交给客户来操作了!

















 77
77

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









