







 本文探讨了在深度学习中如何控制生成对象,主要介绍Conditional GAN在Text-to-Image、image-to-image、patch GAN和speech enhancement、video generation等场景的应用。通过改变Discriminator的输入实现条件生成,解决了传统方法的局限性,增强了生成效果。
本文探讨了在深度学习中如何控制生成对象,主要介绍Conditional GAN在Text-to-Image、image-to-image、patch GAN和speech enhancement、video generation等场景的应用。通过改变Discriminator的输入实现条件生成,解决了传统方法的局限性,增强了生成效果。
本节考虑如何控制生成对象。将GAN变为Conditional GAN,两者的Generator是相同的,不同的是Discriminator。
Text-to-Image
传统的做法:如下图所示,但是如果训练的图片是多个角度的,这样机器两边都学习到就会产生不好的结果,让大家看不出来像什么。

利用GAN去做:存在的问题是discriminator只会判断图片是否清晰是否真实,而无法按条件生成想要的图片。
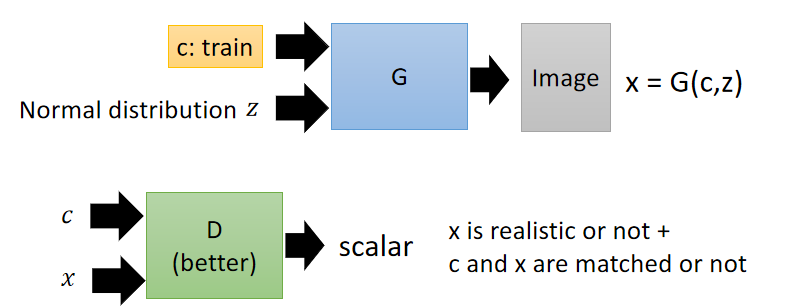
最后用到Conditional GAN:不改变generator的部分,只改变discriminator的部分,给discriminator两个输入,一个是条件,一个是对象
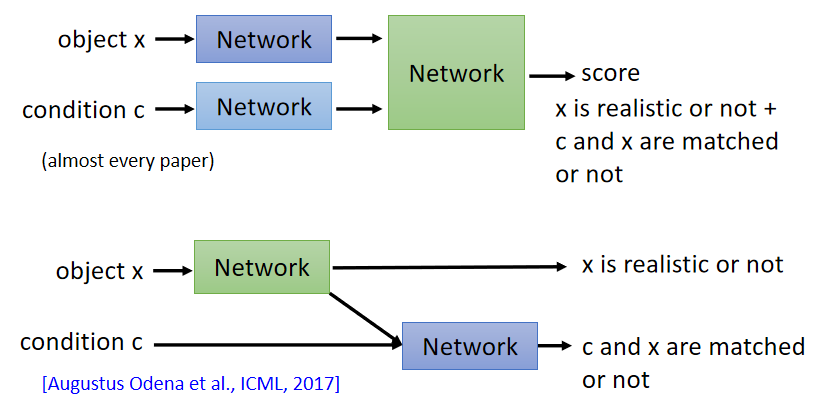
image-to-image
传统方法跟Text-to-Image的传统方法一样,就是直接输入一副图片。但是用了GAN+close之后效果明显增强(不要太注重他们的原理,先了解什么东西会带来什么效果)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









