







Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
是在MR的基础上进行开发的,使用的是scala语言。
目录
Spark Shuffle 和 Hadoop Shuffle 区别
Spark on Hive 和 Hive on Spark 区别
Spark为什么比MR快
-
Spark基于内存,MR基于磁盘,频繁的磁盘IO会消耗大量的时间。
-
Spark排序不是必须的,MR无论结果是否需要都会进行排序。
-
Spark的任务是以线程的方式运行在进程中的,MR的任务是以进程的方式运行在Yarn集群中的,开启和调度进程的代价大于线程的代价。
Saprk运行流程

-
启动Drive,创建SparkContext
-
Client提交程序给Driver,Driver向集群Master申请资源创建Excutor
-
Master接收请求,分配资源发送给Driver
-
Driver按照资源分配方案连接集群worker,在worker中启动Excutor
-
SparkContext根据RDD算子的依赖创建DAG有向无环图
-
DAG Scheduler将DAG分解成Stage并发送给Task Scheduler
-
Excutor向SparkContext申请Task
-
Task Scheduler将Task发生给Excutor运行,同时SparkContext将应用程序代码发放给Excutor
-
Task 在Excutor上运行,运行完毕释放所有资源
RDD介绍
RDD,Resilient Distributed Dataset 弹性分布式数据集,是Spark中最基本的数据抽象,但是不存放数据。
在代码中是一个抽象类,类似ArrayList类,String类,它代表一个弹性、不可变、可区分、里面元素可以并行计算的集合。
RDD算子包括了:
- transform 算子(划分task):map、flatMap、filter、sample等
常见的转化算子: 1、map:将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换 2、flatmap:将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射,flat-map 3、filer:筛选过滤 4、分区算子 coalesce:用于减少分区,不shuffle repartition:重新分区,shuffle 5、sample:采样 6、distinct:去重 - shuffle算子(触发新的stage):属于transform算子,key-value型的RDD才会有Shuffle操作(shuffle说白了就是重新分区,涉及到重新分区的算子都会进行shuffle)
常见shuffle算子 1、repartition:重新分区,shuffle 2、partitionBy:将数据按照指定 Partitioner 重新进行分区 3、groupBy:将数据根据指定的规则进行分组, 分区默认不变,会将数据打乱(shuffle),重新组合 4、groupByKey:根据key进行分组,将相同键的所有值放到同一个列表中 5、reduceByKey:根据key进行聚合,先对相同键的值进行局部聚合,然后将各个分区的局部聚合结果进行全局聚合 6、aggregateByKey:根据key进行聚合,允许用户在聚合过程中指定初始值,并且可以在局部和全局聚合过程中使用不同的逻辑函数,更加灵活 7、SortBykey:根据key进行排序操作,默认升序 8、join:两个RDD关联,相关的key关联在一起 总结 1、repartition类的操作:比如repartition、repartitionAndSortWithinPartitions、coalesce等 重分区: 一般会shuffle,因为需要在整个集群中,对之前所有的分区的数据进行随机,均匀的打乱,然后把数据放入下游新的指定数量的分区内 2、byKey类的操作:比如reduceByKey、groupByKey、sortByKey等 byKey类的操作:因为你要对一个key,进行聚合操作,那么肯定要保证集群中,所有节点上的,相同的key,一定是到同一个节点上进行处理 3、join类的操作:比如join、cogroup等join类的操作:两个rdd进行join,就必须将相同join key的数据,shuffle到同一个节点上,然后进行相同key的两个rdd数据的笛卡尔乘积 - action算子(触发新的job):reduce、collect等
常见的action算子 1、reduce 聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据 2、collect 以数组的形式返回数据集中所有元素 3、count 返回元素个数 4、first 返回第一个元素 5、take(N) 返回前N个元素 6、takeSample 类似于Simle,区别是action直接返回结果 7、fold 指定初始值和计算函数,折叠聚合整个数据集 8、saveAsTextFile 将结果存在path对应的文件中 9、saveAsSequenceFiel 将结果存在path对于的Sequence文件中 10、countByKey 求真个数据集中key出现的次数,常常用来解决数据倾斜时的问题,查看数据倾斜的key 11、foreach 遍历每一个元素
为什么需要RDD?

RDD可以看做是一个分布式计算模型:
-
是一个对象(抽象类,类似String类)
-
封装了大量方法和属性(计算逻辑,不能太复杂,有通用性)
-
适合分布式处理(划分数据,实现并行计算)

RDD算子
- Transformations转换算子:实现功能的补充和封装,将就的RDD转换成新的RDD,如map,filter
- Action动作算子:触发任务的调度和作业的执行,如collect、sum
对于转换操作(Transformations),RDD的所有转换都不会直接计算结果。 Spark仅记录作用于RDD上的转换操作逻辑,当遇到动作算子( Action)时才会进行真正计算。
DAG有向无环图
在Saprk中,使用DAG来描述的计算逻辑。

-
整个计算任务称为Application
-
Application按照action算子(clooect、savAsTextFile)划分为多个Job(作业)
-
Job按照Shuffle算子(groupByKey)划分为多个Stage(阶段)
-
RDDstage之间会有依赖关系,后面根据前面的依赖关系来构建,如果前面的数据丢了, 它会记住前面的依赖,Spark可以通过这个依赖关系重新计算丢失的分区数据,⽽不是对RDD的所有分区进⾏重新计算。
-
-
Stage按照算子划分为Task(任务),Task是Spark运行的最小调度单元
Shuffle算子

使用shuffle的常见算子:join、groupByKey、reduceByKey、countByKey、...ByKey
-
窄依赖:RDD 之间分区是一一对应的,任务可以在内存中的管道上迭代并行运行,而不需要等待前一阶段的运行结果
-
宽依赖:发生shuffle,多对多的关系,宽依赖表示子RDD的一个分区依赖了父RDD的多个分区
shuffle流程
Spark Shuffle分为两种:
-
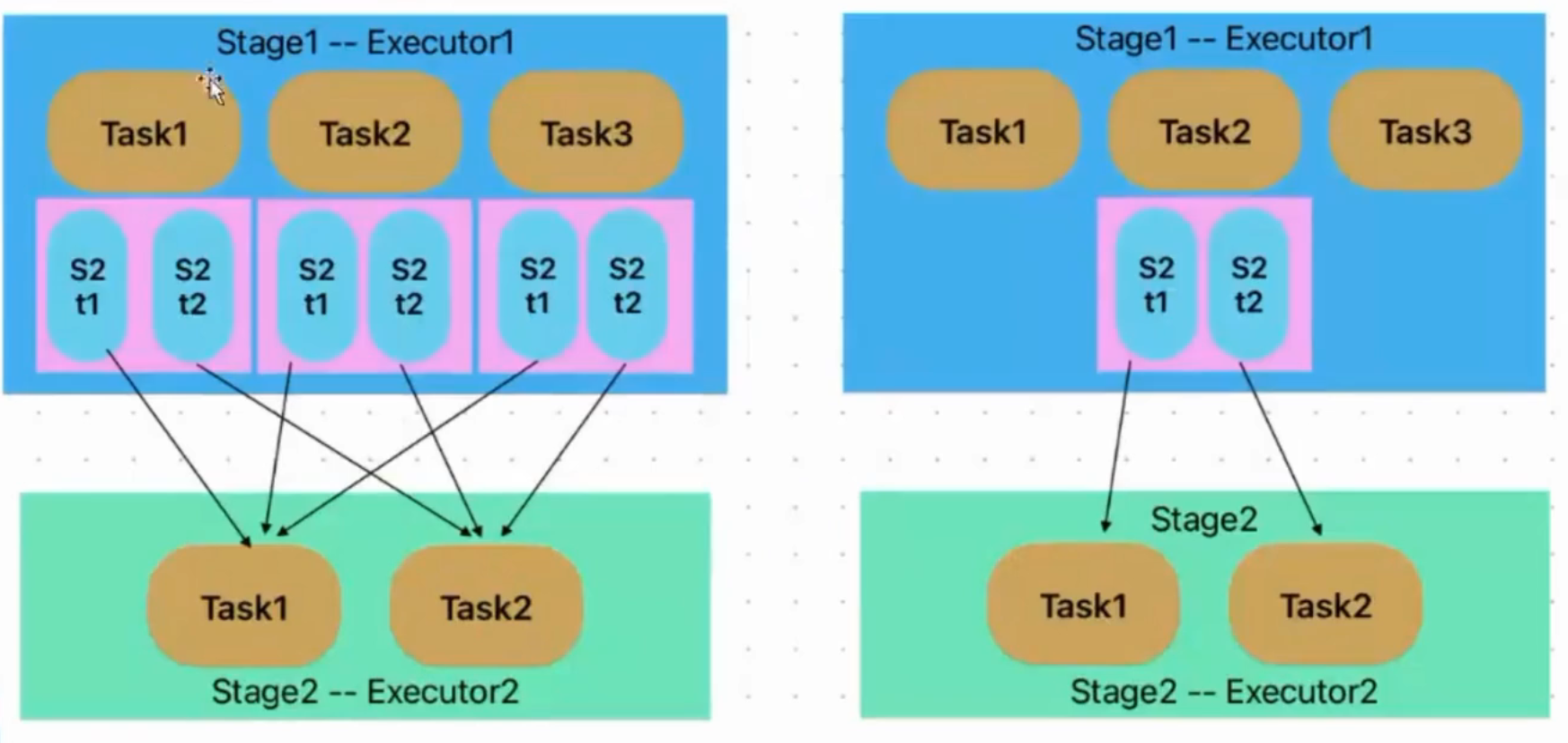
基于Hash的Shuffle
在基于 Hash 的 Shuffle 实现方式中,每个 Mapper 阶段的 Task 会为每个 Reduce 阶段的 Task 生成一个文件,通常会产生大量的文件m*n,伴随大量的随机磁盘 I/O 操作与大量的内存开销。
-
合并机制:倘若Executor只有一个core,所以每次只能有一个task执行,当第一个task执行完成后,第二个task会复用第一个task所创建的buffer和磁盘文件,从而减少磁盘文件的个数,也就是说maper阶段无论多少个task,产生的文件数量都=reduce阶段的task数量。
-
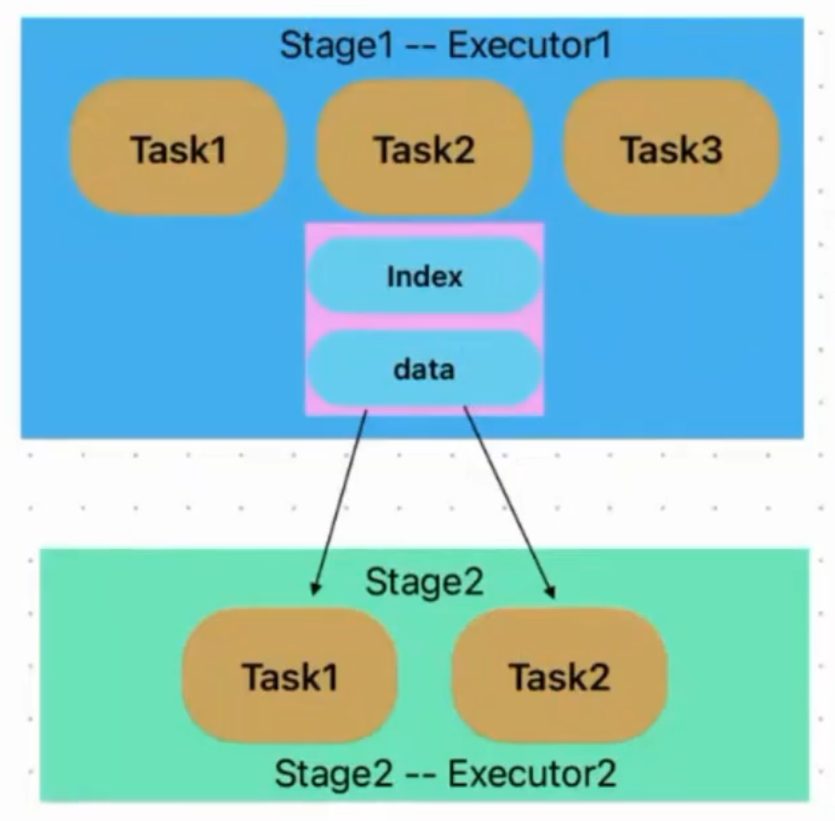
基于Sort的Shuffle
在溢写磁盘前,先根据 key 进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为 10000 条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是说一个 Task 过程会产生多个临时文件。最后在每个 Task 中,将所有的临时文件合并,这就是 merge 过程,此过程将所有临时文件读取出来,一次写入到最终文件。(也就是说,map阶段只会产生2个文件,一个是data保存数据,一个是index保存对应索引,reduce只需要按照对应索引去data取数就行)
-
bypass运行机制:与sort shuffle一样,但是不排序,效率高。在不需要排序的场景使用。

Spark Shuffle 和 Hadoop Shuffle 区别
-
Hadoop 不用等所有的 MapTask 都结束后开启 ReduceTask;Spark 必须等到父 Stage都完成,才能去 Fetch 数据。
-
Hadoop 的 Shuffle 是必须排序的,那么不管是 Map 的输出,还是 Reduce 的输出,都是分区内有序的,而 Spark 不要求这一点。
Spark的内存管理
统一内存管理:主要是Storage内存用于缓存数据,Execution内存用于缓存shuffle产生的中间数据,实行动态占用机制,但是Execution内存优先级更高,才能保证程序正常执行,Storage内存不足大不了落磁或者重新计算。
RDD五大特性
-
RDD由一系列分区partition组成;
-
对RDD计算相当于对RDD每个分区做计算(算⼦是作⽤在partition之上的);
-
RDD之间存在依赖关系;
-
分区器是作⽤在kv形式的RDD上;
-
尽量让计算程序靠近数据源,移动数据不如移动计算程序;计算每个分区时,在分区所在机器的本地上运行task是最好的,避免了数据的移动,减少数据的IO和网络传输,这样才能更好地减少作业运行时间。
RDD的弹性怎么体现
(repartition分区弹性)RDD中的数据假设分散在3台机器上,可以设置为分散到10台机器上。
(存储弹性)优先存放在内存中,内存不足存放在磁盘中。
(容错弹性)Stage或task出错会自动重试,如果还是失败可以通过checkpoint恢复,不需要全部重来。
“弹性”指的是可以根据计算规模进行动态改变计算资源的特性。当计算量增长时,可以动态增加资源来满足计算需求,而当计算量减少时,又可以降低资源配置来节约成本。
-
存储弹性
Spark能够自动的进行内存和磁盘数据存储的切换,优先把数据放到内存中,如果内存实在放不下,会放到磁盘里面 -
计算弹性
基于Lineage血缘的高效容错,某个节点出错,可以从前一个节点恢复数据。 -
重试弹性,Task和Stage如果失败会自动进行特定次数的重试
-
Checkpoint检查点(每次对 RDD 操作都会产生新的 RDD,如果链条比较长,计算比较笨重,就把数据放在硬盘中)和persist持久化(内存或磁盘中对数据进行复用)
-
数据调度弹性,Spark将执行模型抽象为DAG,这可以将多Stage的任务串联或并行执行,从而不需要将Stage中间结果输出到HDFS中,当发生节点运行故障时,可有其他可用节点代替该故障节点运行。DAG Task 和资源管理无关。
-
数据分片弹性,Spark进行数据分片时,默认将数据放在内存中,如果内存放不下,一部分会放在磁盘上进行保存。
SparkSQL底层原理
-
将SQL语句转换成语法抽象树AST
-
生成逻辑计划,并对逻辑计划进行优化
-
生成物理计划
-
最后生成代码到集群中以为RDD的形式运行
对比HiveSQL的解析过程:
-
解析器:将SQL语句转换成语法抽象树AST
-
语义分析器:将语法抽象树进一步抽象为基本的查询单元:查询块QueryBlock
-
通过遍历查询块,生成逻辑计划,并对逻辑计划进行优化
-
根据优化后的逻辑计划生成物理计划(MR任务),并对物理计划进优化
-
执行器:执行物理计划(MR任务)
Spark on Hive 和 Hive on Spark 区别

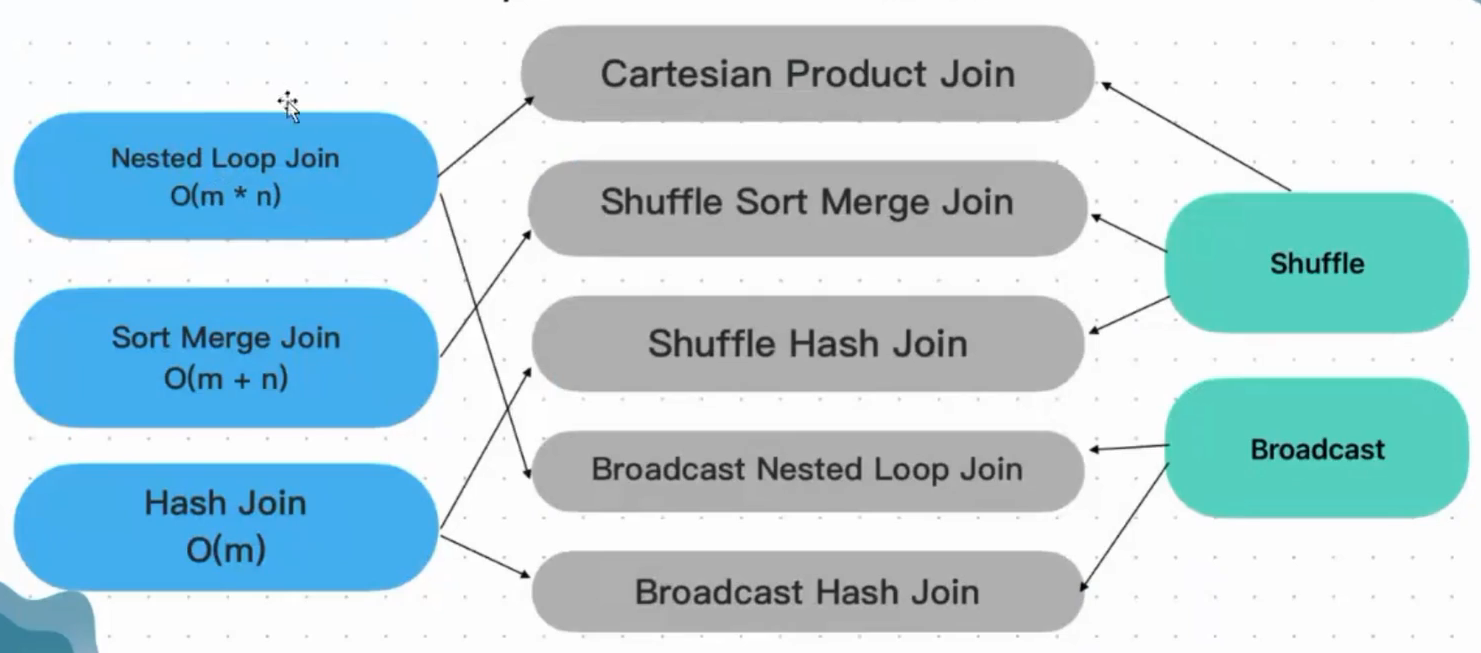
Spark的Join实现
Spark优化

AQE(有shuffle自动生效):
- 自动分区合并:设置小分区阈值,自动合并小分区,减少并行度
- 数据倾斜:设置大分区阈值,大分区自动拆分多个小分区
- join策略调整:设置小表阈值,自动广播
Spark的数据倾斜
1.聚合的时候
1)如果数据倾斜的Key比较密集,也就是集中在某几个task中,那就先进行aggregate预聚合,预聚合是并行执行的,会比shuffle再聚合速度快一些。
2)如果数据倾斜的Key比较分散,也就是分散在很多task里面,那么就加随机前缀把他打散,聚合后再把前缀去掉合并起来。
案例:Hive使用双重GroupBy解决数据倾斜问题_group by数据倾斜-优快云博客
#加随机前缀1_a
with tmp as
(
select
concat_ws(‘_‘,cast(ceil(rand()*10) as string),a) salt_a, #加盐salt_a
count(1) count
from wordcount
group by concat_ws(’’,cast(ceil(rand()*10) as string),a) #对字段a加盐分组
)
#去除前缀1_
select select split(salt_a,‘_’)[1] alpah ,sum(count)
from tmp
group by split(salt_a,‘_’)[1];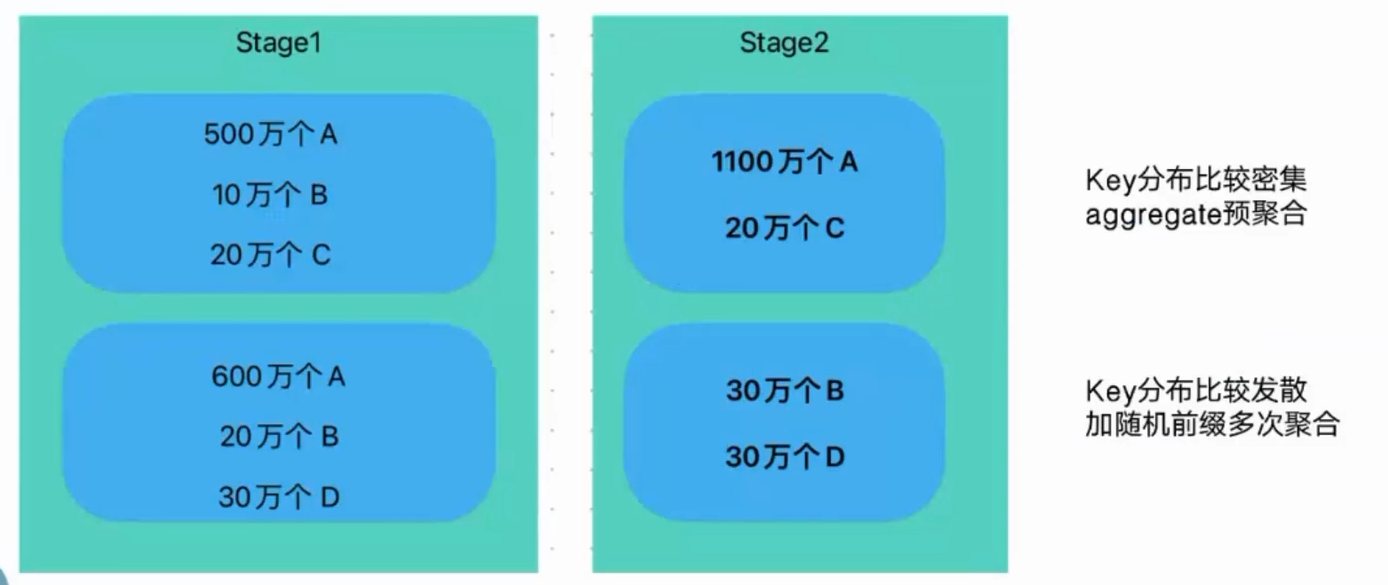
2.join的时候
1)大表join 小表优化
使用Mapjoin,mapjoin优化是在Map阶段进行join,而不是通常那样在Reduce阶段分发后在每个Reduce节点上进行join,不需要分发也就没有倾斜的问题。
mapjoin的原理是把小表广播(Broadcast)出去,这样大表就不用动了,可以减少网络传输,避免shuffle。
需要注意的是小表不能太大,不然得不偿失,默认是25M,而且这个大小是指加载到内存的大小,不是压缩后的大小。
2)大表join大表 优化
对大表选择合适的列拆分成小表,然后广播出去进行jion,最后再union到一起。
需要注意的是大表需要提前缓存,避免重复计算。
3)Key倾斜
解决思路:将数据量过大的key数据单独拆分出来加上1-n随机前缀,将另一个表中对应的数据也拆分出来,并膨胀成n份,每份数据同样加上前缀,保证能够关联,这样再join就不会发生数据倾斜了。
Spark解决方案:
- 对包含少数几个数据量过大的key的那个RDD(大表),通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
- 然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
- 接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
- 再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
- 而另外两个普通的RDD就照常join即可。 最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
小表left join大表
小表作为基表时不能被广播,若广播则基表必须全部被写出的逻辑会被破坏,也就是说小表中没有关联上的数据会丢失。(基表包括left join左侧,right join右侧,full join两侧)
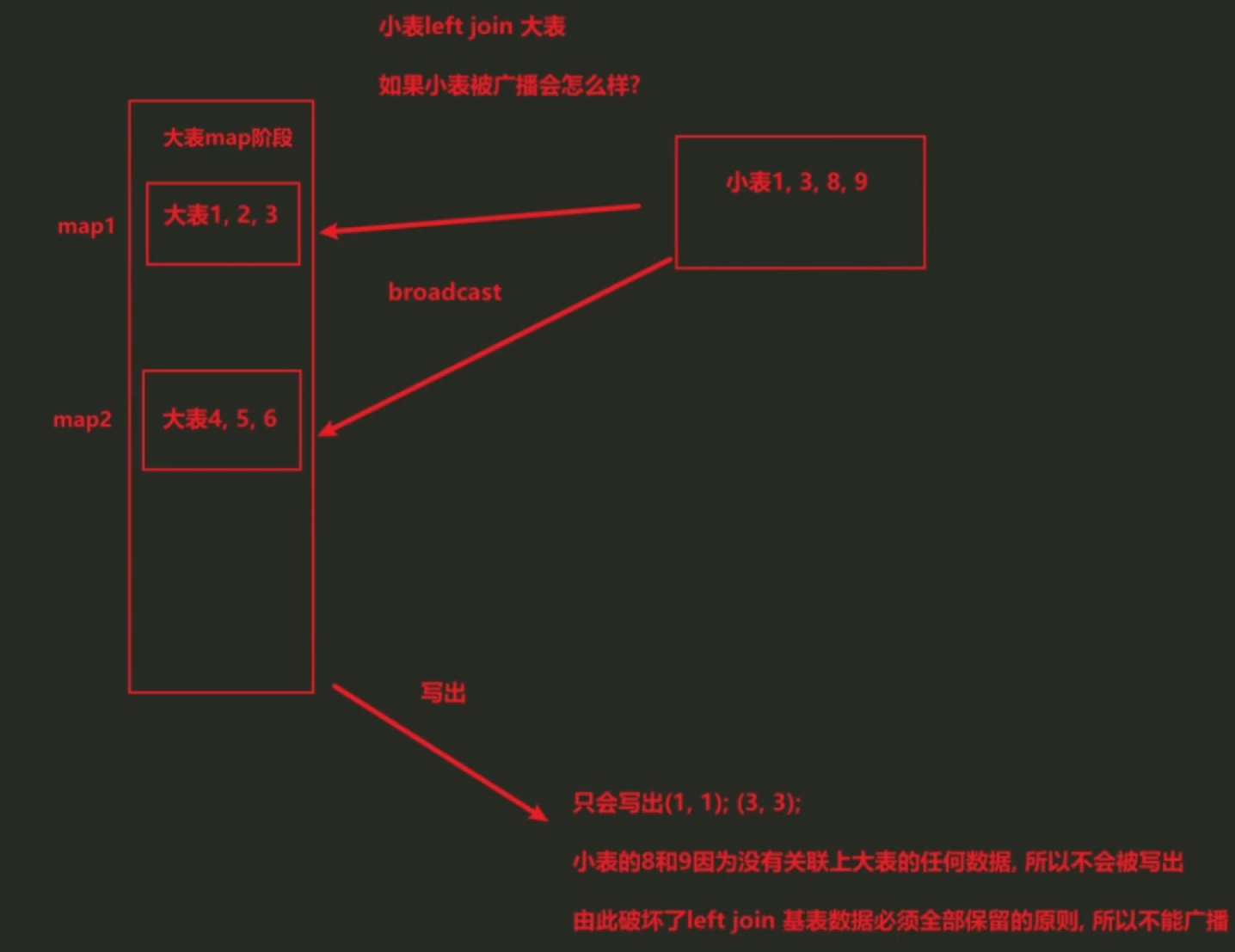
场景1:订单增量表(2W)关联全量用户维表(10亿),通过用户id关联,实现维度退化:
select * from 订单增量表 a left join 全量用户维表 b on a.uid=b.uid优化:
--先采用内连接关联(内连接时可以广播的),顺便过滤掉没关联上的数据
--外层再采用小表left join,就能保留小表没关联上的数据
前提是小表需要有唯一主键order_id,否则外层关联就会多对多膨胀
select * #广播t1
from 订单增量表
left join #以订单增量表作为基表,left join新的小表,保留没关联上的数据,这个也可以广播
(
#先通过内连接,就可以广播,获得一张新的小表
select * #广播t1订单增量表
from 订单增量表 a join 全量用户维表 b on a.uid=b.uid
)t1
on 订单增量表.order_id = t1.order_idRDD、DataFrame、Dataset三者的区别
相同点:三者都是spark的分布式数据集,都是懒执行(创建、转换时不会立即执行,遇到行动算子才会开始计算),都是基于内存的,最终都是转成RDD执行。
- RDD:RDD内置了很多函数用于处理数据;面向对象编程,直接存储Java对象;不支持sparksql操作。
- DataFrame:类似一张二维表,更好地处理结构化数据,保存的是row对象;支持sparksql操作(结构化数据sql查询),但是对于数据类型的检查不敏感,只有运行时才能发现错误。
- Dataset:DataFrame的扩展,整合了RDD和DataFrame,支持结构化和非结构化数据,加入了编译器的数据类型检查,给每一行加了类型约束;支持sparksql操作。
发展:Spark1.0提出RDD,Spark1.3提出DataFrame,Spark1.6提出Dataset,Spark2.0中Dataset包含了DataFrame,DataFrame=Dataset[row]。



















 2672
2672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









