







这里总结一下刷sql题遇到的那些一开始思路不是很清晰的题目以及八股文,方便复习,要保证看到相同的题目一眼出思路。
目录
SQL八股
1.SQL执行顺序
from->on->join->where->group by(开始使用select中的别名,后面的语句中都可以使用别名)->sum、count、max、avg->having->select->distinct->order by->limit
- FROM:选择FROM后面跟的表,产生虚拟表1。
- ON:ON是JOIN的连接条件,符合连接条件的行会被记录在虚拟表2中。
- JOIN:如果指定了LEFT JOIN,那么保留表中未匹配的行就会作为外部行添加到虚拟表2中,产生虚拟表3。如果有多个JOIN链接,会重复执行步骤1~3,直到处理完所有表。
- WHERE:对虚拟表3进行WHERE条件过滤,符合条件的记录会被插入到虚拟表4中。
- GROUP BY:根据GROUP BY子句中的列,对虚拟表4中的记录进行分组操作,产生虚拟表5。
- AGG_FUNC:常用的 Aggregate 函数(聚合函数)包涵以下几种:(AVG:返回平均值)、(COUNT:返回行数)、(FIRST:返回第一个记录的值)、(LAST:返回最后一个记录的值)、(MAX: 返回最大值)、(MIN:返回最小值)、(SUM: 返回总和)。
- WITH 对虚拟表5应用ROLLUP或CUBE选项,生成虚拟表 6。
- HAVING:对虚拟表6进行HAVING过滤,符合条件的记录会被插入到虚拟表7中。
- SELECT:SELECT到一步才执行,选择指定的列,插入到虚拟表8中。
- UNION:UNION连接的两个SELECT查询语句,会重复执行步骤1~9,产生两个虚拟表9,UNION会将这些记录合并到虚拟表10中。
- DISTINCT 将重复的行从虚拟表10中移除,产生虚拟表 11。DISTINCT用来删除重复行,只保留唯一的。
- ORDER BY: 将虚拟表11中的记录进行排序,虚拟表12。
- LIMIT:取出指定行的记录,返回结果集。
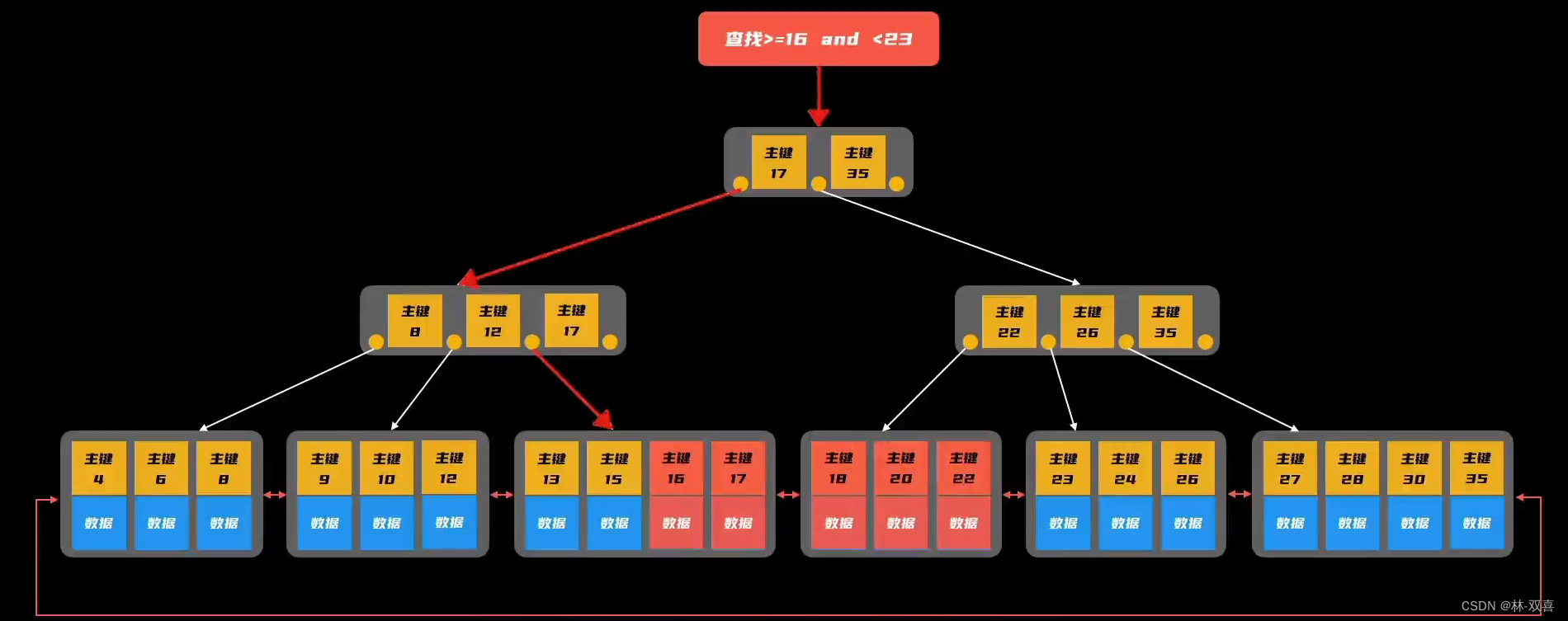
2.Mysql B+树索引
作用:解决查询问题,提高查询速度,避免全表扫描。
数据结构:B+树,B+树是B树的升级版,每个节点中存储着多个元素、有多个分叉;数据都存放在最底层的叶子节点上,非叶子节点只存储键值;叶子节点之间使用双向指针连接,即最底层的叶子节点形成了一个双向有序链表。
优点:
- 普通的二叉树(二分查找),随着数据的不断插入,容易发生倾斜,导致树的高度太高,极端情况下就成了链表,查询效率低。
- 红黑树(平衡二叉树),虽然解决了数据不平衡的问题,但是每个节点只保存一个元素,而B+树每个节点中存储着多个元素,降低了树的高度,减小了磁盘IO的次数。(查询时,每一层分层都要读取一次磁盘数据)
- B树,虽然B树每个节点保存了多个数据,但是数据散落在不同的节点上,很难进行范围查找,而B+树更利于范围查询,因为底层的叶子节点形成了一个双向有序链表,只需要查找到范围最左边的数,根据偏移量就可以进行范围查询。
3.索引失效
- 最左匹配原则:查询数据时从联合索引的最左边开始匹配,例如联合索引(a,b,c),只有查询(a),(a,b),(a,b,c)会走索引,而(b),(b,c),(c)都不会走索引。
例如:name和phone为联合索引,id为主键索引
那么对phong进行查询时不会使用索引,对name/name+phone查询时会使用索引。
select id,name,phone from User where phone='110'; #不使用索引 select id,name,phone from User where phone='110' and name='警察';#使用索引 - 反向查询:反向查询无法使用索引,可能会导致全表扫描,例如:
select * from User where name!='警察'; - 对索引列做任何操作:数值计算、使用函数、类型转换等操作无法使用索引,例如:
select * from User where left(name,2)='警察'; select * from User where id+1 = 15; - or查询:or之前的条件列是索引列,or之后的条件列不是索引列,则不会使用索引,例如:
select * from User where id=10 or gender=0; #gender不是索引列
4.SQL优化
优化方向:较少数据扫描、返回更少数据、较少交互次数、较少服务器cpu内存开销
(1) 避免使用select *
- 查询时需要先将*解析成表的所有字段再查询,增加了查询解析器的。
- select *查询一般不走覆盖索引优化,会产生大量的回表查询。
- 查询不需要的字段也会浪费CPU内存资源。
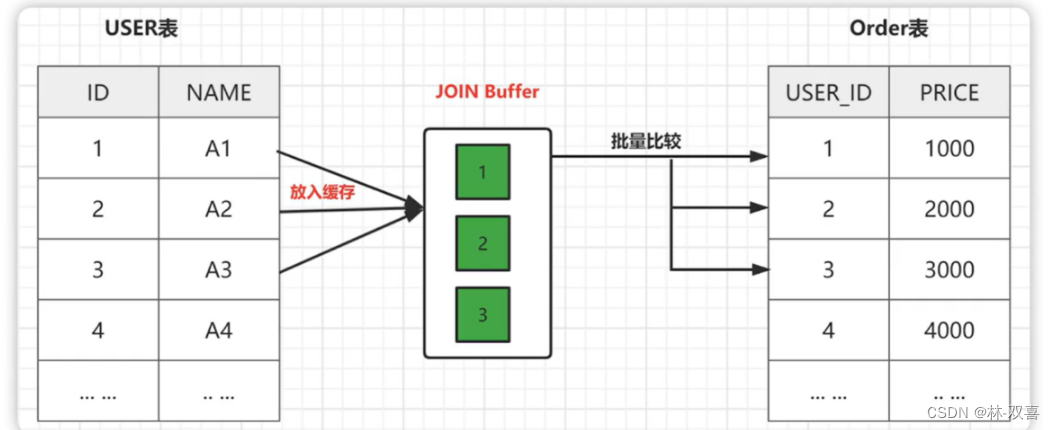
(2) join的优化
- 在表中冗余关联字段来减少表的连接
- 小表驱动大表:select ... from 小表 join 大表
小表指数据量较小、索引比较完备的表,使用小表的索引和条件对大表进行数据筛选,从而减少数据计算量,提高查询效率。
- 为被驱动表关联字段建立索引
- 增大 join buffer 的大小(一次缓存的数据越多,那么扫表次数就越少)
(3) 某些场景下使用连接查询join代替子查询in
对于大型的数据集,使用连接查询反而比子查询更高效,子查询通常需要扫描整个表并且多次执行数据库查询(外部查询和嵌套子查询),连接查询可以减少数据库查询次数,同时还可以利用索引加速读取操作,提高查询性能。
(4) 提升group by的效率
如果group by的列没有索引,那么查询可能会变得很慢,因此可以创建一个或多个适当索引来加速查询。
(5) 批量操作
批量插入/删除数据,因为逐个处理会频繁的与数据库交互,损耗性能,批量操作只需要远程请求一次数据集。
(6) 使用limit
- 避免过度提取数据:一个查询返回大量数据时会占用大量资源,使用limit限制返回的数据行数,可以减轻系统负担,避免过度提取数据,提高查询效率。
- 优化分页查询:分页查询使用limit优化,只查询需要的数据行,缩短查询时间,减少资源浪费。
- 简化查询结果:当只需要一小部分数据来得出决策,查看数据内容,使用limit可以使查询结果更加精简,同时提高查询效率。
(7) limit优化
问题:limit 查询使会从第一行开始找偏移量,所以越往后查询越慢
优化:利用自增索引,比如想要limit 10000,10(查询第10000行开始的10条数据)
-----> where (id>=10000) limit 10
(8) 用union all代替union
- union all:合并所有数据,包含重复数据
- union:合并所有数据且去重,不包含重复数据
union去重操作,需要遍历、排序、比较,耗时、消耗cpu资源。
5.事务特性
数据库事务:包含一组相关的SQL语句,它们在业务逻辑上组成一个原子单元。
事务特性:
- 原子性:事务中的操作要么全部成功,要么全部失败
- 一致性:事务开始前后数据库都要位于一致性的状态,
- 隔离性:多个并发事务之间相互隔离,有4种隔离级别
- 持久性:提交的事务必须永久生效,即使发生断电、系统崩溃等故障也不会丢失数据。
-----------------------
SQL题目
1.连续N天登录
以下是用户登录游戏的日期,查询连续三天登录的用户
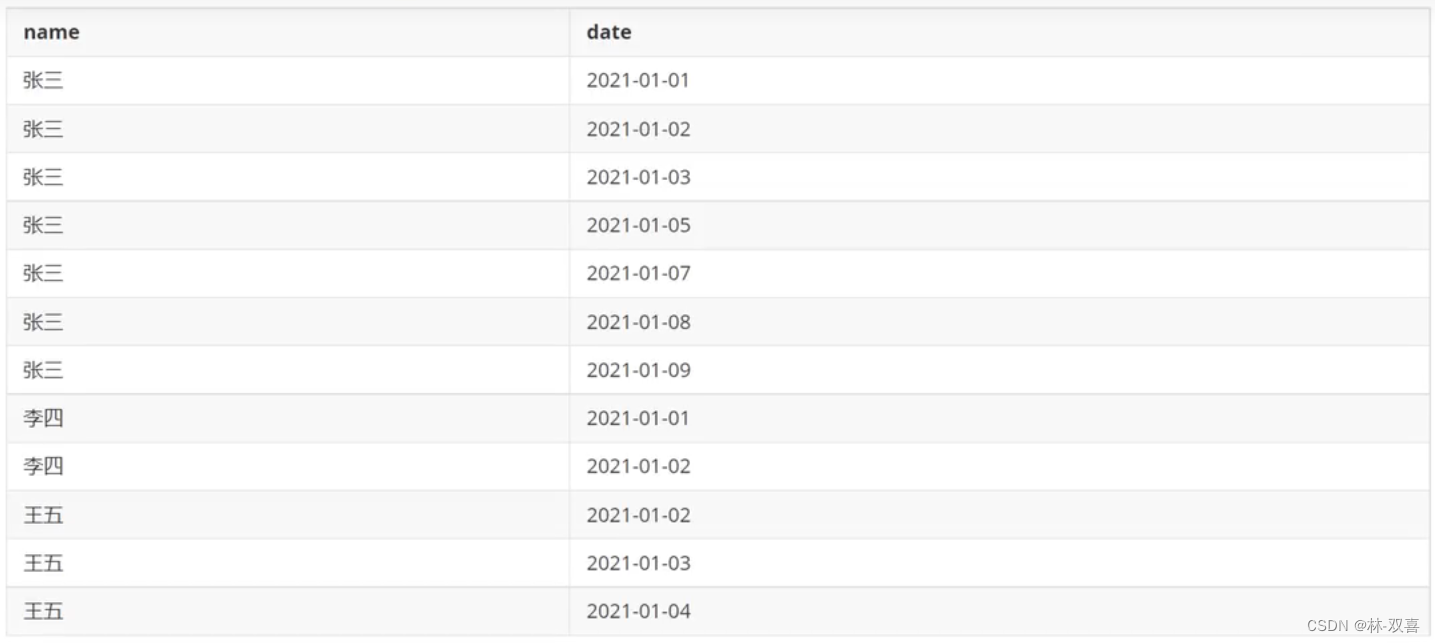
思路:以为用户作为分组,对分组内日期进行排序,排序后用日期减去排序的值,如果相同表示连续登录,重新分组后count即可。
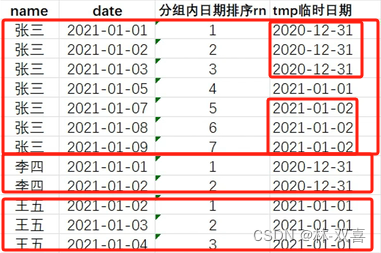
1.分组排序
select name,date,
row_number() over (partition by name order by data) rn
from game2.日期减去排序
select *,date_sub(date,interval rn day) tmp
from(
select name,date,
row_number() over (partition by name order by data) rn
from game
)t13.统计连续登录人数
记得去重,因为不只是按照name排序,还按照tmp排序,可能有多个用户
select distinct name
from(
select *,date_sum(date-rn) tmp
from(
select name,date,
row_number() over (partition by name order by data) rn
from game
)t1
)t2
group by name,tmp
having count(*)>=32.变化数据查指定日期
编写一个解决方案,找出在 2019-08-16 时全部产品的价格,假设所有产品在修改前的价格都是 10。
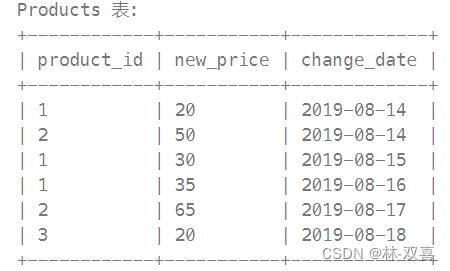
思路:先用找出2019-08-16时各商品价格,同时找出所有商品id,left join商品价格,保证商品不丢,然后对于nul的商品价格输出10。
1.找出2019-08-16时各商品价格
select product_id,new_price from Products
where (product_id,change_date) in (
select product_id,max(change_date) from Products
where change_date <='2019-08-16'
group by product_id)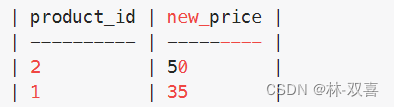
2.找出所有商品id,left join商品价格
select * from
(select distinct product_id from Products
) t1 #所有商品id
left join
(select product_id,new_price from Products
where (product_id,change_date) in (
select product_id,max(change_date) from Products
where change_date <='2019-08-16'
group by product_id)
)t2 #找出当日各商品价格
on t1.product_id=t2.product_id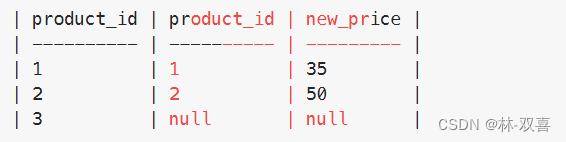
3.对于nul的商品价格输出10
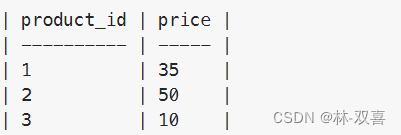
select t1.product_id,ifnull(t2.new_price,10) price from
(select distinct product_id from Products
) t1 #所有商品id
left join
(select product_id,new_price from Products
where (product_id,change_date) in (
select product_id,max(change_date) from Products
where change_date <='2019-08-16'
group by product_id)
)t2 #找出当日各商品价格
on t1.product_id=t2.product_id3.累加开窗函数
有一队乘客按照turn的顺序上大巴,大巴限重1000kg,求最后一个上大巴的乘客。
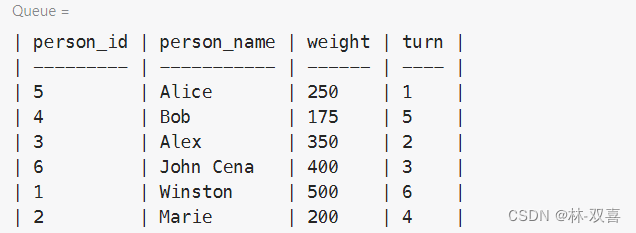
思路:使用累加开窗函数,通过筛选条件求最后一个上大巴的乘客。
1.使用开窗函数,按照turn进行排序,累加计算weight
select person_name, turn,
weight ,sum(weight) over(order by turn) as total
from Queue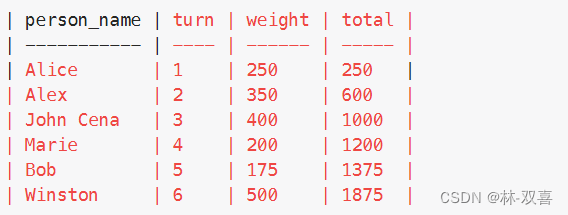
2.筛选出最后一个上大巴的乘客
select person_name from
(
select person_name, turn, weight ,sum(weight) over(order by turn) as total from Queue
) t
where total<=1000
order by total desc
limit 1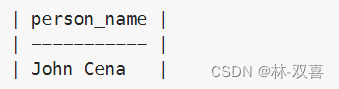
4.关于NULL
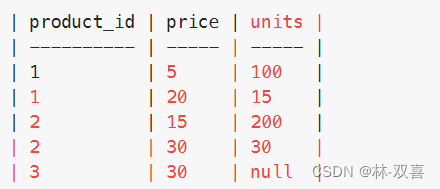
- 按照product_id分组,计算count(units)
--->count(*) 不会计入null值,如果都是null,输出0
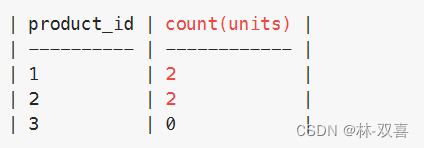
- 按照product_id分组,计算sum(units)
--->sum(*) 如果都是null,输出null,而不是0
--->想要输出0,ifnull(sum(*) ,0)
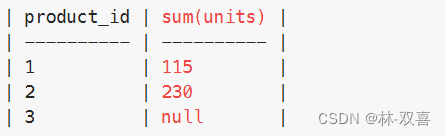
5.布尔运算的sum和count
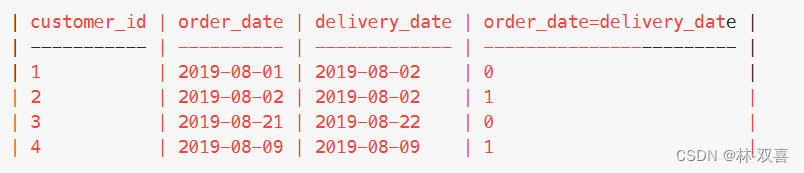
计算order_date=delivery_date 的数量
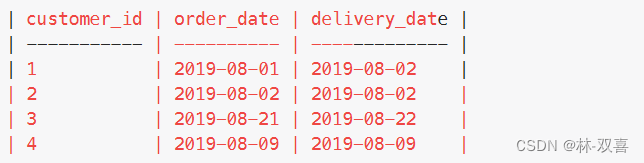
使用count(order_date=customer_pref_delivery_date),结果是4
使用sum(order_date=customer_pref_delivery_date),结果是2
分析:
order_date=customer_pref_delivery_date 等号成立时为1,不成立为0
count(*),只计算非null的数量,对于0和1都是当做一个数值,所以结果是4
sum(*),计算数值相加,0+1+0+1=2,所以结果是2
6.计算比率/占比
首次登录的第二天再次登录的玩家的比率
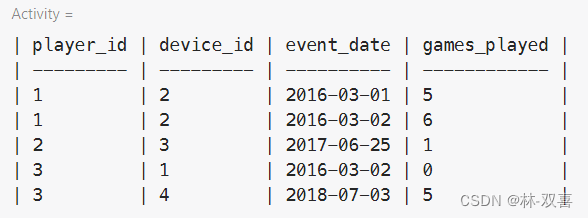
思路:用全部玩家首次登录表 left join 第二天再次登录的玩家表,那么第二天没有登录的玩家就是null了,通过count(表二)/count(表一)可以算出比率
1.全部玩家首次登录表
select player_id,min(event_date) login from Activity group by player_id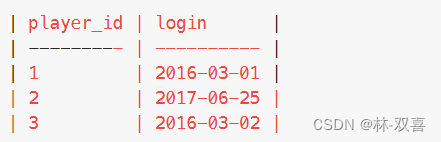
2.left join第二天的登录的玩家
select * from
(select player_id,min(event_date) login from Activity group by player_id) a
left join Activity b
on a.player_id=b.player_id and datediff(b.event_date,a.login)=1
3.计算比率
select round(count(b.event_date)/count(*),2) fraction from
(select player_id,min(event_date) login from Activity group by player_id) a
left join Activity b
on a.player_id=b.player_id and datediff(b.event_date,a.login)=17.筛选统计获得新表
按照收入进行分类:
- "Low Salary": 收入低于 20000 美元
- "Average Salary": 收入范围在 [$20000, $50000]
- "High Salary": 收入大于 50000 美元
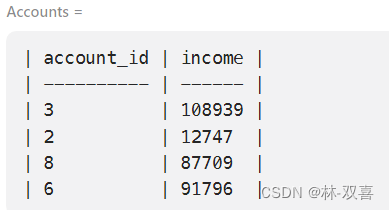
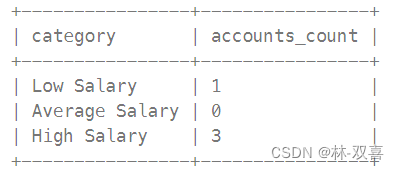
思路:创建三张表(三行数据)union起来,通过select "..." 创建新数据条
SELECT "Low Salary" category,sum(if(income<20000,1,0)) accounts_count FROM Accounts
union
SELECT "Average Salary",sum(if(income<=50000 and income>=20000,1,0)) FROM Accounts
union
SELECT "High Salary",sum(if(income>50000,1,0)) FROM Accounts8.偏移开窗函数
- lag(字段名,偏移量[,默认值])over() 向上偏移
- lead(字段名,偏移量[,默认值])over() 向下偏移
交换每两个连续的学生的座位号,如果学生的数量是奇数,则最后一个学生的id不交换。

思路:使用偏移开窗函数,获取每行数据的上下数据,按照奇偶进行筛选。
1.偏移开窗函数,获取每行数据的上下数据
(设置默认值,第一行数据的上一行和最后一行数据的下一行都取他本身)
SELECT id , student ,
lag(student,1,student) over(order by id) last,
lead(student,1,student) over(order by id) next
FROM seat
3.按照奇偶进行筛选
select id,if(id%2=0,last,next) student
from(
SELECT id , student ,
lag(student,1,student) over(order by id) last,
lead(student,1,student) over(order by id) next
FROM seat
)t
9.近七日消费总额(滑动窗口)
rows n perceding #从当前行到前n行(一共n+1行)
rows n following #从当前行到后n行(一共n+1行)
rows between 2 perceding and 2 following #当前行往前2行+当前行+当前行往后2行(一共5行)
rows between 1 following 3 following #当前行的后1——>后3(共3行)
rows between unbounded preceding and current row #从第一行到当前行
rang/rows between 边界规则1 and 边界规则2 #rang表示按照值的范围进行定义框架,rows表示按照行的范围进行定义框架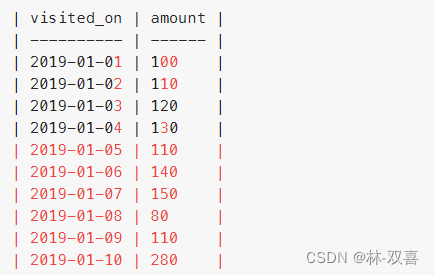
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费总值。
rows 6 preceding 表示前6行+当行
select visited_on,
sum(amount) over (partition by visited_on order by visited_on rows 6 preceding) 7_amount
from Customer

计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。
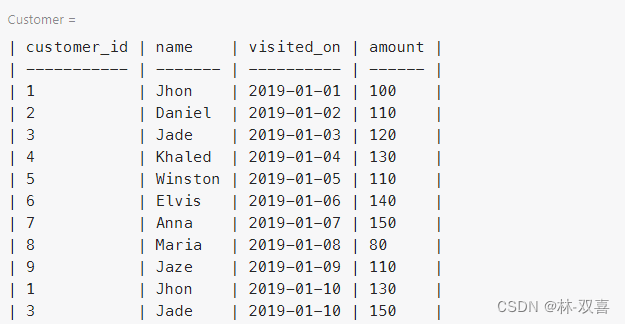
思路:使用滑动窗口,计算每个窗口(7天)的营业总额,再筛选出满足7营业7天的日期,计算平均值。
1.滑动窗口,计算每个窗口(7天)的营业总额
range interval 6 days preceding 表示按照日期前6天+当天
SELECT visited_on,
SUM(amount) OVER (ORDER BY visited_on RANGE interval 6 day preceding) AS amount
FROM Customer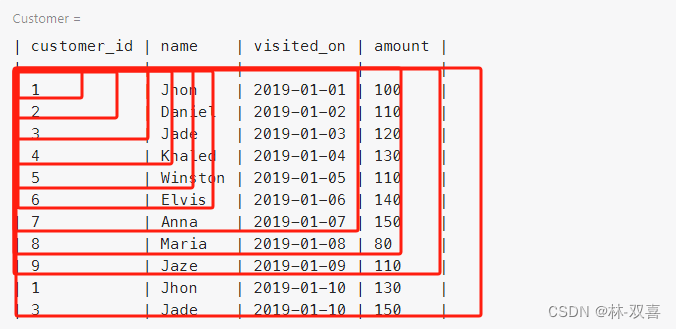
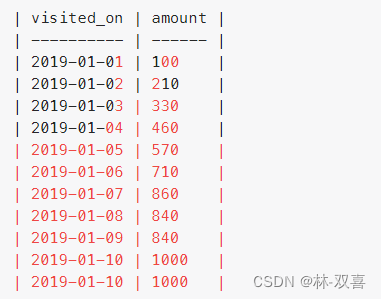
2.计算营业额均值
select visited_on,amount,round(amount/7,2) average_amount from
(
SELECT visited_on, SUM(amount) OVER (ORDER BY visited_on RANGE interval 6 day preceding) AS amount
FROM Customer
)t
where datediff(visited_on, (SELECT MIN(visited_on) FROM Customer) )>=6
group by visited_on,amount10.行列转换
行转列
思路:通过case when或if函数,获取根据列1筛选列2,同时通过分组聚合获得所需数据。
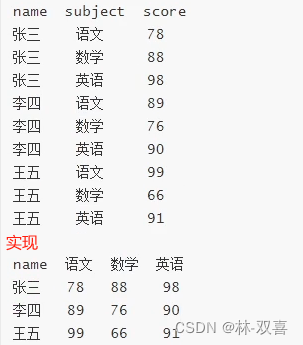
#方法一
select name,
sum(if(subject='语文',score ,0)) as '语文',
sum(if(subject='数学',score ,0)) as '数学',
sum(if(subject='英语',score ,0)) as '英语',
from Score group by name
#方法二
select name,
sum(case subject when '语文' then score else 0 end)) as '语文',
sum(case subject when '数学' then score else 0 end)) as '数学',
sum(case subject when '英语' then score else 0 end)) as '英语',
from Score group by name
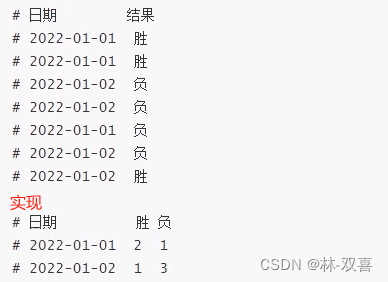
#方法一
select date,
sum(if(result='胜',1,0)) as '胜',
count(if(result='负',1,null)) as '负'
from Result group by date
#方法二
select date,
sum(case result when '胜' then 1 else 0 end)) as '胜',
count(case result when '负' then 1 else null end)) as '负'
from Result group by date列转行
思路:通过select将列每列字段转为行,然后union,排序
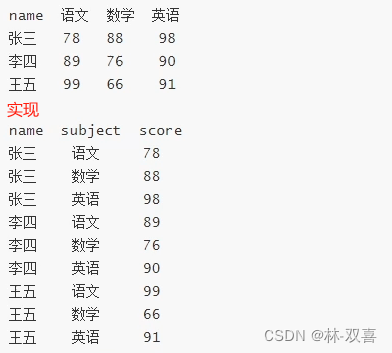
select name,'语文' as subject,语文 as score from Score2
union all
select name,'数学' as subject,数学 as score from Score2
union all
select name,'英语' as subject,英语 as score from Score2
order by name; 
select 'Q1' as 季度,Q1 as 业绩 from table
union all
select 'Q2' as 季度,Q2 as 业绩 from table
union all
select 'Q3' as 季度,Q3 as 业绩 from table
order by 季度;总结:
- 扩展列:select ... as 新列名
- 扩展行:union/union all
- 减少列:不select
- 减少行:聚合哈数
11.计算最大在线人数
统计每篇文章同一时刻最大在看人数,如果同一时刻有进入也有离开时,先记录用户数增加再记录减少,结果按最大人数降序。
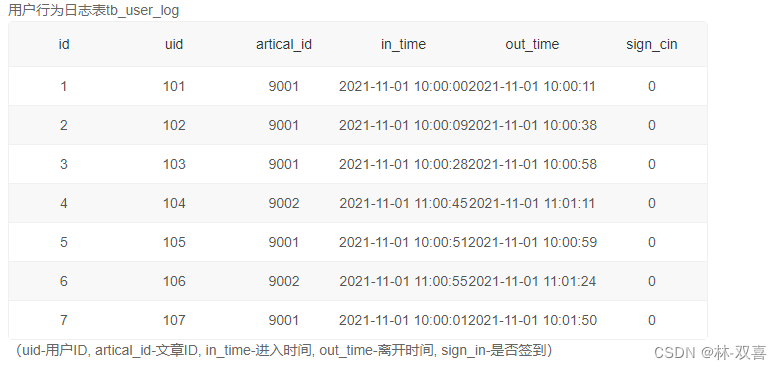 思路:将in_time和out_time放在一列,in_time则+1表示观看人数+1,out_time则-1表示观看人数1,然后通过窗口累加函数计算每个时间点同时在线人数,取最大值
思路:将in_time和out_time放在一列,in_time则+1表示观看人数+1,out_time则-1表示观看人数1,然后通过窗口累加函数计算每个时间点同时在线人数,取最大值
1.将in_time和out_time放在一列,并打上标签
select uid,artical_id,in_time dt,1 flag
from tb_user_log
union all
select uid,artical_id,out_time dt,-1 flag
from tb_user_log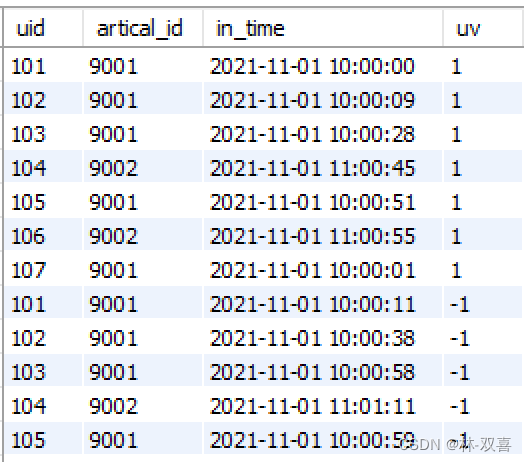
2.窗口累加函数计算每个时间点同时在线人数
select *,sum(flag) over (partition by artical_id order by dt,flag desc) uv
#里面需要按flag降序,先计算当前看的人,再减去不看的人,这样才能保证算出最大在线人数
from(
select uid,artical_id,in_time dt,1 flag
from tb_user_log
union all
select uid,artical_id,out_time dt,-1 flag
from tb_user_log
)t where artical_id!=0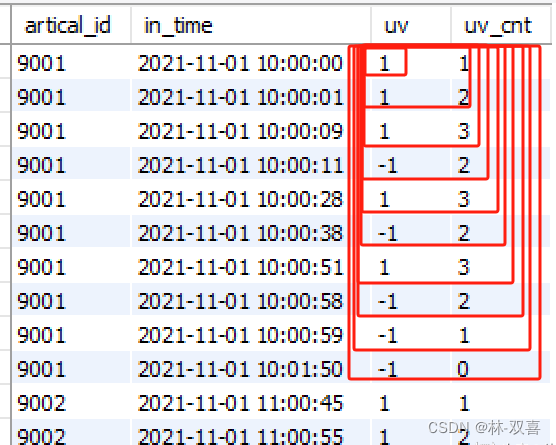
3.按文章分组,取最大值
select artical_id,max(uv) max_uv
from(
select *,sum(flag) over (partition by artical_id order by dt,flag desc) uv
#里面需要按flag降序,先计算当前看的人,再减去不看的人,这样才能保证算出最大在线人数
from(
select uid,artical_id,in_time dt,1 flag
from tb_user_log
union all
select uid,artical_id,out_time dt,-1 flag
from tb_user_log
)t where artical_id!=0
)t2
group by artical_id
order by max_uv desc
12.每日新用户次日留存率

- 统计2021年11月每天新用户的次日留存率(保留2位小数)
- 次日留存率为当天新增的用户数中第二天又活跃了的用户数占比
- 如果in_time-进入时间和out_time-离开时间跨天了,在两天里都记为该用户活跃过,结果按日期升序。
思路:创建用户首次登录表、创建用户在线表
用户首次登录表 left join 用户在线表 on 用户在首次登录后第二天在线
1.用户首次登录表
select uid,min(date(in_time)) dt from tb_user_log group by uid2.用户在线表,包括登录和登出时间(注意要去重,使用union,否则后面left join会计算多次)
select uid,date(in_time) log_time from tb_user_log
union
select uid,date(out_time) log_time from tb_user_log3.用户首次登录表 left join 用户在线表
select dt,
round(count(log_time)/count(*),2) uv_left_rate
from
(select uid,min(date(in_time)) dt from tb_user_log group by uid) a
left join
(select uid,date(in_time) log_time from tb_user_log
union
select uid,date(out_time) log_time from tb_user_log)b
on datediff(b.log_time,a.dt)=1 and a.uid=b.uid
where date_format(dt,'%Y-%m')="2021-11"
group by dt
order by dt13.炸裂函数
| class | students | scores |
| 1班 | 小A,小B,小C | 80,92,70 |
| 2班 | 小D,小E | 88,62 |
| 3班 | 小F,小G,小H | 90,97,85 |
with table as
(
select '1班' as class
,'小A,小B,小C' as name
,'80,92,70' as score
union all
select '2班' as class
,'小D,小E' as name
,'82,73' as score
union all
select '3班' as class
,'小F,小G,小H' as name
,'88,36,100' as score
)
#只对学生列进行炸裂
select class,students,scores
,student_name
from table
lateral view explode(split(student,',')) tmp1 as student_name;
#对学生和成绩都进行炸裂
select class,students,scores
,student_name,student_score
from table
lateral view posexplode(split(student,',')) tmp1 as index1,student_name
lateral vier posexplode(split(score,',')) tmp2 as index2,student_score
where index1=index2; #保证学生姓名和成绩对应14.with rollup
使用 WITH ROLLUP,此函数是对聚合函数进行求和,注意 with rollup是对 group by 后的第一个字段,进行分组求和。
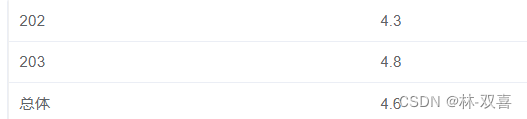
例子:统计司机202和203的平均评分,并计算总体评分,就可以先对司机进行分组聚合得到每个司机的平均评分,然后通过WITH ROLLUP计算总体评分
select driver_id,
round(avg(grade),1) avg_grade
from tb_get_car_order
where driver_id in(
select driver_id
from tb_get_car_order
where date_format(order_time,'%Y-%m')='2021-10'
and start_time is null)
group by driver_id with ROLLUP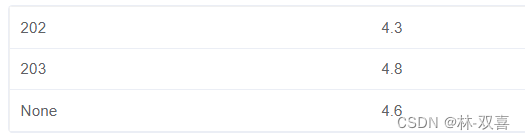
再对null值进行处理
select ifnull(driver_id,'总体'),
round(avg(grade),1) avg_grade
from tb_get_car_order
where driver_id in(
select driver_id
from tb_get_car_order
where date_format(order_time,'%Y-%m')='2021-10'
and start_time is null)
group by driver_id with ROLLUP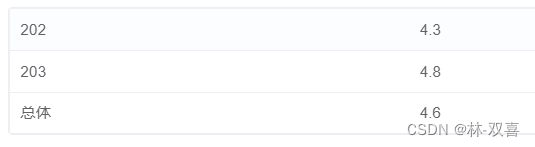
其他常用函数
字符串
日期
date(2021-11-01 10:00:00) = 2021-11-01
总结:时间差不能直接用date1 - date2
删除行
#正确
delete
from Person
where id not in (
select id from (select min(id) id from Person group by email)t
);
#错误
delete
from Person
where id not in (
select min(id) id from Person group by email
);
where中使用聚合函数
一般只能在having中使用聚合函数,不能直接在where中使用
例如:筛选条件是最近一个月,则需要在where中使用max函数获取最近的日期
where datediff((select max(end_time) from tb_video_info),end_time)<30注意:不能直接使用max,而应该从另一一张表中select出来,并且需要加上括号。
MD5
MD5(Message-Digest Algorithm 5)是一种广泛使用的哈希函数,用于生成数据的唯一标识。它将任意长度的数据转换为一个固定长度(128位)的哈希值,通常表示为一个32字符的十六进制字符串。
MD5 的主要特点
-
固定长度输出:无论输入数据的长度如何,MD5 的输出始终是一个128位的哈希值,通常表示为一个32字符的十六进制字符串。
-
唯一性:虽然理论上存在哈希冲突(即不同的输入产生相同的哈希值),但在实际应用中,MD5 能够为不同的输入生成唯一的哈希值。
-
不可逆性:从哈希值无法直接还原出原始数据。
-
快速计算:MD5 的计算速度较快,适合在需要快速生成哈希值的场景中使用。
MD5 的应用场景
-
数据完整性验证:通过比较文件或数据的 MD5 值,可以验证数据在传输或存储过程中是否被篡改。
-
密码存储:虽然 MD5 不再推荐用于密码存储(因为它容易被彩虹表攻击),但在某些旧系统中仍然使用。
-
唯一标识生成:用于生成数据的唯一标识,例如在数据库中生成唯一键。
案例:
数据迁移时,采样SQL计算每行数据的MD5,比较两张表是否一模一样,查询两张表存在差异的数据量。
select count(0) #统计存在差异的数据行
from
(
select *,
md5(concat(
coalesce(cast(account_name as string),'suibian'),
coalesce(cast(user_id as string),'suibian')
-- ...
)) as md5_value #把所有字段concat在一起,再计算md5
from 表1
where p_date ='20240102'
) t
full join
(
select *,
md5(concat(
coalesce(cast(account_name as string),'suibian'),
coalesce(cast(user_id as string),'suibian')
-- ...
)) as md5_value
from 表1
where p_date ='20240102'
) b on t.account_id=b.account_id --唯一主键
where coalesce(t.md5_value,'') != coalesce(b.md5_value,'') #MD5不一样的数据
















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









