






本文介绍了nnom源文件中的auto_test示例代码的运行,其总体思路为在PC上用tensorflow训练模型,并导出权重为weights.h,从而可以用C语言加载模型文件,并且利用神经网络进行预测。项目地址:
https://github.com/majianjia/nnom/tree/master一、用tensorflow框架生成weights.h文件
1.创建环境,运行如下指令
注意tensorflow版本要小于2.14,git下载时注意开启代理
conda create -n keras python==3.8
activate keras
pip install git+https://github.com/majianjia/nnom@master
pip install tensorflow==2.10.02.下载visual studio code。
3.下载visual studio,并且配置环境变量
3.1visual stdio下载
注意:安装时选择仅“C++桌面”,其他不选
3.2配置CL指令的环境变量
【C/C++】VS的cl命令 | 配置环境变量 | 使用命令行编译C/C++程序-优快云博客
4.安装scons
pip install scons5.修改源码
下载源码,用vscode打开Auto_test文件。作者使用window操作系统,python3.8,因此sys.pltform为'win32',而不是'win'。修改main.py中的第142行的代码
cmd = ".\mnist.exe" if 'win' in sys.platform else "./mnist"
修改为
cmd = ".\mnist.exe" if 'win32' in sys.platform else "./mnist"
4.运行main.py
运行结果如下:
60000 train samples
10000 test samples
x_train shape: (60000, 28, 28, 1)
data range 0.0 1.0
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 16) 160
batch_normalization (BatchN (None, 26, 26, 16) 64
ormalization)
conv2d_1 (Conv2D) (None, 22, 22, 16) 6416
batch_normalization_1 (Batc (None, 22, 22, 16) 64
hNormalization)
leaky_re_lu (LeakyReLU) (None, 22, 22, 16) 0
max_pooling2d (MaxPooling2D (None, 11, 11, 16) 0
)
dropout (Dropout) (None, 11, 11, 16) 0
depthwise_conv2d (Depthwise (None, 7, 7, 32) 320
Conv2D)
batch_normalization_2 (Batc (None, 7, 7, 32) 128
hNormalization)
re_lu (ReLU) (None, 7, 7, 32) 0
dropout_1 (Dropout) (None, 7, 7, 32) 0
conv2d_2 (Conv2D) (None, 7, 7, 16) 528
batch_normalization_3 (Batc (None, 7, 7, 16) 64
hNormalization)
re_lu_1 (ReLU) (None, 7, 7, 16) 0
max_pooling2d_1 (MaxPooling (None, 4, 4, 16) 0
2D)
dropout_2 (Dropout) (None, 4, 4, 16) 0
flatten (Flatten) (None, 256) 0
dense (Dense) (None, 64) 16448
re_lu_2 (ReLU) (None, 64) 0
dropout_3 (Dropout) (None, 64) 0
dense_1 (Dense) (None, 10) 650
softmax (Softmax) (None, 10) 0
=================================================================
Total params: 24,842
Trainable params: 24,682
Non-trainable params: 160
_________________________________________________________________
Epoch 1/2
938/938 - 34s - loss: 0.4986 - accuracy: 0.8403 - val_loss: 0.1026 - val_accuracy: 0.9694 - 34s/epoch - 37ms/step
Epoch 2/2
938/938 - 35s - loss: 0.1783 - accuracy: 0.9449 - val_loss: 0.0737 - val_accuracy: 0.9766 - 35s/epoch - 37ms/step
binary test file generated: test_data.bin
test data length: 1000
32/32 - 0s - loss: 0.0862 - accuracy: 0.9710 - 341ms/epoch - 11ms/step
Test loss: 0.0861600786447525
Top 1: 0.9710000157356262
32/32 [==============================] - 0s 5ms/step
[[ 84 0 0 0 0 0 1 0 0 0]
[ 0 125 0 0 0 0 0 0 1 0]
[ 0 1 110 0 0 0 1 2 2 0]
[ 0 0 0 102 0 3 0 1 1 0]
[ 0 1 0 0 105 0 2 0 0 2]
[ 0 0 0 0 0 85 0 0 1 1]
[ 3 0 0 0 0 0 84 0 0 0]
[ 0 0 0 1 1 1 0 96 0 0]
[ 0 0 1 0 0 0 0 0 87 1]
[ 0 0 0 0 1 0 0 0 0 93]]
input_1 Quantized method: max-min Values max: 1.0 min: 0.0 dec bit 7
32/32 [==============================] - 0s 1ms/step
conv2d Quantized method: max-min Values max: 0.77834666 min: -0.6643031 dec bit 7
32/32 [==============================] - 0s 2ms/step
batch_normalization Quantized method: max-min Values max: 6.892522 min: -5.467197 dec bit 4
32/32 [==============================] - 0s 4ms/step
conv2d_1 Quantized method: max-min Values max: 17.596895 min: -27.735723 dec bit 2
32/32 [==============================] - 0s 4ms/step
batch_normalization_1 Quantized method: max-min Values max: 3.2113974 min: -3.7283127 dec bit 5
leaky_re_lu Quantized method: max-min Values max: 3.2113974 min: -3.7283127 dec bit 5
max_pooling2d Quantized method: max-min Values max: 3.2113974 min: -3.7283127 dec bit 5
dropout Quantized method: max-min Values max: 3.2113974 min: -3.7283127 dec bit 5
32/32 [==============================] - 0s 4ms/step
depthwise_conv2d Quantized method: max-min Values max: 1.3406438 min: -1.0324882 dec bit 6
32/32 [==============================] - 0s 4ms/step
batch_normalization_2 Quantized method: max-min Values max: 5.8297634 min: -5.458767 dec bit 4
re_lu Quantized method: max-min Values max: 5.8297634 min: -5.458767 dec bit 4
dropout_1 Quantized method: max-min Values max: 5.8297634 min: -5.458767 dec bit 4
32/32 [==============================] - 0s 4ms/step
conv2d_2 Quantized method: max-min Values max: 5.3312216 min: -4.18351 dec bit 4
32/32 [==============================] - 0s 4ms/step
batch_normalization_3 Quantized method: max-min Values max: 5.1313715 min: -4.3312516 dec bit 4
re_lu_1 Quantized method: max-min Values max: 5.1313715 min: -4.3312516 dec bit 4
max_pooling2d_1 Quantized method: max-min Values max: 5.1313715 min: -4.3312516 dec bit 4
dropout_2 Quantized method: max-min Values max: 5.1313715 min: -4.3312516 dec bit 4
flatten Quantized method: max-min Values max: 5.1313715 min: -4.3312516 dec bit 4
32/32 [==============================] - 0s 5ms/step
dense Quantized method: max-min Values max: 9.411628 min: -11.911018 dec bit 3
re_lu_2 Quantized method: max-min Values max: 9.411628 min: -11.911018 dec bit 3
dropout_3 Quantized method: max-min Values max: 9.411628 min: -11.911018 dec bit 3
32/32 [==============================] - 0s 4ms/step
dense_1 Quantized method: max-min Values max: 15.168733 min: -14.624195 dec bit 3
32/32 [==============================] - 0s 5ms/step
softmax Quantized method: max-min Values max: 0.9999963 min: 5.881822e-13 dec bit 7
quantisation list {'input_1': [7, 0], 'conv2d': [4, 0], 'batch_normalization': [4, 0], 'conv2d_1': [5, 0], 'batch_normalization_1': [5, 0], 'leaky_re_lu': [5, 0], 'max_pooling2d': [5, 0], 'dropout': [5, 0], 'depthwise_conv2d': [4, 0], 'batch_normalization_2': [4, 0], 're_lu': [4, 0], 'dropout_1': [4, 0], 'conv2d_2': [4, 0], 'batch_normalization_3': [4, 0], 're_lu_1': [4, 0], 'max_pooling2d_1': [4, 0], 'dropout_2': [4, 0], 'flatten': [4, 0], 'dense': [3, 0], 're_lu_2': [3, 0], 'dropout_3': [3, 0], 'dense_1': [3, 0], 'softmax': [7, 0]}
fusing batch normalization to conv2d
original weight max 0.2235549 min -0.24778879
original bias max 0.043418616 min -0.06542501
fused weight max 2.9589512 min -2.8448143
fused bias max 0.5293808 min -0.5222879
quantizing weights for layer conv2d
tensor_conv2d_kernel_0 dec bit 5
tensor_conv2d_bias_0 dec bit 7
quantizing weights for layer batch_normalization
fusing batch normalization to conv2d_1
original weight max 0.19423744 min -0.24259652
original bias max 0.013735103 min -0.012081833
fused weight max 0.03725449 min -0.036782067
fused bias max -0.11885923 min -0.42289153
quantizing weights for layer conv2d_1
tensor_conv2d_1_kernel_0 dec bit 11
tensor_conv2d_1_bias_0 dec bit 8
quantizing weights for layer batch_normalization_1
fusing batch normalization to depthwise_conv2d
original weight max 0.2989247 min -0.33221692
original bias max 0.031672217 min -0.09777981
fused weight max 4.2178764 min -2.2269676
fused bias max 0.611039 min -0.9544384
quantizing weights for layer depthwise_conv2d
tensor_depthwise_conv2d_depthwise_kernel_0 dec bit 4
tensor_depthwise_conv2d_bias_0 dec bit 7
quantizing weights for layer batch_normalization_2
fusing batch normalization to conv2d_2
original weight max 0.57738096 min -0.52470607
original bias max 0.0042722966 min -0.012099096
fused weight max 0.55349463 min -0.5876506
fused bias max 0.6647942 min -0.7078786
quantizing weights for layer conv2d_2
tensor_conv2d_2_kernel_0 dec bit 7
tensor_conv2d_2_bias_0 dec bit 7
quantizing weights for layer batch_normalization_3
quantizing weights for layer dense
tensor_dense_kernel_0 dec bit 8
tensor_dense_bias_0 dec bit 10
quantizing weights for layer dense_1
tensor_dense_1_kernel_0 dec bit 8
tensor_dense_1_bias_0 dec bit 10
scons: Reading SConscript files ...
scons: done reading SConscript files.
scons: Building targets ...
CC main.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
main.c
CC E:\nnom\nnom\src\core\nnom.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom.c
CC E:\nnom\nnom\src\core\nnom_layers.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_layers.c
CC E:\nnom\nnom\src\core\nnom_tensor.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_tensor.c
CC E:\nnom\nnom\src\core\nnom_utils.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_utils.c
CC E:\nnom\nnom\src\layers\nnom_activation.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_activation.c
CC E:\nnom\nnom\src\layers\nnom_avgpool.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_avgpool.c
CC E:\nnom\nnom\src\layers\nnom_baselayer.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_baselayer.c
CC E:\nnom\nnom\src\layers\nnom_concat.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_concat.c
CC E:\nnom\nnom\src\layers\nnom_conv2d.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_conv2d.c
CC E:\nnom\nnom\src\layers\nnom_conv2d_trans.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_conv2d_trans.c
CC E:\nnom\nnom\src\layers\nnom_cropping.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_cropping.c
CC E:\nnom\nnom\src\layers\nnom_dense.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_dense.c
CC E:\nnom\nnom\src\layers\nnom_dw_conv2d.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_dw_conv2d.c
CC E:\nnom\nnom\src\layers\nnom_flatten.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_flatten.c
CC E:\nnom\nnom\src\layers\nnom_global_pool.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_global_pool.c
CC E:\nnom\nnom\src\layers\nnom_gru_cell.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_gru_cell.c
CC E:\nnom\nnom\src\layers\nnom_input.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_input.c
CC E:\nnom\nnom\src\layers\nnom_lambda.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_lambda.c
CC E:\nnom\nnom\src\layers\nnom_lstm_cell.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_lstm_cell.c
CC E:\nnom\nnom\src\layers\nnom_matrix.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_matrix.c
CC E:\nnom\nnom\src\layers\nnom_maxpool.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_maxpool.c
CC E:\nnom\nnom\src\layers\nnom_output.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_output.c
CC E:\nnom\nnom\src\layers\nnom_reshape.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_reshape.c
CC E:\nnom\nnom\src\layers\nnom_rnn.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_rnn.c
CC E:\nnom\nnom\src\layers\nnom_simple_cell.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_simple_cell.c
CC E:\nnom\nnom\src\layers\nnom_softmax.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_softmax.c
CC E:\nnom\nnom\src\layers\nnom_sumpool.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_sumpool.c
CC E:\nnom\nnom\src\layers\nnom_upsample.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_upsample.c
CC E:\nnom\nnom\src\layers\nnom_zero_padding.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_zero_padding.c
CC E:\nnom\nnom\src\backends\nnom_local.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_local.c
CC E:\nnom\nnom\src\backends\nnom_local_q15.c
cl: 命令行 warning D9002 :忽略未知选项“-std=c99”
nnom_local_q15.c
LINK mnist.exe
scons: done building targets.
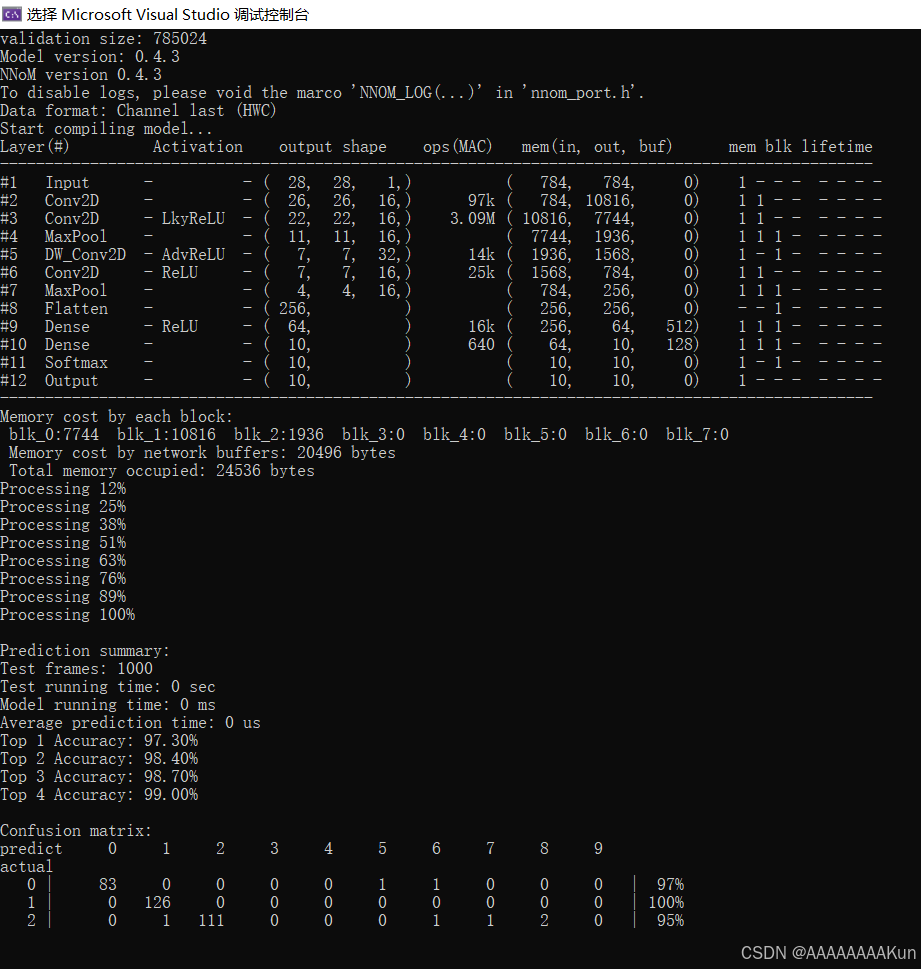
validation size: 785024
Model version: 0.4.3
NNoM version 0.4.3
To disable logs, please void the marco 'NNOM_LOG(...)' in 'nnom_port.h'.
Data format: Channel last (HWC)
Start compiling model...
Layer(#) Activation output shape ops(MAC) mem(in, out, buf) mem blk lifetime
-------------------------------------------------------------------------------------------------
#1 Input - - ( 28, 28, 1,) ( 784, 784, 0) 1 - - - - - - -
#2 Conv2D - - ( 26, 26, 16,) 97k ( 784, 10816, 0) 1 1 - - - - - -
#3 Conv2D - LkyReLU - ( 22, 22, 16,) 3.09M ( 10816, 7744, 0) 1 1 - - - - - -
#4 MaxPool - - ( 11, 11, 16,) ( 7744, 1936, 0) 1 1 1 - - - - -
#5 DW_Conv2D - AdvReLU - ( 7, 7, 32,) 14k ( 1936, 1568, 0) 1 - 1 - - - - -
#6 Conv2D - ReLU - ( 7, 7, 16,) 25k ( 1568, 784, 0) 1 1 - - - - - -
#7 MaxPool - - ( 4, 4, 16,) ( 784, 256, 0) 1 1 1 - - - - -
#8 Flatten - - ( 256, ) ( 256, 256, 0) - - 1 - - - - -
#9 Dense - ReLU - ( 64, ) 16k ( 256, 64, 512) 1 1 1 - - - - -
#10 Dense - - ( 10, ) 640 ( 64, 10, 128) 1 1 1 - - - - -
#11 Softmax - - ( 10, ) ( 10, 10, 0) 1 - 1 - - - - -
#12 Output - - ( 10, ) ( 10, 10, 0) 1 - - - - - - -
-------------------------------------------------------------------------------------------------
Memory cost by each block:
blk_0:7744 blk_1:10816 blk_2:1936 blk_3:0 blk_4:0 blk_5:0 blk_6:0 blk_7:0
Memory cost by network buffers: 20496 bytes
Total memory occupied: 24536 bytes
Processing 12%
Processing 25%
Processing 38%
Processing 51%
Processing 63%
Processing 76%
Processing 89%
Processing 100%
Prediction summary:
Test frames: 1000
Test running time: 0 sec
Model running time: 0 ms
Average prediction time: 0 us
Top 1 Accuracy: 97.30%
Top 2 Accuracy: 98.40%
Top 3 Accuracy: 98.70%
Top 4 Accuracy: 99.00%
Confusion matrix:
predict 0 1 2 3 4 5 6 7 8 9
actual
0 | 83 0 0 0 0 1 1 0 0 0 | 97%
1 | 0 126 0 0 0 0 0 0 0 0 | 100%
2 | 0 1 111 0 0 0 1 1 2 0 | 95%
3 | 0 0 0 104 0 3 0 0 0 0 | 97%
4 | 0 1 0 0 105 0 2 0 0 2 | 95%
5 | 0 0 0 0 0 86 0 0 1 0 | 98%
6 | 3 0 0 0 0 0 84 0 0 0 | 96%
7 | 0 0 1 1 1 1 0 95 0 0 | 95%
8 | 0 0 1 0 0 1 0 0 86 1 | 96%
9 | 0 0 0 0 0 0 0 1 0 93 | 98%
Print running stat..
Layer(#) - Time(us) ops(MACs) ops/us
--------------------------------------------------------
#1 Input - 0
#2 Conv2D - 0 97k
#3 Conv2D - 0 3.09M
#4 MaxPool - 0
#5 DW_Conv2D - 0 14k
#6 Conv2D - 0 25k
#7 MaxPool - 0
#8 Flatten - 0
#9 Dense - 0 16k
#10 Dense - 0 640
#11 Softmax - 0
#12 Output - 0
Summary:
Total ops (MAC): 3251168(3.25M)
Prediction time :0us
Total memory:24536
Top 1 Accuracy on Keras 97.10%
Top 1 Accuracy on NNoM 97.30%二、用VS纯C语言跑模型
1.创建c工程
用VS创建工程文件夹,把如下源代码的部分文件移动到工程文件夹下,如下所示:
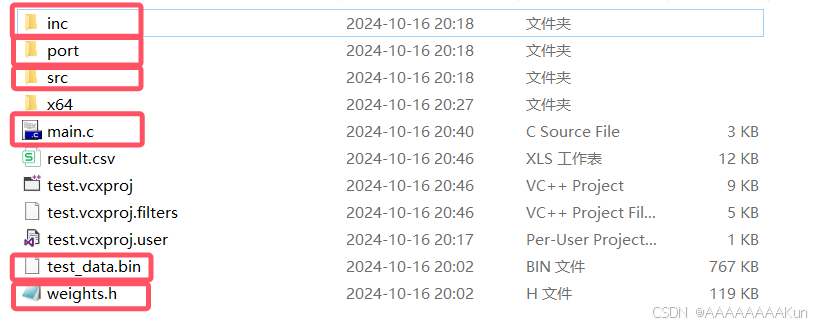
2.添加文件到项目中
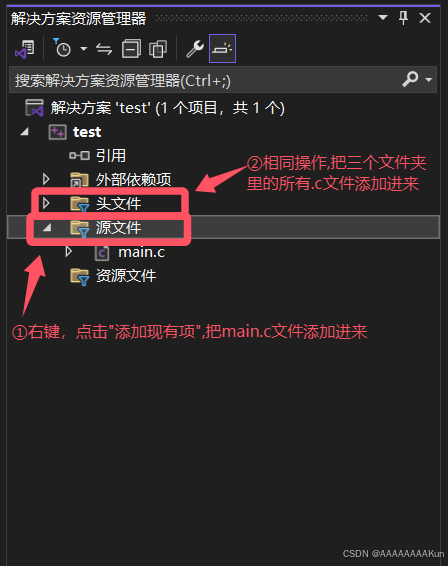
3.修改main.c代码
因为项目比较老,使用fopen函数时会提示不安全,因此需要屏蔽掉此警告,所以在第十行添加如下代码:
#define _CRT_SECURE_NO_WARNINGS4.编译,运行
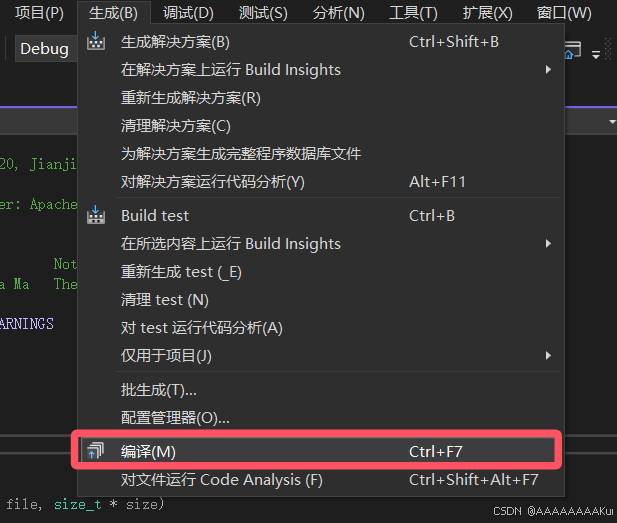
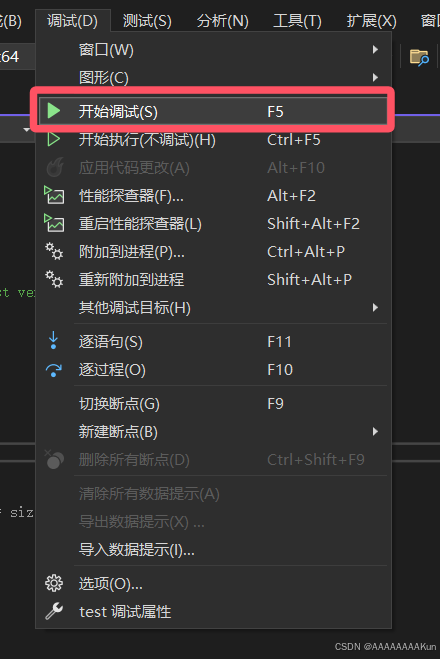
5.运行结果如下

















 7953
7953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









