







本文的理论部分:
目录
1、CountVectorizer——将文本数据转换为一个词频矩阵
一、朴素贝叶斯分类器——最小错误率决策
朴素贝叶斯分类器(Naive Bayes Classifier)是一种基于贝叶斯定理的简单而有效的概率分类算法。它特别适用于文本分类、垃圾邮件过滤、情感分析等任务。尽管它被称为“朴素”,它在很多应用中表现出了出色的效果。
朴素贝叶斯之所以“朴素”,是因为它假设特征之间是条件独立的,即在给定类别的情况下,每个特征是相互独立的。
根据特征的类型(如是否为离散型或连续型),朴素贝叶斯分类器可以使用不同的概率模型:
- 伯努利朴素贝叶斯(Bernoulli Naive Bayes):也用于离散特征,但假设每个特征都是一个二元变量(0或1),适合在文本分类中用来表示单词的出现与否。
- 多项式朴素贝叶斯(Multinomial Naive Bayes):用于离散特征,常用于文本分类和词袋模型,假设特征(如词频)在每个类别下服从多项分布。
- 高斯朴素贝叶斯(Gaussian Naive Bayes):用于连续特征,假设特征在每个类别条件下服从正态分布。
1、伯努利朴素贝叶斯——实例分析
(1)问题背景
我们有一个简单的文档数据集,每个文档属于两类之一:Positive(正面评论)或 Negative(负面评论)。每个文档会被表示为一组二元特征:每个特征表示某个特定的词是否出现在该文档中。
(2)数据集
| 文档 | 是否正面评论 |
|---|---|
| 我喜欢这部电影,剧情很棒 | 正面 |
| 这部电影很糟糕,完全浪费时间 | 负面 |
| 很高兴看到了这部电影,演技不错 | 正面 |
| 这电影真差劲,完全不值得一看 | 负面 |
| 电影很好,剧情很精彩,演员很棒 | 正面 |
| 我不喜欢这部电影,情节很无聊 | 负面 |
特征:我们关注的词汇包括 "电影"、"很好"、"糟糕"、"浪费"、"演技"、"差劲"。
每个文档会根据这些词汇是否出现,转化为一个二元特征向量。比如,假设词汇表是:["电影", "很好", "糟糕", "浪费", "演技", "差劲"],我们就可以为每个文档创建一个向量,表示这些词是否出现。
(3)示例数据集的特征向量
我喜欢这部电影,剧情很棒→ [1, 0, 0, 0, 0, 0]这部电影很糟糕,完全浪费时间→ [1, 0, 1, 1, 0, 1]很高兴看到了这部电影,演技不错→ [1, 0, 0, 0, 1, 0]这电影真差劲,完全不值得一看→ [1, 0, 1, 0, 0, 1]电影很好,剧情很精彩,演员很棒→ [1, 1, 0, 0, 0, 0]我不喜欢这部电影,情节很无聊→ [1, 0, 1, 1, 0, 1]
(4)步骤
- 准备数据:我们手动创建一个文本数据集,并将其转换为二元特征。
- 训练模型:使用
BernoulliNB来训练模型。 - 评估模型:测试模型在新数据上的表现。
(5)Python代码实现
import numpy as np
from sklearn.naive_bayes import BernoulliNB
from sklearn.metrics import accuracy_score
# 数据集
X_train = np.array([
[1, 0, 0, 0, 0, 0], # 我喜欢这部电影,剧情很棒
[1, 0, 1, 1, 0, 1], # 这部电影很糟糕,完全浪费时间
[1, 0, 0, 0, 1, 0], # 很高兴看到了这部电影,演技不错
[1, 0, 1, 0, 0, 1], # 这电影真差劲,完全不值得一看
[1, 1, 0, 0, 0, 0], # 电影很好,剧情很精彩,演员很棒
[1, 0, 1, 1, 0, 1], # 我不喜欢这部电影,情节很无聊
])
# 标签(1表示正面评论,0表示负面评论)
y_train = np.array([1, 0, 1, 0, 1, 0])
# 初始化伯努利朴素贝叶斯分类器
model = BernoulliNB()
# 训练模型
model.fit(X_train, y_train)
# 测试数据
X_test = np.array([
[1, 1, 0, 0, 0, 0], # 电影很好,值得推荐
[1, 0, 1, 1, 0, 1], # 电影真差劲
])
# 预测
y_pred = model.predict(X_test)
# 预测结果
print("预测结果:", y_pred)
print("预测标签: 1为正面评论,0为负面评论")
# 模型准确率(假设我们知道测试集的实际标签)
y_test = np.array([1, 0]) # 实际标签:正面、负面
accuracy = accuracy_score(y_test, y_pred)
print(f"预测准确率: {accuracy * 100:.2f}%")
结果为:
预测结果: [1 0]
预测标签: 1为正面评论,0为负面评论
预测准确率: 100.00%2、多项式朴素贝叶斯——实例分析
(1)问题背景
我们有一个简单的文本数据集,用于分类两类文本:正面 和 负面 评论。与 伯努利朴素贝叶斯(只考虑词是否出现)不同,多项式朴素贝叶斯 会考虑每个词汇在文档中的 出现次数。
(2)数据集
| 文档 | 标签 |
|---|---|
| 我喜欢这部电影,它非常有趣 | 正面 |
| 这部电影很糟糕,我不喜欢它 | 负面 |
| 很高兴看到这部电影,剧情非常精彩 | 正面 |
| 这电影真差劲,演员演技也差 | 负面 |
| 电影很好,导演也很棒 | 正面 |
| 我不喜欢这部电影,剧情太无聊了 | 负面 |
我们使用的特征包括:["电影", "喜欢", "糟糕", "有趣", "剧情", "导演", "差劲", "演员"]。
(3)特征向量化
每个文档会转化为一个特征向量,表示每个词汇在文档中出现的次数。例如:
我喜欢这部电影,这个电影非常有趣→ [2, 1, 0, 1, 0, 0, 0, 0]这部电影很糟糕,我不喜欢它→ [1, 1, 1, 0, 0, 0, 1, 0]
(4)Python代码实现
import jieba
import numpy as np
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import accuracy_score
# 中文分词函数
def chinese_tokenizer(text):
return jieba.lcut(text)
# 文档数据集
documents = [
"我喜欢这部电影,它非常有趣,剧情也非常有趣,演员也很有趣", # 正面
"这部电影很糟糕,我不喜欢它,其中的演员我也不喜欢", # 负面
"很高兴看到这部电影,剧情非常精彩,演员非常幽默", # 正面
"这电影真差劲,演员演技也差,导演也很糟糕,演员也糟糕", # 负面
"电影很好,导演也很棒,剧情有趣,演员很有趣", # 正面
"我不喜欢这部电影,剧情太无聊了,演员也很差劲" # 负面
]
# 标签(1表示正面评论,0表示负面评论)
labels = [1, 0, 1, 0, 1, 0]
# 手动指定特征词汇表
vocabulary = ['电影', '喜欢', '糟糕', '有趣', '剧情', '导演', '差劲', '演员']
# 使用 CountVectorizer 转换文本数据为词频特征矩阵,确保仅使用指定的词汇表,并使用自定义分词器
vectorizer = CountVectorizer(vocabulary=vocabulary, tokenizer=chinese_tokenizer)
X = vectorizer.fit_transform(documents)
# 打印词汇表和对应的词频特征矩阵
print("词汇表:", vectorizer.get_feature_names_out())
print("训练数据特征矩阵:\n", X.toarray())
# 初始化多项式朴素贝叶斯分类器
model = MultinomialNB()
# 训练模型
model.fit(X, labels)
# 测试数据
X_test = vectorizer.transform([
"这部电影我觉得很不错,剧情有趣,演员幽默", # 正面
"电影实在是太糟糕了,我不喜欢,演员也不有趣" # 负面
])
# 预测
y_pred = model.predict(X_test)
# 输出预测结果
print("预测结果:", y_pred)
print("预测标签: 1为正面评论,0为负面评论")
# 评估模型准确率(假设我们知道测试集的实际标签)
y_test = [1, 0] # 实际标签:正面、负面
accuracy = accuracy_score(y_test, y_pred)
print(f"预测准确率: {accuracy * 100:.2f}%")
输出结果:
词汇表: ['电影' '喜欢' '糟糕' '有趣' '剧情' '导演' '差劲' '演员']
训练数据特征矩阵:
[[1 1 0 3 1 0 0 1]
[1 2 1 0 0 0 0 1]
[1 0 0 0 1 0 0 1]
[1 0 2 0 0 1 1 2]
[1 0 0 2 1 1 0 1]
[1 1 0 0 1 0 1 1]]
预测结果: [1 0]
预测标签: 1为正面评论,0为负面评论
预测准确率: 100.00%jieba:在默认情况下,CountVectorizer 会尝试对文本进行空格分词,而中文文本没有明显的空格分隔,因此它无法正确处理中文词汇。
为了解决这个问题,我们需要对中文文本进行适当的分词,通常可以使用一些中文分词工具,比如 jieba。我们可以将中文文本先进行分词,再传递给 CountVectorizer,这样就能正确提取出词汇。
3、高斯朴素贝叶斯——实例分析
(1)预测鸢尾花(Iris)数据集的花卉种类问题描述
我们将使用著名的鸢尾花数据集(Iris dataset)。该数据集包含了 150 个样本,每个样本有 4 个特征,分别是:
- 花萼长度(sepal length)
- 花萼宽度(sepal width)
- 花瓣长度(petal length)
- 花瓣宽度(petal width)
这些特征用于预测鸢尾花的种类(Setosa、Versicolor、Virginica)。
(2)高斯朴素贝叶斯分类
我们将使用 sklearn 库中的 GaussianNB 来实现高斯朴素贝叶斯分类器。
(3)Python代码实现
# 导入相关库
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 1. 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y = iris.target # 标签:花卉种类(0, 1, 2表示Setosa, Versicolor, Virginica)
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 初始化高斯朴素贝叶斯分类器
model = GaussianNB()
# 4. 训练模型
model.fit(X_train, y_train)
# 5. 预测测试集
y_pred = model.predict(X_test)
# 6. 评估模型准确性
accuracy = accuracy_score(y_test, y_pred)
print(f"模型预测准确率: {accuracy * 100:.2f}%")
# 7. 打印预测结果(示例)
print("测试集真实标签:", y_test)
print("测试集预测标签:", y_pred)
输出结果为:
模型预测准确率: 97.78%
测试集真实标签: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
测试集预测标签: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 2 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]二、给不同的错误分类赋予不同的代价——最小风险决策
1、引入代价
在朴素贝叶斯分类器(Naive Bayes)中,通常我们处理的是标准的分类任务,其中每个分类错误的代价是相同的。然而,在某些实际问题中,不同类别的分类错误可能会带来不同的后果,这时我们需要为不同的分类错误设置不同的代价(即 代价敏感学习)。例如,在医疗诊断中,假阴性和假阳性可能会有不同的后果,因此我们需要为这些错误指定不同的代价。
(1)代价敏感学习
代价敏感学习的核心思想是:当分类器做出错误分类时,采用不同的代价来衡量错误的严重性。具体来说,我们通过 代价矩阵 来指定每种类型的错误分类的代价。在 sklearn 中,我们可以通过调整模型的 决策阈值 或直接通过 修改目标函数 来实现代价敏感学习。
(2)代价矩阵示例
假设有两个类:正类(class 1)和 负类(class 0),其中我们设定:
- 假阳性(将负类预测为正类)会有一个 高代价,因为可能导致错误的治疗或干预。
- 假阴性(将正类预测为负类)会有较低的代价,但仍然不可忽视。
我们可以设计一个 代价矩阵:
- 代价矩阵的行表示实际标签(0 或 1),列表示预测标签(0 或 1)。
- 例如,如果真实标签是负类(0),但是预测为正类(1),代价是 5(假阳性);如果真实标签是正类(1),但是预测为负类(0),代价是 1(假阴性)。
(3)实现代价敏感学习
对于高斯朴素贝叶斯,sklearn 的 GaussianNB 类本身并不直接支持代价敏感学习,但我们可以通过以下两种方式来实现代价敏感的分类:
- 手动调整阈值:改变决策阈值,使得模型对某些错误更加敏感。
- 使用代价矩阵调整预测结果:根据代价矩阵调整最终预测的标签。
下面我将展示如何在高斯朴素贝叶斯分类器中实现代价敏感学习的两个方法。
(4)示例 1:通过调整决策阈值来实现代价敏感学习
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix, accuracy_score
# 示例数据
X_train = np.array([[1, 2], [2, 3], [3, 4], [5, 6], [7, 8], [8, 9]])
y_train = np.array([0, 0, 1, 1, 1, 0]) # 类别0和1
X_test = np.array([[2, 3], [6, 7], [8, 9]])
y_test = np.array([0, 1, 0])
# 创建高斯朴素贝叶斯模型
model = GaussianNB()
# 训练模型
model.fit(X_train, y_train)
# 获取模型的预测概率
y_probs = model.predict_proba(X_test)
# 假设代价矩阵
# Cost Matrix: [ [0, 5], [1, 0] ]
# 假阳性 (FP) = 5, 假阴性 (FN) = 1
# 计算不同阈值下的代价
threshold = 0.7 # 假设我们设置阈值为 0.7
# 使用阈值做预测
y_pred = (y_probs[:, 1] > threshold).astype(int)
# 输出预测结果和混淆矩阵
print("预测标签:", y_pred)
print("实际标签:", y_test)
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
# 计算代价
cost = 0
cm = confusion_matrix(y_test, y_pred)
# cost = 假阳性代价 * FP + 假阴性代价 * FN
cost += 5 * cm[0, 1] # 假阳性
cost += 1 * cm[1, 0] # 假阴性
print(f"总代价: {cost}")
输出结果为:
预测标签: [0 1 0]
实际标签: [0 1 0]
混淆矩阵:
[[2 0]
[0 1]]
总代价: 0解释:
- 我们首先训练一个 高斯朴素贝叶斯 分类器。
- 然后,我们计算预测为每个类的 概率,而不是直接预测类别标签。这样可以更灵活地调整决策阈值。
- 假设我们设置一个 决策阈值
0.7,这意味着当某个文档被预测为正类的概率大于 0.7 时,我们就将其预测为正类。 - 最后,我们计算 混淆矩阵 和 代价,根据假阳性和假阴性的代价来评估模型的整体代价。
(5)示例 2:通过代价矩阵调整预测结果
如果我们不希望通过调整阈值来处理代价敏感性,也可以手动计算每种错误的代价,来选择使总代价最小化的预测结果。
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix
# 示例数据
X_train = np.array([[1, 2], [2, 3], [3, 4], [5, 6], [7, 8], [8, 9]])
y_train = np.array([0, 0, 1, 1, 1, 0]) # 类别0和1
X_test = np.array([[2, 3], [6, 7], [8, 9]])
y_test = np.array([0, 1, 0])
# 创建高斯朴素贝叶斯模型
model = GaussianNB()
# 训练模型
model.fit(X_train, y_train)
# 预测概率
y_probs = model.predict_proba(X_test)
# 假设代价矩阵
# Cost Matrix: [ [0, 5], [1, 0] ]
# 假阳性 (FP) = 5, 假阴性 (FN) = 1
# 假设我们使用预测概率和代价矩阵来做决策
cost = []
y_pred_cost_sensitive = []
for i in range(len(y_probs)):
# 计算假阳性和假阴性代价
fp_cost = y_probs[i, 1] * 5 # 预测为正类,但实际为负类
fn_cost = (1 - y_probs[i, 1]) * 1 # 预测为负类,但实际为正类
# 比较假阳性代价和假阴性代价
if fp_cost > fn_cost:
# 假阳性代价较高,倾向于预测为负类
y_pred_cost_sensitive.append(0)
else:
# 假阴性代价较高或两者相等,倾向于预测为正类
y_pred_cost_sensitive.append(1)
# 输出预测结果和混淆矩阵
print("预测标签:", y_pred_cost_sensitive)
print("实际标签:", y_test)
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred_cost_sensitive))
# 计算代价
cm = confusion_matrix(y_test, y_pred_cost_sensitive)
total_cost = 5 * cm[0, 1] + 1 * cm[1, 0] # 假阳性代价 * FP + 假阴性代价 * FN
print(f"总代价: {total_cost}")输出结果为:
预测标签: [1, 0, 0]
实际标签: [0 1 0]
混淆矩阵:
[[1 1]
[1 0]]
总代价: 6
解释:
y_probs[i, 1]表示对于第i个样本,预测为正类的概率。- 对于每个样本,我们根据 假阳性 和 假阴性 的概率计算相应的代价。
- 根据代价大小,我们选择代价最小的类别作为最终预测结果。
- 最后,我们计算总的 代价,并输出混淆矩阵。
总结
- 代价敏感学习 是指在模型训练和预测时考虑不同类型错误的代价。
- 在高斯朴素贝叶斯中,我们可以通过 调整决策阈值 或 根据代价矩阵调整预测结果 来实现代价敏感学习。
- 通过计算假阳性和假阴性的代价,并根据代价选择最优预测,可以有效减少高代价错误。
这种方法在一些特定场景下(如金融欺诈检测、医疗诊断等)非常有用,因这些场景中不同类型错误的代价差异很大。
2、引入拒识
(1)拒识(Rejection)概念
拒识(Rejection),又叫拒绝分类,是分类器在某些情况下不做出预测的策略。简单来说,就是在遇到一些不确定的样本时,分类器选择不做决策,而是将这些样本拒绝(即不分类)。拒识可以用于处理以下几种情况:
- 不确定性:某些样本对于分类器来说可能非常模糊,分类器不确定该将其归为哪个类别。
- 代价控制:在一些应用场景中,错误分类的代价非常高,因此,拒识可能是一种减少错误分类代价的策略。
(2)为什么要使用拒识?
- 错误代价太高:如果一个错误分类的代价太高,分类器可能会选择拒识某些样本,而不是冒着错误分类的风险。
- 不确定性很大:当模型对样本的预测概率接近时,拒识可以帮助减少错误的发生。例如,模型预测某个样本为正类的概率为 0.51,预测为负类的概率为 0.49,那么模型对于该样本的不确定性非常大,这时就可以选择拒识。
(3)拒识的代价
在引入拒识时,通常会有一个 拒识代价,这个代价一般设置为 低于错误分类代价,因为拒识意味着模型不做出决策,但也可以避免产生严重的错误分类。
- 拒识代价(Reject Cost):分类器不做预测时产生的代价。这个代价通常低于错误分类的代价,因为拒识避免了高代价错误的发生。
- 错误分类代价(Mistake Cost):分类器错误地分类样本所产生的代价。这个代价通常是通过代价矩阵设置的。
(4)拒识的实现
在朴素贝叶斯分类器中,我们可以通过概率来判断是否进行拒识。如果某个样本的预测正负概率接近,即差值的绝对值低于某个阈值,意味着模型对该样本的预测不确定,可以选择不做预测(拒识)。但我认为根据概率来拒识不如根据代价来拒识好,下面例子时根据代价进行拒识的,如果要想根据概率来拒识,分错不同类别的代价都设为1即可。
假设我们设置一个拒识的阈值,当模型预测两种类别的代价差值的绝对值低于这个阈值时,我们就拒绝该样本的分类,而不是做出预测。拒识代价通常会比错误分类代价要小,我们需要在分类决策过程中加入一个拒识阈值。
(5)Python代码实现
import numpy as np
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix
# 示例数据
X_train = np.array([[1, 2], [2, 3], [3, 4], [5, 6], [7, 8], [8, 9]])
y_train = np.array([0, 0, 1, 1, 1, 0]) # 类别0和1
X_test = np.array([[2, 3], [6, 7], [8, 9]])
y_test = np.array([0, 1, 0])
# 创建高斯朴素贝叶斯模型
model = GaussianNB()
# 训练模型
model.fit(X_train, y_train)
# 预测概率
y_probs = model.predict_proba(X_test)
# 假设代价矩阵
# Cost Matrix: [ [0, 5], [1, 0] ]
# 假阳性 (FP) = 5, 假阴性 (FN) = 1
# 拒识代价 (Reject Cost) = 0.5
# 设置拒识阈值和拒识代价
reject_threshold = 0.2 # 如果假阳性代价和假阴性代价的差异小于该阈值,则拒识
reject_cost = 0.5 # 拒识的代价小于错误分类的代价
# 假设我们使用预测概率和代价矩阵来做决策
cost = []
y_pred_cost_sensitive = []
for i in range(len(y_probs)):
# 计算假阳性和假阴性代价
fp_cost = y_probs[i, 1] * 5 # 预测为正类,但实际为负类
fn_cost = (1 - y_probs[i, 1]) * 1 # 预测为负类,但实际为正类
# 计算代价差异
cost_diff = abs(fp_cost - fn_cost)
if cost_diff < reject_threshold:
# 如果假阳性和假阴性代价的差异小于拒识阈值,则拒识
y_pred_cost_sensitive.append(-1) # -1表示拒识
cost.append(reject_cost) # 拒识代价
else:
# 比较假阳性代价和假阴性代价
if fp_cost > fn_cost:
# 假阳性代价较高,倾向于预测为负类
y_pred_cost_sensitive.append(0)
cost.append(fp_cost)
else:
# 假阴性代价较高或两者相等,倾向于预测为正类
y_pred_cost_sensitive.append(1)
cost.append(fn_cost)
# 输出预测结果和混淆矩阵
print("预测标签:", y_pred_cost_sensitive)
print("实际标签:", y_test)
print("混淆矩阵:")
print(confusion_matrix(y_test, [y if y != -1 else 0 for y in y_pred_cost_sensitive])) # 将拒识视为负类
# 计算总代价
total_cost = sum(cost)
print(f"总代价: {total_cost}")
三、高斯判别分析
高斯判别分析(Gaussian Discriminant Analysis,GDA)是一种用于分类的统计学方法,它基于贝叶斯决策理论,假设各类的样本数据服从高斯分布(正态分布)。它广泛应用于机器学习中的分类任务,尤其是在数据的分布特征和类别较为明确的情况下。
1、高斯判别分析的基本思想
GDA 的基本思想是根据给定的数据,通过对不同类别数据的概率模型进行建模,计算给定输入数据属于每个类别的概率,并根据最大概率原则进行分类。
(1)GDA的关键假设:
- 数据属于不同的类别:假设数据集有 K 个类别,且数据集中的每一类是通过高斯分布进行建模的。
- 每类的特征服从高斯分布:假设每个类别的特征(输入特征)服从多元高斯分布,每个类别有一个自己的均值向量和协方差矩阵。
- (这个并不是GDA的假设,而是线性判别分析LDA的假设)各类之间的数据服从独立性:在给定类别的情况下,各个特征之间是条件独立的。
(2)GDA的模型建立
-
训练阶段:
- 估计每个类别的均值向量
和协方差矩阵
。
- 估计每个类别的先验概率
,即每个类别在训练集中的出现频率。
- 估计每个类别的均值向量
-
推断阶段:
- 给定一个测试样本
,计算它属于每个类别的后验概率
,然后选择具有最大后验概率的类别作为预测类别。
- 给定一个测试样本
根据贝叶斯定理,后验概率为:
其中:
是类别
的条件概率密度,假设为高斯分布
。
是所有类别的联合概率密度。
2、GDA模型建立步骤
(1)高斯分布假设
对每个类别,假设其特征向量 服从多元高斯分布。对于类别
,它的条件概率密度函数为:
其中:
是特征空间的维度。
(2)先验概率和后验概率
- 先验概率
- 后验概率
(3)分类决策
在推断阶段,我们计算每个类别的后验概率 ,并选择具有最大后验概率的类别作为预测结果:
在实际计算中,由于分母 对所有类别是常数,通常不需要计算,优化目标变成最大化:
即最大化:
(4)简化的判别函数
通过对数变换,判别函数可以简化为:
(5)当协方差矩阵相同的情况(LDA)
如果我们进一步假设所有类别的协方差矩阵相同,即 ,那么 GDA 就退化为线性判别分析(Linear Discriminant Analysis,LDA)。在这种情况下,判别函数的决策边界是一个超平面,GDA 的分类规则变得更加简单。
3、高斯判别分析的优缺点
优点:
- 简单易懂:基于统计学原理,理论基础扎实。
- 计算高效:对于较小规模的数据集,可以通过直接估计均值和协方差矩阵来获得有效的分类模型。
- 灵活性高:能够处理不同类别之间的协方差差异。
缺点:
- 高斯分布假设:如果数据的实际分布与高斯分布相差较大,GDA的效果可能不好。例如,数据可能是多模态的或非对称的。
- 对协方差矩阵的依赖:GDA 假设每个类别的数据具有固定的协方差矩阵(对于 LDA),否则需要估计复杂的协方差矩阵,这可能导致过拟合,尤其是在数据较少时。
- 计算复杂度较高:对于高维数据,计算协方差矩阵的逆矩阵和行列式可能会很耗时,特别是在数据维度很大时。
4、总结
高斯判别分析是基于高斯分布假设的分类方法,它通过建立类别条件概率分布来做出分类决策。其基本假设是每个类别的特征服从高斯分布,且各类别之间的数据是独立的。虽然它在许多场景下表现良好,但在数据不符合高斯分布假设的情况下,它可能会表现不佳。
5、Python代码实现
在sklearn中只有LDA和QDA的类,没有GDA的类,所以要自己建立GDA的类。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成一个二分类数据集
X, y = make_classification(n_samples=100, n_features=2, n_classes=2,
n_informative=2, n_redundant=0, n_repeated=0,
random_state=42)
# 拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 高斯判别分析(GDA)模型
class GaussianDiscriminantAnalysis:
def fit(self, X, y):
self.classes = np.unique(y) # 获得类别标签
self.priors = {} # 类别的先验概率
self.means = {} # 各类别的均值向量
self.covariances = {} # 各类别的协方差矩阵
# 对每一个类别进行建模
for c in self.classes:
# 取出类别 c 的样本
X_c = X[y == c]
# 计算均值向量
self.means[c] = np.mean(X_c, axis=0)
# 计算协方差矩阵
self.covariances[c] = np.cov(X_c, rowvar=False)
# 计算先验概率 P(C_k)
self.priors[c] = len(X_c) / len(X)
def predict(self, X):
# 对每个样本计算后验概率
predictions = []
for x in X:
posteriors = []
for c in self.classes:
# 计算 P(x | C_k) 使用多元高斯分布公式
mean = self.means[c]
covariance = self.covariances[c]
prior = self.priors[c]
# 多元高斯分布的概率密度函数
d = len(x) # 特征维度
coeff = 1 / ((2 * np.pi) ** (d / 2) * np.linalg.det(covariance) ** 0.5)
exp_term = np.exp(-0.5 * (x - mean).T @ np.linalg.inv(covariance) @ (x - mean))
likelihood = coeff * exp_term
posterior = likelihood * prior
posteriors.append(posterior)
# 选择最大后验概率的类别
predictions.append(np.argmax(posteriors))
return np.array(predictions)
# 实例化并训练模型
gda = GaussianDiscriminantAnalysis()
gda.fit(X_train, y_train)
# 预测
y_pred = gda.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 可视化决策边界
xx, yy = np.meshgrid(np.linspace(X[:, 0].min(), X[:, 0].max(), 100),
np.linspace(X[:, 1].min(), X[:, 1].max(), 100))
Z = gda.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.title("Gaussian Discriminant Analysis Decision Boundary")
plt.show()
输出结果为:(下面是改变随机种子的多次输出结果)《关于上段代码中的可视化决策边界分析见附录2》
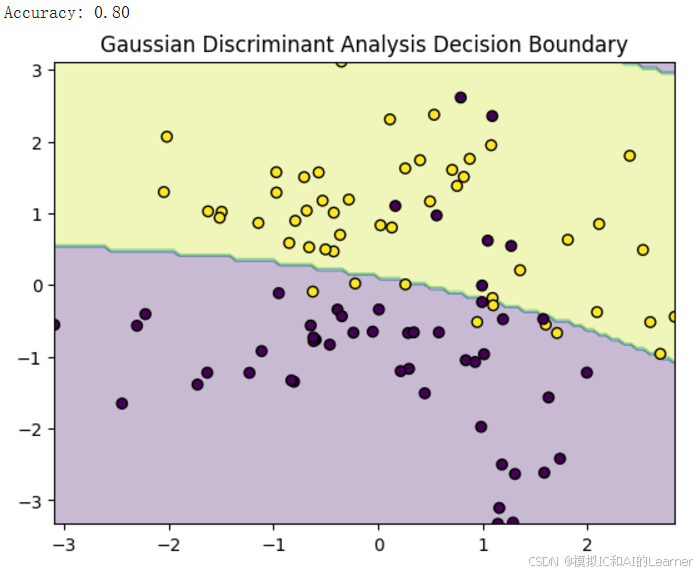
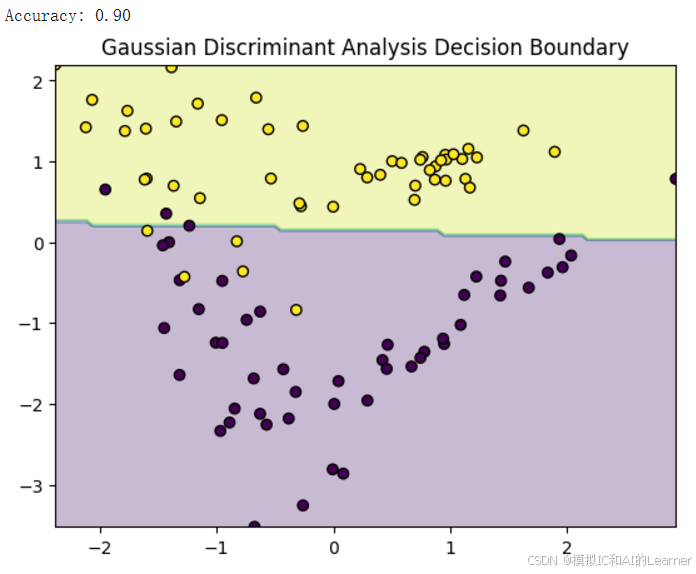
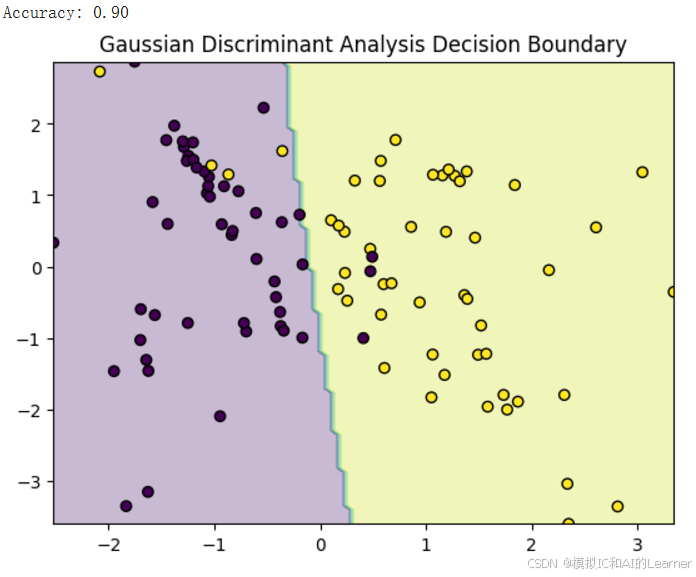
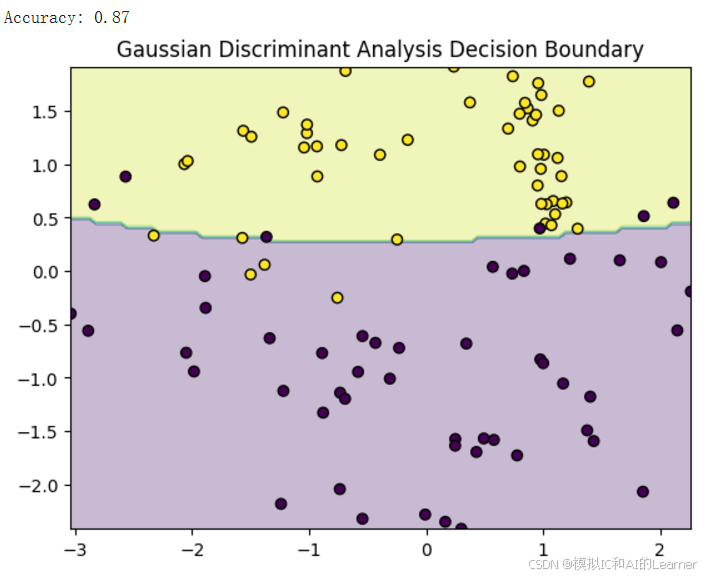
6、加入收缩估计(正则化)
(1)在QDA中加入收缩估计
在两分类的情况下,也就是QDA的情况,sklearn中有QDA的模块,收缩估计就是调节参数reg_param,对于这个参数,他就是对协方差矩阵进行的调节,调节方式如下:
通过将S2转换为
S2 = (1 - reg_param) * S2 + reg_param * np.eye(n_features)来规范化每个类的协方差估计,其中S2对应于给定类的scaling_属性。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
# 生成一个简单的二分类数据集
X, y = make_classification(n_samples=500, n_features=2, n_classes=2, n_informative=2,
n_redundant=0, n_clusters_per_class=1, random_state=42)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用 QDA 模型,并加入收缩估计(正则化)
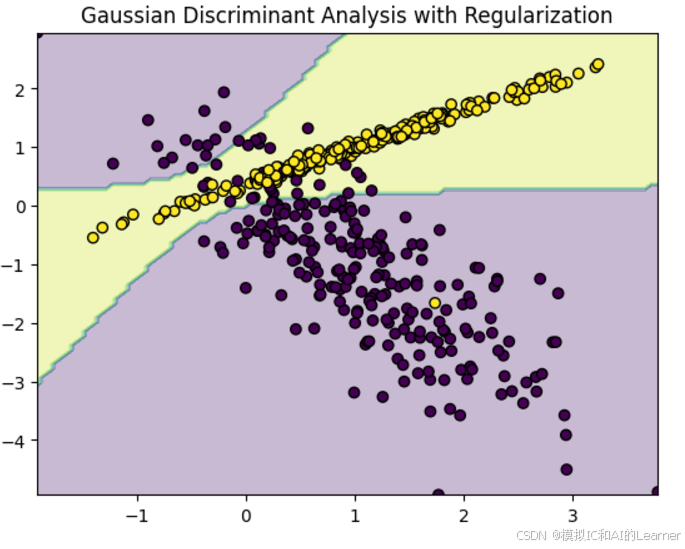
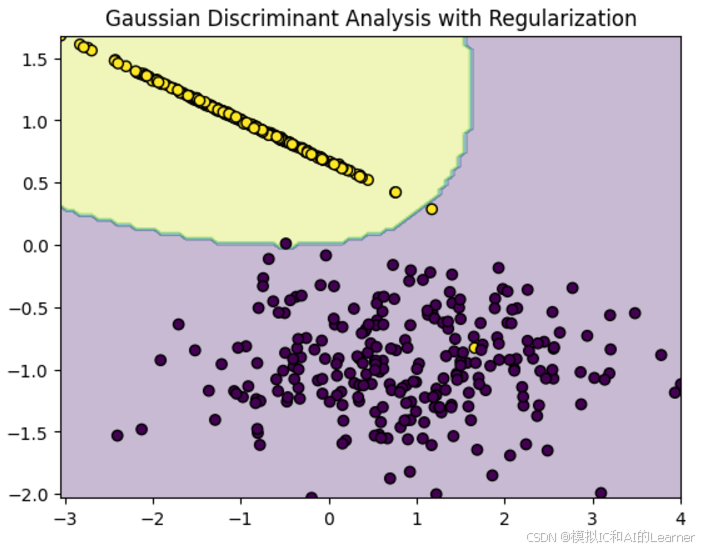
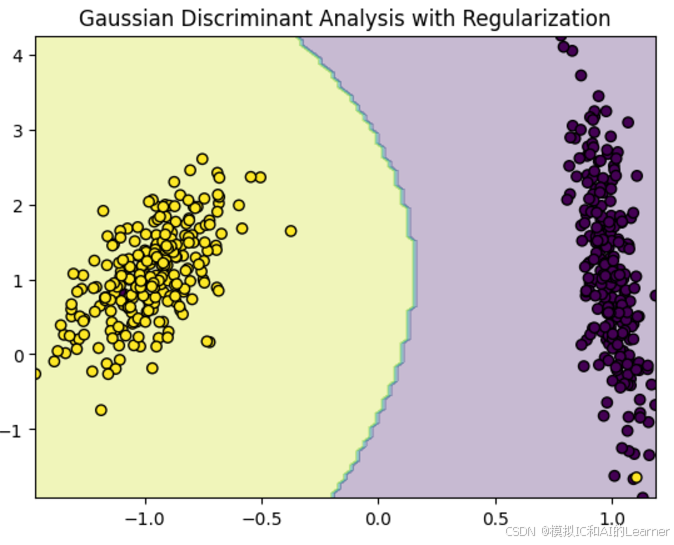
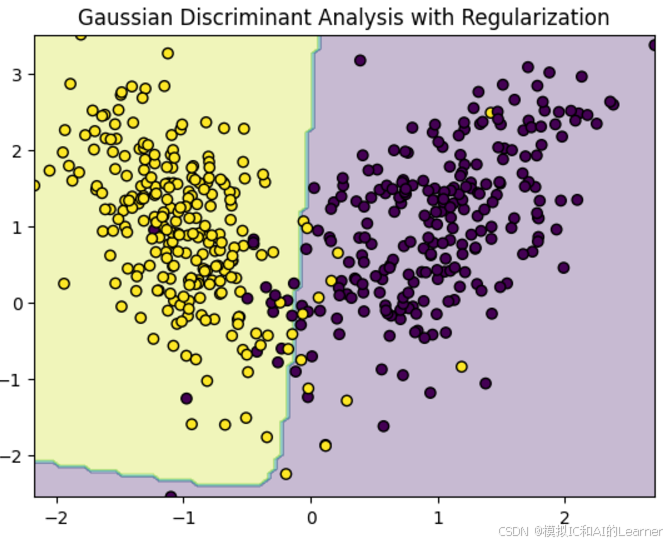
qda = QuadraticDiscriminantAnalysis(reg_param=0.1) # 设置收缩估计的强度,0.1为示例值
qda.fit(X_train, y_train)
# 创建网格用于绘制决策边界
xx, yy = np.meshgrid(np.linspace(X[:, 0].min(), X[:, 0].max(), 100),
np.linspace(X[:, 1].min(), X[:, 1].max(), 100))
# 预测每个网格点的类别
Z = qda.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.title("Gaussian Discriminant Analysis with Regularization")
plt.show()
输出结果为:(下面不同的图为改变随机数从而改变随机生成的类别)
(2)在GDA中加入收缩估计
由于sklearn中没有GDA的类,所以要自己建立。在类中加入收缩估计参数。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成一个二分类数据集
X, y = make_classification(n_samples=100, n_features=2, n_classes=2,
n_informative=2, n_redundant=0, n_repeated=0,
random_state=42)
# 拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 高斯判别分析(GDA)模型
class GaussianDiscriminantAnalysis:
def __init__(self, shrinkage=0.1):
self.shrinkage = shrinkage # 收缩参数,默认值为0.1
def fit(self, X, y):
self.classes = np.unique(y) # 获得类别标签
self.priors = {} # 类别的先验概率
self.means = {} # 各类别的均值向量
self.covariances = {} # 各类别的协方差矩阵
self.global_cov = np.cov(X, rowvar=False) # 全局协方差矩阵
# 对每一个类别进行建模
for c in self.classes:
# 取出类别 c 的样本
X_c = X[y == c]
# 计算均值向量
self.means[c] = np.mean(X_c, axis=0)
# 计算协方差矩阵
covariance = np.cov(X_c, rowvar=False)
# 应用收缩估计:将协方差矩阵收缩向全局协方差矩阵
self.covariances[c] = (1 - self.shrinkage) * covariance + self.shrinkage * self.global_cov
# 计算先验概率 P(C_k)
self.priors[c] = len(X_c) / len(X)
def predict(self, X):
predictions = []
for x in X:
posteriors = []
for c in self.classes:
# 计算 P(x | C_k) 使用多元高斯分布公式
mean = self.means[c]
covariance = self.covariances[c]
prior = self.priors[c]
# 多元高斯分布的概率密度函数
d = len(x) # 特征维度
coeff = 1 / ((2 * np.pi) ** (d / 2) * np.linalg.det(covariance) ** 0.5)
exp_term = np.exp(-0.5 * (x - mean).T @ np.linalg.inv(covariance) @ (x - mean))
likelihood = coeff * exp_term
posterior = likelihood * prior
posteriors.append(posterior)
# 选择最大后验概率的类别
predictions.append(np.argmax(posteriors))
return np.array(predictions)
# 实例化并训练模型
gda = GaussianDiscriminantAnalysis(shrinkage=0.1) # 设置收缩参数为0.1
gda.fit(X_train, y_train)
# 预测
y_pred = gda.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy with shrinkage: {accuracy:.2f}")
# 可视化决策边界
xx, yy = np.meshgrid(np.linspace(X[:, 0].min(), X[:, 0].max(), 100),
np.linspace(X[:, 1].min(), X[:, 1].max(), 100))
Z = gda.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.title("Gaussian Discriminant Analysis with Shrinkage Decision Boundary")
plt.show()
输出结果为:(下面不同的图为改变随机数从而改变随机生成的类别)
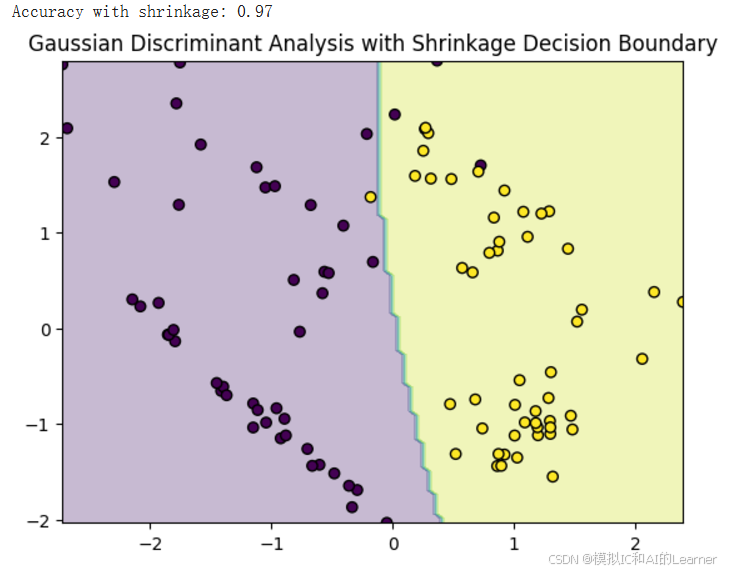
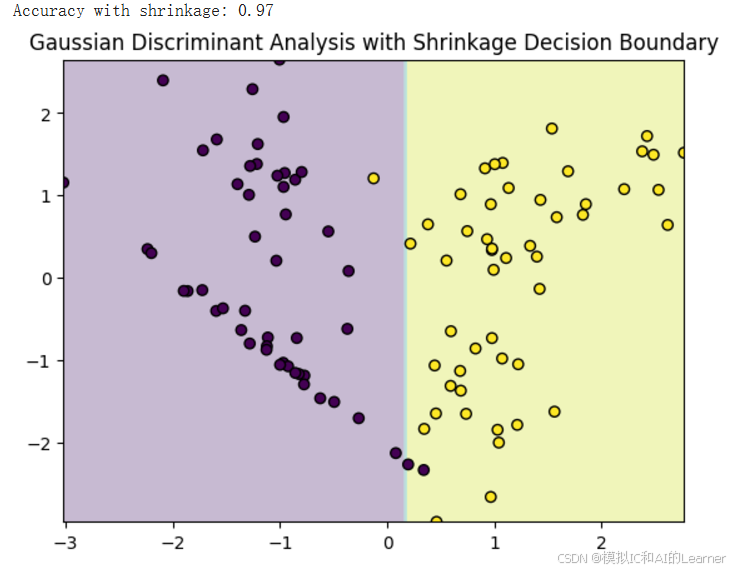
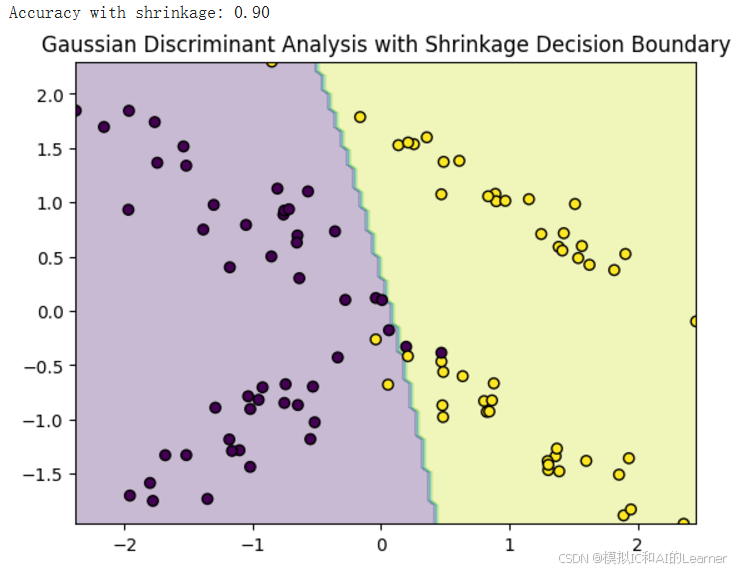
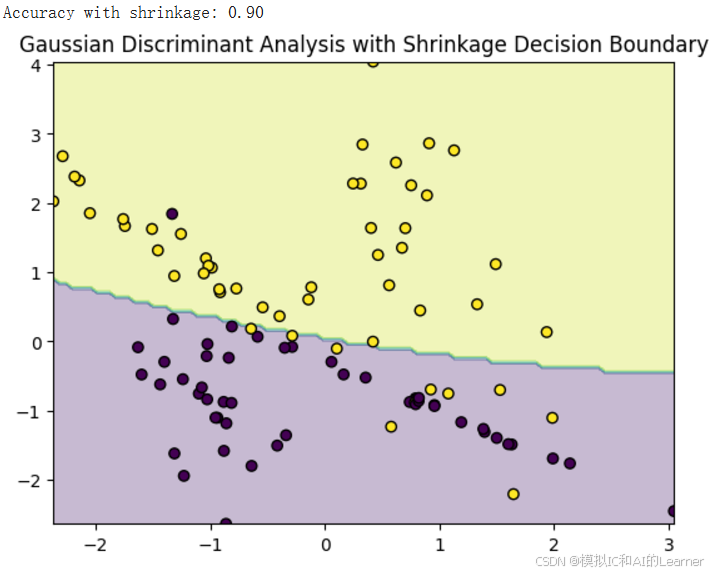
决策面明显比为收缩估计时的更加光滑了。
四、LDA,QDA,GDA的区别与联系
线性判别分析(LDA)、二次判别分析(QDA) 和 高斯判别分析(GDA) 都是基于贝叶斯理论的分类方法,它们的目标都是根据已知的训练数据集,学会如何将新样本分类到不同的类别中。然而,它们在模型假设和分类决策上存在一些关键差异。
1、高斯判别分析(GDA)
高斯判别分析假设每个类别的样本数据都服从 高斯分布,即每个类别的特征向量是一个高斯分布(也叫正态分布)。GDA 允许每个类别有不同的协方差矩阵。
假设:
- 每个类别的样本是独立同分布的(i.i.d)。
- 每个类别的样本服从 多元高斯分布,且各类别可能具有不同的 协方差矩阵。
- 各类别的 先验概率 是根据训练数据中每个类别的出现频率来估计的。
特点:
- 由于每个类别可以有不同的协方差矩阵,GDA 能够处理类别间数据的相关性。
- 分类规则是基于贝叶斯定理,通过计算每个类别的后验概率来进行分类。
数学推导:
- 对于每个类别
- 使用高斯分布的概率密度函数来计算
,然后结合先验概率
- 选择后验概率最大的类别作为预测类别。
适用场景:
- 当不同类别之间的数据分布有不同的形状时,GDA 能够提供较好的分类性能。
2、线性判别分析(LDA)
线性判别分析是高斯判别分析的简化版本,它对 GDA 做出了一个假设:所有类别的数据都服从 相同的协方差矩阵。
假设:
- 每个类别的样本是独立同分布的(i.i.d)。
- 每个类别的样本服从 多元高斯分布,但 所有类别的协方差矩阵是相同的,即
。
- 类别之间的协方差相同意味着它们具有相同的 形状,只是 均值 不同。
特点:
- 由于假设所有类别共享同一个协方差矩阵,LDA 本质上是将类别之间的决策边界建模为 线性 的,即每两个类别之间的决策边界是一个 超平面。
- LDA 主要依赖于类别的 均值向量 和共享的协方差矩阵来进行分类。
数学推导:
- 对每个类别
- 由于所有类别有相同的协方差矩阵
,LDA 使用 类间散度矩阵 和 类内散度矩阵 来计算最优的分类超平面。
- 通过最大化类间散度和最小化类内散度,找到一个最优的线性决策面。
适用场景:
- 当类别间的数据有相似的方差,且数据点大致呈现线性分布时,LDA 是一个高效的分类方法。
3、二次判别分析(QDA)
二次判别分析是对高斯判别分析的一个扩展,它允许每个类别有 不同的协方差矩阵,但与 GDA 不同的是,QDA 的决策边界通常是 二次曲线(即二次多项式)。
假设:
- 每个类别的样本是独立同分布的(i.i.d)。
- 每个类别的样本服从 多元高斯分布,且每个类别有自己独立的 协方差矩阵(即每个类别可以有不同的形状)。
- 类别之间的协方差矩阵 不相同,这允许每个类别具有不同的方差和相关性。
特点:
- 由于每个类别有不同的协方差矩阵,QDA 可以处理每个类别不同的 形状 和 方向,因此其决策边界是 二次曲线。
- 分类决策也是基于贝叶斯定理,计算每个类别的后验概率,并选择最大后验概率的类别。
数学推导:
- 对每个类别
- 使用多元高斯分布的概率密度函数计算
- 选择后验概率最大的类别进行分类。由于每个类别有不同的协方差矩阵,因此其决策边界是二次的。
适用场景:
- QDA 适用于类别之间的协方差差异较大,数据分布呈现 非线性 时。例如,当数据呈现椭圆或其他非线性形状时,QDA 可能表现得比 LDA 更好。
4、三者决策边界的区别
LDA决策边界:
- LDA的决策边界是线性的。由于所有类别的协方差矩阵相同,决策边界可以表示为一个 超平面,即一个低维空间中的线性面(对于二维数据就是一条直线)。
- 决策边界的位置由类别的均值向量
QDA决策边界:
- QDA的决策边界是二次曲线。由于每个类别有不同的协方差矩阵,决策边界通常是 二次方程 的解,表现为椭圆、抛物线或其他形式的曲线(具体形式依赖于协方差矩阵的特征)。
- 这些决策边界可以是 非线性的,且其形状与类别的协方差矩阵密切相关。
GDA决策边界:
- GDA的决策边界是二次曲线。与 QDA 相似,GDA 允许每个类别有不同的协方差矩阵,这使得决策边界成为 非线性 的。通常是一个二次方程,表示一个 二次曲线,其形状由类别的均值向量和协方差矩阵的关系决定。
- 如果协方差矩阵不同,则决策边界的形状通常是一个 二次曲线(例如椭圆、抛物线、双曲线等)。
QDA决策边界与GDA决策边界的联系:当只有两类时,GDA与QDA没有区别。
5、比较总结:
| 特性 | LDA | GDA | QDA |
|---|---|---|---|
| 协方差矩阵假设 | 所有类别共享相同的协方差矩阵 | 每个类别有独立的协方差矩阵 | 每个类别有独立的协方差矩阵 |
| 决策边界 | 线性决策边界 | 根据不同类别的协方差矩阵,可能为非线性决策边界 | 二次决策边界,通常为二次曲线 |
| 计算复杂度 | 较低,计算量较小 | 较高,需要计算每个类别的协方差矩阵 | 较高,需要计算每个类别的协方差矩阵 |
| 适用场景 | 类别之间数据呈现相似的协方差和线性分布 | 类别之间的协方差不同,数据可能是非线性分布 | 类别之间协方差差异较大,数据呈现非线性形状 |
| 分类效果 | 适合类别分布线性且协方差相同的情况 | 可以处理类别间不同的相关性,效果较好 | 适合类别间差异较大的情况,效果较好 |
- LDA 适用于类别之间数据的方差相似且数据呈现线性分布的情况,使用 相同的协方差矩阵。
- GDA 适用于类别之间具有不同方差和相关性的情况,但假设每个类别的样本服从 高斯分布,且 协方差矩阵不同。
- QDA 是 GDA 的一种扩展,假设每个类别有不同的协方差矩阵,因此能够捕捉类别间更复杂的差异,决策边界为 二次曲线。
6、LDA与QDA的Python代码实现
(1)LDA在sklearn中
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
y = np.array([1, 1, 1, 2, 2, 2])
clf = LinearDiscriminantAnalysis()
clf.fit(X, y)
print(clf.predict([[-0.8, -1]]))输出为:
[1](2)QDA在sklearn中
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
y = np.array([1, 1, 1, 2, 2, 2])
clf = QuadraticDiscriminantAnalysis()
clf.fit(X, y)
print(clf.predict([[-0.8, -1]]))输出为:
[1]附录
1、CountVectorizer——将文本数据转换为一个词频矩阵
CountVectorizer 是 sklearn 中用于文本数据预处理的工具,它将文本数据转换为一个 词频矩阵,用于训练机器学习模型。CountVectorizer 实现了文本的 词袋模型(Bag of Words, BoW),它将文本中的词语转换为一个 特征矩阵,矩阵的每一行表示一个文档,每一列表示一个词,矩阵中的每个值表示该词在该文档中的出现次数。
(1)CountVectorizer 工作原理
CountVectorizer 主要通过以下几个步骤将文本数据转换为数值型的特征矩阵:
- 分词:把文本拆分成单词(或称为词语)。
- 去除停用词:停用词是指一些没有实质意义的常见词汇(如“的”、“和”等),可以在某些场景下去除。
- 构建词汇表:从所有文本中提取出一个所有唯一词汇的集合(即词汇表),并为每个词汇分配一个唯一的编号。
- 词频计数:统计每个词汇在每篇文档中出现的次数,得到一个 词频矩阵。
(2)基本用法
from sklearn.feature_extraction.text import CountVectorizer
# 示例文档
documents = ["我 爱 编程", "编程 很 有趣", "我 爱 很多 编程"]
# 初始化 CountVectorizer
vectorizer = CountVectorizer()
# 拟合并转换文档数据为特征矩阵
X = vectorizer.fit_transform(documents)
# 输出特征矩阵
print(X.toarray())
# 输出词汇表
print(vectorizer.get_feature_names_out())
(3)输出解释
-
X.toarray():输出的是 词频矩阵。每一行对应一个文档,每一列对应一个词汇,矩阵的每个元素表示该文档中该词汇的出现次数。假设输出的词频矩阵如下:
[[1 1 1 0 0 1] [0 1 1 1 1 0] [1 1 1 1 0 1]]这表示:
- 文档 1(“我 爱 编程”)中,词汇“我”出现 1 次,“爱”出现 1 次,“编程”出现 1 次,其他词汇没有出现。
- 文档 2(“编程 很 有趣”)中,词汇“编程”出现 1 次,“很”出现 1 次,“有趣”出现 1 次,其他词汇没有出现。
- 文档 3(“我 爱 很多 编程”)中,词汇“我”出现 1 次,“爱”出现 1 次,“编程”出现 1 次,“很多”出现 1 次,其他词汇没有出现。
-
vectorizer.get_feature_names_out():输出词汇表,即所有文档中出现的唯一词汇集合。在上述示例中,假设词汇表为:['很', '爱', '编程', '有趣', '我', '很多']每个词汇的索引会与词频矩阵中的列顺序相对应,例如:
- 索引 0 对应词汇
'很' - 索引 1 对应词汇
'爱' - 索引 2 对应词汇
'编程' - 索引 3 对应词汇
'有趣' - 索引 4 对应词汇
'我' - 索引 5 对应词汇
'很多'
- 索引 0 对应词汇
(4)CountVectorizer 的参数详解
CountVectorizer 提供了很多可以自定义的参数,用于调整文本数据处理的细节。以下是一些常用的参数:
1. stop_words
- 说明:指定要去除的停用词,可以设置为
'english'(去除英语停用词),也可以传入一个列表,指定自己的停用词。 - 示例:
vectorizer = CountVectorizer(stop_words='english')
2. ngram_range
- 说明:指定生成的词组范围,可以是一个元组
(min_n, max_n),min_n和max_n分别表示最小和最大 n-gram 的长度。 - 示例:
vectorizer = CountVectorizer(ngram_range=(1, 2)) # 生成 1-gram 和 2-gram(即单词和连续两词组合)
3. max_features
- 说明:指定构建词汇表时最多保留的特征数,即保留频率最高的
max_features个词汇,其他的将被忽略。 - 示例:
vectorizer = CountVectorizer(max_features=10) # 只保留频率最高的 10 个词
4. min_df 和 max_df
- 说明:
min_df:指定词汇在文档中出现的最小频率,只有出现频率大于或等于min_df的词汇才会被考虑。max_df:指定词汇在文档中出现的最大频率,只有出现频率小于或等于max_df的词汇才会被考虑。
- 示例:
vectorizer = CountVectorizer(min_df=2, max_df=0.8) # 只考虑出现至少 2 次且最多出现在 80% 文档中的词汇
5. tokenizer
- 说明:用于指定自定义的分词器。默认情况下,
CountVectorizer会使用正则表达式(\b\w+\b)来分词,你也可以传入一个函数来实现自定义的分词逻辑。 - 示例:
def custom_tokenizer(text): return text.split() # 例如简单的按空格分词 vectorizer = CountVectorizer(tokenizer=custom_tokenizer)
6. lowercase
- 说明:是否将所有文本转换为小写。默认值为
True,即将所有文本转换为小写。 - 示例:
vectorizer = CountVectorizer(lowercase=False) # 不进行小写化
7. analyzer
- 说明:指定文本预处理的级别。可以选择:
'word':按词处理(默认)。'char':按字符处理。- 自定义函数:你可以提供一个函数,对文本进行更复杂的预处理(如分句、分词等)。
- 示例:
vectorizer = CountVectorizer(analyzer='char') # 按字符生成特征
8. max_features
- 说明:限制词汇表中的最大特征数量,优先保留出现频率最高的特征。
- 示例:
vectorizer = CountVectorizer(max_features=5) # 只保留出现频率最高的 5 个词
(5)CountVectorizer 的应用场景
- 文本分类:例如垃圾邮件分类、情感分析、新闻分类等。
- 特征工程:在自然语言处理(NLP)任务中,通常将
CountVectorizer作为特征提取的工具,帮助将文本转化为可供机器学习模型使用的数值数据。 - 信息检索:在搜索引擎中,词频矩阵被用于评估文本的相似度。
(6)总结
CountVectorizer是一个非常重要的文本特征提取工具,它将文本转换为机器学习模型可以处理的数值特征矩阵。- 它的核心思想是 词袋模型,通过统计词频来表示文本。
CountVectorizer提供了丰富的参数设置,允许你定制分词、停用词过滤、n-gram 提取等操作,从而更好地处理文本数据。
2、可视化决策边界部分代码详细分析
# 可视化决策边界
xx, yy = np.meshgrid(np.linspace(X[:, 0].min(), X[:, 0].max(), 100),
np.linspace(X[:, 1].min(), X[:, 1].max(), 100))
Z = gda.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.title("Gaussian Discriminant Analysis Decision Boundary")
plt.show()在这段代码中,我们的目标是通过 高斯判别分析(GDA) 可视化 决策边界,并展示分类结果。
(1)创建网格点 (xx, yy)
xx, yy = np.meshgrid(np.linspace(X[:, 0].min(), X[:, 0].max(), 100),
np.linspace(X[:, 1].min(), X[:, 1].max(), 100))
-
np.linspace(X[:, 0].min(), X[:, 0].max(), 100):- 这是生成一个从数据集 X 中第一个特征(
X[:, 0])的最小值到最大值之间的 100个等间距的值,类似于构造一个范围为[min(X[:, 0]), max(X[:, 0])]的 线性间隔。 - 也就是说,这一步产生了 100 个点来覆盖特征空间的 横坐标范围。
- 这是生成一个从数据集 X 中第一个特征(
-
np.linspace(X[:, 1].min(), X[:, 1].max(), 100):- 类似的操作,这一行生成了第二个特征(
X[:, 1])的 100个等间距 点,覆盖纵坐标的范围。
- 类似的操作,这一行生成了第二个特征(
-
np.meshgrid:- 这个函数通过输入两个 1D 数组(
xx和yy)生成一个 二维网格。它将横坐标(xx)与纵坐标(yy)相结合,创建出一个 2D 的网格,方便我们在这个网格上进行预测,得到分类结果。 xx和yy是 网格的坐标矩阵,它们分别对应每个点的 x 和 y 坐标。
- 这个函数通过输入两个 1D 数组(
(2)预测网格点的分类标签 (Z)
Z = gda.predict(np.c_[xx.ravel(), yy.ravel()])
-
np.c_[xx.ravel(), yy.ravel()]:xx.ravel()和yy.ravel()将xx和yy矩阵展平为一维数组。np.c_是 NumPy 的连接操作符,用来按列连接数组。这里的操作是将xx和yy展平后的 1D 数组合并成一个 N x 2 的二维数组,其中每一行代表一个网格点的[x, y]坐标。- 也就是,我们将整个网格上的所有点平铺成了一个二维数组,用于后续的分类预测。
-
gda.predict(...):gda是训练好的 高斯判别分析模型。调用predict()方法对网格上的每个点进行分类预测。Z是一个 包含预测类别标签 的数组,形状与网格的形状相同,每个元素是该网格点属于某个类别的预测结果。
(3)调整 Z 的形状
Z = Z.reshape(xx.shape)
Z.reshape(xx.shape):- 这里,
Z是一个一维的预测结果数组,它的长度等于网格点的数量(即 100 * 100 = 10000)。但我们需要将Z重新调整为与网格xx和yy相同的形状,这样才能正确地将预测结果映射到网格上的每个点。 xx.shape返回网格xx的形状((100, 100)),也就是 100行 100列,因此Z的形状将变成(100, 100),和网格一致。
- 这里,
(4)绘制决策边界 (contourf)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.contourf(xx, yy, Z, alpha=0.3):- 这里使用了
contourf方法,绘制 等高线填充图,显示分类的决策边界。 xx和yy是网格的坐标,而Z是每个网格点的预测类别。Z作为 类别标签 被映射到颜色上,contourf将这些标签用不同的颜色填充在对应的区域。alpha=0.3控制填充的透明度,透明度设置为 0.3 使得决策边界区域呈现半透明状态,避免遮挡其他数据点的可见性。
- 这里使用了
(5)绘制样本数据点
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o'):X[:, 0]和X[:, 1]是样本数据集 X 的第 1 和第 2 特征,分别对应 x 和 y 坐标。c=y将样本的类别标签(y)映射到颜色上,使得不同类别的点显示为不同的颜色。edgecolors='k'设置点的边框颜色为黑色('k'代表黑色)。marker='o'设置点的形状为圆形。
(6)显示图表标题并展示图像
plt.title("Gaussian Discriminant Analysis Decision Boundary")
plt.show()
plt.title("Gaussian Discriminant Analysis Decision Boundary") plt.show()
plt.title("Gaussian Discriminant Analysis Decision Boundary"):设置图表的标题为 "Gaussian Discriminant Analysis Decision Boundary"。plt.show():显示绘制好的图像。
(7)整体流程总结:
- 网格生成:我们在特征空间上创建一个规则的二维网格,覆盖了数据集的整个范围。
- 预测:通过 GDA 模型对网格上的每个点进行分类,得到每个点的类别标签。
- 决策边界可视化:使用
contourf绘制决策边界,将预测结果映射为不同的颜色区域。 - 数据点显示:通过
scatter绘制数据点,使用不同的颜色表示不同的类别。 - 图表展示:添加标题并展示最终的可视化图像,便于分析模型的分类效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









