




目录
一、K均值
1、K均值不适用的情况
此示例旨在说明k-means将产生不直观的、可能是意外的聚类的情况。在前三幅图中,输入的数据不符合一些隐含的假设,即k均值生成,因此产生了不理想的聚类。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
plt.figure(figsize=(12, 12))
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# Incorrect number of clusters :集群数量不正确
y_pred = KMeans(n_clusters=2, random_state=random_state).fit_predict(X)
plt.subplot(221)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("Incorrect Number of Blobs")
# Anisotropicly distributed data :各向异性分布的数据
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
X_aniso = np.dot(X, transformation)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_aniso)
plt.subplot(222)
plt.scatter(X_aniso[:, 0], X_aniso[:, 1], c=y_pred)
plt.title("Anisotropicly Distributed Blobs")
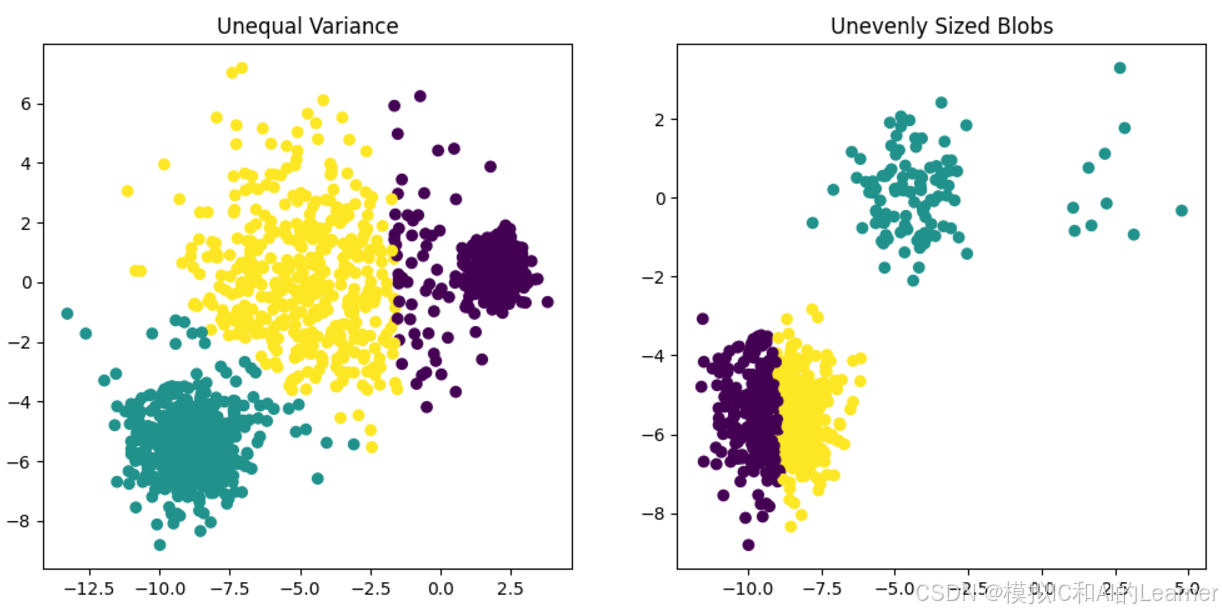
# Different variance :不同的方差
X_varied, y_varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_varied)
plt.subplot(223)
plt.scatter(X_varied[:, 0], X_varied[:, 1], c=y_pred)
plt.title("Unequal Variance")
# Unevenly sized blobs :大小不均匀的blobs
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
y_pred = KMeans(n_clusters=3,
random_state=random_state).fit_predict(X_filtered)
plt.subplot(224)
plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=y_pred)
plt.title("Unevenly Sized Blobs")
plt.show()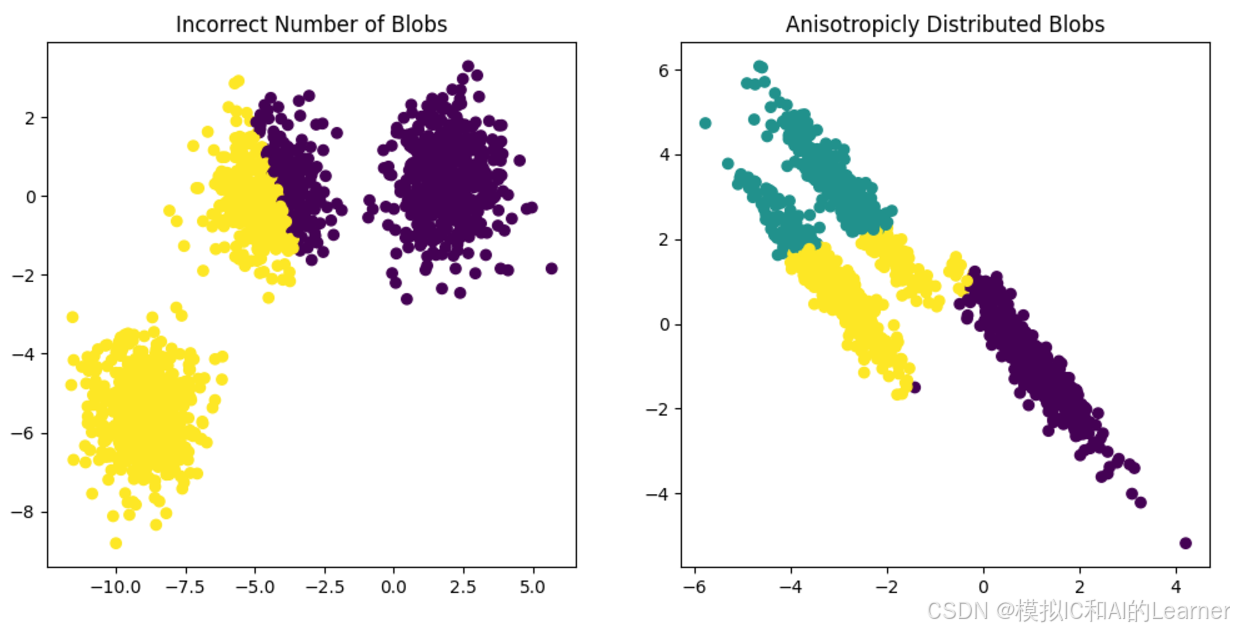
2、K均值聚类鸢尾花数据集
# K均值-鸢尾花聚类
#!pip install plotly
import plotly.express as px
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Though the following import is not directly being used, it is required
from sklearn.cluster import KMeans
from sklearn import datasets
np.random.seed(5)
iris = datasets.load_iris()
X = iris.data
y = iris.target
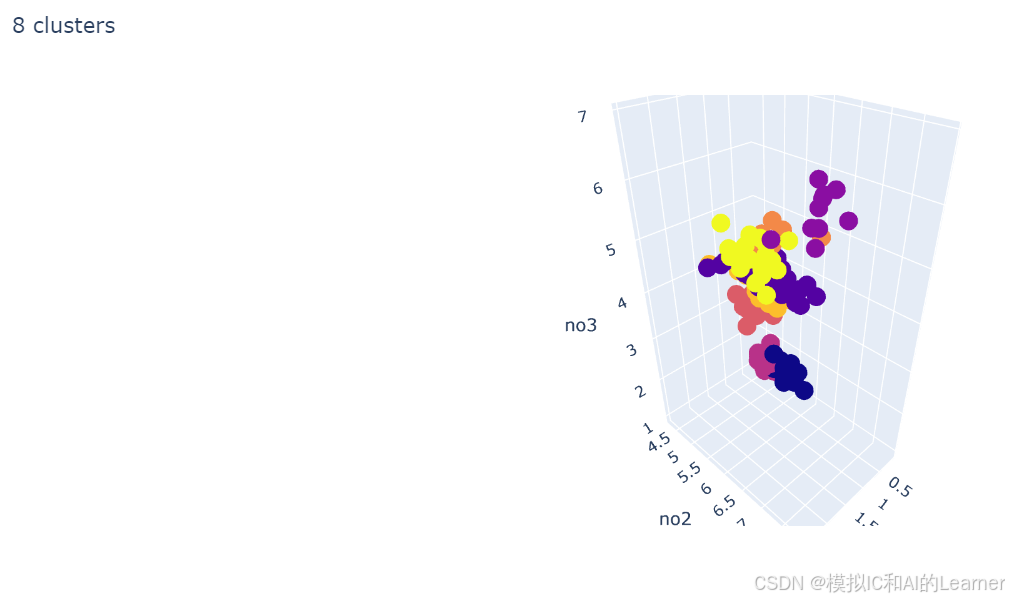
estimators = [('k_means_iris_8', KMeans(n_clusters=8)),
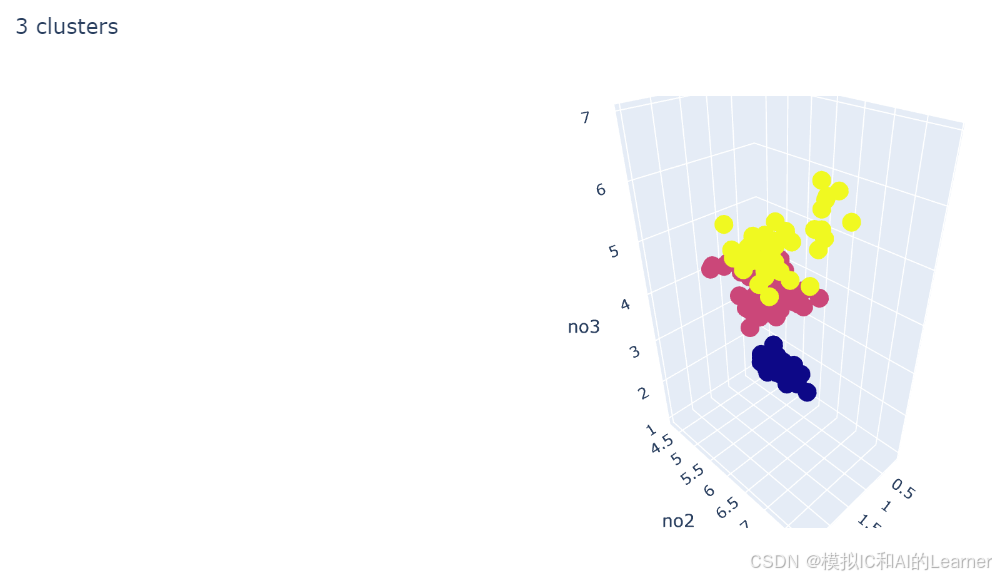
('k_means_iris_3', KMeans(n_clusters=3)),
('k_means_iris_bad_init', KMeans(n_clusters=3, n_init=1,
init='random'))]
fignum = 0
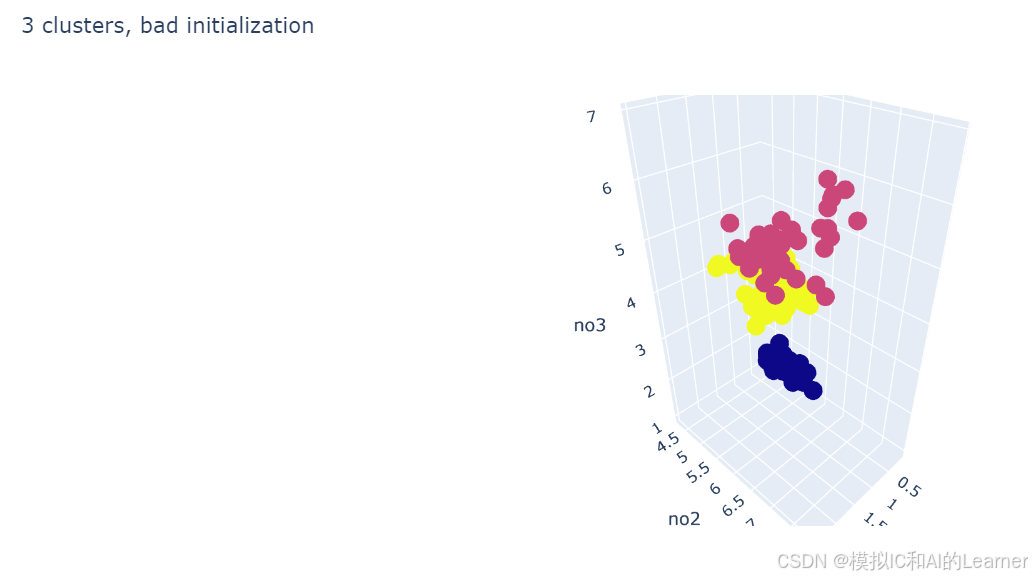
titles = ['8 clusters', '3 clusters', '3 clusters, bad initialization']
for name, est in estimators:
est.fit(X)
labels = est.labels_
# 创建DataFrame
df = pd.DataFrame(X[:, [3, 0, 2]], columns=["no1", "no2", "no3"])
df['species'] = labels
fig = px.scatter_3d(df, x="no1", y="no2", z="no3", color="species", title=titles[fignum])
fig.show()
fignum = fignum + 1
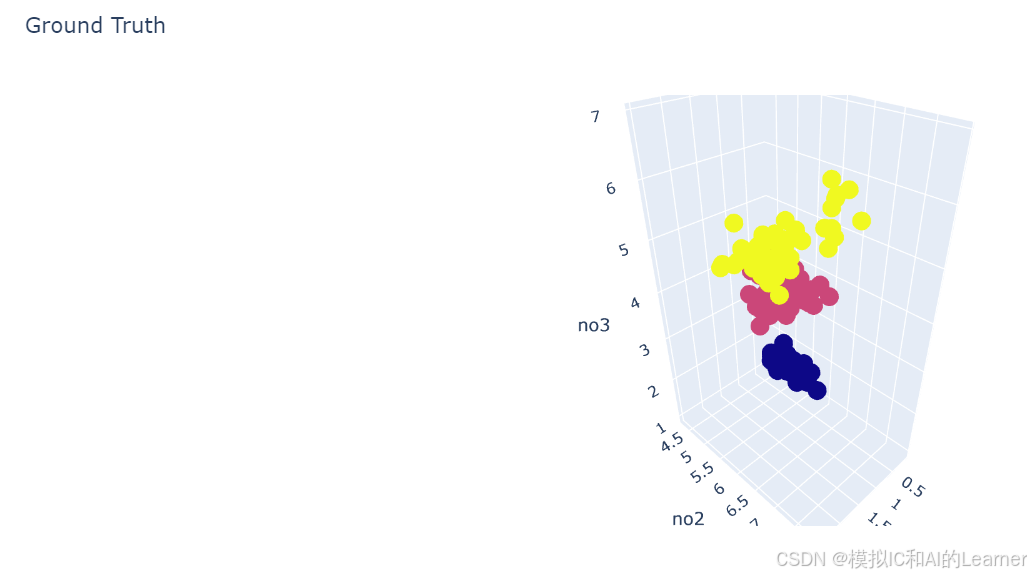
# Reorder the labels to have colors matching the cluster results
#y = np.choose(y, [1, 2, 0]).astype(np.float64)
# 创建DataFrame
df = pd.DataFrame(X[:, [3, 0, 2]], columns=["no1", "no2", "no3"])
df['species'] = y
fig = px.scatter_3d(df, x="no1", y="no2", z="no3", color="species", title='Ground Truth')
fig.show()
二、高斯混合模型
# 高斯混合模型对鸢尾花聚类
#!pip install plotly
import plotly.express as px
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.mixture import GaussianMixture
from sklearn.metrics import confusion_matrix
# 1. 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 特征数据
y_true = iris.target # 真实标签(仅用于比较)
feature_names = iris.feature_names
# 2. 使用高斯混合模型进行聚类,指定聚类数为3(鸢尾花数据集有3个类别)
gmm = GaussianMixture(n_components=3, random_state=42)
gmm.fit(X)
y_gmm = gmm.predict(X)
# 3. 输出混淆矩阵(真实类别与聚类结果之间的对比)
print("混淆矩阵:")
print(confusion_matrix(y_true, y_gmm))
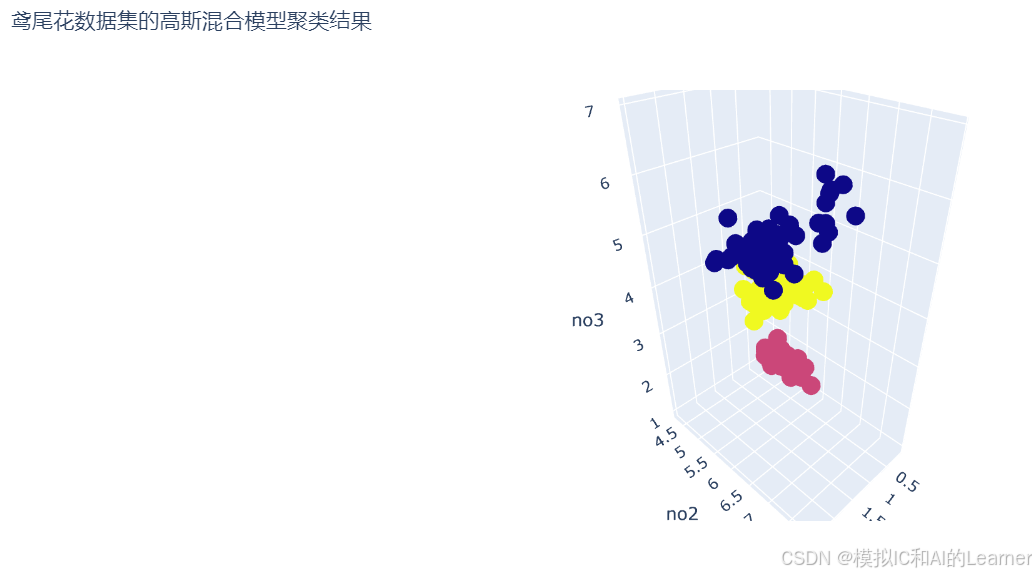
# 4. 可视化聚类结果
# 创建DataFrame
df = pd.DataFrame(X[:, [3, 0, 2]], columns=["no1", "no2", "no3"])
df['species'] = y_gmm
fig = px.scatter_3d(df, x="no1", y="no2", z="no3", color="species", title='鸢尾花数据集的高斯混合模型聚类结果')
fig.show()
混淆矩阵: [[ 0 50 0]
[ 5 0 45]
[50 0 0]]
三、层次聚类
代码一:
#层次聚类鸢尾花数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram
# 1. 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 2. 使用 AgglomerativeClustering,确保获取距离信息
agg_cluster = AgglomerativeClustering(n_clusters=3, linkage='ward', compute_distances=True)
y_pred = agg_cluster.fit_predict(X)
# 3. 输出混淆矩阵(真实类别与聚类结果之间的对比)
print("混淆矩阵:")
print(confusion_matrix(y, y_pred))
# 3. 提取合并信息和距离
children = agg_cluster.children_
distances = agg_cluster.distances_
# 4. 构造 linkage matrix
n_samples = X.shape[0]
counts = np.zeros(children.shape[0])
for i, merge in enumerate(children):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # 原始样本
else:
current_count += counts[child_idx - n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack([children, distances, counts]).astype(float)
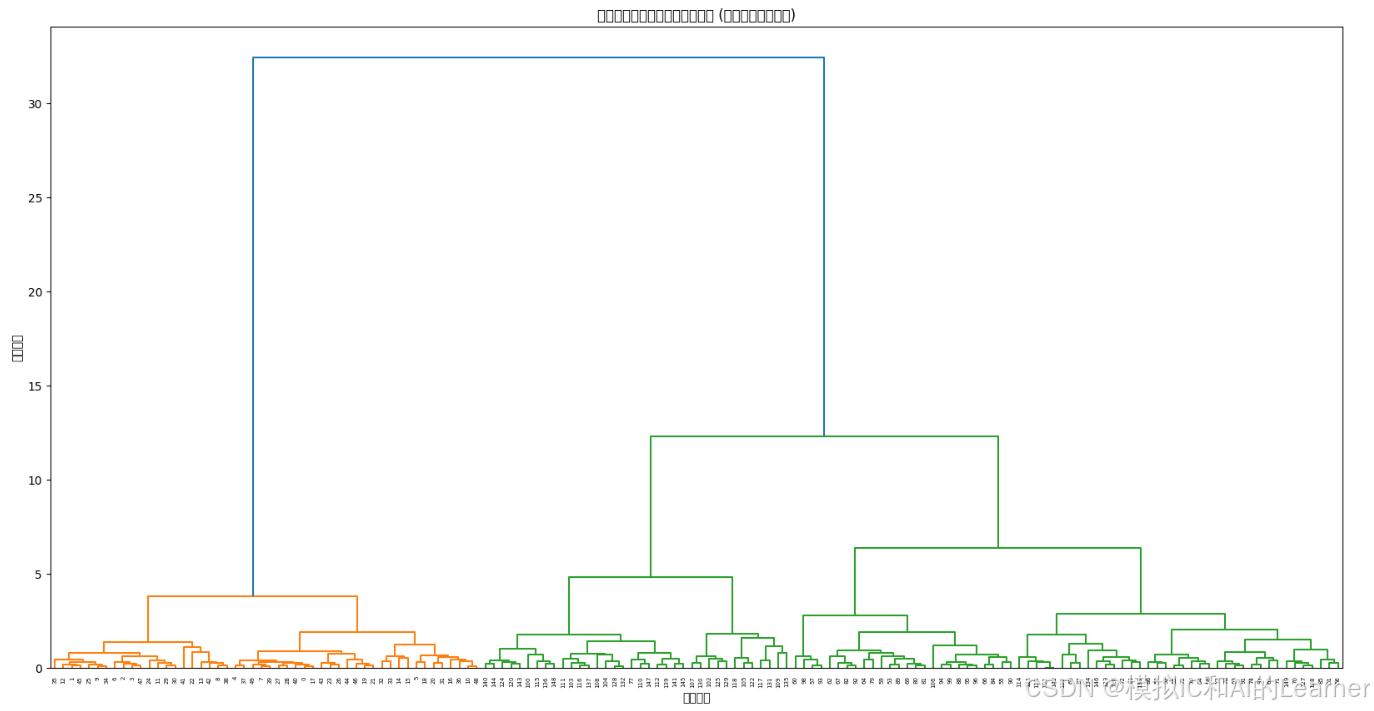
# 5. 绘制树状图
plt.figure(figsize=(20, 14))
plt.title("鸢尾花数据集的层次聚类树状图 (反映模型训练过程)")
dendrogram(linkage_matrix)
plt.xlabel("样本索引")
plt.ylabel("合并距离")
plt.show()
代码二:
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram
from sklearn.datasets import load_iris
from sklearn.cluster import AgglomerativeClustering
def plot_dendrogram(model, **kwargs):
# Create linkage matrix and then plot the dendrogram
# create the counts of samples under each node
counts = np.zeros(model.children_.shape[0])
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # leaf node
else:
current_count += counts[child_idx - n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack([model.children_, model.distances_,
counts]).astype(float)
# Plot the corresponding dendrogram
dendrogram(linkage_matrix, **kwargs)
iris = load_iris()
X = iris.data
# setting distance_threshold=0 ensures we compute the full tree.
model = AgglomerativeClustering(distance_threshold=0, n_clusters=None)
model = model.fit(X)
plt.title('Hierarchical Clustering Dendrogram')
# plot the top three levels of the dendrogram
plot_dendrogram(model, truncate_mode='level', p=3)
plt.xlabel("Number of points in node (or index of point if no parenthesis).")
plt.show()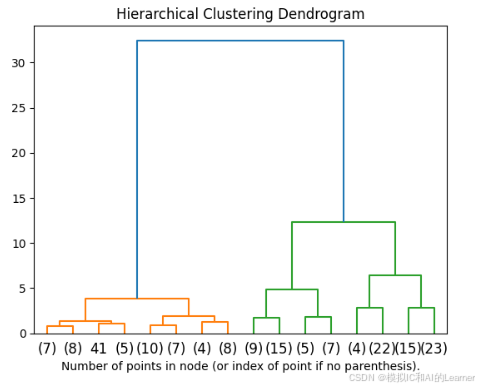
四、基于密度的聚类
# DBSCAN基于密度的聚类
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# #############################################################################
# Compute DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
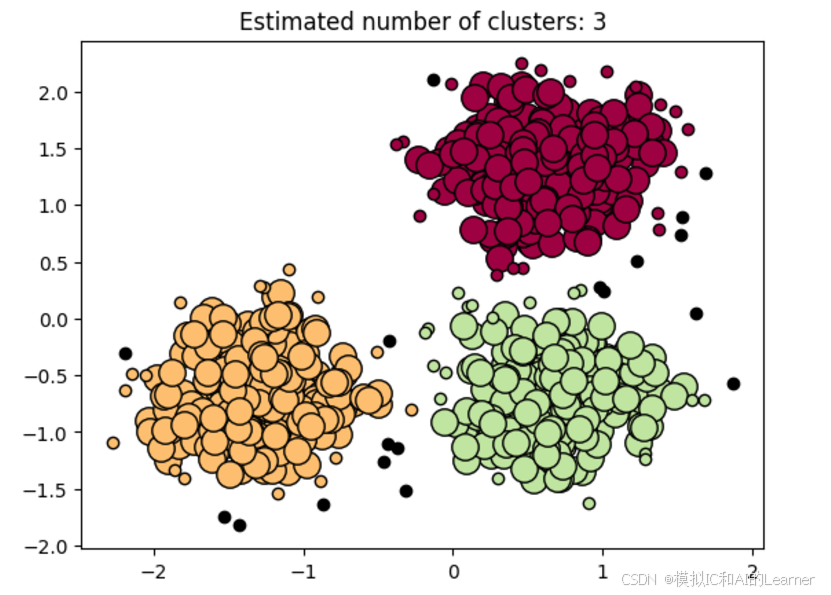
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)Estimated number of clusters: 3 Estimated number of noise points: 18 Homogeneity: 0.953 Completeness: 0.883 V-measure: 0.917 Adjusted Rand Index: 0.952 Adjusted Mutual Information: 0.916 Silhouette Coefficient: 0.626
Text(0.5, 1.0, 'Estimated number of clusters: 3')
五、基于图的聚类(谱聚类)
# 基于图的聚类
import numpy as np
from sklearn.cluster import SpectralClustering
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# #############################################################################
# Compute
clustering = SpectralClustering(n_clusters=3,assign_labels="discretize",random_state=0).fit(X)
labels = clustering.labels_
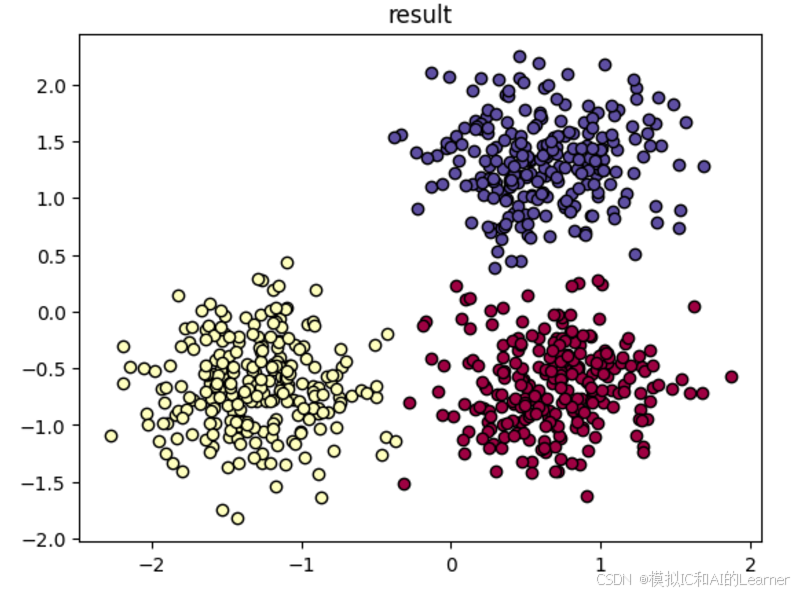
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
class_member_mask = (labels == k)
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('result')Homogeneity: 0.939 Completeness: 0.939 V-measure: 0.939 Adjusted Rand Index: 0.964 Adjusted Mutual Information: 0.938 Silhouette Coefficient: 0.650
Text(0.5, 1.0, 'result')
六、聚类综合
# 综合
import time
import warnings
import numpy as np
import matplotlib.pyplot as plt
from sklearn import cluster, datasets, mixture
from sklearn.neighbors import kneighbors_graph
from sklearn.preprocessing import StandardScaler
from itertools import cycle, islice
np.random.seed(0)
# ============
# Generate datasets. We choose the size big enough to see the scalability
# of the algorithms, but not too big to avoid too long running
# 生成数据集。我们选择足够大的大小,以便看到算法的可扩展性,但不要太大,以避免运行时间过长
# ============
n_samples = 1500
noisy_circles = datasets.make_circles(n_samples=n_samples, factor=.5,
noise=.05)
noisy_moons = datasets.make_moons(n_samples=n_samples, noise=.05)
blobs = datasets.make_blobs(n_samples=n_samples, random_state=8)
no_structure = np.random.rand(n_samples, 2), None
# Anisotropicly distributed data 各向异性分布的数据
random_state = 170
X, y = datasets.make_blobs(n_samples=n_samples, random_state=random_state)
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X, transformation)
aniso = (X_aniso, y)
# blobs with varied variances 具有不同方差的 blob
varied = datasets.make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
# ============
# Set up cluster parameters 设置聚类参数
# ============
plt.figure(figsize=(9 * 2 + 3, 12.5))
plt.subplots_adjust(left=.02, right=.98, bottom=.001, top=.96, wspace=.05,
hspace=.01)
plot_num = 1
default_base = {'quantile': .3,
'eps': .3,
'damping': .9,
'preference': -200,
'n_neighbors': 10,
'n_clusters': 3,
'min_samples': 20,
'xi': 0.05,
'min_cluster_size': 0.1}
datasets = [
(noisy_circles, {'damping': .77, 'preference': -240,
'quantile': .2, 'n_clusters': 2,
'min_samples': 20, 'xi': 0.25}),
(noisy_moons, {'damping': .75, 'preference': -220, 'n_clusters': 2}),
(varied, {'eps': .18, 'n_neighbors': 2,
'min_samples': 5, 'xi': 0.035, 'min_cluster_size': .2}),
(aniso, {'eps': .15, 'n_neighbors': 2,
'min_samples': 20, 'xi': 0.1, 'min_cluster_size': .2}),
(blobs, {}),
(no_structure, {})]
for i_dataset, (dataset, algo_params) in enumerate(datasets):
# update parameters with dataset-specific values 使用数据集特有的值更新参数
params = default_base.copy()
params.update(algo_params)
X, y = dataset
# normalize dataset for easier parameter selection 规范化数据集以便于参数选择
X = StandardScaler().fit_transform(X)
# estimate bandwidth for mean shift 估计均值偏移的带宽
# 根据数据 X 和指定的 quantile 参数来估计 MeanShift 算法中所需的带宽。
bandwidth = cluster.estimate_bandwidth(X, quantile=params['quantile'])
# connectivity matrix for structured Ward 连接矩阵对于结构化Ward算法
connectivity = kneighbors_graph(
X, n_neighbors=params['n_neighbors'], include_self=False)
# make connectivity symmetric 使连接对称
connectivity = 0.5 * (connectivity + connectivity.T)
# ============
# Create cluster objects 创建聚类对象
# ============
ms = cluster.MeanShift(bandwidth=bandwidth, bin_seeding=True)
two_means = cluster.MiniBatchKMeans(n_clusters=params['n_clusters'])
ward = cluster.AgglomerativeClustering(
n_clusters=params['n_clusters'], linkage='ward',
connectivity=connectivity)
spectral = cluster.SpectralClustering(
n_clusters=params['n_clusters'], eigen_solver='arpack',
affinity="nearest_neighbors")
dbscan = cluster.DBSCAN(eps=params['eps'])
optics = cluster.OPTICS(min_samples=params['min_samples'],
xi=params['xi'],
min_cluster_size=params['min_cluster_size'])
affinity_propagation = cluster.AffinityPropagation(
damping=params['damping'], preference=params['preference'])
average_linkage = cluster.AgglomerativeClustering(
linkage="average",
n_clusters=params['n_clusters'], connectivity=connectivity)
birch = cluster.Birch(n_clusters=params['n_clusters'])
gmm = mixture.GaussianMixture(
n_components=params['n_clusters'], covariance_type='full')
clustering_algorithms = (
('MiniBatchKMeans', two_means), # K均值
('AffinityPropagation', affinity_propagation), # 基于信息传播的聚类方法
('MeanShift', ms), # 基于密度的基于密度估计的聚类
('SpectralClustering', spectral), # 基于图的聚类(谱聚类)
('Ward', ward), # 基于 Ward 法则的层次聚类
('AgglomerativeClustering', average_linkage), # 使用平均链接的层次聚类,同样利用连接矩阵。
('DBSCAN', dbscan), # 基于密度的聚类DBSCAN
('OPTICS', optics), # 基于密度的聚类改进版
('Birch', birch), # 适用于大规模数据的层次聚类算法,指定聚类数。
('GaussianMixture', gmm) # 高斯混合模型
)
for name, algorithm in clustering_algorithms:
t0 = time.time()
# catch warnings related to kneighbors_graph :捕获与 kneighbors_graph 相关的警告
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message="the number of connected components of the " +
"connectivity matrix is [0-9]{1,2}" +
" > 1. Completing it to avoid stopping the tree early.",
category=UserWarning)
warnings.filterwarnings(
"ignore",
message="Graph is not fully connected, spectral embedding" +
" may not work as expected.",
category=UserWarning)
algorithm.fit(X)
t1 = time.time()
if hasattr(algorithm, 'labels_'):
y_pred = algorithm.labels_.astype(np.int64)
else:
y_pred = algorithm.predict(X)
plt.subplot(len(datasets), len(clustering_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
colors = np.array(list(islice(cycle(['#377eb8', '#ff7f00', '#4daf4a',
'#f781bf', '#a65628', '#984ea3',
'#999999', '#e41a1c', '#dede00']),
int(max(y_pred) + 1))))
# add black color for outliers (if any) 为异常值添加黑色(如果有)
colors = np.append(colors, ["#000000"])
plt.scatter(X[:, 0], X[:, 1], s=10, color=colors[y_pred])
plt.xlim(-2.5, 2.5)
plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.text(.99, .01, ('%.2fs' % (t1 - t0)).lstrip('0'),
transform=plt.gca().transAxes, size=15,
horizontalalignment='right')
plot_num += 1
plt.show()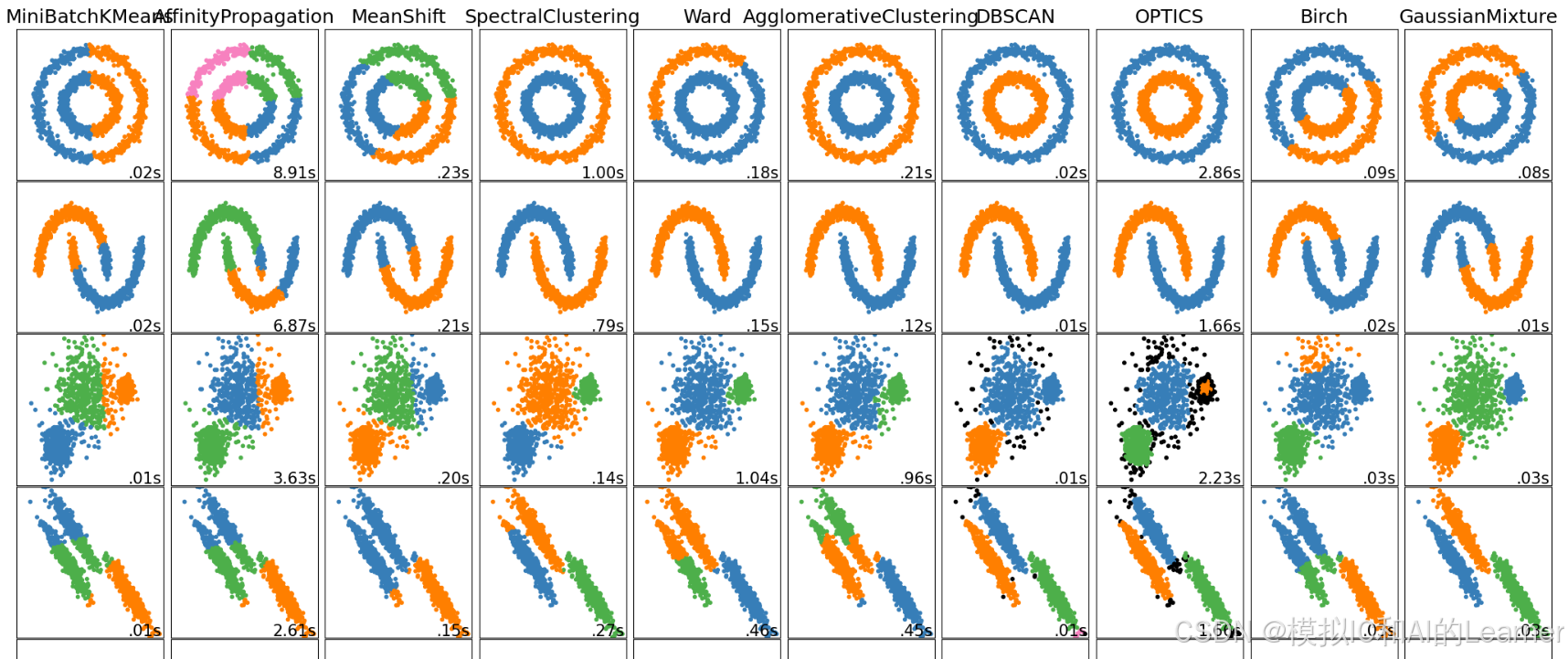
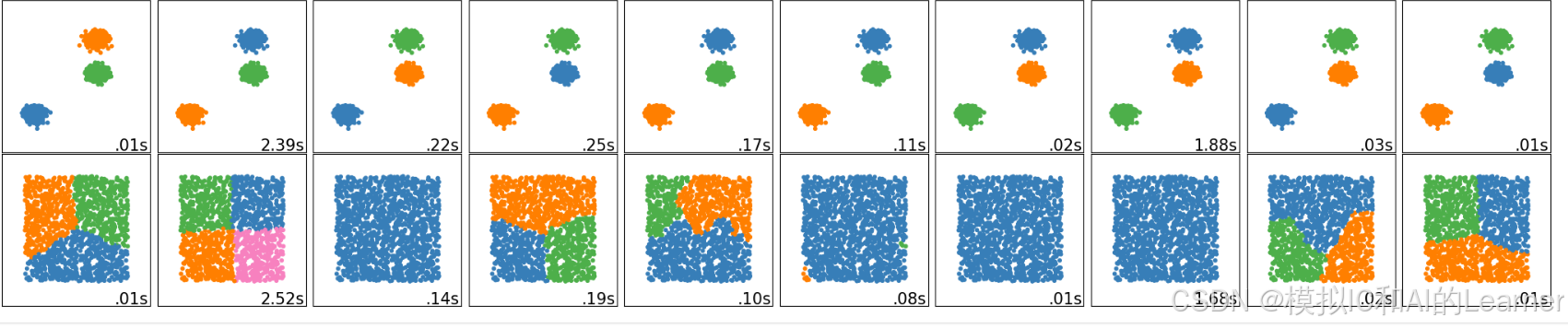
七、聚类评估
1、外部评价指标
# 聚类评估——外部评估(有真实标签)
# K均值-鸢尾花聚类
#!pip install plotly
import plotly.express as px
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Though the following import is not directly being used, it is required
from sklearn.cluster import KMeans
from sklearn import datasets
# 导入评估指标(理论文章中提到的)
import math
from sklearn.metrics import fowlkes_mallows_score, rand_score
from sklearn.metrics.cluster import contingency_matrix
# 导入更多的聚类评估指标
from sklearn.metrics import homogeneity_score, completeness_score, v_measure_score, adjusted_rand_score, adjusted_mutual_info_score, silhouette_score
np.random.seed(5)
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = KMeans(n_clusters=3)
estimators.fit(X)
labels = estimators.labels_
# 创建DataFrame
df = pd.DataFrame(X[:, [3, 0, 2]], columns=["no1", "no2", "no3"])
df['species'] = labels
fig = px.scatter_3d(df, x="no1", y="no2", z="no3", color="species")
fig.show()
# --- 以下部分进行聚类评估 ---
# 定义计算 Jaccard 系数的函数
def jaccard_index(labels_true, labels_pred):
"""
计算基于样本对计数的 Jaccard 系数:
JC = a / (a + c + d)
其中:
a:同一对样本在真实标签和预测标签中均在同一簇
c:样本对在真实标签中同属一簇但在预测中分属不同簇
d:样本对在预测标签中同属一簇但在真实中分属不同簇
"""
# 构造真实标签与预测标签的列联矩阵
cont = contingency_matrix(labels_true, labels_pred)
# 计算组合数:n 取 2
def comb(n):
return math.comb(n, 2) if n >= 2 else 0
# a:所有 cell 中样本对的组合数和
a = np.sum([comb(n_ij) for n_ij in cont.flatten()])
# 每个真实簇内部的样本对数之和
sum_true = np.sum([comb(n_i) for n_i in np.sum(cont, axis=1)])
# 每个预测簇内部的样本对数之和
sum_pred = np.sum([comb(n_j) for n_j in np.sum(cont, axis=0)])
# c 与 d 分别为真实或预测内部的样本对数减去 a
c = sum_true - a
d = sum_pred - a
return a / (a + c + d)
# 计算各项评估指标(理论文章中提到的外部评估方法)
jc = jaccard_index(y, labels)
fmi = fowlkes_mallows_score(y, labels)
ri = rand_score(y, labels)
print("评估指标结果:")
print("Jaccard 系数 (JC):", jc)
print("Fowlkes and Mallows 指数 (FMI):", fmi)
print("Rand 指数 (RI):", ri)
# 还有其他评估指标
homo = homogeneity_score(y, labels)
comp = completeness_score(y, labels)
v_meas = v_measure_score(y, labels)
ari = adjusted_rand_score(y, labels)
ami = adjusted_mutual_info_score(y, labels)
print("其他的聚类评估指标结果:")
print("Homogeneity Score:", homo)
print("Completeness Score:", comp)
print("V-measure Score:", v_meas)
print("Adjusted Rand Score:", ari)
print("Adjusted Mutual Information Score:", ami)
评估指标结果(理论文章中提到的):
Jaccard 系数 (JC): 0.6958587915818059
Fowlkes and Mallows 指数 (FMI): 0.8208080729114153
Rand 指数 (RI): 0.8797315436241611
其他的聚类评估指标结果:
Homogeneity Score: 0.7514854021988338
Completeness Score: 0.7649861514489815
V-measure Score: 0.7581756800057784
Adjusted Rand Score: 0.7302382722834697
Adjusted Mutual Information Score: 0.7551191675800484
2、内部评价指标
# 聚类评估——内部评估(无真实标签)
# K均值-鸢尾花聚类
#!pip install plotly
import plotly.express as px
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Though the following import is not directly being used, it is required
from sklearn.cluster import KMeans
from sklearn import datasets
# 导入评估指标(理论文章中提到的)
import math
# 导入内部评价指标函数
from sklearn.metrics import davies_bouldin_score, calinski_harabasz_score, silhouette_score
from sklearn.metrics.pairwise import pairwise_distances
np.random.seed(5)
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = KMeans(n_clusters=3)
estimators.fit(X)
labels = estimators.labels_
# 创建DataFrame
df = pd.DataFrame(X[:, [3, 0, 2]], columns=["no1", "no2", "no3"])
df['species'] = labels
fig = px.scatter_3d(df, x="no1", y="no2", z="no3", color="species")
fig.show()
# --- 以下部分进行聚类评估 ---
# 定义计算 Dunn 指数的函数
def dunn_index(X, labels):
"""
计算 Dunn 指数:
DI = (簇间最小距离) / (簇内最大直径)
其中:
- 簇内直径:每个簇中任意两点之间的最大距离
- 簇间距离:任意两个不同簇之间点的最小距离
"""
unique_labels = np.unique(labels)
# 计算每个簇的直径(簇内最大距离)
diameters = []
for label in unique_labels:
cluster_points = X[labels == label]
if len(cluster_points) > 1:
distances = pairwise_distances(cluster_points)
diameters.append(np.max(distances))
else:
diameters.append(0)
max_diameter = np.max(diameters)
# 计算任意两个不同簇之间的最小距离
min_intercluster = np.inf
for i, label_i in enumerate(unique_labels):
for label_j in unique_labels[i+1:]:
cluster_i = X[labels == label_i]
cluster_j = X[labels == label_j]
distances = pairwise_distances(cluster_i, cluster_j)
min_dist = np.min(distances)
if min_dist < min_intercluster:
min_intercluster = min_dist
# 防止除以0的情况
if max_diameter == 0:
return np.inf
return min_intercluster / max_diameter
# 计算各项评估指标(理论文章中提到的内部评估方法)
# 1. Davies-Bouldin 指数 (DBI)
db_index = davies_bouldin_score(X, labels)
# 2. Calinski-Harabasz 指数 (CHI)
chi_index = calinski_harabasz_score(X, labels)
# 3. 轮廓系数 (SI)
si = silhouette_score(X, labels)
# 4. Dunn 指数 (DI)
dunn_idx = dunn_index(X, labels)
print("内部评价指标结果:")
print("Davies-Bouldin 指数 (DBI):", db_index)
print("Dunn 指数 (DI):", dunn_idx)
print("Calinski-Harabasz 指数 (CHI):", chi_index)
print("轮廓系数 (SI):", si)
内部评价指标结果:
Davies-Bouldin 指数 (DBI): 0.6619715465007465
Dunn 指数 (DI): 0.09880739332807607
Calinski-Harabasz 指数 (CHI): 561.62775662962
轮廓系数 (SI): 0.5528190123564095


















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









