







 本文详细介绍了Spark中的高级特性,如闭包如何封装局部作用域,RDD操作中的闭包使用,以及广播变量和累加器在优化性能和分布式环境中的应用。
本文详细介绍了Spark中的高级特性,如闭包如何封装局部作用域,RDD操作中的闭包使用,以及广播变量和累加器在优化性能和分布式环境中的应用。
Spark高级特性 (难)
-
闭包
/* * 编写一个高阶函数,在这个函数要有一个变量,返回一个函数,通过这个变量完成一个计算 * */ @Test def test(): Unit = { // val f: Int => Double = closure() // val area = f(5) // println(area) // 在这能否访问到 factor,不能,因为factor所在作用域是closure()方法,test()方法和closure()方法作用域是平级的,所有不能直接访问 // 不能访问,说明 factor 在一个单独的作用域中 // 在拿到 f 的时候, 可以通过 f 间接的访问到 closure() 作用域中的内容 // 说明 f 携带了一个作用域 // 如果一个函数携带了一个外包的作用域,这种函数我们称之为闭包 val f = closure() f(5) // 闭包的本质是什么? // f 就是闭包,闭包的本质就是一个函数 // 在 Scala 中,函数就是一个特殊的类型,FunctionX // 闭包也是一个 FunctionX 类型的对象 // 所以闭包是一个对象 } /* * 返回一个新的函数 * */ def closure(): Int => Double = { val factor = 3.14 val areaFunction = (r: Int) => math.pow(r, 2) * factor // 计算圆的面积 areaFunction }通过 closure 返回的函数 f 就是一个闭包, 其函数内部的作用域并不是 test 函数的作用域, 这种连带作用域一起打包的方式, 我们称之为闭包, 在 Scala 中
Scala 中的闭包本质上就是一个对象, 是 FunctionX 的实例
-
Spark中的闭包
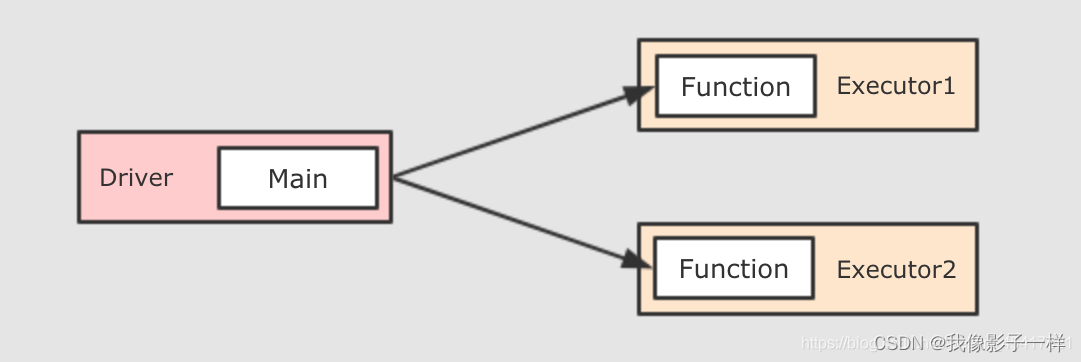
分发闭包
sc.textFile("./dataset/access_log_sample.txt") .flatMap(item => item.split(" ")) .collect() // item => item.split(" ") 是一个函数,代表一个Task,这个Task会被分发到不同的Executor中上述这段代码中,flatMp中传入的是另外一个函数,传入的这个函数就是一个闭包,这个闭包会被序列化运行在不同的Executor中
class MyClass { val field = "Hello" def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(x => field + x) } } /* * x => field + x 引用MyClass对象中的一个成员变量,说明它可以访问MyClass这个类的作用域, * 所以这个函数也是一个闭包,封闭的是MyClass这个作用域。 * x => field + x */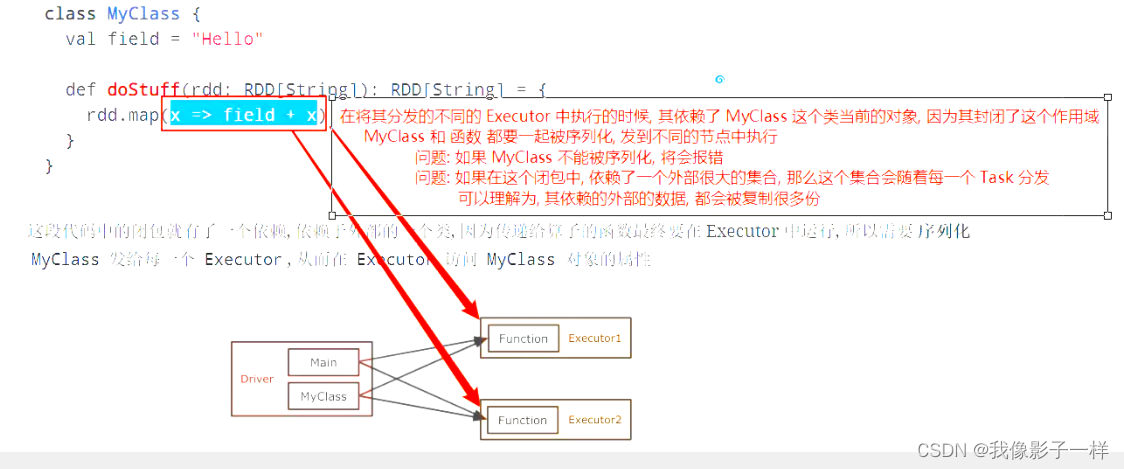
这段代码中的闭包就有了一个依赖, 依赖于外部的一个类, 因为传递给算子的函数最终要在 Executor 中运行, 所以需要 序列化 MyClass 发给每一个 Executor, 从而在 Executor 访问 MyClass 对象的属性
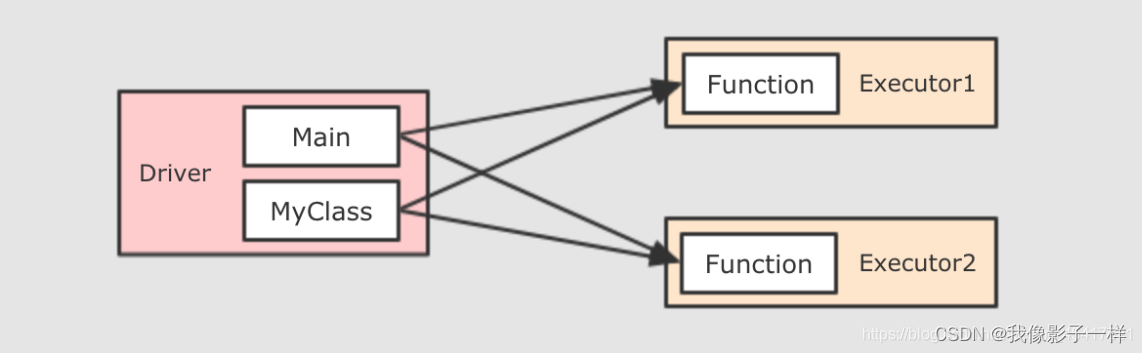
总结
- 闭包就是一个封闭的作用域, 也是一个对象
- Spark 算子所接受的函数, 本质上是一个闭包, 因为其需要封闭作用域, 并且序列化自身和依赖, 分发到不同的节点中运行
-
累加器
-
一个小问题
var count = 0 val conf = new SparkConf().setAppName("ip_ana").setMaster("local[6]") val sc = new SparkContext(conf) sc.parallelize
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









